

基于单一LLM的情感分析方法的局限性
描述
作者:wkk
就像人类在做一件事情的时候,可能需要尝试多次。LLM也是如此!这对于情感分析任务尤其如此,在情感分析任务中,LLM需要深入推理来处理输入中的复杂语言现象(例如,从句组成、反讽等),单个LLM生成的单回合输出可能无法提供完美的决策。
今天介绍的论文工作就上面提到的单一LLM框架在进行情感分析时的缺陷展开。

在博士毕业就有10篇ACL一作的师兄指导下是种什么体验
简介
LLM的发展为情感分析任务带来的新的解决方案。有研究人员使用LLM,在上下文学习(in-context learning, ICL)的范式下,仅使用少量的训练示例就能够实现与监督学习策略旗鼓相当的性能表现。
缺点:但是单个LLM产生的单轮输出可能无法提供完美的决策。针对情感分析任务,LLM通常需要阐明推理过程,以解决输入句子中的复杂语言现象。
创新:为了解决这个问题,本文提出了一种用于情感分析的多LLM协商策略。所提出的策略的核心是生成器-鉴别器框架,其中一个LLM充当生成器做出情感决策,而另一个充当鉴别器,任务是评估第一个LLM生成的输出的可信度。如下图所示。
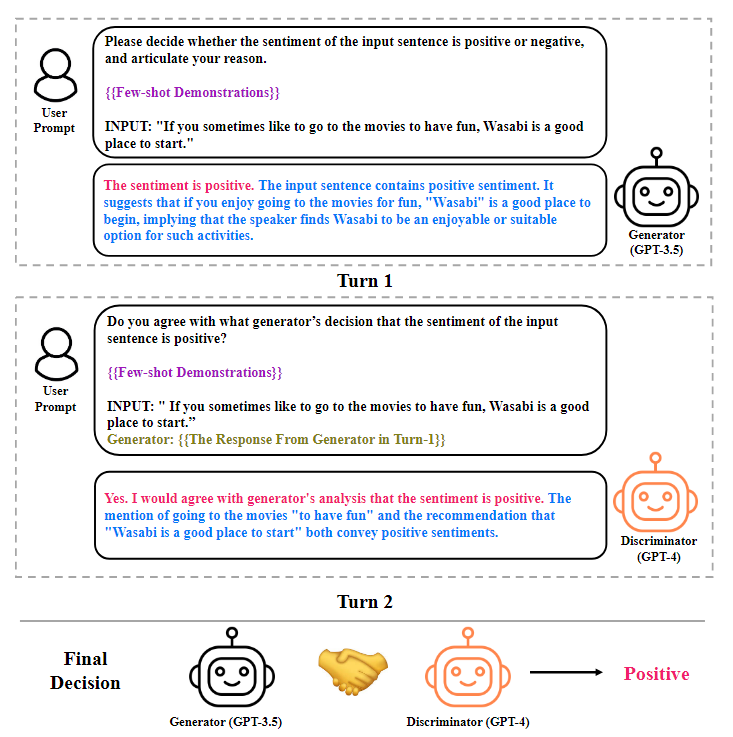
具体步骤:
推理生成器:一种LLM,它遵循结构化的推理链,增强生成器的ICL,同时为鉴别器提供评估其有效性的证据和见解;
推导鉴别器的解释;其他LLM,旨在为其判断提供评估后的理由;
协商:两个LLM充当生成器和鉴别器的角色,执行协商直到达成共识。
在情感分析基准上的实验表明,在所有基准中,所提出的算法始终比ICL基准产生更好的性能,甚至比Twitter和电影评论数据集上的监督基线更出色的性能。
相关工作
情感分析
情感分析是自然语言处理的热门研究方向之一。其研究方法和思路由早期的“序列模型+分类器”演化到ICL,并逐渐成为一种新的NLP任务范式。研究人员发现在二分类的情感分析中,ICL取得了出色的性能。然而在一些更加复杂的任务(如方面级情感分析)中,ICL的表现不如监督基线模型。
LLM and In-context Learning
LLM训练来自大规模的未标注语料库。LLM可以划分为三类:only Encoder,only Decoder and Encoder-Decoder模型。从GPT3.0开始,LLM通过ICL在许多自然语言处理任务中展现出了出色的性能。
LLM协作
LLM协作涉及多个LLM协同工作以解决给定任务。具体来说,任务被分解为几个中间任务,每个LLM被分配独立完成一个中间任务。给定的任务是在对这些中间结果进行集成或汇总后解决的。LLM协作方法可以利用LLM的能力,提高复杂任务的性能,并能够构建复杂的系统。
LLM情感分析协商
使用两个LLM充当答案生成器和鉴别器。将生成器和鉴别器之间的交互称为协商。协商将重复进行,直到达成共识或超过最大协商次数。图示如下图所示。

生成器
生成器由一个LLM扮演。通过提示询问基于ICL范式的答案生成器,旨在生成一个循序渐进的推理链,并对测试输入的情绪极性做出决定。提示由三个元素组成:任务描述、演示和测试输入。任务描述是用自然语言对任务的描述(如,“请确定测试输入的整体情感倾向。”);测试输入是测试集中的文本输入(例如,“天空是蓝色的”);演示是从训练中完成的任务。每一个都包含三个元素:输入、推理链和情感决策。对于每个测试输入,首先从训练集中检索K nearest邻居作为演示。然后,我们通过提示生成器生成推理链,将演示转换为(输入、推理过程、情绪决策)三元组。在连接任务描述、演示和测试输入后,将提示转发给生成器,生成器将以逐步推理链和情感决策作为响应。
