

苹果m3处理器是什么级别 m3处理器性能详解
处理器/DSP
描述
以全新 M3 系列处理器为基础,Apple 选择一次性推出大部分堆栈,同时发布了基于普通 M3 的产品,以及更强大的 M3 Pro 和 M3 Max SoC。基于台积电的 N3B 工艺,苹果希望再次提高 CPU 和 GPU 性能的标准,并创下单个笔记本电脑 SoC 中使用的晶体管数量的新记录。
新款 M3 芯片的推出与新款 MacBook Pro 笔记本电脑以及更新的 24 英寸 iMac 齐头并进。但由于苹果没有对任何这些设备进行任何外部设计或功能更改——它们的尺寸、端口和部件与以前相同——它们是对这些设备内部结构的直接更新。因此,这些最新产品发布中的明星是新的 M3 系列 SoC 及其带来的功能和性能。
凭借适用于 Mac(毫无疑问,还有高端 iPad)的最新一代高性能芯片,苹果似乎充分利用了台积电 N3B 工艺提供的密度和功耗改进。但与此同时,他们也在改变 SoC 的配置方式;尤其是 M3 Pro 与其前身有很大不同。因此,尽管 M3 芯片本身并未达到“突破性”的水平,但我们将关注一些重要的变化。
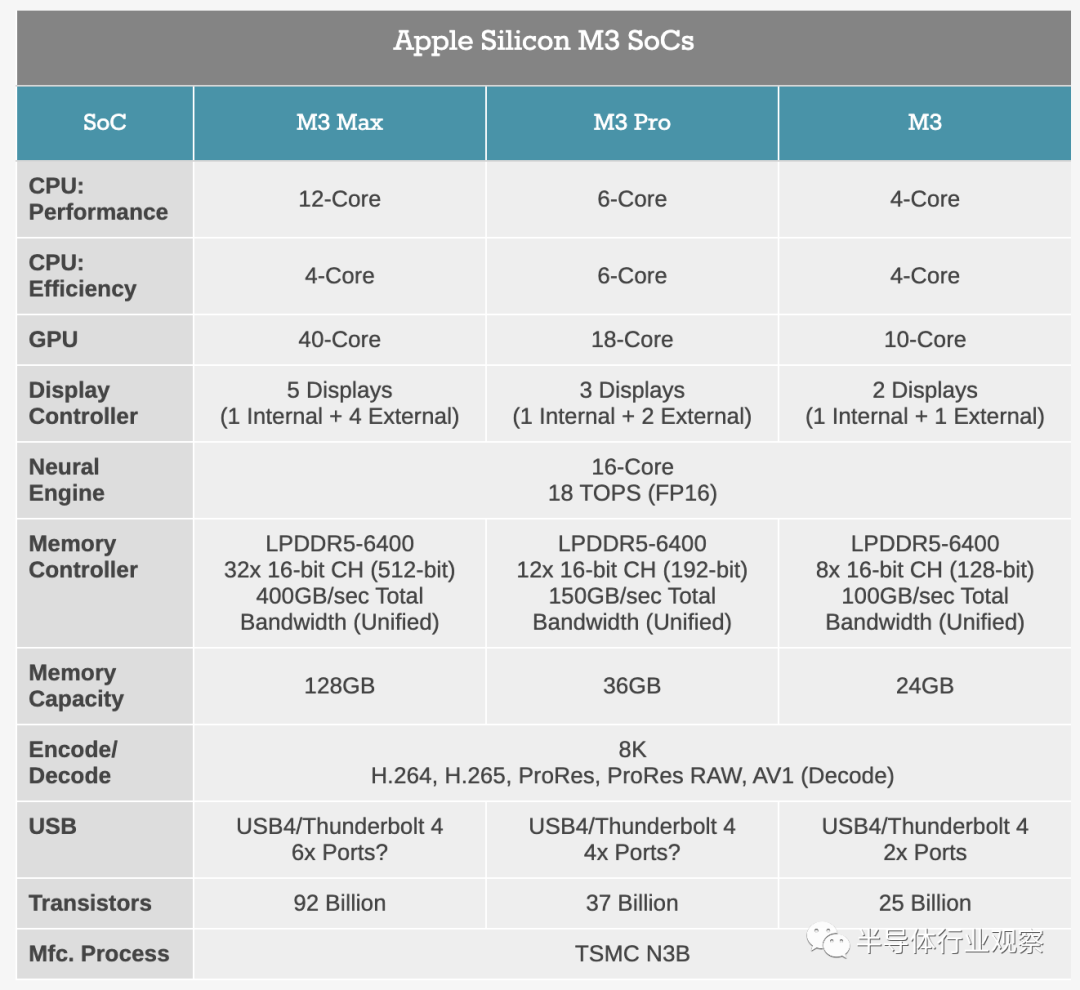
首先,我们来看看三款新 M3 芯片的规格。所有三款芯片均在一个月内发布(从技术上讲,M3 Max 设备要到 11 月中旬才会上市),这是新一代 M 系列芯片迄今为止最雄心勃勃的发布。通常情况下,Apple 都是从小规模开始,然后逐步提升,例如M2,然后是 Pro 和 Max 变体,但这次我们得到的可能是所有单片(且适用于笔记本电脑)硅部件。
但苹果也开始缩小体积。该公司正在使用这些新芯片来更新 MacBook Pro 系列和 iMac,这是该公司一些更昂贵(并且普遍认为产量较低)的产品。这与从 MacBook Air 和其他更便宜的设备开始形成鲜明对比,后者消耗了大量的入门级芯片。这很可能是由于苹果决定使用像 N3B 这样的前沿节点(他们是唯一的客户之一),这将带来新的芯片产量和数量瓶颈。但是,当然,苹果永远不会证实这一点。不管怎样,他们已经彻底改变了这一代的芯片发布策略,首先从更昂贵的设备开始。
