

Google的第五代TPU,推理性能提升2.5倍
处理器/DSP
描述
在Cloud Next 2023 大会上,公开了Google Cloud新款自研AI芯片TPU v5e,并推出了搭配英伟达(NVIDIA)H100 GPU的 “A3超级计算机”GA(通用版) ,谷歌还宣布与AI芯片龙头英伟达扩大合作伙伴关系。
第五代TPU:训练性能提高2倍,推理性能提升2.5倍,成本降低50%!
TPU是谷歌专门为机器学习(ML)/深度学习(DL)设计的专用AI加速芯片,比CPU、GPU等通用处理器对于AI计算效率更高。谷歌第一代 TPU(TPU v1)是 2016 年在 Google I/O 大会上发布的,随后在2017 年作为 Google Cloud 基础设施“Cloud TPU”推出,通常使用 FP32 和 FP16 等精度数据,如果降低 ML 的精度/DL计算到8位(INT8)等,则将使得在ML/DL中的处理能力得到进一步提高。此外,通过仅合并专门用于 ML/DL 的算术单元,谷歌减少了 CPU 和 GPU 所需的高速缓存、分支预测和乱序执行等复杂算术单元,可以以低功耗执行专门针对 ML/DL 的计算。
之后,谷歌TPU又经过了数次迭代,比如第二代TPU v2于2017年发布,第三代TPU v3于2018年发布,第四代TPU v4于去年发布,目前已开始服务和提供。
而最新的第五代TPU,即TPU v5e 则是谷歌专为提升大中型模型的训练、推理性能以及成本效益所设计,并且其内部张量处理单元的最新版本。与与 2021 年发布的 TPU v4 相比,TPU v5e 的大型语言模型提供的训练性能提高了 2 倍、推理性能提高了2.5 倍。但是TPU v5e 的成本却不到上一代的一半,使企业能够以更低的成本,训练和部署更大、更复杂的 AI 模型。
需要指出的是,从第三代TPU v3开始,谷歌就专注于增强可扩展性,以便能够更大规模地并行处理。最新的TPU v5e ,可以通过采用400 TB/s互连来配置多达256个芯片。使得进行更大规模的学习和推理成为可能。谷歌表示,在 256 个芯片配置下,INT8 的算力将达到 100 PetaOps。
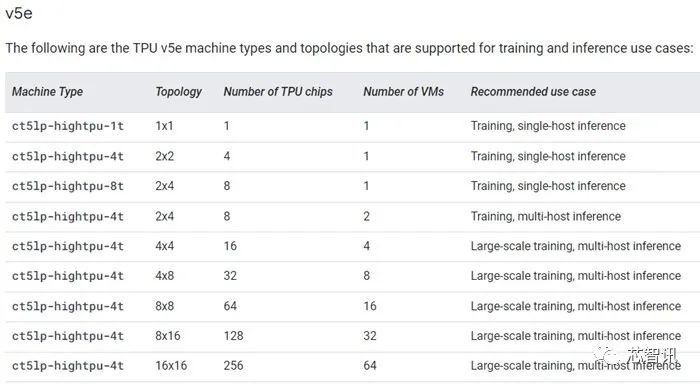
据介绍,TPU v5e将提供了多种不同的虚拟机配置,范围从一个 TPU 芯片到单个切片内 256 个 TPU 芯片。对于那些需要更多算力的用户,谷歌也正在推出“Multislice”,这是一种将模型交给数万个TPU芯片计算的服务。
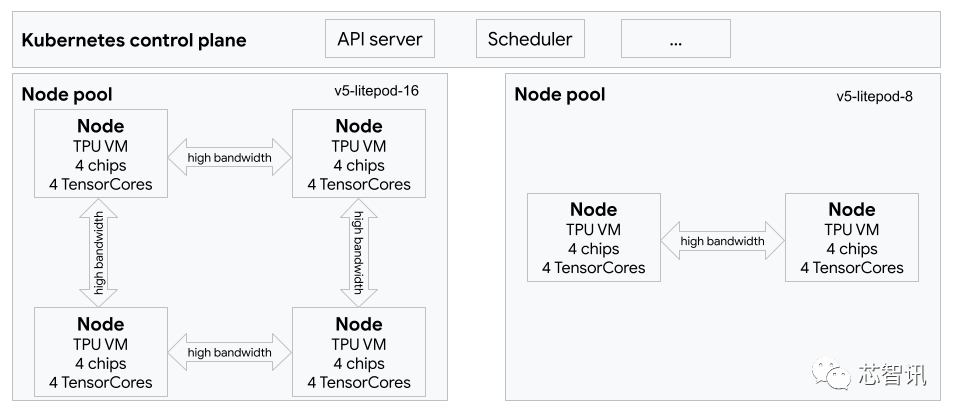 上图显示了一个包含 1 个 TPU (v5e) 切片(拓扑:4x4)和 1 个 TPU v5litepod-8(v5e) 切片(拓扑:2x4)的GKE 集群
上图显示了一个包含 1 个 TPU (v5e) 切片(拓扑:4x4)和 1 个 TPU v5litepod-8(v5e) 切片(拓扑:2x4)的GKE 集群
谷歌机器学习、系统和云AI 副总裁 Amin Vahdat 表示:“到目前为止,使用 TPU 的训练作业仅限于单个 TPU 芯片切片,TPU v4 的最大作业切片大小为 3,072 个芯片。”
谷歌计算和机器学习基础设施副总裁 Mark Lohmeyer在联合博客文章中表示,“借助 Multislice,开发人员可以在单个 Pod 内通过芯片间互连 (ICI) 或通过数据中心网络 (DCN) 跨多个 Pod 将工作负载扩展到数万个芯片。”
AssemblyAI 技术副总裁Domenic Donato表示:“在我们的生产 ASR 模型上运行推理时,TPU v5e 的性价比始终比市场上同类解决方案高出 4 倍。Google Cloud 软件堆栈非常适合生产 AI 工作负载,我们能够充分利用 TPU v5e 硬件,该硬件专为运行高级深度学习模型而构建。这种强大的硬件和软件组合极大地提高了我们为客户提供经济高效的人工智能解决方案的能力。”
Gridspace 机器学习主管Wonkyum Lee表示:“我们的速度基准测试表明,在 Google Cloud TPU v5e 上训练和运行时,AI 模型的速度提高了 5 倍。我们还看到推理指标的规模有了巨大改进,我们现在可以在一秒内实时处理 1000 秒的内部语音到文本和情绪预测模型,性能提高了 6 倍。”
与英伟达合作推出A3超级计算机
