

DDD死党:查询模型的本质
电子说
描述
1. 查询模型的本质
查询模型的本质就是:为不同的应用场景选择最合适的存储引擎,充分发挥各个存储引擎的优势。
在系统中,读接口的数量远超写接口,但我深信:==再简单的写也是复杂,再复杂的读也是简单。==
为什么呢?因为,想做好查询只需为不同的应用场景选择最合适的存储引擎,从而充分发挥底层存储引擎的优势,然后所面对的高性能、高并发等技术问题就迎刃而解了。
如下图所示:
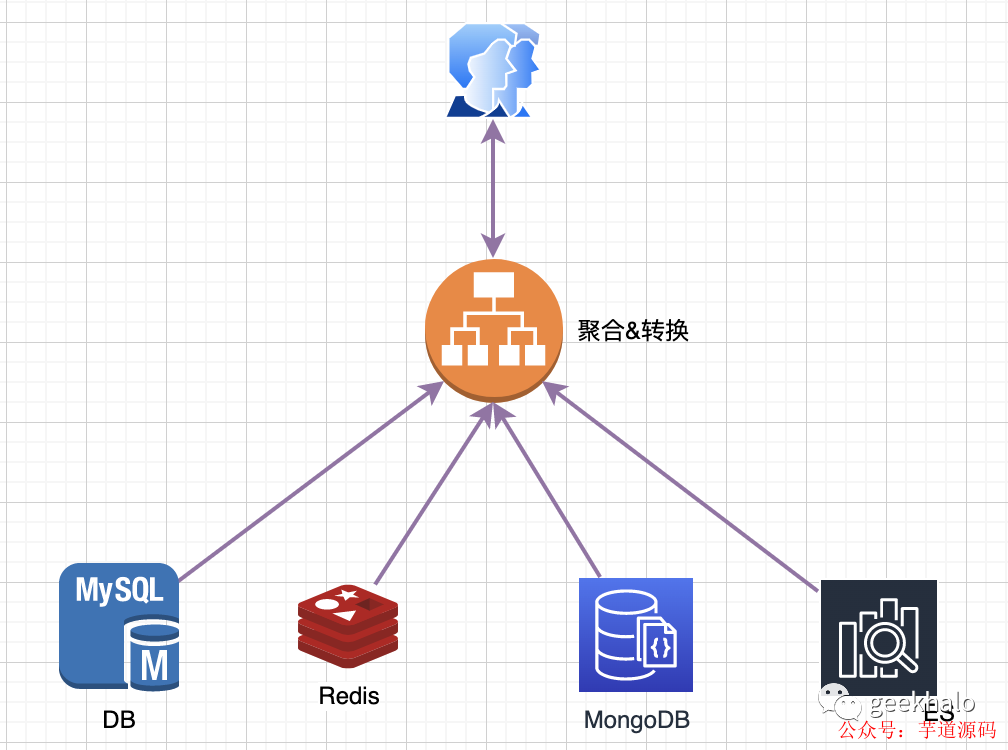
面对一个查询请求,我们需要:
接受并解析用户请求;
从各个存储引擎中获取数据;
对数据进行加工,包括数据聚合、数据关联、数据转换等;
将最终结果返回用户;
1.1. 常见存储引擎的特征
技术选型唯一原则:==仅仅使用它的成名之作,万万不可被花里胡哨的东西干扰你的判断。==
简单列举下常见的存储引擎:
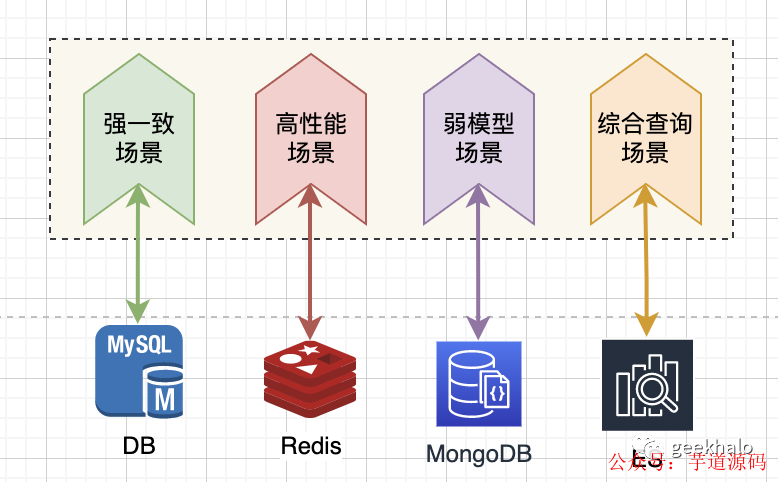
1.关系数据库。
【特点】提供事务机制对数据强一致性进行保障,其ACID四大特性更是建模利器;
【场景】适用于一致性要求高的金融或类金融场景,比如银行、支付、订单等;
2.Redis。
【特点】基于内存的键值存储引擎,具有高性能和低延迟;支持丰富的数据结构(字符串、哈希、列表、集合、有序集合等)和功能(发布订阅、事务等),提供丰富的持久化选项;
【场景】:缓存、会话存储、计数器、排行榜、分布式锁等对性能和实时性要求较高的场景;
3.Elasticsearch。