鉴别器
鉴别器则是由另一个LLM扮演。在完成答案生成过程后,使用答案鉴别器来判断生成器所做的决定是否正确,并提供合理的解释。为了实现这个目标,首先为答案鉴别器构造提示。提示由四个元素组成:任务描述、演示、测试输入和来自答案生成器的响应。任务描述是一段用自然语言描述任务的文本(例如,“请确定决策是否正确。“)。每个演示由六个元素组成:(输入文本、推理链、情感决策、鉴别者态度、鉴别器解释、鉴别器决策)并且通过提示回答鉴别器提供为什么情绪决定对于输入文本是正确的解释来构造。然后使用构造提示询问鉴别器。答案鉴别器将用文本字符串进行响应,该文本字符串包含表示鉴别器是否同意生成器的态度(即,是,否)、解释鉴别器为什么同意/不同意生成器的解释,以及确定测试输入情绪的鉴别器决定。
Why Two LLMs but Not One?
本文工作为何使用两个不同的LLM分别扮演生成器和鉴别器的原因:
如果LLM由于错误的推理而作为生成器出错,它更有可能也会犯与鉴别器相同的错误,因为来自同一模型的生成器和鉴别器很可能会犯类似的理由;
通过使用两个独立的模型,能够利用这两个模型的互补能力。
角色转换
在两个LLM以协商结束后,要求它们转换角色并启动新的协商,其中第二个LLM充当生成器,第一个LLM用作鉴别器。同样,角色转换协商也会结束,直到达成共识或超过最大协商次数。当两次协商达成协议,并且他们的决定相同时,选择其中一个决定作为最终决定,因为它们是相同的。如果一个协商未能达成共识,而另一个协商达成决定,将从达成共识的协商中选择一个决定作为最终决定。然而,如果双方协商达成共识,但双方的决定不一致,将需要额外的LLM帮助。
引入第三个LLM
如果两次协商的决定不一致,将引入第三个LLM,并与上述两个LLM中的每一个进行协商和角色转换协商。随后,将得到6个协商结果,并对这些结果进行投票:将最频繁出现的决策作为输入测试的情感极性。
实验
实验选择GPT3.5和GPT4.0作为骨干,并且使用以下三种不同的ICL方法。
Vanilla ICL
Self-Negotiation
Negotiation with two LLMs
Dataset and methods
本文在六个数据集上进行实验,分别为:SST-2,Movie Review,Twitter,Yelp-Binary,Amazon-Binary和IMDB数据集。并选择了以下Baselines。
supervised methods:DRNN, RoBERTa, XLNet, UDA, BERTweet和EFL。
ICL methods:FLan-UL2, T5, ChatGPT, InstructGPT-3.5, IDS, GPT-4和Self-negotiation。
实验结果与分析
本文实验结果如下表所示:
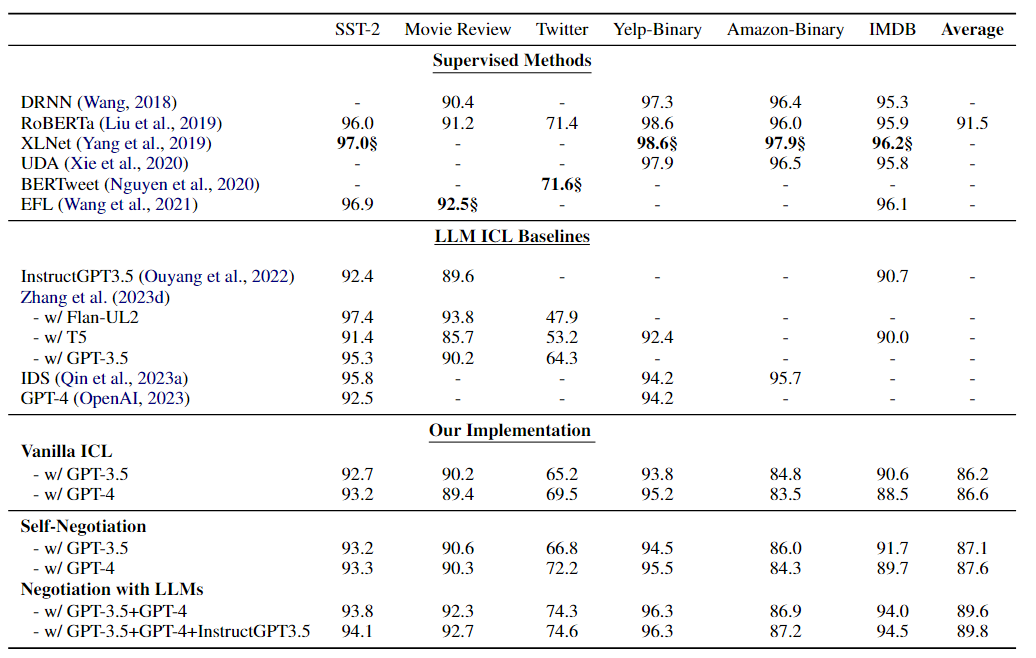
从表中可以看出,与普通ICL相比,使用一个LLM(Self-negotiation)遵循generate-discriminate范式在六个情绪分析数据集上获得了性能增益:GPT-3.5增益平均+0.9;GPT-4增益平均+1.0 acc。这种现象表明,LLM作为答案鉴别器,可以校正由任务生成器引起的一部分错误。
