

基于ICL范式的LLM的最高置信度预测方案
描述
作者:cola
虽然大多数现有的LLM提示工程只专注于如何在单个提示输入中选择一组更好的数据样本(In-Context Learning或ICL),但为什么我们不能设计和利用多个提示输入来进一步提高LLM性能?本文提出上下文采样(ICS),一种低资源LLM提示工程技术,通过优化多个ICL提示输入的结构来产生最有置信度的预测结果。
介绍
指令微调的LLMs,如Flan-T5、LLaMA和Mistral展示了通用的自然语言理解(NLI)和生成(NLG)能力。然而,解决实际任务需要广泛的领域专业知识,这对LLM来说仍然具有挑战性。研究人员提出了各种激励策略来探索LLM的能力。一个突出的方法是少样本上下文学习(ICL),通过向提示输入插入一些数据示例,特别是对未见任务的能力提高了LLM的任务解释和解决能力。最近的几项工作研究了不同ICL设置的影响,包括数量、顺序和组合。然而,最好的ICL策略还没有共识。
本文假设不同的ICL为LLM提供了关于任务的不同知识,导致对相同数据的不同理解和预测。因此,一个直接的研究问题出现了:llm能否用多个ICL提示输入来增强,以提供最可信的预测?为解决这个问题,本文提出上下文采样(ICS)。ICS遵循三步流程:采样、增强和验证,如图1所示。
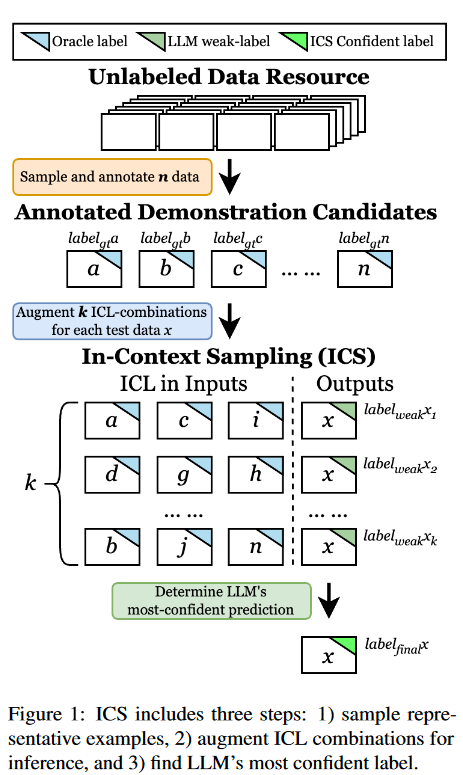
ICS策略
给定一个自然语言任务指令和一个数据,指令微调的SOTA可以接受输入,生成一个输出,其中表示上下文中的注释示例,是预测结果。
示例可以为LLM提供:
直接理解任务指令(I)和预期输出
间接指导如何解决任务。
本文假设不同的ICL示例集为LLM提供了关于该任务的不同知识。因此,LLM可以根据不同的ICL提示输入改变对相同数据的预测,但预测的变化最终将收敛到一个最可信的预测。
ICS的框架如图1所示。
从未标记的数据池中采样示例候选集并获取注释,
用不同的ICL组合增加标签,
验证置信度最高的标签作为增强标签的最终预测。
ICS方法是模型无关的且“即插即用”,可以以最小的工作量切换到不同的采样、增强和验证算法。
示例候选集采样