【特点】全文搜索和分析引擎,建立在Lucene库之上。擅长水平扩展、近实时搜索、全文搜索和复杂查询等功能;支持分布式架构、自动分片和数据冗余;
【场景】日志分析、实时监控、商业智能、搜索引擎、推荐系统等需要高效的实时全文搜索和分析功能的场景;
4.MongoDB。
【特点】面向文档的NoSQL数据库,以JSON风格的文档格式存储数据;支持动态模式、灵活的索引和复制集、分片等特性,可扩展性好,支持水平扩展;
【场景】大数据量、高写入频率、动态模式和灵活查询的场景,如内容管理系统、用户个性化数据存储、实时分析等;
1.2. 读接口三把利器
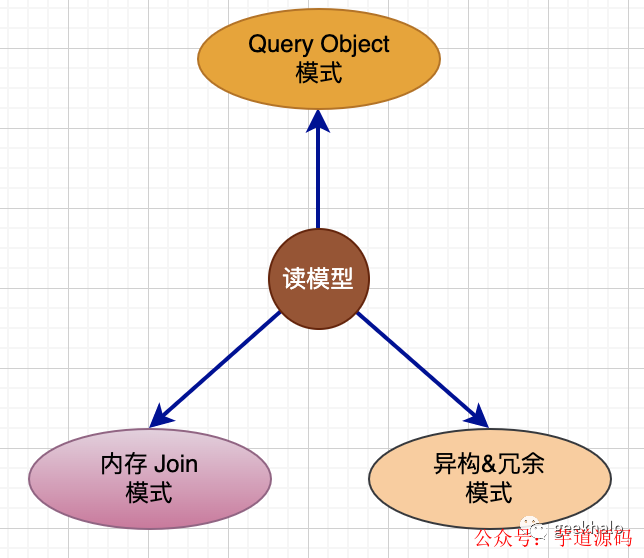
对于查询请求,主要有三种模式:
1.Query Object 模式。基于 Query Object 建模,完成对单引擎的快速查询;
通过对 Query Object 对象建模,便可以对查询条件进行灵活管理;
无需写 SQL,只需在 Query Object 上声明好各种过滤条件,便能完成查询。包括单条查询、批量查询、数量查询、分页查询等
2.内存 Join 模式。基于 View Object 建模,完成对结果数据的聚合操作;
通过对 View Object 对象建模,便可以对返回结果进行灵活控制;
无需手写关联代码,只需在 View Object 上声明关联关系,自动完成关联数据的聚合;
3.异构&冗余模式。
CQRS 思想的体现,彻底的将写模型和读模型拆分开,从而最大限度的发挥存储引擎优势;
