

嵌套的结构体 字节是如何对齐的
描述
嵌套的结构体,字节又是如何对齐的呢
先来看下面的代码
typedef structstu1{ char ary[5]; int a;}stu1;
typedef structstu2{ double a; char b;}stu2;
typedef structstu3{ stu1 s; char str;}stu3;
typedef structstu4{ stu2 s; char str;}stu4;
LOG_INFO("rnrn====== Struct Test ======rnrn");LOG_INFO("sizeof(stu1) :t%dn",sizeof(stu1)); LOG_INFO("sizeof(stu2) :t%dn",sizeof(stu2)); LOG_INFO("sizeof(stu3) :t%dn",sizeof(stu3));LOG_INFO("sizeof(stu4) :t%dn",sizeof(stu4));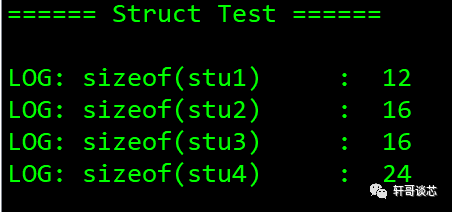
在上面的运行结果中,stu1和stu2所占内存的分别为12字节和16字节,对这两者的分析与前面相同。
我们重点看一下这里的stu3和stu4。
在默认情况下,结构体采用该结构体中占用内存最大的类型所占的字节数作为字节对齐方式,但是在stu3中定义的stu1结构体类型的变量s占用16字节,而stu3并不是按照16字节进行对齐的,而是采用4字节对齐,这是因为stu1和stu3中占用内存最大的是int型变量,占用4字节。因此在分析结构体字节对齐方式时需要将结构体分解为“原子类型”,如int、double、char、float、short等,而不是自定义的结构体类型。
找出分解出来的“原子类型”中占用内存最大的类型,将其占用的内存值作为结构体的默认字节对齐值。
在stu4中定义了stu2类型的结构体变量s,按照上面的方法先对stu2进行分解。分解出来的类型有double、char,stu4中还有char类型,其中占用内存最大的是double类型,占用内存大小为8字节,由此可知,stu4采用8字节对齐。
由于stu4中的stu2结构体类型变量s所占用的内存大小为16,而接下来定义了一个char类型的str变量,其偏移地址为16,占用一个字节,此时stu4占用的内存大小为17,不是字节对齐数8的整数倍,所以在stu4占用的内存的最后添加7字节的空间,使其占有内存大小为24。
需要注意,编译器添加的内存并没有使用,没有存放任何有意义的内容。
在结构体的嵌套中,不管遇到多少层的嵌套,都可以按照这种分解方法,对结构体进行逐层分解,再根据分解出来的“原子类型”分析结构体的字节对齐方式.
看下面的例子,会更清楚一些
typedef structstu2{ char a; short c; int d; int b;
}stu2;
typedef structstu4{ stu2 s; char str; double h;}stu4;
LOG_INFO("offset_of(stu4,s):t%dn",offset_of(stu4,s));LOG_INFO("offset_of(stu4,str):t%dn",offset_of(stu4,str));LOG_INFO("offset_of(stu4,h):t%dn",offset_of(stu4,h));
在 stu2 中,a 的偏移地址为 0,c 的偏移地址为 2,d 的偏移地址为 4,b 的偏移地址为 8。这里的变量 a,c,d 组成第一个对齐单元,变量 b 会和 stu4 中的 str 组合成一个对齐单元。
套在 stu4 中以后,str 的起始地址就为 12,这里,stu2 的 b 和 stu4 的 str 共同组成了第二个 8 字节的对齐单元。
最后一个对齐单元是 double 类型的 h 变量。
-
C语言-结构体对齐详解2017-07-12 4187
-
RM48HDK平台CCS结构体字节对齐总是咨询2018-05-25 5145
-
CCS3.3 结构体成员对齐2018-06-21 5852
-
请问在ccs4.2 中怎么设置结构体的字节对齐?2018-08-02 4428
-
请问z-stack结构体默认对齐方式是一字节吗?2018-08-18 2061
-
请问cc2640r2 ccs7.4结构体字节能实现对齐吗?2019-10-31 1378
-
STM32终极字节对齐的相关资料推荐2021-12-06 961
-
解析C语言结构体字节如何对齐2021-06-12 3928
-
C语言中Linux字节对齐的问题2021-08-16 3227
-
STM32 终极字节对齐解析2021-11-23 1629
-
对结构体的对齐理解上有点偏差2022-08-10 2123
-
结构体对齐为什么那么重要?2023-04-03 2031
-
为什么要结构体对齐?为什么结构体对齐那么重要?2023-05-26 2217
-
什么是结构体的字节对齐现象2023-11-20 1471
-
keil arm工程中结构体1字节对齐如何实现2024-01-05 6652
全部0条评论

快来发表一下你的评论吧 !