此外,与仅使用一个模型相比,使用两个不同的LLM作为任务生成器和鉴别器反过来又带来了显著的性能改进。在MR、Twitter和IMDB数据集上,使用两个LLM的协商在准确性方面分别优于Self-negotiation方法+1.7、+2.1和+2.3。出现这种现象的原因是,使用两个不同的LLM通过协商完成情感分析任务,可以利用对给定输入的不同理解,释放两个LLM的力量,从而做出更准确的决策。
还发现,当引入第三个LLM来解决转换角色协商之间的分歧时,可以获得额外的性能提升。这表明第三个LLM可以通过多次协商解决两个LLM之间的冲突,并提高情绪分析任务的性能。值得注意的是,多模型协商方法在MR数据集上比监督方法RoBERTa Large高出+0.9,并弥合了普通ICL与监督方法之间的差距:在SST-2上实现94.1(+1.4)的准确度;Twitter上92.1(+2.7);对Yelp-Binary为96.3(+2.5);Amazon-Binary的87.2(+3.7);在IMDB数据集上为94.5(+6.0)。
本文在Twitter数据集上的消融实验结果如下表所示:
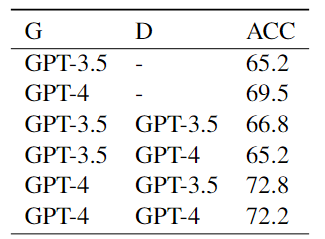
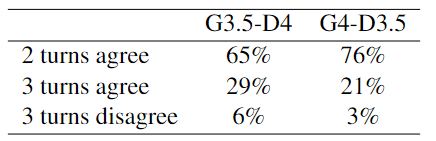
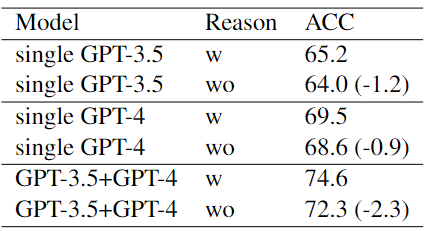
结果表明:
利用异构LLM扮演不同的角色可以优化协商的性能。
GPT-4的推理过程比3.5更明智,使前者的决策更有可能达成一致。
在协商过程中,LLM被要求阐明其推理原因过程具有重大的意义。
总结
在本文中,分析了基于单一LLM的情感分析方法的局限性,并引入了一种新的角色转换的多LLM协商方法,以提高情感分类的准确性和可解释性。在多个基准上的实验表明,与传统的ICL和许多监督方法相比,本文提出的方法具有优势。未来的工作可以探索优化速度和资源消耗的框架,使基本原则适应其他NLP任务,并设计明确的协商模块,以识别和减轻单个LLM中存在的偏见和解码错误的影响。
审核编辑:黄飞
-
34063的局限性2011-06-12 5373
-
FPGA的优势与局限性2017-12-20 7656
-
无线网络有什么局限性?2019-08-23 3383
-
MySQL优化之查询性能优化之查询优化器的局限性与提示2020-06-02 2137
-
超声波液位计的局限性及安装要求2020-06-19 1911
-
运算放大器的精度局限性是什么2021-03-11 2029
-
栅漏电流噪声有哪几种模型?这几种模型有什么局限性?2021-04-09 1514
-
贴片机转塔式结构的优缺点是什么?有什么局限性?2021-04-25 1639
-
基于FPGA的神经网络的性能评估及局限性2021-04-30 1767
-
RS-485自动换向电路设计的局限性2015-12-21 952
-
红外显微镜用于测量高性能微波GaN HEMT器件和MMIC的有什么局限性?2018-08-02 1277
-
WSN中LEACH协议局限性的分析与改进2021-09-15 1022
-
千兆光模块存在哪些局限性?2023-10-16 1599
-
碳化硅二极管的优点和局限性分析2023-12-21 5581
-
WDM技术的缺点和局限性2024-08-09 2703
全部0条评论

快来发表一下你的评论吧 !
