

深度探索AI微控制器对CNN的硬件转换方案
人工智能
描述
人工智能应用需要大量的能源消耗,通常以服务器群或昂贵的现场可编程门阵列(FPGA)的形式出现。挑战在于提高计算能力,同时保持较低的能耗和成本。现在,人工智能应用正在经历由强大的智能边缘计算实现的巨大转变。与传统的基于固件的计算相比,基于硬件的卷积神经网络加速现在以其令人印象深刻的速度和功能开创了计算性能的新时代。通过使传感器节点能够做出自己的决策,智能边缘技术大大降低了 5G 和 Wi-Fi 网络上的数据传输速率。这为以前不可能实现的新兴技术和独特应用提供了动力。例如,远程位置的烟雾/火灾探测器或传感器级别的环境数据分析成为现实,所有这些都需要使用电池电源多年。为了研究这些功能是如何实现的,本文探讨了使用专用 AI 微控制器对 CNN 进行硬件转换。
具有超低功耗卷积神经网络加速器的人工智能微控制器
MAX78000是一款具有超低功耗CNN加速器的AI微控制器,这是一种先进的片上系统。它能够以超低功耗为资源受限的边缘设备或物联网应用提供神经网络。此类应用包括物体检测和分类、音频处理、声音分类、降噪、面部识别、用于心率/健康信号分析的时间序列数据处理、多传感器分析和预测性维护。
图 1 显示了该MAX78000的框图,该器件由带有浮点单元的 Arm Cortex-M100F 内核提供高达 4 MHz 的电源。为了给应用提供足够的内存资源,此版本的微控制器配备了 512 kB 闪存和 128 kB SRAM。该器件包括多个外部接口,如I²C、SPI和UART,以及I²S,这些接口对于音频应用非常重要。此外,还集成了一个 60 MHz RISC-V 内核。RISC-V将数据从各个外设模块和存储器(闪存和SRAM)复制到/复制到各个外设模块和存储器,使其成为智能直接存储器访问(DMA)引擎。RISC-V 内核为 AI 加速器预处理传感器数据,因此 Arm 内核在此期间可以处于深度睡眠模式。如有必要,推理结果可以通过中断触发 Arm 内核,然后 Arm CPU 在主应用程序中执行操作,以无线方式传递传感器数据或通知用户。®®
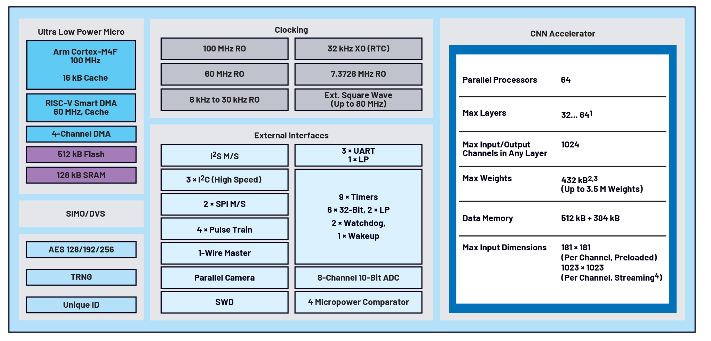
.A MAX78000模块原理图。
MAX7800x系列微控制器具有独特的功能,用于卷积神经网络的推理,有别于标准微控制器架构和外设。该硬件加速器可以支持完整的 CNN 模型架构以及所有必需的参数(权重和偏差)。CNN 加速器配备 64 个并行处理器和一个集成存储器,其中 442 kB 用于存储参数,896 kB 用于输入数据。由于模型和参数存储在SRAM存储器中,因此可以通过固件进行调整,并且可以实时调整网络。根据模型中使用的是 1 位、2 位、4 位还是 8 位权重,此内存足以容纳多达 3 万个参数。由于存储器功能是加速器不可或缺的一部分,因此每次连续的数学运算都不必通过微控制器总线结构获取参数。由于高延迟和高功耗,此活动成本高昂。神经网络加速器可以支持 5 或 32 层,具体取决于池化功能。每层可编程图像输入/输出尺寸高达 64 × 1024 像素。
CNN 硬件转换:能耗和推理速度比较
CNN 推理是一项复杂的计算任务,由矩阵形式的大型线性方程组成。利用 Arm Cortex-M4F 微控制器的强大功能,可以对嵌入式系统的固件进行 CNN 推理;但是,有一些缺点需要考虑。在微控制器上运行基于固件的推理时,需要从内存中检索计算所需的命令以及相关的参数数据,然后才能写回中间结果,因此会消耗大量能源和时间。