异构意味着冗余,冗余意味着数据不一致,该模式通过准实时巡检、天级对账来保障数据的最终一致性;
三大模式综合使用如下:
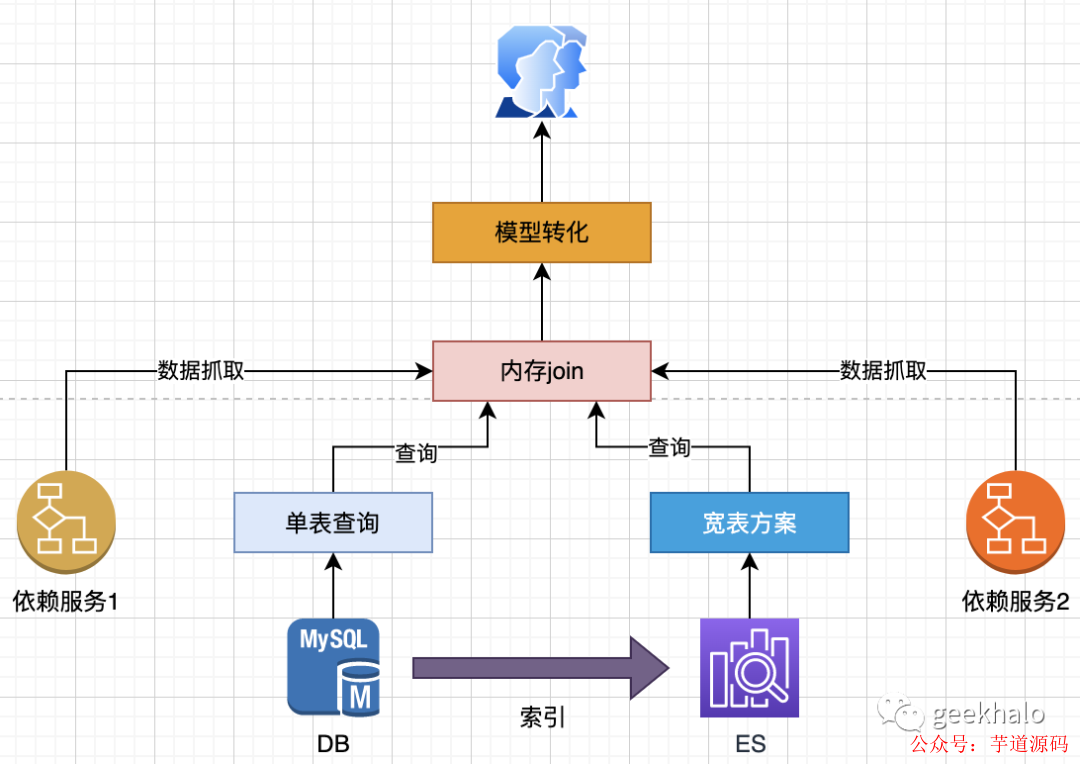
内存 Join 模式,从远程服务、存储引擎中获取数据,完成数据的聚合操作,然后对聚合数据进行转换,返回给用户;
Query Object 模式,大大简化对单引擎的查询,让你从繁重的 SQL(底层API) 中解放出来,大大提升开发效率;
异构&冗余模式,方便构建多副本异构数据模型,完成最繁琐的数据同步和数据一致性保障;
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
2. Query Object 模式
这是最常见,也是应用最多的模型,主要用于解决单引擎的数据查询。让开发聚焦于查询建模,而不再是繁杂易错的技术细节。
我们以简单的 MySQL 查询为例,假如使用 MyBatis 作为系统的 ORM 框架,其核心流程如下:
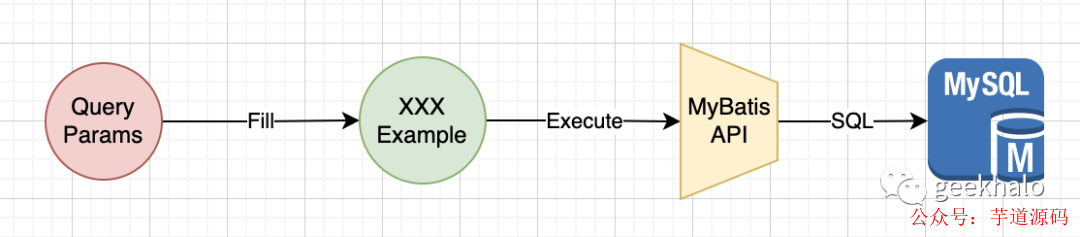
首先,我们会定义一组查询对象;
当我们接收到参数后,把有效参数填充到 Example 对象;
然后,将 Example 对象传入 MyBatis API 进行查询;
MyBatis 根据 Mapper 配置,将 Example 对象转换为对应的 SQL 和参数,并提交给 MySQL;
最终,MySQL 执行 SQL 获取并返回查询结果;
仔细思考下,这里面是不是存在很多“固定逻辑”,而我们每天写的代码是不是有很强的“重复性”?
