

如何看待处理器中的专业化与通用化
处理器/DSP
描述
学术界多年来一直在关注专业化,但解决方案被拒绝,因为通用解决方案发展得足够快,无法满足大多数应用程序的需求。情况不再是这样了。RISC-V处理器架构的引入和支持吸引了很多关注,但对于大多数现代计算来说,这是否是正确的方向可能会随着时间的推移而改变。
随着时间的推移,关于是专业化还是通用化的架构问题有了不同的答案,这导致了20世纪90年代被称为牧本波。Tsugio Makimoto当时是索尼的首席技术官。

图1:牧本的波。来源:半导体工程
DAC每年隐藏的瑰宝之一是IEEE CEDA杰出演讲人午餐会。今年的演讲题为“边缘计算系统:专业化还是通用化”,由新加坡国立大学副教务长(学术事务)兼教务长计算机科学讲座教授Tulika Mitra主讲。
以下是Mitra演讲的浓缩版,集中讨论了边缘物联网设备的专业化与通用化问题。
“我在这里带你经历特殊化和普遍化之间的辩论,”米特拉说。“她演讲的第一部分简要介绍了从大规模集成电路时代开始的Makimoto浪潮的早期阶段之后的半导体行业历史。”他们吹嘘将22个元件集成到一个集成电路上。第一批集成电路非常专业化。它们是特定于应用的。“
当英特尔在1971年推出4004处理器时,情况发生了变化。“按照今天的标准,这是一个非常简单的设计,只有2300个晶体管。但它是第一个使用冯·诺依曼建筑和存储指令的概念。从这个意义上说,它是革命性的,因为它允许你有一个可以重复使用的电路来执行不同的算法。随着这一点,行业进入了通用化领域,我们有一个固定的指令集架构来确定硬件设计人员和软件开发人员之间的合同。它提供了高度的可编程性,并且支持多种应用。”
这些架构的问题是,它们花费大量精力提取并行性,而不执行有用的计算。“到2005年,我们结束了频率缩放,因为登纳德标度。单核优化不再可行,行业转向多核和众核架构。问题是软件设计没有跟上这种并行。“
即使这些架构也有局限性。“阿姆达尔定律表明,即使您可以并行化99%的应用,也只能获得100倍的最大加速,无论您使用多少个处理器。今天,我们也走到了路的尽头摩尔定律,所以我们被迫回到专门的领域。”
她的演讲着眼于一些正在引入的加速器,包括谷歌张量处理单元和达尔文基因组处理器。“如果你看看GPU,它是一个大规模的并行架构。这些东西实际上是为特定领域设计的。因为它们具有大规模并行性,所以您可以获得非常高的性能。但是因为你是为一个特定的领域设计的,所以硬件可以非常简单,功耗也可以很低。但同时也不容易编程。”
Mitra随后介绍了边缘计算的一些具体要求,包括需要在数据附近进行更多处理,而不是必须将数据传输到云。“这不仅效率低,而且依赖于可靠的连接,而可靠的连接并不总是有保证的。”
介绍了一个手指运动识别示例,并通过确定使用Arm Cortex M3处理器进行识别的功率和性能来设置基线。使用移动电话建立了另一个数据点。“虽然M3提供了低功耗解决方案,但速度不够快,而且手机对于边缘应用程序来说功耗太大。”
业界部署的一个常见解决方案是创建针对特定任务进行调整的自定义加速器。“加速器有很多,在边缘AI加速器方面出现了爆炸式增长。它们可以获得非常高的效率,可以达到每瓦3到4托普。还有其他加速器。例如,麻省理工学院有一个导航系统。但是你怎么能把它们结合在一起呢?”