表 1 比较了使用三种不同解决方案的 CNN 推理速度和能耗。此示例模型是使用 MNIST 开发的,MNIST 是一种手写数字识别训练集,它对视觉输入数据中的数字和字母进行分类,以得出准确的输出结果。测量每种处理器类型所需的推理时间,以确定能耗和速度之间的差异。
表 1.利用MNIST数据集进行手写数字识别的三种不同场景的CNN推理时间和每次推理的能量
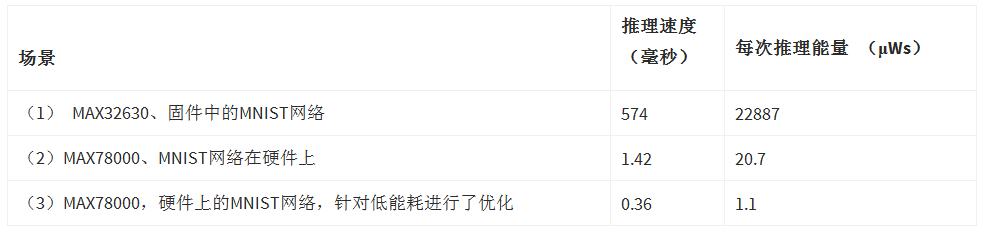
在第一种场景中,集成在MAX4中的 Arm Cortex-M32630F 处理器(运行频率为 96 MHz)用于计算推理。在第二个场景中,为了处理计算,使用了MAX78000基于硬件的CNN加速器。当使用带有基于硬件的加速器 (MAX400) 的微控制器时,推理速度(即在网络输入和结果输出时呈现视觉数据之间的时间)会降低 78000 倍。此外,每次推理所需的能量要低 1100 倍。在第三次比较中,MNIST网络经过优化,每次推理的能耗最小。在这种情况下,结果的准确度从 99.6% 下降到 95.6%。但是,该网络的速度要快得多,每次推理只需要 0.36 毫秒。每次推理的能耗降低到仅 1.1 μWs。在使用两节 AA 碱性电池(总能量为 6 Wh)的应用中,可以进行 《》 万次推断(省略电路其余部分消耗的功率)。
这些数据说明了硬件加速计算的强大功能。硬件加速计算对于无法利用连接或持续电源的应用来说是一种非常宝贵的工具。该MAX78000支持边缘处理,无需大量能源、宽带互联网接入或延长推理时间。
MAX78000 AI 微控制器的示例用例
该MAX78000支持多种潜在应用,但让我们以以下用例为例。要求是设计一个电池供电的摄像头,该摄像头可以检测猫何时在其图像传感器的视野中,从而能够通过猫门的数字输出进入房屋。
图 2 描绘了此类设计的示例框图。在这种情况下,RISC-V内核会定期打开图像传感器,并将图像数据加载到由MAX78000供电的CNN中。如果猫识别的概率高于先前定义的阈值,则启用猫门。然后系统返回待机模式。
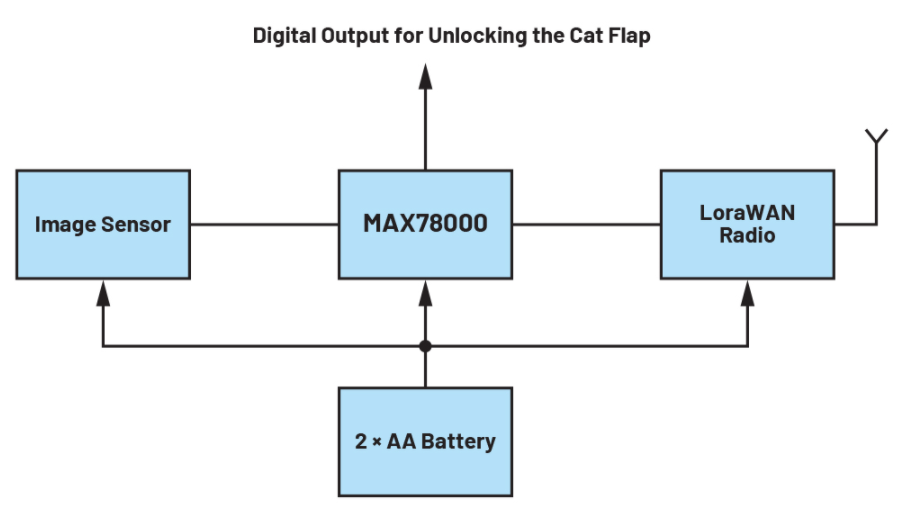
图2.智能宠物门的框图。
开发环境和评估套件
开发边缘 AI 应用程序的过程可分为以下几个阶段:
第 1 阶段:人工智能——网络的定义、训练和量化
第 2 阶段:Arm 固件 – 将第 1 阶段生成的网络和参数包含在 C/C++ 应用程序中,并创建和测试应用程序固件
开发过程的第一部分涉及对 AI 模型进行建模、训练和评估。在此阶段,开发人员可以利用 PyTorch 和 TensorFlow 等开源工具。GitHub 存储库提供了全面的资源,可帮助用户规划使用 PyTorch 开发环境构建和训练 AI 网络的旅程,同时考虑MAX78000的硬件规格。存储库中包含一些简单的 AI 网络和应用程序,例如面部识别 (Face ID)。
图 3 显示了 PyTorch 中的典型 AI 开发过程。首先,对网络进行建模。必须注意的是,并非所有MAX7800x微控制器的硬件都支持PyTorch环境中的所有数据操作。因此,ADI公司提供的文件 ai8x.py 必须首先包含在项目中。此文件包含使用MAX78000所需的 PyTorch 模块和运算符。基于此设置,可以构建网络,然后使用训练数据进行训练、评估和量化。此步骤的结果是一个检查点文件,其中包含最终合成过程的输入数据。在最后的流程步骤中,网络及其参数被转换为适合硬件 CNN 加速器的形式。这里应该提到的是,网络训练可以在任何PC(笔记本电脑、服务器等)上完成。但是,如果没有 CUDA 显卡支持,这可能需要花费大量时间——即使对于小型网络,几天甚至几周也是完全现实的。