A3将会配备 8 个NVIDIA H100 GPU、两个第四代 Intel Xeon 可扩展处理器、 2TB 内存以及定制的Intel 200G IPU(基础设施处理单元)网络组成。与使用传统NVIDIA A100 GPU的A2相比,学习和推理过程中的性能提升了3倍,带宽提升了10倍。这些实例最初于 5 月份宣布,可以增加到 26,000 个 Nvidia H100 Hopper GPU。鉴于NVIDIA GPU 持续短缺,目前尚不清楚谷歌将拥有多少个NVIDIA H100。
在 Google Cloud Next 大会上,NVIDIA 创始人兼首席执行官黄仁勋与 Google Cloud 首席执行官 Thomas Kurian 一起发表了活动主题演讲,庆祝 NVIDIA H100 GPU 驱动的 A3 实例全面上市,并谈论了谷歌如何使用 NVIDIA H100 和 A100 GPU 进行内部部署DeepMind 和其他部门的研究和推理。
黄仁勋和Thomas Kurian还宣布在 Google Cloud 中开发一款新型超级计算机,该计算机将使用 NVIDIA 正在开发的下一代 AI 芯片。
在讨论中,黄仁勋指出了更深层次的合作,使 NVIDIA GPU 能够为 PaxML 框架加速,从而创建大规模的法学硕士。这个基于 Jax 的机器学习框架是专门为训练大型模型而构建的,允许高级且完全可配置的实验和并行化。目前PaxML 已被 Google 用于构建内部模型,包括 DeepMind 以及研究项目,并将使用 NVIDIA GPU。两家公司还宣布 PaxML 可立即在 NVIDIA NGC 容器注册表中使用。
谷歌表示,生成式人工智能初创公司 Anthropic 是新 TPU v5e 和 A3 VM 的早期用户。虽然谷歌向这家初创公司投资了 3 亿美元,但它同时也是亚马逊网络服务的用户。
Anthropic 联合创始人 Tom Brown 表示:“我们很高兴能与 Google Cloud 合作,我们一直在与 Google Cloud 合作高效地训练、部署和共享我们的模型。由 A3 和 TPU v5e 以及 Multislice 提供支持的谷歌下一代 AI 基础设施将带来性价比优势,将助力我们继续构建下一波人工智能浪潮所需的工作负载。”
支持100款AI模型
为了支持企业云端服务,Google Cloud 还整合加入了 20 个 AI 模型,使其支持的总数达到 100 个,通过其 AI 基础设施,可让客户使用包括 Meta Llama 2 模型、Anthropic Claude 2 聊天机器人等,可以自由选择最能满足营运需求的 AI 模型。
Google Cloud 也对既有 AI 模型提高性能并添加功能,例如文字处理方面的 PaLM 模型可支援用户输入更多文字量,以便处理篇幅较长的报导、书籍文章或者法院判决文件等。
同时,Google Cloud 这次也推出企业级新工具,包括“SynthID”可为 AI 产生的图片加上隐形浮水印,以人眼看不见的方式更改数字图片,即使 AI 图片被编辑或篡改也能保有完整性。
Google Workspace 办公套件将为用户提供 Duet AI 新产品,预计今年稍晚向所有用户开放,可在 Google 文件、试算表、简报中运用 AI 助手帮助更快完成工作。
审核编辑:黄飞
-
capsense第四代和第五代在感应模式上的具体区别是什么?2024-05-23 1139
-
第五代移动通信技术的特点是什么2021-12-22 3375
-
如何提高YOLOv4模型的推理性能?2023-08-15 1422
-
汇佳第五代25-29寸彩电电路图2009-05-25 2730
-
iPod nano(第五代)功能指南手册2009-12-10 928
-
iPod 功能指南(第五代) de-CH.pdf2010-01-13 1311
-
IGBT/FWD功率损耗模拟系统 (英文,含第五代U系列IG2010-07-20 1399
-
第五代增强型STC自动烧录器资料包2016-03-22 1124
-
第五代新品重磅上市,它的优势优点是什么2020-11-24 2310
-
苹果有望在3月发布第五代iPad Pro2021-01-12 4728
-
wifi技术标准第四代第五代区别2022-01-01 42546
-
英特尔发布第五代至强可扩展处理器:性能和能效大幅提升,AI 加速2023-12-15 1784
-
CPU也可以完美运行大模型 英特尔第五代至强重磅发布2023-12-22 1595
-
英特尔专家为您揭秘第五代英特尔® 至强® 可扩展处理器如何为AI加速2023-12-23 1491
-
开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能2024-09-06 1770
全部0条评论

快来发表一下你的评论吧 !