所有这三款芯片都共享一个通用架构,并且从广义上讲,都是该架构的扩展版本,具有更多内核、更多 I/O 和更多内存通道。最小的芯片 M3 一开始有 250 亿个晶体管(比 M2 多 50亿个),而最高峰是 M3 Max 及其 920 亿个晶体管。虽然苹果提供了芯片die shot(当今业界很少见),但他们不提供芯片尺寸,因此我们必须在设备发货后看看这些芯片尺寸如何测量。
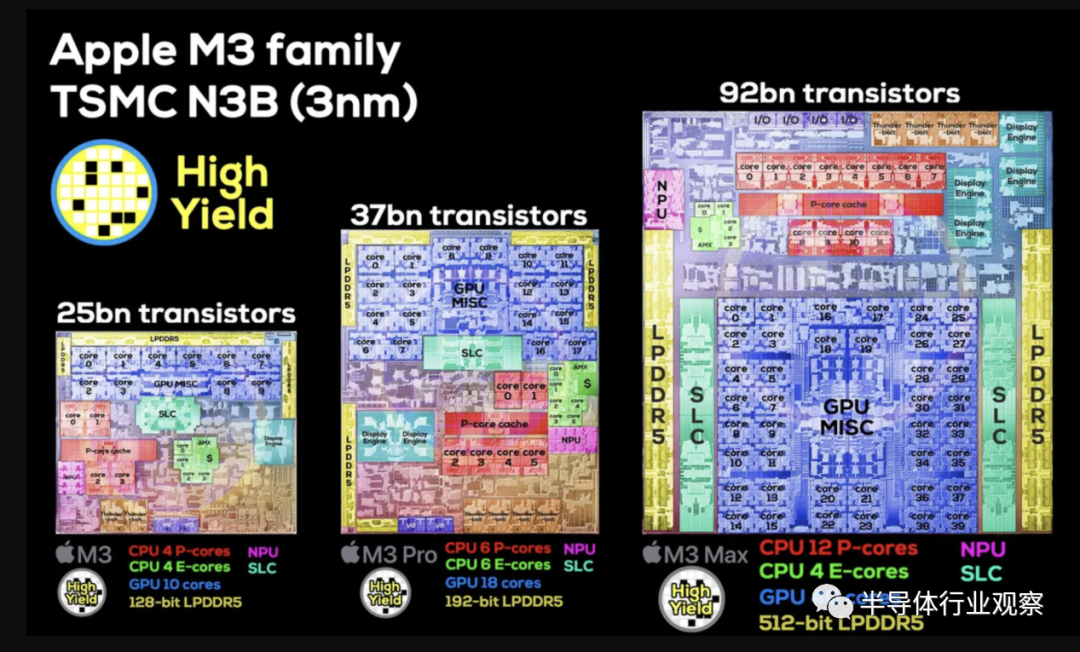
虽然苹果尚未正式披露除 3 纳米设计之外所使用的工艺,但考虑到唯一可用于这种大批量生产的台积电 3 纳米生产线是他们的 N3B 生产线,因此可以非常安全地打赌,我们这里我们看一下 N3B,它也被用在 A17 上。根据台积电官方数据,N3B 提供了极高的晶体管密度,特征尺寸减少了 42%,iso-power 减少了约 25%。但即便如此,M3 Max 仍然是一款坚固的芯片。
在其他方面,苹果支持的内存类型似乎没有任何变化。在某些情况下,该公司的带宽数据与 M2 系列的数据相同,表明该公司仍在使用 LPDDR5-6400 内存。这有点令人惊讶,因为更快的 LPDDR5X 内存很容易获得,而且 Apple 的 GPU 密集型设计往往会从额外的内存带宽中受益匪浅。目前最大的问题是,这是否是由于技术限制(例如苹果的内存控制器不支持 LPDDR5X),或者苹果是否有意决定坚持使用常规 LPDDR5。
M3 CPU 架构:速度明显更快
在架构方面,不幸的是,Apple 对于 M3 系列 SoC 中使用的 CPU 和 GPU 架构相当模糊。事实上,该公司全年都在严格控制泄密情况——即使现在我们也不知道 A17 SoC 中使用的 CPU 内核的代号。
无论如何,鉴于苹果在 A 和 M 系列芯片之间共享 CPU 架构,我们无疑以前见过这些 CPU 内核。问题是我们是在关注最近推出的 A17 SoC 的 CPU 内核,还是 A16(Everest 和 Sawtooth)的 CPU 内核。A17 是更有可能的候选者,特别是因为苹果已经拥有 N3B 的工作 IP。但严格来说,我们目前没有足够的信息来排除A16 CPU核心;特别是苹果没有就 M3 系列 CPU 内核相对于 M2 提供的架构改进提供任何指导。