她再次查看了现有的商业系统,指出了加速器的数量和处理器的大小。“如果我看着蒂尼物联网拥有几个特定领域加速器和多个通用内核的边缘设备是不可行的。“
专业化的时代
任务有一些属性使它们适合专业化。“应用程序必须具有并行性。您需要定期执行计算。并且计算必须具有内存局部性。但是专业化也有缺点。考虑到设计成本,你最好有足够的量来摊销成本。不是所有的应用都可以的。虽然专业化可能有助于一些应用程序,但也会使其他应用程序受到影响。”
专业化和通用化之间有一个权衡。“在X轴上(见图2),您可以看到与通用处理器相比,专业化带来的速度提升。Y轴代表生产量。它显示了为了从专业化中获益你必须生产的芯片数量。浅蓝色区域是我们大多数人的目标。您将从通用处理器中获得大量性能提升。这就是为什么你在一段时间内没有看到专业化,因为你需要从专业化中获得高速度或非常高的产量。但是现在,我们正处于后摩尔时代,在这个时代,我们并没有从通用微处理器中获得太多的好处。更多的应用程序将从专业化中受益。但即便如此,你也有一部分人根本没有从专业化中受益。”
图2:专业化的经济学。资料来源:tuli ka Mitra/发援会
一种方法是使用增量专业化。“你从一个通用处理器开始,然后通过定制指令添加一点特定的功能。这需要一个循环操作,并把它变成一个自定义指令。这是20年前的一个热门话题,人们关注的是如何获取一个应用程序并找到所有的专业。今天,对于RISC-V处理器,我们有定制的指令集扩展,您可以在其中添加这些指令。你可以创建一个图书馆,你可以拥有这些微型加速器。”
但是,您能为众核和多核架构定制这些处理器吗?“我们的想法是让处理器尽可能简单,然后给每个处理器添加一条定制指令。我们还试图将定制指令分段,并将它们分布在多个处理器上,然后将它们缝合在一起。从某种意义上说,我们是成功的,因为我们能够满足我们所关注的各种应用程序的实时要求。我们现在可以做手指手势识别。但是在139兆瓦,这并不完全是我们所希望的。其中一个原因是处理器仍然会消耗大量的能量。”
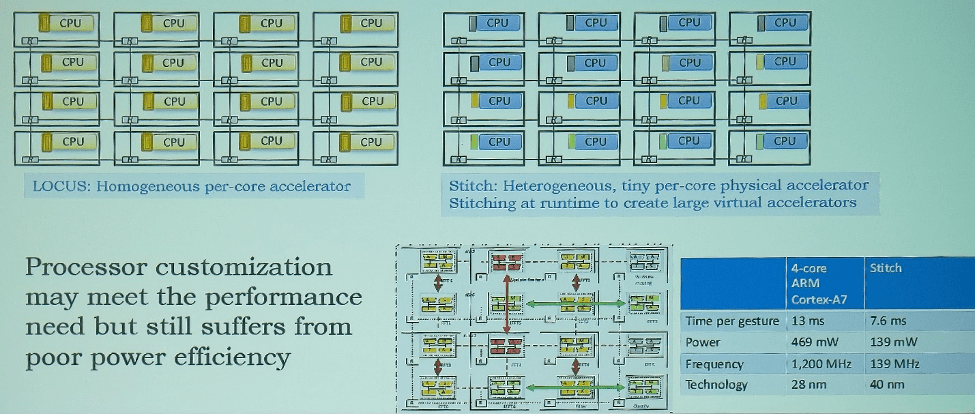
图三。众核处理器定制。资料来源:tuli ka Mitra/发援会
万能加速器
就像冯·诺依曼机器一样,Mitra正在寻找一个可以运行任何算法的加速器。如果可能的话,NRE成本可以分摊到多个应用中,并且仍然能够满足性能和功耗目标。“你必须让硬件尽可能简单,否则它会消耗很多能量。所以你把复杂性推给了软件。这意味着软件需要知道硬件中发生了什么。你只暴露指令集架构的接口是不够的。你需要向软件公开底层架构。”
一种方法是从本质上是顺序的计算模型转移到提供异步并行的数据流计算模型。“在这个模型中,您以数据流图的形式展示了整个计算,这展示了操作之间的依赖性和并行性。你把整个数据流图映射到硬件上,然后让它执行。你不需要提取排比。”
第一个数据流处理器在1975年被描述。它没有被广泛采用,因为通用处理器做得很好。软件堆栈也存在问题。“今天,AI加速器遵循这种数据流计算模型。然而,硬件是为特定的数据流而实例化的。我们想看看相同的硬件是否支持不同的数据流,这就是软件定义的硬件的想法。您希望软件在同一硬件上实例化对应于不同应用程序的不同数据流。然后你就得到一个万能加速器。”
一种方法是使用粗粒度可重构阵列(CGRAs)。这种例子在2000年左右首次出现。今天,许多公司的投资组合中都有CGRA,包括三星、英特尔和瑞萨。
CGRA是处理元素的2D阵列,其中每个处理元素都有一个非常简单的ALU,并将北、南、东、西连接到四个邻居。“这种体系结构的有趣之处在于,您可以改变特定PE在每个周期执行的操作。您可以重新配置网络来执行不同的路由。你有强大的逐周期重构能力。软件发送这些存储在内存中的配置数据,但由于配置内存有限,这意味着您只能映射那些需要经常计算的内容。”
图4:CGRA–可编程的效率。资料来源:tuli ka Mitra/发援会
“TPU专门处理矩阵乘法的数据流。但是有了CGRA,你可以给它任何数据流,软件会在那个架构上实例化同样的东西。这样做的好处是它可以进行语音识别、FFT、矩阵乘法和卷积运算。所有这些数据流都可以映射到CGRA上,我们可以获得非常好的效率和性能。”