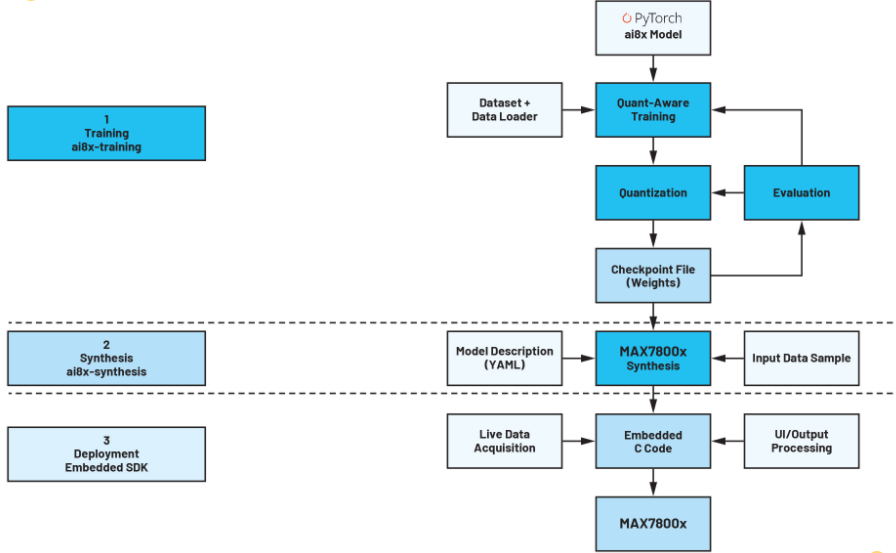
3.AI 开发过程。
在开发过程的第 2 阶段,使用将数据写入 CNN 加速器并读取结果的机制创建应用程序固件。在第一阶段创建的文件通过 #include 指令集成到 C/C++ 项目中。Eclipse IDE 和 GNU 工具链等开源工具也用于微控制器的开发环境。ADI公司提供软件开发套件(Maxim Micros SDK (Windows))作为安装程序,已包含所有必要的元件和配置。软件开发套件还包含外设驱动程序以及示例和说明,以简化应用程序开发过程。
一旦项目被编译和链接而没有任何错误,就可以在目标硬件上对其进行评估。为此,ADI公司开发了两种不同的硬件平台。图 4 显示了MAX78000EVKIT,图 5 显示了 MAX78000FTHR,这是一个稍小的羽毛外形板。每个板都配有一个 VGA 摄像头和一个麦克风。

图4.MAX78000评估套件。

图5.MAX78000FTHR评估套件。
结论
以前,人工智能应用需要以服务器群或昂贵的FPGA的形式消耗大量能源。现在,借助具有专用 CNN 加速器的 MAX78000 系列微控制器,可以使用单个电池长时间为 AI 应用供电。这一在能源效率和功耗方面的突破使边缘人工智能比以往任何时候都更容易获得,并释放了以前不可能实现的令人兴奋的新的边缘人工智能应用的潜力。
审核编辑:黄飞
-
MAX7800X AI 微控制器开发人员资源2025-05-14 1792
-
微控制器的开发方案2010-05-04 1247
-
微控制器中各式各样的编程语言2022-05-19 3803
-
UM2271_板载STM32L4R9AI微控制器的探索板2022-11-22 609
-
如何采用带专用CNN加速器的AI微控制器实现CNN的硬件转换2023-05-16 2479
-
基于AI微控制器的CNN的硬件转换2023-09-29 2262
-
新唐科技宣布推出基于微控制器的终端AI平台,加速AI应用普及2024-04-23 1933
-
ADI 新型AI微控制器 # MAX78000 数据手册和芯片介绍2025-02-08 2042
-
Analog Devices / Maxim Integrated MAX78002人工智能微控制器数据手册2025-06-18 1098
-
深度剖析Microchip PIC16F870/871微控制器:硬件特性与应用指南2026-03-19 1322
-
探索DS80C310高速微控制器:性能与应用深度解析2026-03-24 312
-
探索AT91FR40162:高性能ARM微控制器的深度剖析2026-04-06 765
-
深度剖析Microchip PIC16F62X系列微控制器:硬件设计与应用指南2026-04-07 675
-
探索MAXQ1050:深度安全保障的USB微控制器2026-04-08 271
-
探索MCF523x系列微控制器:硬件设计与应用的深度剖析2026-04-09 356
全部0条评论

快来发表一下你的评论吧 !