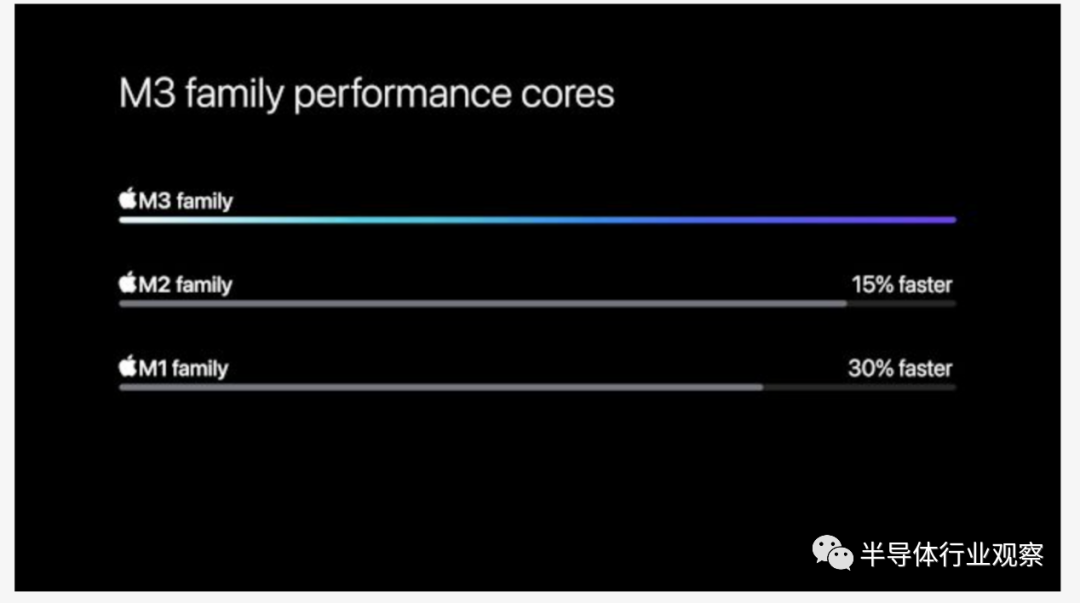
目前我们所知道的是,与 M2 系列相比,Apple 宣称其高性能 CPU 内核的性能提高了约 15%。或者,如果您更喜欢 M1 比较,则可提高 30%。苹果没有透露用于做出这一决定的基准或设置,因此我们无法透露该估计的真实性。或者,就此而言,其中有多少来自 IPC 提升与时钟速度提升。
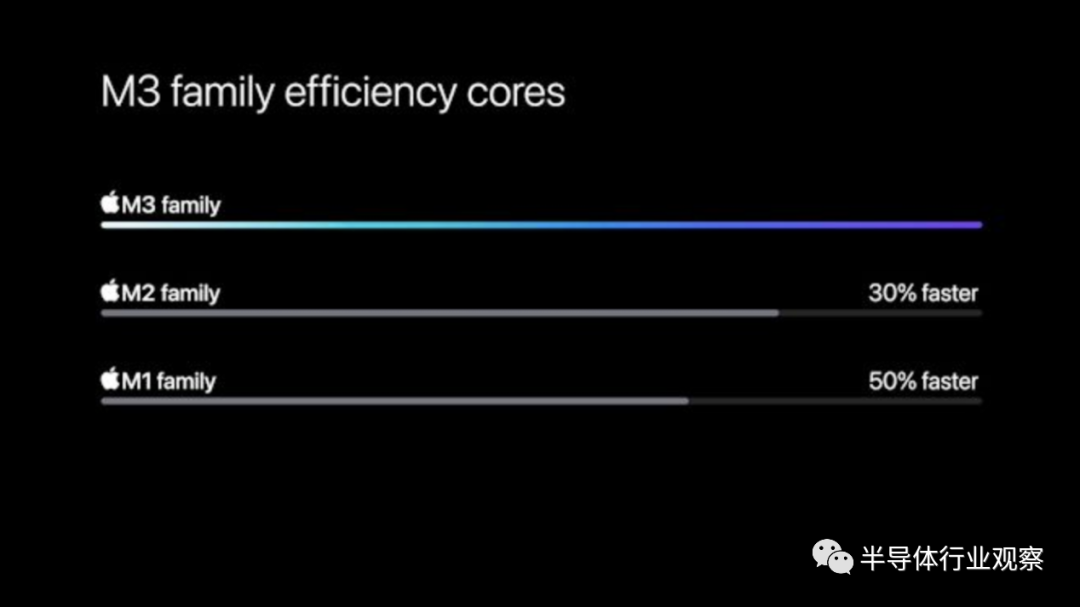
与此同时,效率核心也得到了改进,根据苹果公司的说法,其增益比高性能核心更大。M3 系列效率核心比 M2 快 30%,比 M1 快 50%。
苹果在其网站上发布了特定于应用程序的基准测试,尽管这些是系统级基准测试。其中许多是 CPU 和 GPU 共同获得的收益。这肯定与这些应用程序的用户相关,但它们并没有告诉我们太多有关 CPU 内核本身的信息。
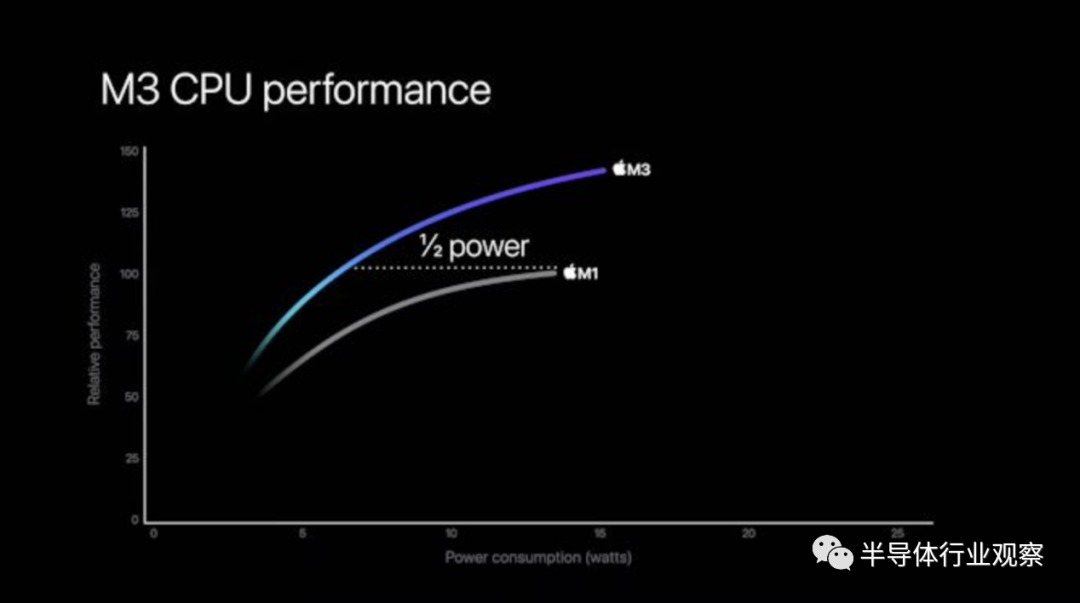
苹果同样模糊的性能/功率曲线图也在很大程度上重申了这些说法,同时证实了性能/功率曲线变得平坦的长期趋势正在持续。举例来说:Apple 声称 M3 可以以一半的功耗提供与 M1 相同的 CPU 性能;但在等功率下,峰峰值性能仅高出 40% 左右。
从等性能的角度来看,连续几代的工艺技术不断降低功耗,但在解锁更高的时钟速度方面却做得相对较少。这使得更高时钟速度带来的持续性能提升在功耗方面相对昂贵,这反过来又促使芯片供应商增加整体功耗。根据苹果的图表,即使是 M3 也未能幸免,因为它的峰值功耗高于 M1。
M3 GPU 架构:具有网格着色和光线追踪的新架构
与此同时,在 GPU 方面,M3 系列芯片包含了更实质性的 GPU 架构更新。虽然苹果公司对 GPU 架构的底层组织一如既往地守口如瓶,但从功能角度来看,新架构为苹果平台带来了一些主要的新功能:网格着色和光线追踪。