挑战在于在CGRA上进行数据流合成。“这与布局布线非常相似。我们希望获得数据流图,并将其映射到PE上。因此,您需要进行布局,然后路由依赖关系,即从一个PE到另一个PE的连接。有趣的是,这不仅仅是一个空间映射,而是一个时空映射。利用时空映射,一个PE在一个周期中执行该操作,并且在下一个周期中执行不同的操作。同样,所有的路由都是不同的。这给了它很大的能力,并且不局限于一次一个迭代。实际上,您可以使用软件流水线技术并行处理多个操作。”
Mitra讨论了CGRA和现场可编程门阵列。她指出了两个主要区别。第一个涉及一个抽象,其中FPGA处于位级,而CGRA处于操作级。第二是CGRA的时间可重构性。
新加坡国立大学于2019年制作了第一个名为HyCUBE的CGRA。与处理器、FPGAs和三星可重构处理器相比,它具有令人印象深刻的性能特征。该大学后来发布了一个更大的CGRA,也增加了一个基于RISC-V的控制器和其他一些架构上的进步。“它是目前CGRAs中效率最高的0.45V时每瓦582 GOPS,我们使用的是40纳米超低功耗工艺。我们的大多数竞争对手都在使用22纳米工艺,我们估计该技术的性能将达到1 TOPS/W。”
复杂性在于软件。“CGRAs我们过去不成功,因为我们没有软件工具链。空间加速器使用布局和布线试探法。这些路由试探法依赖于您使用的加速器,因此您需要手工制作编译器。这需要很多时间,并且布局布线做出非常局部的决定。它们可能不是整个系统的最佳选择。所以我们想知道机器学习技术是否可以为新的CGRA自动生成编译器。”
这导致了LISA的诞生,一个自动化的编译器生成器。“我们创建了许多合成数据流图(DFG ),并使用它们来创建一组训练数据。一旦你有了一个新的CGRA,我们建立一个图神经网络模型,试图从这个图中估计某些属性,如调度顺序,以及两个DFG节点之间的空间和时间距离。然后,当你有一个新的数据流图,你生成标签,通知我们的模拟退火为基础的映射方法。这为我们提供了一个非常可移植的编译器,在不同的加速器集上以创纪录的速度实现了非常高质量的映射。”
最初的结果需要很长的编译时间,所以使用了几种技术来加速。这包括抽象、公共重用模式和集群。整个事情已经被打包成一个开源的CGRA工具链,如图5所示。
图5: NUS Morpher开源CGRA工具链。资料来源:tuli ka Mitra/发援会
“我们有这个抽象的架构模型,所以你可以建模任何架构,你可以有任何应用。它会将应用程序映射到您的架构上。它还允许您进行FPGA仿真。更重要的是,我们实际上有一个模拟和验证流程,这是最先进的CGRA工具所缺少的。”
然而,挑战依然存在。“嵌入式应用的很大一部分包括循环体内的控制发散。CGRAs不擅长这个。此外,CGRAs是高度并行的架构,你需要将大量数据引入系统。我们已经取得了一些进展,但我们还可以做得更多。我们试图在一个大项目的背景下进行研究,我们试图从应用到电路的所有环节开始开发下一代软件。”
审核编辑:黄飞
-
通用化自动测试系统技术2017-08-15 2113
-
防雷设计的专业化代表2013-05-07 2381
-
苏州回收西门子plc模块,专业化回收服务,触摸屏2020-02-11 793
-
基于协议栈的现场总线协议转换通用化设计2009-10-10 801
-
遥测前端设备通用化方案设计2010-06-25 813
-
什么是通用处理器2010-01-12 5375
-
审慎对待处理器选择2010-01-04 547
-
通用化测试系统技术2012-07-17 1876
-
中屏科技携领先的通用化功能测试系统及汽车钥匙标定测试系统亮相NEPCON China2015-03-05 1781
-
一种远程监控系统通用化5层架构2018-02-27 949
-
随着电动汽车产业化发展的加快 电动汽车即将迈向专业化发展趋势2019-04-24 1788
-
VM604系列振弦专业化读数模块2022-09-30 780
-
工程师说 | RX23E-A MCU实现传感器设备通用化的实例2023-02-04 1455
-
RX23E-A MCU实现传感器设备通用化的实例2023-03-05 1515
-
本田与索尼将推进纯电动车底盘通用化,应对市场挑战2024-07-09 1867
全部0条评论

快来发表一下你的评论吧 !