从许多未标记的数据中采样少量数据作为ICL示例,通常分为两种类型:基于数据多样性和基于模型概率。我们的策略坚持基于集群的策略(即核心集),旨在识别代表所有未标记数据的示例,同时最大化这些选定实例的多样性。该策略用句子转换器编码计算每个数据的余弦相似度,其中embed表示句Transformer Embedding。然后,根据相似度得分对候选样本进行排序,并检索个相同间隔的样本集,以保证样本集的多样性。本文试图确定样本量和增强的ICL组合数量,在下面三个角度上取得平衡:
包含足够的多样性充分表示基础数据,
置信预测具有鲁棒性,
最小化注释成本。
ICL组合增强
如图1所示,ICS通过为要预测的相同数据构建不同的ICL组合来增强标签,然后获得所有标签中置信度最高的标签。然而,如果要求LLM预测候选的每个组合,计算量可能会很大。我们认为,ICS不需要每个ICL组合来找到模型的最可信的标签。类似于人类投票,少数代表代表更多的人口投票,我们计划调查合理数量的“代表”,即及时的输入。用一个随机和基于数据多样性的算法作为基准,用于示例增强,并研究了策略差异的影响。两种方法都是从候选列表中迭代采样次,其中基于多样性的增强策略使用上述策略。然后对相同的测试数据查询LLM次,得到个弱标签,记为。
置信标签验证
既然我们从上述ICS步骤中获得了一组标签,就可以应用一些验证算法来找到置信度最高的标签,获得了最可信的预测。可以想象ICL有潜力提供模型可信的无监督标签,以在资源匮乏的场景中迭代地微调LLM,这些场景中专家注释难以访问且昂贵。
实验
实验设置
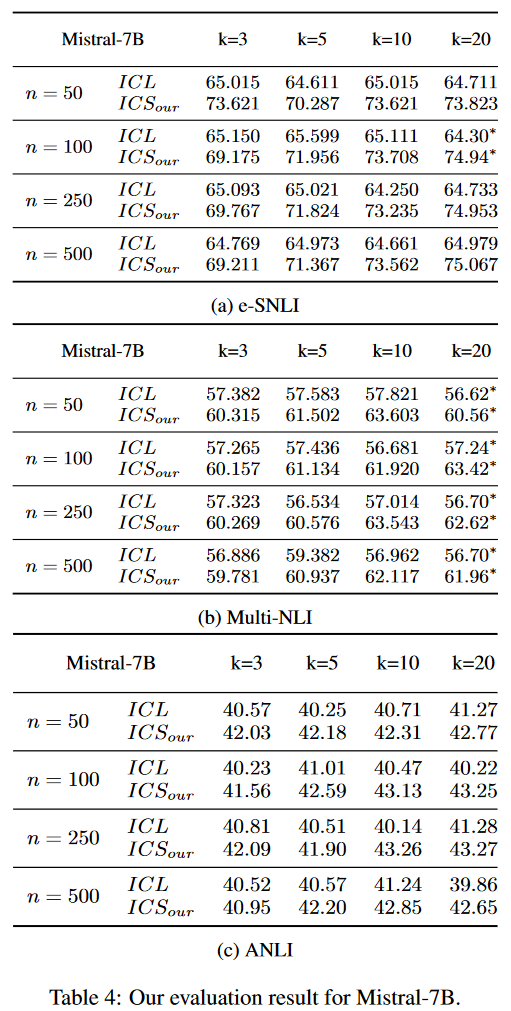
采用了两个SOTA LLMs FLAN-T5-XL和Mistral,并在三个难度越来越大的NLI任务上进行实验:eSNLI、Multi-NLI和ANLI。排除了LLaMA-2的原因是初步实验显示了LLaMA-2在“中性”类别上有过拟合问题。我们使用vanilla ICL作为基线。利用随机抽样来构建基础ICS策略的ICS提示输入,并使用多数代表方法来找到最可信的标签。对每个提示输入使用3个示例。操作ICS的两个控制变量:采样的代表性数据的大小,其中,以及每个待预测数据的增强示例组合的数量,其中,其中是ICL基线。对于真实场景,500个注释是一个合理的预算。在10次试验中取平均值。
对LLaMA-2进行分析
利用三种不同的自然语言指令,在ANLI上对LLaMA-2进行初始推理实验:
确定一个假设是否是蕴涵的,中性的,矛盾的前提。
将一对前提和假设句分为三类:蕴涵句、中性句、矛盾句。
通过蕴涵、中性、矛盾来预测前提和假设之间的关系。
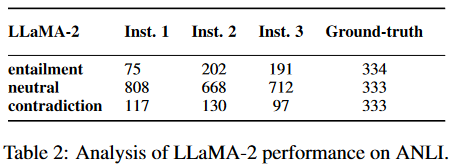
结果如表2所示,我们可以很容易地观察到,尽管改变了指令,LLaMA-2倾向于过度预测其他两个类别的"中性",而真实分布是跨类别的。因此,我们在工作中省略了LLaMA-2。可能有不同的原因导致了这个问题;例如,LLaMA-2对NLI任务或共享同一组目标类别("蕴含"、"中性"和"矛盾")的类似任务进行了过拟合。
实验结果
在图2中,我们展示了时,基线ICL和我们的ICS策略对每个模型和数据集的预测精度。基线和我们的策略之间的标准差变化也用右纵轴的虚线表示。以随机采样策略为基准的ICS策略,可以不断提高LLM在每个组合中的预测性能,证明了所提出的ICS管道的有效性。
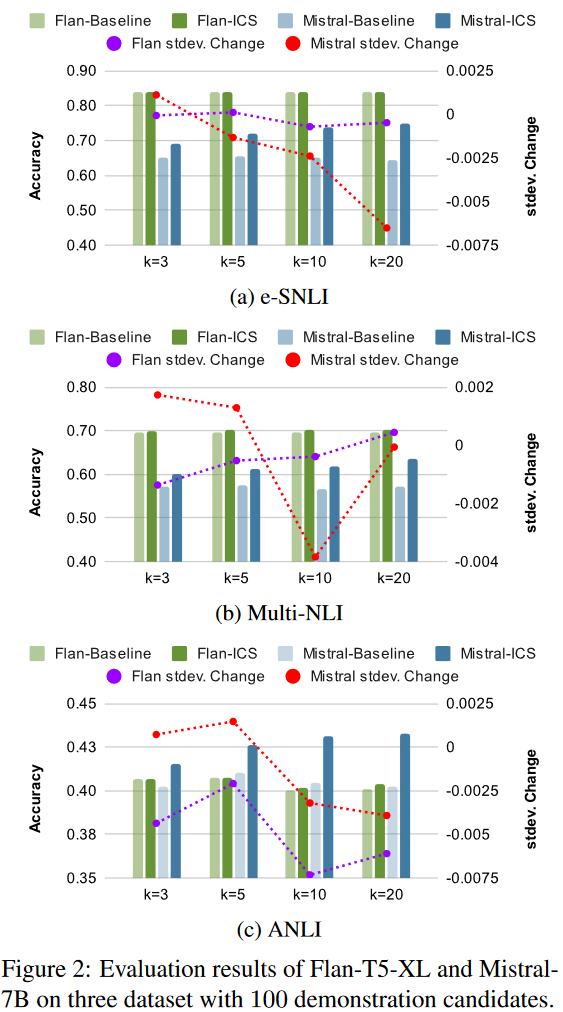
此外,我们观察到LLM对ICS有明显的敏感性。具体来说,对于Flan-T5来说,ICS策略提供的精度提升远小于Mistral,这可以归因于Flan-T5可能会过拟合我们实验的三个数据集或NLI任务。另一方面,Mistral证明了ICS策略对准确性的显著提升,在所有数据集上的平均提升超过5%。当时,两个模型的标准偏差减少得最多,当超过10时,增加的提供的性能改善开始逐渐减少。对于示例候选采样,一旦超过100,精度的提高就不显著。样本量超过100可以被认为具有足够的多样性和代表性。
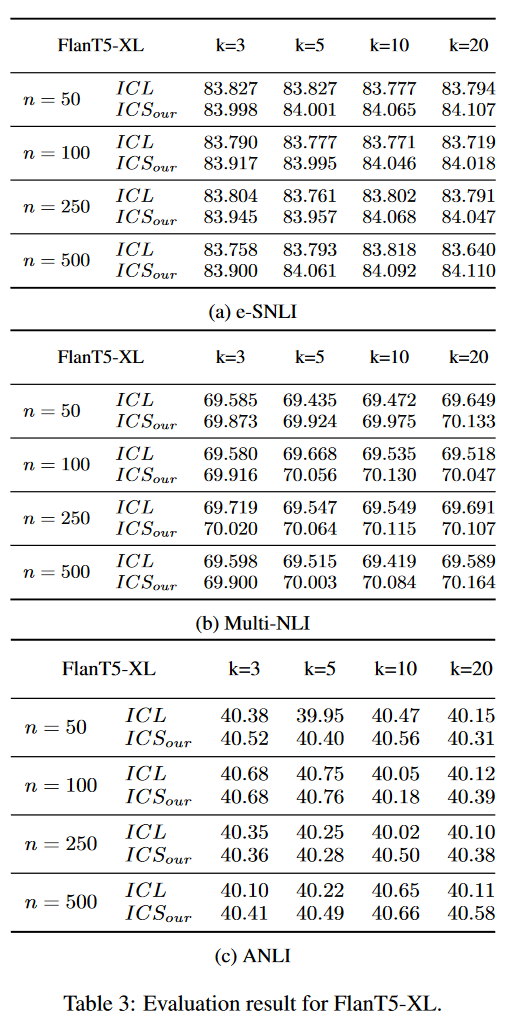
表3和表4报告了对FlanT5XL和Mistral-7b的完整评估结果。
消融实验
使用Mistral-7B和性能最佳的设置:和。从3个NLI数据集中随机采样3000和1000数据作为训练集和测试集。我们共进行了4种情况下的10次试验,记为组合策略,其中RD为随机策略,DS为基于数据相似性的策略。实验结果如表1所示:
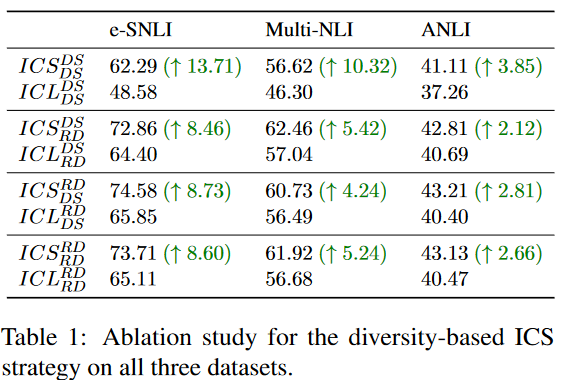
基于多样性的示例候选采样和组合增强策略可以有效提高ICL的性能。
总结
