

如何利用3D点编码提升PETRV1/V2及StreamPETR性能
汽车电子
描述
自动驾驶系统需要准确感知和理解周围道路环境中的障碍物。通过3D障碍物检测,系统能够获取3D坐标系下的障碍物坐标、尺寸、朝向、速度等信息,从而准确感知和建模道路环境。这有助于系统做出合理的规划和决策,避免与障碍物碰撞,并选择最佳路径和行驶策略。
近年来,相对于成本较高的雷达感知方案而言,纯视觉的低成本3D障碍物检测方案受到越来越多关注。尽管配备辅助自动驾驶功能的车辆一直装有多个环视相机,但早期的纯视觉方案主要通过在后处理中融合来自多个相机的单目3D障碍物检测结果来进行道路环境感知,这导致了大量逻辑操作以及对跨相机截断物体的挑战。
自特斯拉AI-Day提出BEV感知的思路后,端到端中融合环视3D感知成为业界争相落地的热点。与此同时,后摩智能与悉尼大学、苏黎世联邦理工大学以及阿德莱德大学的学者合作研究提出了3D点编码(3D Point Position Embedding, 3DPPE),该方案旨在解决当前基于Transformer范式的环视3D障碍物检测中存在的图像与锚点位置编码不一致以及沿射线方向的误检导致后处理逻辑复杂等问题,在获得卓越性能的同时进一步降低了后处理的复杂度,同比petr-v1/2以及streampetr均取得显著提升,已收录于计算机视觉顶会ICCV2023。
内容简介
方法架构:
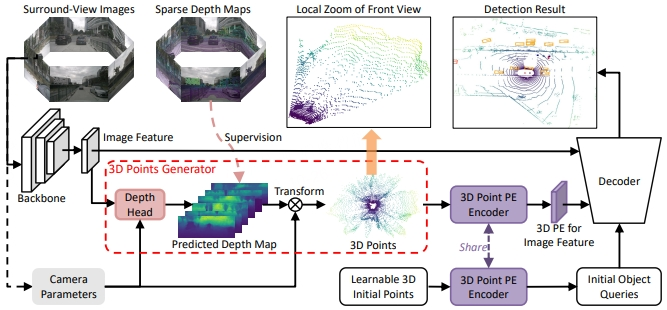
图 1. 3DPPE框架图
如图1所示,3DPPE基于Transformer结构。模型的输入是环视图像,经过主干网处理后得到图像特征,该特征送入深度检测头后得到对应的深度预测信息,再结合相机内外参,可以得到对应的3D点云。这个3D点云继续送入3D点编码器中用于构建对应图像特征的位置编码;与此同时,随机初始化的3D锚点同样经过共享的3D点编码器,由此构建对应的初始目标索引特征。将上述图像特征、图像位置编码以及初始索引特征送入解码器后即可得到环视系统下3D障碍物的检测框信息。
由于3DPPE在构建图像特征的位置编码时引入了显式的深度信息,使得对应的位置先验与真实物理世界的分布更为一致,从而有效的减缓了沿射线方向的误检。具体差异如下图所示,之前的3D相机射线编码无法建模物体的物理真实深度(图2.a),而3DPPE中构建3D点编码构建时用到的深度信息都是符合物理世界分布的,深度点都是相机射线和车体表面相交的点(图2.b)。此外,改进后的图像位置编码与锚点分布同源,因此性能更好。
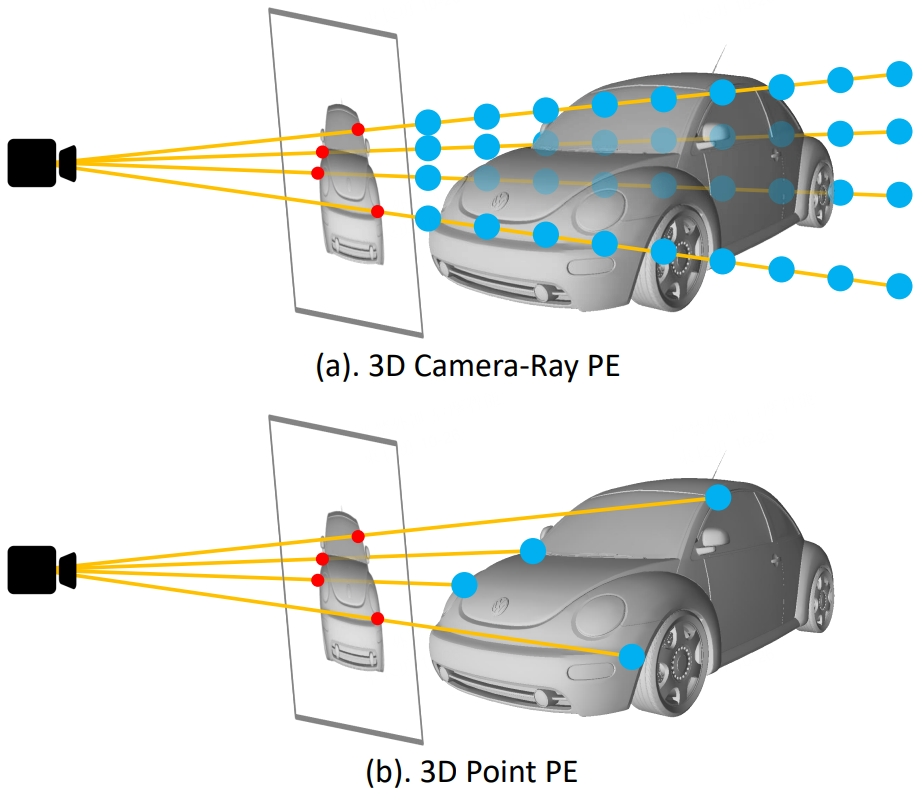
图 2. 3D相机射线编码和3D点编码的图示说明
实验表明不论在验证集还是测试集上,我们方法在同比条件下都取得了最优的性能。
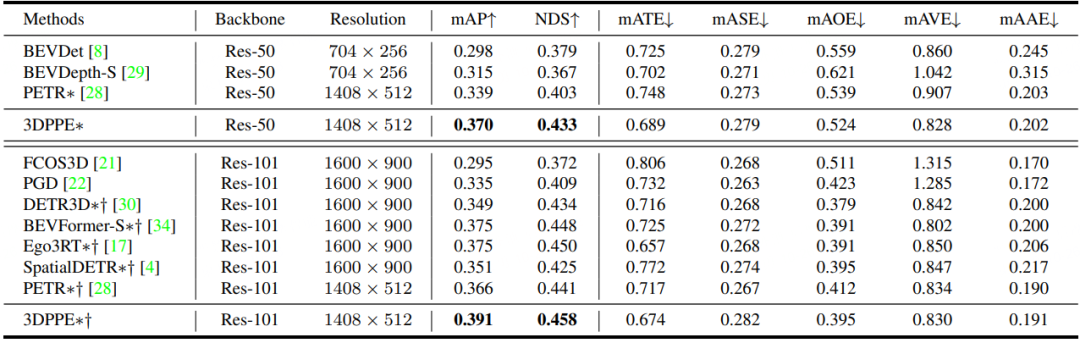
表 1. Nus验证集上的性能
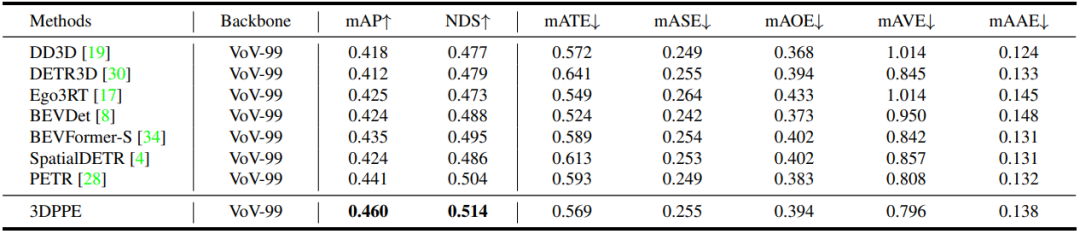
表 2. Nus测试集上的性能
下图对位置编码的相似度进行可视化,可以看出3D点编码具有更好的相似度聚焦能力。