接下来看下面这张图:
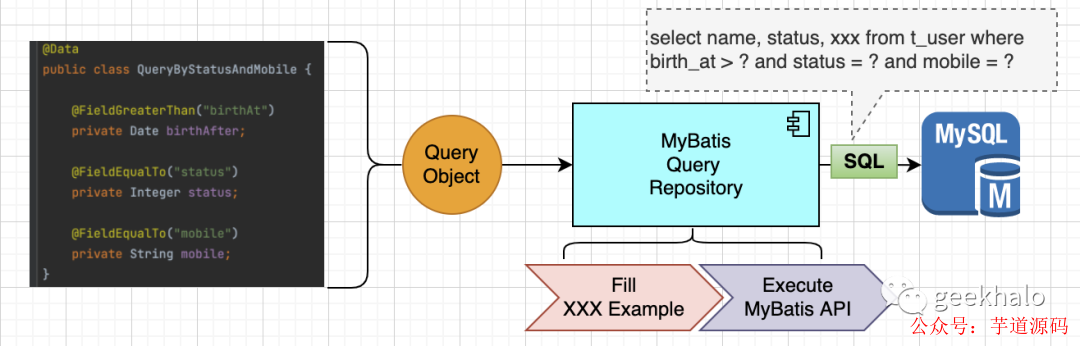
内核和核心流程没有变化,但上层 API 出现巨大变化:
1.首先,引入了 Query Object:
将分散的查询参数封装到一个类中;
在查询对象的属性上多了一组注解,用于声明该属性与数据库查询条件的关系;
2.然后,多了一个核心组件 MyBatisQueryRepository:
从 Query Object 上读取属性和注解信息,并完成对 Example 对象的填充;
使用填充好的 Example 对象调用 MyBatis API,从而完成数据查询;
在该模式下,开发 MyBatis 的单表查询,只有一件事要做:按照业务要求对 Query Object 进行建模。
当然为了方便使用,QueryRepository 提供多种接口:
get:查询单个对象;
listOf:查询多个对象;
countOf:查询数量;
pageOf:分页查询;
如对该部分感兴趣,可研读稍后文章。
该玩法支持复杂查询吗?
首先,不支持。对于复杂查询,只能回归到 MyBatis 底层 API。
【注】不要奢求一个框架或一个方案解决所有问题。使用 20% 的精力来解决 80% 的问题,那开发效率已经得到极大提升。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
3. 内存 Join 模式
内存 Join 等同于关系数据库的 Join 语句,只是将 Join 动作从数据层提升到了应用层。
其实我们每天都在写这样的重复代码!!!
