

马里兰&NYU合力解剖神经网络,CLIP模型神经元形似骷髅头
描述
【导读】神经网络黑盒怎么解释?马里兰大学和NYU研究人员开启了新的尝试。
AI黑盒如何才能解? 神经网络模型在训练的时,会有些ReLU节点「死亡」,也就是永远输出0,不再有用。 它们往往会被被删除或者忽略。 恰好赶上了模糊了生与死的界限的节日——万圣节,所以这是探索那些「死节点」的好时机。

对于大多数图像生成模型来说,会输出正面的图像。但是优化算法,可以让模型生成更多诡异、恐怖的图像。 就拿CLIP模型来说,可以衡量一段文本和一张图片的匹配程度。 给定一段描述怪诞场景的文本,使用优化算法通过最小化CLIP的损失,来生成一张与这段文本匹配的、吓人的图片。

当你不断探索损失函数的最深最恐怖的区域,就像进入了一个疯狂的状态。 就会发现这些诡异图片超乎想象。 最重要的是,它们仅仅是通过CLIP模型优化生成,并没有借助其他的模型。

优化算法,可以让我们对神经网络进行「解剖」,特征可视化(feature visualization)可以找到一个最大激活单个神经元的图像。 吴恩达和Jeff Dean曾在2012年就ImageNet图像分类模型上做过这样的实验,并发现了一个对黑色猫有响应的神经元。 对此,来自马里兰大学和NYU的研究人员使用「特征可视化」来剖析CLIP模型,发现了一个非常令人不安的神经元: 完全是一个类似骷髅头的图像。

但它真的是「骷髅头神经元」吗?显然不是,实际上它代表的是某种更加神秘、难以解释的模式。 究竟怎么回事?
模型反转,卷积网ViT不适用
想要解释AI生成的图像,需要用到的一种手段——模型反转(model inversion)。
「模型反转」是可视化和解释神经架构内部行为、理解模型学到的内容,以及解释模型行为的重要工具。 一般来说,「模型反转」通常寻找可以激活网络中某个特征的输入(即特征可视化),或者产生某个特定类别的高输出响应(即类别反转)。 然鹅,神经网络架构不断发展,为现有的「模型反转」方案带来了重大挑战。 卷积网长期以来,一直是CV任务的默认方法,也是模型反转领域研究的重点。 随着Vision Transformer(ViT)、MLP-Mixer、ResMLP等其他架构的出现,大多数现有的模型反转方法不能很好地应用到这些新结构上。

总而言之,当前需要研发可以应用到新结构上的模型反转方法。 对此,马里兰和NYU研究人员将关注点放在了「类反转」(class inversion)。 目标是,在不知道模型训练数据的情况下,找到可以最大化某个类别输出分数的可解释图像。 类反转已在模型解释、图像合成等任务中应用,但是存在几个关键缺陷:生成图像质量对正则化权重高度敏感;需要批标准化参数的方法不适用于新兴架构。 研究人员再此提出了基于数据增强的类反转方法——Plug-In Inversion(PII)。