Apple 的 iPhone 15 Pro 系列 A17 SoC 也引入了这些相同的功能,几乎可以肯定,这是该架构的更大规模实现,就像前几代的情况一样。当我们在这里讨论笔记本电脑和台式机时,这些功能将使 M3 GPU 与 NVIDIA/AMD/Intel 的最新独立 GPU 设计大致相当,所有这些设计公司几年来都提供了类似的功能。用 Windows 的话说,M3 GPU 架构将是DirectX 12 Ultimate 级(功能级别 12_2)设计,使 Apple 成为第二家在笔记本电脑 SoC 中提供如此高功能集成 GPU 的供应商。
在这一点上,光线追踪几乎不需要介绍,因为整个 GPU/图形行业在过去五年里一直在大力推广物理上更加精确的渲染形式。另一方面,网格着色不太为人所知,因为它提高了渲染管道的效率,而不是解锁新的图形效果。然而,其重要性不容低估。网格着色颠覆了整个几何渲染管道,以允许在可用帧速率下呈现更多几何细节。它在很大程度上是一个“基线”功能——开发人员需要围绕它设计引擎的核心——所以它在最初的采用中不会有太大影响,但它最终将成为一个决定成败的功能,与 M3 之前的 GPU 兼容的分界点。我们今天已经在 PC 游戏(例如最近发布的《心灵杀手 II》)中看到了这一点。
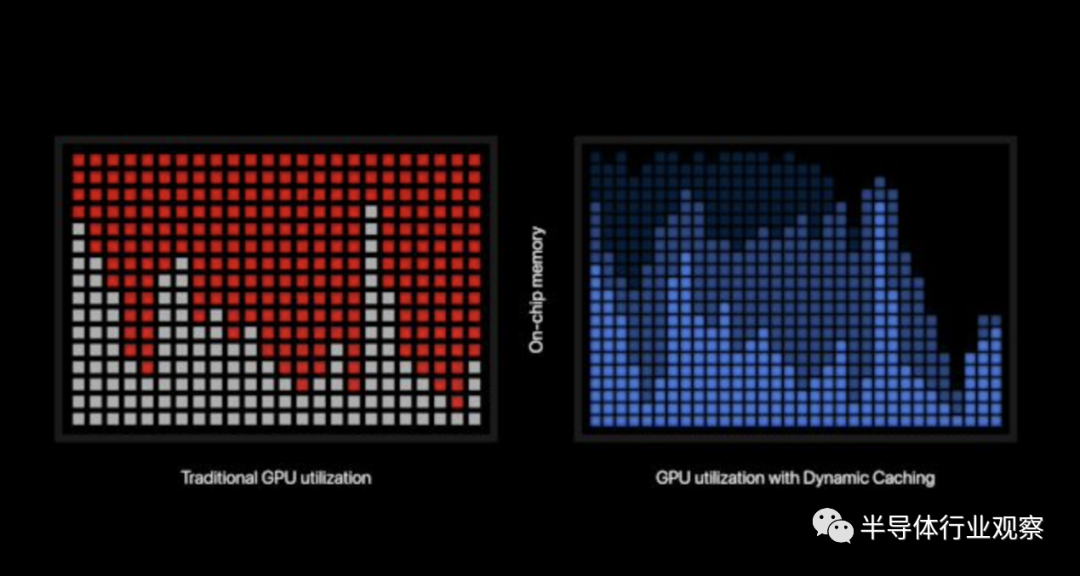
这一代 GPU 还配备了新的内存管理功能/策略,苹果将其称为“动态缓存”。根据苹果产品展示中的有限描述,该公司似乎采取了新的努力来更好地控制和分配其 iGPU 使用的内存,防止其分配比实际需要更多的内存。GPU 过度分配内存是很常见的(拥有它而不需要它比相反更好),但这是浪费的,尤其是在统一内存平台上。因此,正如苹果所说,“每项任务只使用所需的确切内存量”。
值得注意的是,此功能对开发人员来说是透明的,并且完全在硬件级别上运行。因此,无论苹果在幕后做什么,它都被从开发者和用户手中抽象出来。尽管用户最终将受益于更多的可用 RAM,但当 Apple M3 Mac 的最低配置仍然是 8GB RAM 时,这无疑是一件好事。