假如有一个需求,实现我的订单接口,返回值里面需要包括 用户信息(User)、收获地址信息(Address)、商品信息(Product)等。而这些信息没有在一个数据库,甚至分散在不同的服务,需要调用远程接口才能获取到。由于无法使用数据库的 join 语句,所以就出现了如下接口:
查询我的订单并将其转换为 OrderDetail 集合:

获取 User 信息,并填充到 OrderDetail 对象:
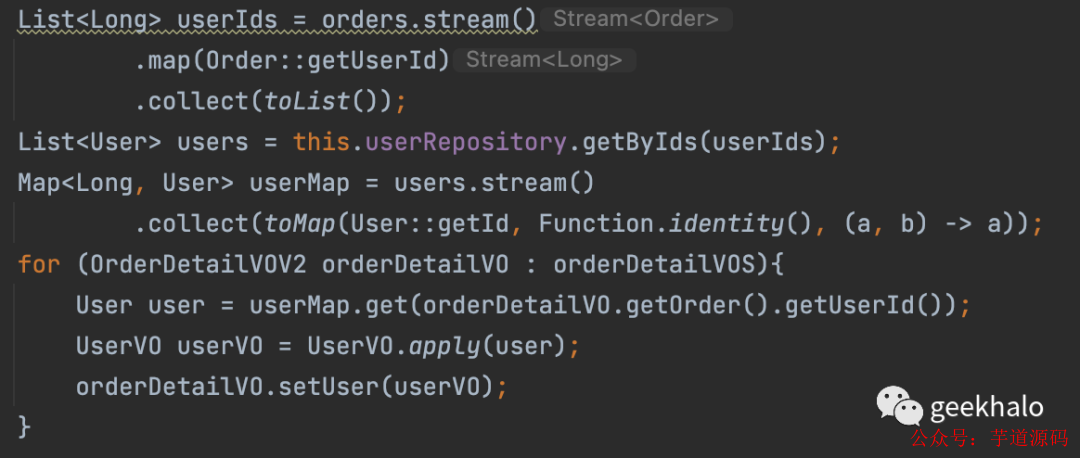
获取 Address 信息,并填充到 OrderDetail 对象:
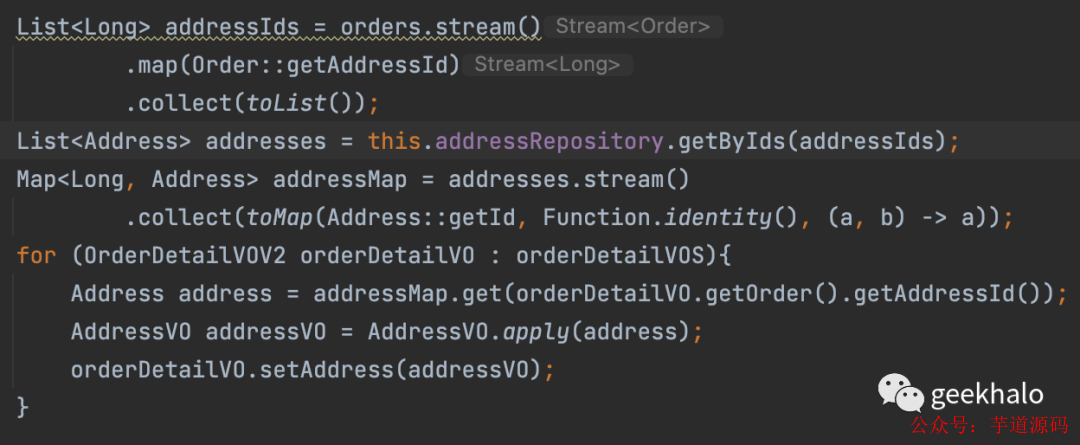
获取 Product 信息,并填充到 OrderDetail 对象:
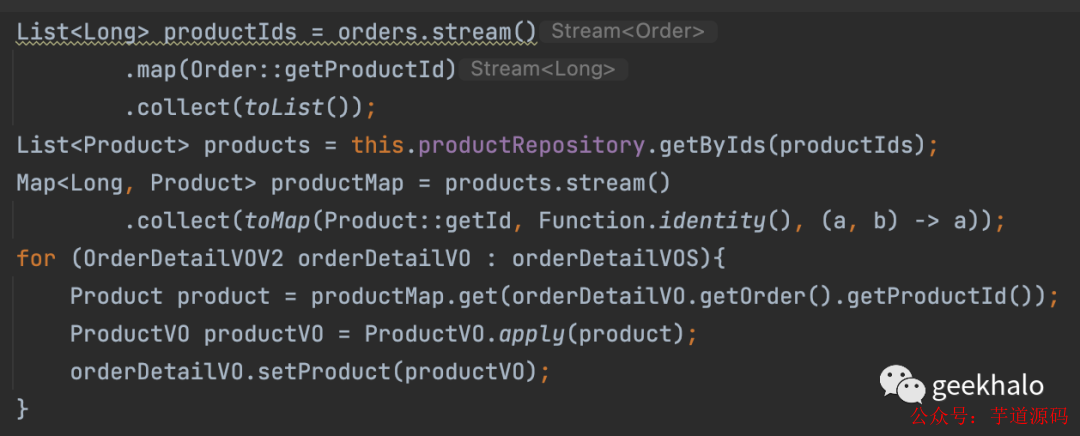
最后,返回填充好的 OrderDetail 集合;
仔细观察上面的代码,你是找到了“重复逻辑”?