图 3. 位置编码的相似度可视化
总结与展望
3DPPE初步探索了位置编码对环视3D障碍物检测的影响,这将为如何在GPU和CPU算力均有限的端上芯片上部署模型提供理论及技术支撑,如何探索具有极致优化潜力的模型将是未来重要研究方向。
审核编辑:黄飞
-
基于深度学习的3D点云实例分割方法2023-11-13 3886
-
NeuralLift-360:将野外的2D照片提升为3D物体2023-04-16 3154
-
如何直接建立2D图像中的像素和3D点云中的点之间的对应关系2022-10-18 11326
-
Core 3399 JD4 V2文档3D结构图2022-09-16 579
-
NodeMCU V2 Amica V3 Lolin的盾牌2022-08-24 866
-
何为3D点云语义分割2022-07-21 10475
-
如何促使2D和3D视觉检测的性能成倍提升?2021-02-22 4214
-
手机大厂如何提升3D识别系统性能?1D ToF的创新应用有哪些?2019-08-02 4574
-
如何同时获取2d图像序列和相应的3d点云?2018-11-13 3006
-
如何利用3D打印技术做发光字2018-10-13 3294
-
3D负载会影响NVENC性能吗2018-09-17 2825
-
3D点云技术介绍及其与VR体验的关系2017-09-15 1573
-
关于利用2D图片利用投影的方法创建3D模型2014-10-08 3946
-
Ansys Maxwell 3D 2D RMxprt v16.0 Win32-U\2014-06-13 6535
全部0条评论

快来发表一下你的评论吧 !