然而,更令人好奇的是,苹果声称这也将提高 GPU 性能。具体来说,动态缓存将“显著”提高 GPU 的平均利用率。目前尚不清楚内存分配和 GPU 利用率之间的关系,除非苹果针对的是一种极端情况,即由于缺乏 RAM,工作负载必须不断交换到存储。不管怎样,苹果认为这一功能是新 GPU 架构的基石,并且值得在未来进行更仔细的研究。
然而,在性能方面,苹果提供的指导非常少。在过去的几代中,该公司至少提供了其 GPU 的一般计算吞吐量数据,例如普通 M2 GPU 的 5.6 TFLOPS。但对于 M3 GPU,我们没有获得任何此类吞吐量数据。因此,目前还不清楚这些 GPU 在现有应用程序/游戏中的速度有多快,或者它们可以有多快。Apple 在其产品页面上引用了 2.5 倍的数字,但查看注释,这是具有硬件 RT (M3) 的 Redshift 与软件 RT(其他所有内容)的对比。
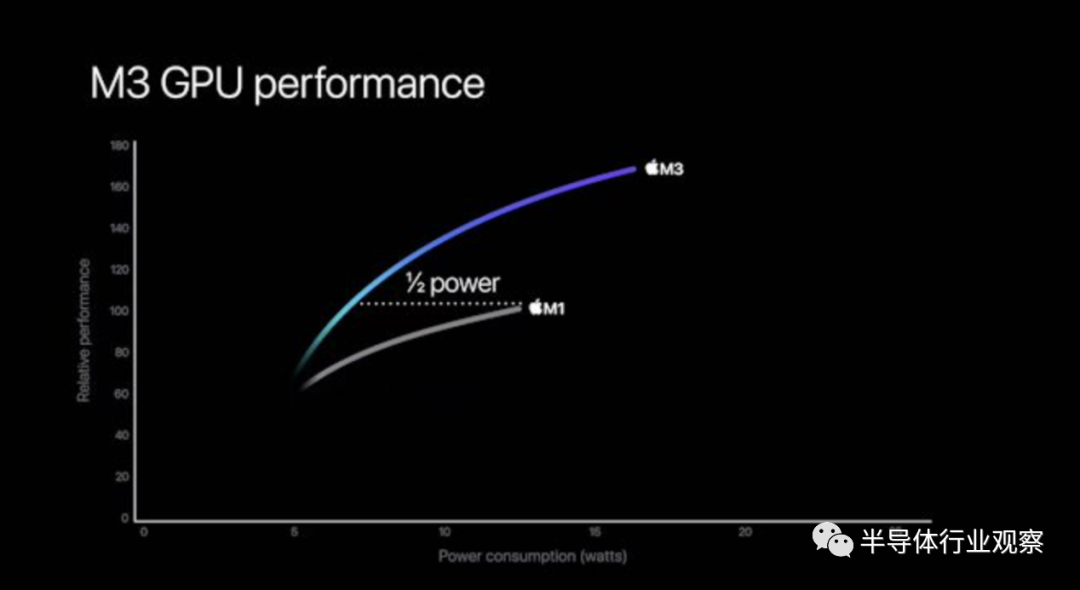
苹果充其量只是在演示中展示了 GPU 性能/功率曲线图,将 M3 与 M1 进行了比较。苹果再次声称 M3 在 iso 性能下消耗一半的电量。同时,等功率(峰值 M1,约 12.5W)下的性能大约提高了 50%。但M3的GPU功率限制也明显更高,达到约17瓦。这释放了更多的性能,但同样消耗了更多的电量,并且没有告诉我们 M3 GPU 与 M2 的比较如何。
M3 NPU:更快一点,但架构没有更新?
最后但并非最不重要的一点是,让我们快速浏览一下 M3 的 NPU(神经引擎)。从高层次来看,这又是 16 核设计。苹果声称它提供了 18 TOPS 的性能,比 M2 的 NPU 高出约 14%(苹果官方数据为 15%,很可能是由于舍弃了小数)。所有三款 M3 芯片似乎都具有相同的 16 核 NPU 设计,因此应该具有相似的性能。

然而,18 TOPS 的数字却令人大吃一惊。正如Ian Cutress 博士向我指出的那样,18 TOPS 实际上比 A17 SoC 中的 NPU 慢。
发生什么了?