如果,又要开发一个购物车列表呢?购物车列表和我的订单是否存在重复逻辑?
思考完之后,请看 内存 Join 模式:
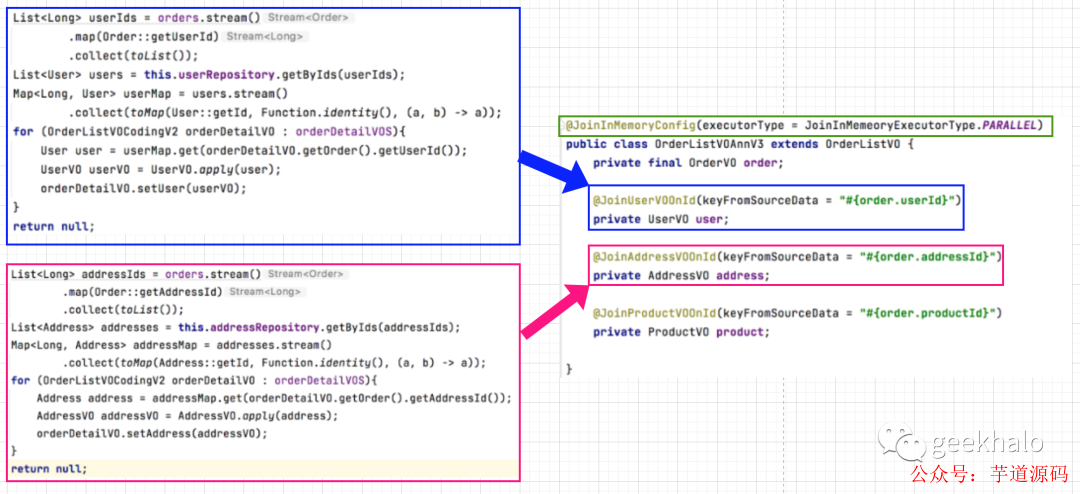
可以看到:
大量繁杂冗余代码被简单的 @Join注解 取代
还可以开启并发模型,使用多线程技术加快接口响应速度
整体流程如下:
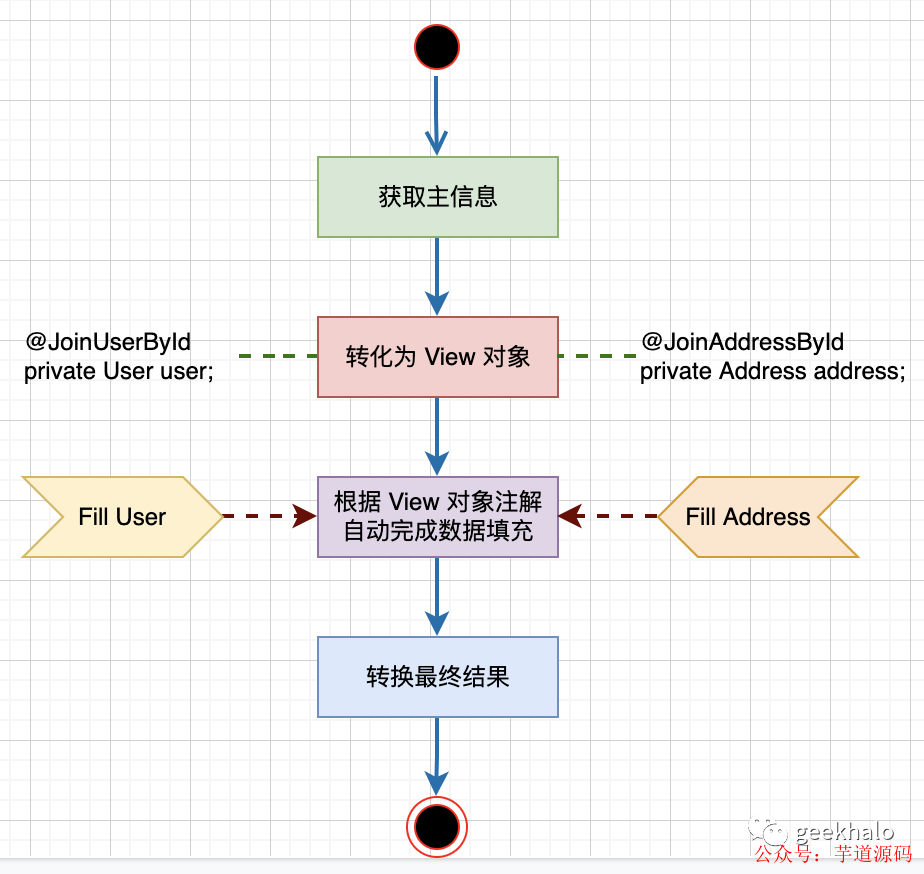
我们通过对 View Object 建模便能对返回数据进行控制,从而大大简化对返回结果的开发成本。
如对该部分感兴趣,可研读稍后文章。
4. 异构&冗余模式
异构冗余模式,主要用于多存储引擎的场景,旨在保障多存储引擎间数据的一致性。
比如,在一个复杂的系统中,核心数据存储于 MySQL,使用 Redis 进行缓存加速,使用 ES 完成全文检索。如何设计系统,才能保障 MySQL 中的数据与 Redis、ES 的数据始终保持同步,从而实现最终一致性。
看似很简单,但真正实现起来却到处是坑,在深入思索后得出两个特征:
存在决策节点并具备强顺序性。按照决策节点给出的变更顺序,依次在异构引擎上进行回放,便能实现两者的最终一致性;
存在权威的“源信息”,发现不一致时可以使用源头信息对数据进行自动修复;
从而,推导出该场景下的最佳实践:
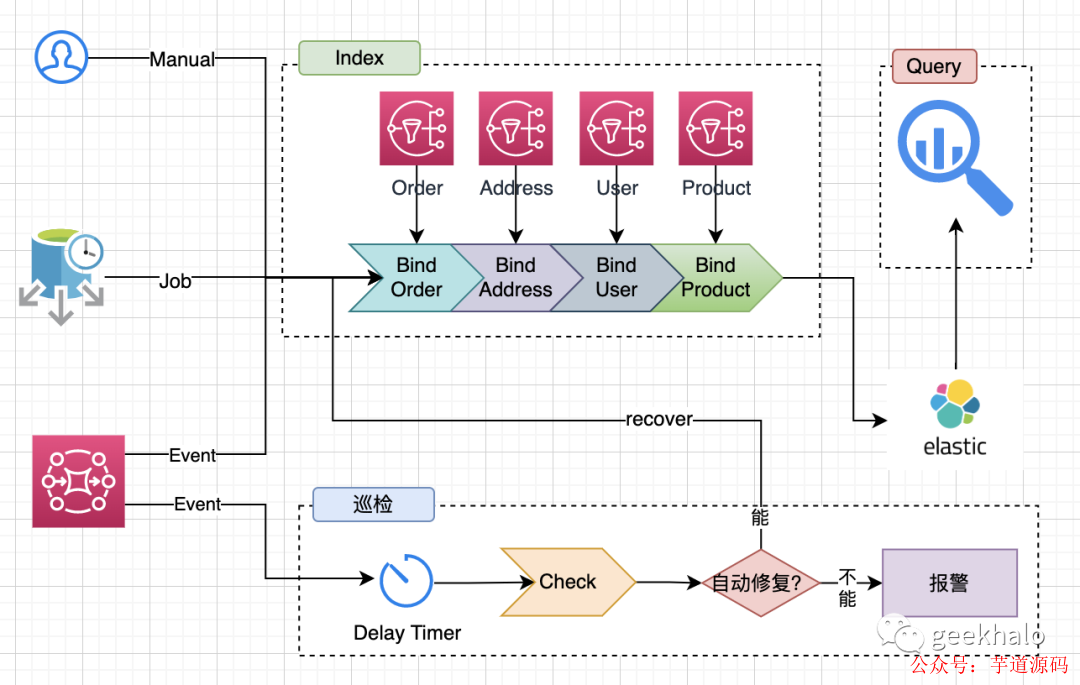