本文提出上下文采样(ICS),一种新的基于ICL的范式,用于探测LLM的最高置信度预测。实验结果表明,与传统的ICL方法相比,ICS方法提高了ICL的准确性,降低了标准偏差。还研究了不同样本数量和ICL组合量的影响,然后进一步进行消融实验,以说明基于ICS简单但有效的数据多样性采样策略的有用性。
限制
本文的主要重点是提出并证明ICS的有效性。然而,尽管对不同的和组合进行了广泛的实验,但仍有几个潜在变量需要进一步分析。例如,尽管我们考虑了3个不同难度的数据集,并且每个ICL组合是任意的,但3个数据集都是NLI任务。此外,只进行了一项基于数据多样性的候选采样和组合增强策略的小规模消融研究。并且我们的实验原本打算由三个SOTA LLM组成,但由于LLaMA-2倾向于预测“中性”类别,因此不包括它。我们仍有各种其他的指令微调LLM没有包括在这项工作中,如InstructGPT。
审核编辑:黄飞
-
VNA计算器显示的值是99.7%置信度还是95%?2018-09-19 2569
-
信度函数在政府形象评价模型中的应用2009-02-28 483
-
统计置信度应用于误差概率估计2009-04-22 857
-
基于预测可信度的多级协调空间负荷预测方法2016-12-28 820
-
用于暂稳预测的支持向量机组合分类器及其可信度评估2018-01-03 965
-
如何对医学图像分割中的置信度进行量化?2020-12-25 2555
-
将置信规则库分级优化的网络安全态势预测方法2021-03-16 1218
-
选择最合适的预测性维护传感器2022-12-19 1835
-
ICL3221、ICL3222、ICL3223、ICL3232、ICL3241、ICL3243 数据表2023-03-15 561
-
基于单一LLM的情感分析方法的局限性2023-11-23 2485
-
LLM推理加速新范式!推测解码(Speculative Decoding)最新综述2024-01-29 6782
-
置信度验证对于自动驾驶来说重要吗?2025-11-12 1157
-
跨越“仿真到实车”的鸿沟:如何构建端到端高置信度验证体系?2025-12-05 1314
-
经纬恒润携手赛目科技打造高置信度HIL测试解决方案2026-06-01 1060
全部0条评论

快来发表一下你的评论吧 !