随着 A17 SoC 的推出,苹果开始引用 INT8 性能数据,而我们认为之前版本的 NPU(A 系列和 M 系列)的 INT16/FP16 数据。该格式的精度较低,可以以较高的速率进行处理(以精度换取吞吐量),因此引用的数字较高。
这里的 18 TOPS 数字显然是 INT16/FP16 性能,因为这与过去的 M 系列声明和 Apple 自己的图表一致。那么,悬而未决的问题是,M3 中的 NPU 是否支持 INT8,因为 A17 最近才添加了 INT8。要么它确实支持 INT8,在这种情况下,Apple 正在努力实现一致的消息传递,要么它是缺乏 INT8 支持的老一代 NPU 架构。
总体而言,这种差异更多的是出于好奇,而不是担忧。但看看苹果是否保持 A 和 M 系列的 NPU 架构相同,或者我们是否看到这一代的差异,将会很有趣。
仅规格:M3、M2、M1
回到速度和馈送,我还整理了每一层 M 系列处理器的规格表,将它们与它们的前辈进行比较。这有助于更好地说明这些部件在核心数量、性能、内存支持和 I/O 方面如何随着时间的推移而演变。

M 系列的vanilla系列是该系列中最简单的。作为 M 系列芯片中的第一款产品,Apple 不断增强该芯片的功能和性能。但他们并没有在功能块/核心方面添加太多。现在已经三代了,CPU还是4P+4E的设计,GPU也从第一代的8核发展到了M2和M3的10核。
一致的 128 位内存总线为这头小野兽提供了食物。由于苹果没有在这一代 M 系列中采用 LPDDR5X,因此内存带宽与 M2 保持不变,LPDDR5-6400 高达 24GB,可实现 100GB/秒的总内存带宽。

芯片的有限 I/O 也一直存在于各代产品中。M3 可以驱动两个 40Gbps USB4/Thunderbolt 端口,与 M2 和 M1 相同。此外,仍然仅支持两个显示器——内部显示器和单个外部显示器。
尽管核心数量没有增加,但随着新功能和更复杂的核心设计占用更大的晶体管预算,晶体管数量在几代人中持续增长。M3 拥有 250 亿个晶体管,比 M2 多出 25%,比 M1 多出 56%。
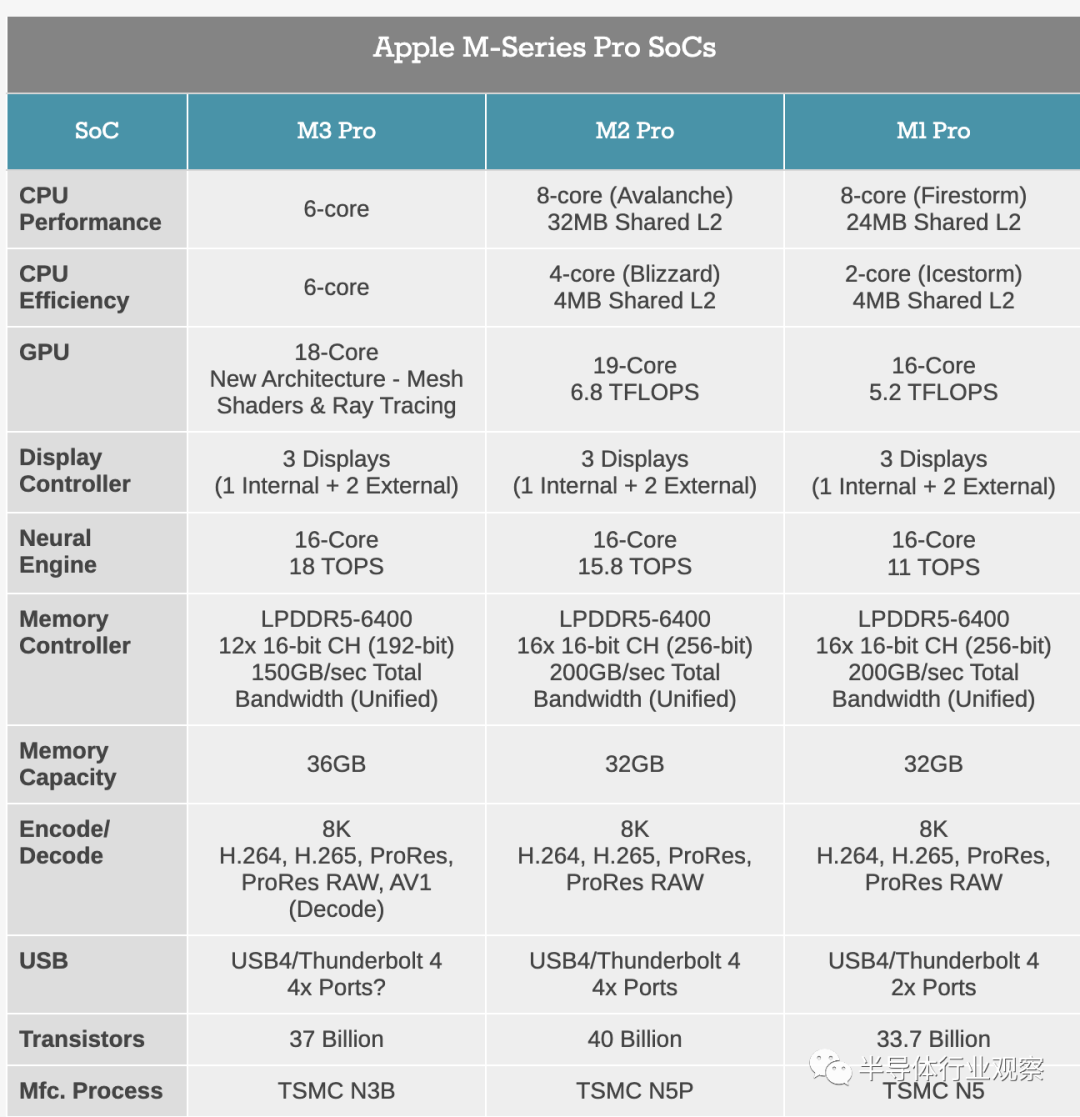
然而,M3 Pro 的情况却变得更加有趣。与以相对简单的方式建立在前辈基础上的兄弟姐妹不同,苹果在第三代 M 系列芯片中重新平衡了 M3 Pro。因此,它在配置方面与 M2 Pro 存在一些显着差异,并且在晶体管数量方面它并没有像其他芯片那样增长。
从CPU核心开始,虽然M3 Pro和M2 Pro一样总共有12个CPU核心,但性能和效率核心之间的平衡已经发生了变化。具体来说,它从8P+4E设计变成了6P+6E设计。虽然所有 CPU 核心的性能总体上都比 M2 同类产品更高,但这就是为什么 Apple 的配备 M2 Pro 的 MacBook Pro 的官方性能数据显示它们在 CPU 性能方面仅提供了微弱的提升。对于多线程繁重的工作负载,计算硬件实际上并没有增加。