论文地址:https://arxiv.org/pdf/2201.12961.pdf PII的好处在于不需要明确的正则化,因此不需要为每个模型或图像实例调节超参数。 实验结果证明,PII可以使用相同的架构无关方法和超参数反转CNN、ViT和MLP架构。
全新类反转——PII
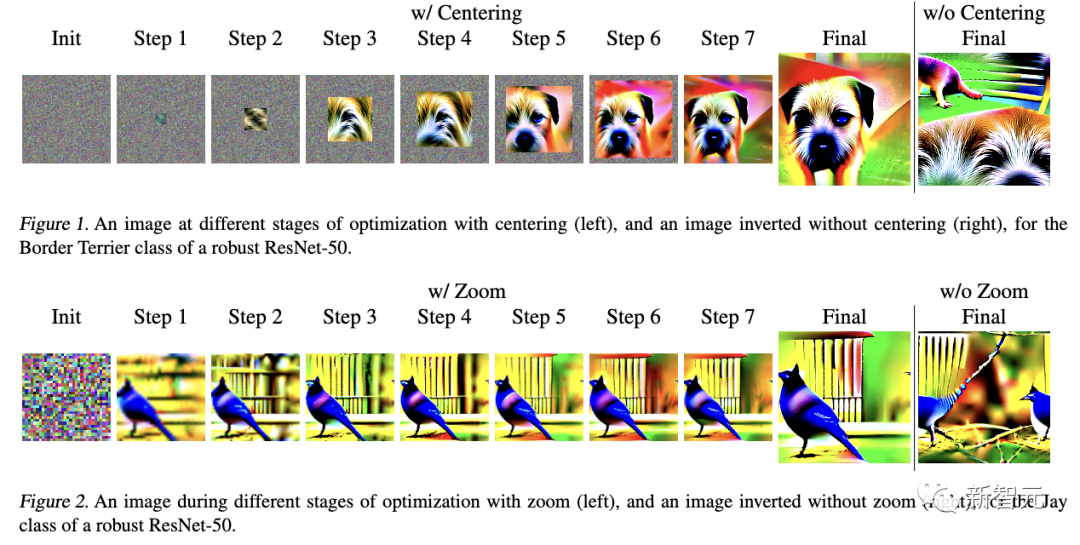
此前,关于类反转的研究,常常使用抖动之类的增强功能。 它会在水平和垂直方向上随机移动图像,以及水平Ips来提高反转图像的质量。 在最新研究中,作者探讨了有利于反转的其他增强,然后再描述如何将它们组合起来形成PII算法。限制搜索空间作者考虑2种增强方法来提高倒置图像的空间质量——居中(Centering)和缩放(Zoom)。 这些方法的设计基于这样的假设:限制输入优化空间,可以得到更好的特征布局。 两种方法都从小尺寸开始,逐步扩大空间,迫使放置语义内容在中心,目的是生成更具解释性和可识别性的反转图像。 图1和图2分别显示了,居中和缩放过程中每个步骤测图像状态。
ColorShift增强之前展示的反转图像,颜色看起来很不自然。 这是由于研究人员现在提出的一种全新增强方法——ColorShift造成的。 ColorShift是随机扰动每个颜色通道的平均值和方差,改变图像颜色,目的是生成更丰富多样的反转图像颜色。 下图,作者可视化了ColorShift的稳定效果。

集成集成是一种成熟的工具,经常用于从增强推理到数据集安全等应用程序。 研究人员发现,优化由同一图像的不同ColorShift组成的整体,可以同时提高反转方法的性能。 图4显示了与ColorShift一起应用集成的结果。 可以观察,到较大的集成似乎给出了轻微的改进,但即使是大小为1或2的集成,也能产生令人满意的结果。 这对于像ViT这样的模型很重要,因为可用的GPU内存限制了该集合的可能大小。

到这里,你就明白什么是PII了,即结合了抖动、集成、ColorShift、居中和缩放技术,并将结果命名为「插件反转」。 它可以应用到任何可微分模型(包括ViT和MLP),只需要一组固定超参数。
多种网络架构适用
那么,PII效果究竟如何? 实验结果发现,PII可以应用于不同的模型。需要强调是的是,研究者在所有情况下都对PII参数使用相同的设置。 图6中,描绘了通过反转各种架构的Volcano类生成的图像,包括CNN、ViT和MLP的示例。

虽然不同神经网络的图像质量有所不同,但它们都包含可区分,且位置恰当的视觉信息。 在图7中,研究人员还显示了PII从几个任意ImageNet类的每种主要架构类型的代表生成的图像。 可以看到,每行有独特视觉风格,说明模型反转可以用来理解不同模型的学习信息。

在图8中,作者使用PII来反转在ImageNet上训练,并在CIFAR-100上进行微调的ViT模型。

图9显示了在CIFAR-10上微调的模型的反转结果。

为了定量评估全新方法,作者反转预训练的ViT模型和预训练的ResMLP模型,使用PII为每个类生成一张图像,并使用DeepDream执行相同的操作。 然后使用各种预训练的模型对这些图像进行分类。 表1包含这些模型的平均top-1和top-5分类精度,以及每种方法生成的图像的初始分数。

图10显示了PII和DeepInversion生成的一些任意类别的图像。

-
脉冲神经元模型的硬件实现2025-10-24 349
-
rnn是什么神经网络模型2024-07-05 2353
-
人工神经网络模型是一种什么模型2024-07-04 2878
-
神经网络模型的原理、类型、应用场景及优缺点2024-07-02 4535
-
神经元与神经网络的区别与联系2024-07-01 3286
-
卷积神经网络模型发展及应用2022-08-02 13410
-
基于BP神经网络的PID控制2021-09-07 2770
-
有关脉冲神经网络的基本知识2021-07-26 1192
-
神经网络与神经网络控制的学习课件免费下载2021-01-20 1860
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 3425
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 3999
-
人工神经网络算法的学习方法与应用实例(pdf彩版)2018-10-23 9658
-
神经网络教程(李亚非)2012-03-20 58625
全部0条评论

快来发表一下你的评论吧 !