整体架构分为如下几部分:
索引:主要完成数据的构建,从多个系统中拉取数据完成数据的装配,并按所需结构对数据进行转化;
巡检:对系统中的数据进行实时巡检或定时对账,发现系统中不一致的数据并完成数据的自动修复。如遇数据无法修复的场景,自动进行报警,人工介入进行处理;
查询:充分发挥存储引擎的优势,提供业务查询能力,常与 Query Object 模式 和 内存 Join 模式 结合使用;
通过对最佳实践的封装,可以在同一套组件、同一个数据模型基础上,完成对 索引&更新、巡检&修复 两大流程的融合,大大降低研发工作量。
如对该部分感兴趣,可研读稍后文章。
5. 小结
查询模型的本质就是:为不同的应用场景选择最合适的存储引擎,然后充分发挥各个存储引擎的优势。
基于此提出三个模式:
Query Object 模式。通过 Query Object 建模,实现对查询条件的灵活管理。无需写 SQL,只需在 Query Object 上声明好各种过滤条件,便能完成常规查询。包括单条查询、批量查询、数量查询、分页查询等;
内存 Join 模式。基于 View Object 建模,实现对返回结果的灵活控制。无需手写关联代码,只需在 View Object 上声明关联关系,自动完成关联数据的聚合;
异构&冗余模式。CQRS 思想的体现,彻底的将写模型和读模型拆分开,通过准实时巡检、天级对账来保障数据的最终一致性,从而最大限度的发挥存储引擎优势;
-
可从GraphQL查询生成Java模型的Apollo HarmonyOS2022-04-12 741
-
聚合查询与分组查询2019-09-19 2169
-
电机的本质运行原理是什么2021-09-06 846
-
MATPOWER工具本质原理是什么?2021-10-21 1548
-
XML数据流基于组着色的XPath查询模型2010-08-02 703
-
黑客攻防入门与进阶ddd2016-02-23 881
-
一种新的查询意图识别模型2018-02-23 1038
-
DDD_RH137K_FAB地段10008104.1 W7修订版22021-05-24 864
-
"Scalable, Distributed Systems Using Akka, Spring Boot, DDD, and Java--转"2021-12-01 769
-
用好DDD必须先过Spring Data这关2023-03-07 2870
-
一文理解DDD领域驱动设计2023-05-25 1743
-
DDD驱动如何设计?如何进行领域建模?2023-07-18 2136
-
DDD是什么?DDD核心概念梳理2023-09-07 12338
-
DDD学习与感悟——向屎山冲锋2024-09-24 1171
-
在DVEVM上通过ddd运行Demo2024-10-15 353
全部0条评论

快来发表一下你的评论吧 !