GPU 核心数量也有所减少。M3 架构 GPU 提供 18 个核心,而 M2 Pro 则有 19 个核心。这与普通的 M3 或 M3 Max 不同,后者的 GPU 核心数量要么持平,要么略有增加。
最后,提供所有这些的是明显更小的内存总线。M1 Pro 和 M2 Pro 都配备了 256 位 LPDDR5 内存总线,当填充 LPDDR5-6400 时,可为 SoC 提供 200GB 的聚合内存带宽。然而,在 M3 Pro 上,Apple 已将内存总线明确削减至 192 位宽,即删除了四分之一的内存总线,这反过来又将内存带宽降低了 25%,至 150GB/秒。

这些变化的结合意味着M3 Pro在高水平上看起来更像是更强大的普通M3,而不是精简版的M3 Max。从某些方面来说,这只是一种半满/半空的心态。但总体而言,CPU 核心的性能和效率的平衡比更接近 M3 的设计,总内存带宽也是如此。M3 Pro 应该仍然明显快于 M3,但在某些方面,它最终会在性能方面落后于 M2 Pro。
苹果对 M3 Pro 更为保守的立场也体现在其晶体管数量上。M3 Pro 上的晶体管数量实际上比 M2 一代有所减少——从 400 亿个减少到 370 亿个。因此,无论使用何种工艺节点,这总体上都是一个稍微简单的芯片。与 M1 Pro 相比,前两代晶体管数量仅略有增长 (~10%)。
至于为什么苹果不像其他 M3 SoC 那样加大 M3 Pro 的体积,目前还只能猜测。但从根本上讲,由于晶体管数量较少和芯片尺寸较小,M3 Pro 的生产成本应该比 M2 Pro 低得多。N3B 良率可能在这里发挥了作用(较低的良率等于较高的芯片有效成本),但只有台积电和苹果知道情况是否属实。
功耗也可能是一个因素,尤其是在 CPU 核心重新平衡时。8 个性能核心可提供出色的性能,但它们肯定会消耗大量电量。Max SoC 在某种程度上可以摆脱这个问题,因为它们是顶级芯片,也适用于高端台式机,并且面向台式机替代级笔记本电脑用户。但对于更多的移动 Mac 用户来说,苹果可能会通过抑制性能增长来降低功耗。
出于这些原因,看看审查基准的结果将会很有趣。虽然这不太可能是苹果公司会讲述的故事,但他们笔记本电脑的性能和功耗应该能够为他们讲述很多故事。
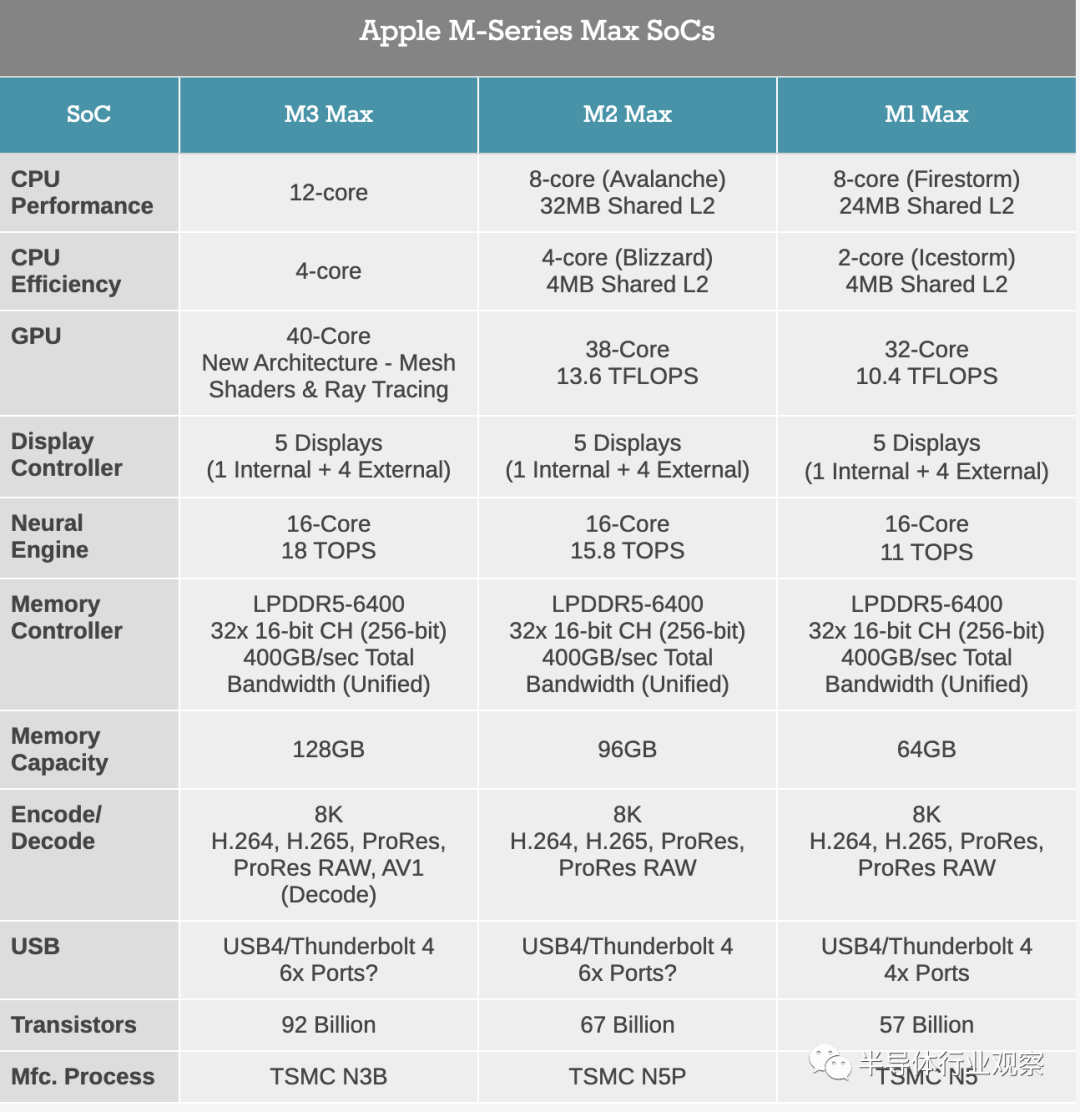
最后,我们拥有最大、最差的单片 M 系列芯片系列 Maxes。Max 芯片始终在核心数量和晶体管数量方面突破极限,与 M3 Pro 不同,M3 Max 延续了这一传统。
与前代 M2 相比,苹果在这里又增加了 4 个性能 CPU 核心,使其总数达到 12 个性能核心和 4 个效率核心。并使其成为唯一一款获得 CPU 核心性能提升的 M3 芯片。因此,这将是唯一一款 M3 芯片,至少在有利的散热条件下,多线程 CPU 性能应该会显著提高。尽管“有利的热条件”确实是那里的关键词,因为这是一个非常强大的冷却芯片。
在 GPU 方面,GPU 核心数量略有增加,从 M2 Max 上的 38 个核心增加到 M3 Max 上的 40 个核心。由于没有来自苹果公司的任何良好的性能数据,很难估计这在实践中会快多少。
为 M3 Max 提供与前两个版本芯片相同的 512 位 LPDDR5 内存总线。值得注意的是,这意味着苹果的可用内存带宽在过去两代中并未增加,无法跟上数量更多的 CPU 和 GPU 核心的需求,因此该公司需要从其芯片架构中获取更高的效率(和缓存命中率)以保持 SoC 的充足运行。
从苹果官方的芯片照片中,我们可以看到苹果再次使用他们定制的 x128 LPDDR5 内存芯片,从而使他们能够仅在 4 个芯片上连接 512 位内存总线。这一代的最大内存容量已达到 128GB,这对这些内存芯片中使用的芯片具有有趣的影响。除非苹果正在做一些真正疯狂的事情,否则获得 128GB LPDDR5 的唯一方法就是使用 32Gbit LPDDR5 芯片(总共 32 个)。我不知道目前有谁提供这种容量的芯片,所以苹果似乎已经从提供它的任何人那里获得了对该内存的优先使用权。对于其他所有人来说,我们应该会在明年晚些时候在 Windows 笔记本电脑上看到 128GB LPDDR5(X) 配置。
随着CPU核心、GPU核心的增加,以及芯片各个构建模块复杂性的普遍增加,M3 Max的晶体管总数已激增至920亿个晶体管。这比 M2 Max 多了 37% 的晶体管,甚至比基于台积电 N4 工艺构建的 NVIDIA 大型 GH100 服务器 GPU 多了 15%(120 亿)。N3B 构建的 M3 Max 应该要小得多(小于 400mm²?),但按照笔记本电脑标准,这仍然是一个巨大的芯片,更不用说如果苹果将其中两个放在一起进行 Ultra 配置时会发生什么。无论苹果为这些芯片向台积电支付多少钱,它都不会便宜——但是有多少其他供应商正在设计比大多数服务器芯片晶体管数量更多的笔记本电脑 SoC?
编辑:黄飞
-
M3芯片和i7处理器的区别2024-03-11 6223
-
苹果M3芯片和英特尔酷睿i9处理器哪个强2024-03-08 9440
-
Cortex™-M3处理器介绍2023-09-04 854
-
m3芯片和m2芯片参数对比2023-08-16 19243
-
cortex m3/m4处理器的复位设计资料分享2022-02-07 1926
-
ARM Cortex M3处理器的总线接口2021-12-14 1392
-
cortex m3/m4处理器的复位设计2021-12-04 1310
-
Cortex™-M3处理器2021-08-11 1845
-
Cortex M3内核概述2021-07-26 2051
-
苹果M2处理器曝光:性能更强 精选资料分享2021-07-23 3774
-
Cortex-M3处理器是什么2021-07-16 1982
-
M3处理器的详细原理图资料免费下载2018-09-26 2097
-
基于Cortex-M3处理器的开关磁阻电机控制器设计2017-09-29 1275
-
高性能低成本Cortex-M3处理器2016-01-22 972
全部0条评论

快来发表一下你的评论吧 !
