

形式化验证最佳实践之三:实现端到端属性
电子说
描述
在本系列的前两集中,我们看到了如何为高速缓存建立一个高效的正式测试平台,如何发现一个真正的漏洞以及如何重现一个死锁漏洞和找到一个设计修复方法。在这一点上,我们确信不存在其死锁漏洞。本集将介绍我们如何验证强大的断言,怎么准备正式测试平台以验证端到端属性(端到端属性将根据 DUT 的输入检查 DUT 的输出),以及新的最佳实践。
基本属性
实际上,让我们从一个不是端到端但对高速缓存至关重要的属性开始。该属性是我们唯一需要检查内部细节的属性。它可以验证缓存中的命中请求是否只有一种命中方式。如果不遵守这一点,那么在读取或写入哪种数据时就会非常模糊。
hit_onehot: assert property(i_ucache.i_hit_stage.is_hit |-> $onehot(i_ucache.i_hit_stage.hit_way);
在缓存中执行查找时,地址会被分割成一个标记(下图中为 123)、一个索引(1)和一个偏移量。索引用于寻址标记方式。如果该索引的内容有效,而标签在两种方式(下图中的 0 和 2)中相同,这就是 "多重命中",也是一个严重的问题。许多潜在的设计错误都可以看作是对这一属性的违反。
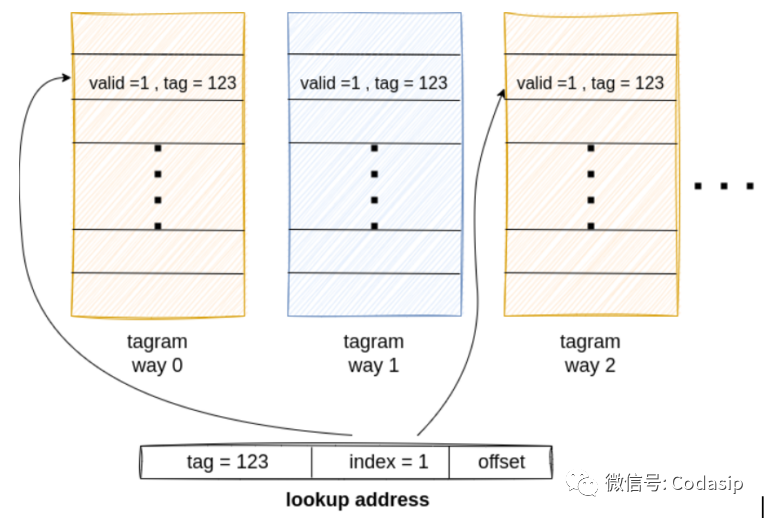
查找标记方式
然而,要摒弃对这一断言的错误失效,需要几个约束条件。如第一集所述,我们抽象了不同的 RAM 阵列,包括 tagram。这意味着缓存读取 tagram 的结果是 "随机 "的。这一点都不好,会导致断言很快失败。
引入 CAM 组件
这就是内容可寻址内存(CAM)发挥作用的地方。CAM 是内存的缩小版。它不能容纳数千个单元(每个地址一个单元),而只能容纳少数几个选定的地址,但这些地址不受任何限制。这实际上是某种固定长度的关联数组,其长度远远小于实际数组的大小。
下图左边显示的是一个真实的 tagram,右边显示的是一个 CAM 抽象。
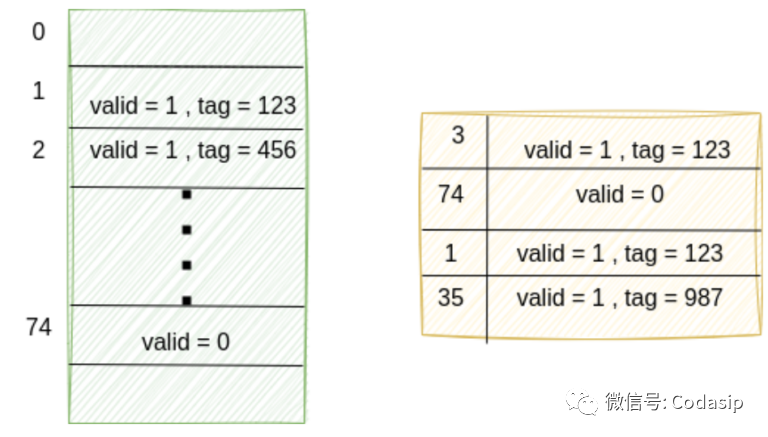
我们可以看到,真实标记图在索引 2 处包含一个有效标记。但在 CAM 中却没有。为了避免因缓存读取索引 2 而导致错误失败,我们只需限制所有读取(和写入)都必须在 CAM 中存在的索引处进行:
request_in_cam: assume property(request |-> there_exists_one_in_cam(req_index));
这是一个很强的过约束,我们可以通过正确调整 CAM 的大小来缓解这个问题。为此,我们定义了覆盖属性,以确定使用了多少个不同的索引。通过对这些属性的证明,我们可以确定哪些 CAM 大小过大,无法充分利用,因为形式分析会变得过于复杂。我们通常使用 FV 无法充分利用的最小 CAM 大小。
我们使用一个 CAM 实例数组来表示所有标签阵列。此外,使用 CAM 可以抽象出缓存的初始内容。我们只需让数组中的值不受限制即可。事实上,并非完全无约束!hit_onehot 断言仍然会在一个简单的情况下失效:读取请求进来后,会以两种方式命中,因为每个 CAM 的初始状态允许在同一索引中有两种方式拥有相同的有效标记。我们需要添加仅适用于复位后第一个周期的约束:

这给形式分析增加了很多复杂性,所以只有在需要时才使用这些约束。不幸的是,我们还没有完成 hit_onehot 断言,还需要使用 CAM 内容的新约束:
对于 CAM 中已经存在的地址,高速缓存不得收到 "非高速缓存 "请求。
我们还需要用 CAM 为 dirtyram 阵列建模,并使标签和 dirty CAM 的内容保持一致(即 dirty 行必须有效)。
CAM 中的地址必须在内存映射寄存器范围之外。
其中一些约束用于确保 CAM 的初始内容正确无误。我们还可以使用非常类似的属性作为断言来检查任何循环。只需删除 "init_cycle "项即可:

对死循环状态存有敬意!
正如前面提到的,我们需要限制到达 tagram(实际上是 CAM)的请求,使它们只针对 CAM 中存在的索引。这有一个隐藏的缺点。为了说明这一点,让我先总结一下什么是 FV 中的 "深度错误查找"。
深度漏洞查找
有多种不同的查找方法,所有方法都是 "半正式 "的,这意味着它们并非详尽无遗。但是它们在查找故障方面非常出色。
除了从复位状态开始进行形式分析外,主要技术还使用轨迹末端来启动形式分析。首先根据用户定义的覆盖属性或自动生成的覆盖属性生成轨迹。然后,从这一跟踪的最后一个周期(或最后几个周期)开始,执行另一项形式分析,找到其他跟踪,用于启动其他形式分析等。它们也可能会发现错误。这种方法能够发现需要大量循环才能出现的错误,而标准(穷举)FV 是无法发现这些错误的。
下面以穷举式 FV 为例进行说明:穷举式 FV 仅从重置状态开始探索,在探索了所有状态直至几个周期后就达到了极限。相反,深度错误查找从复位状态开始探索,但也会探索一些其他状态(绿色),并且可以深入设计,可能会发现错误状态(红色),但也会遗漏一些状态(灰色)。
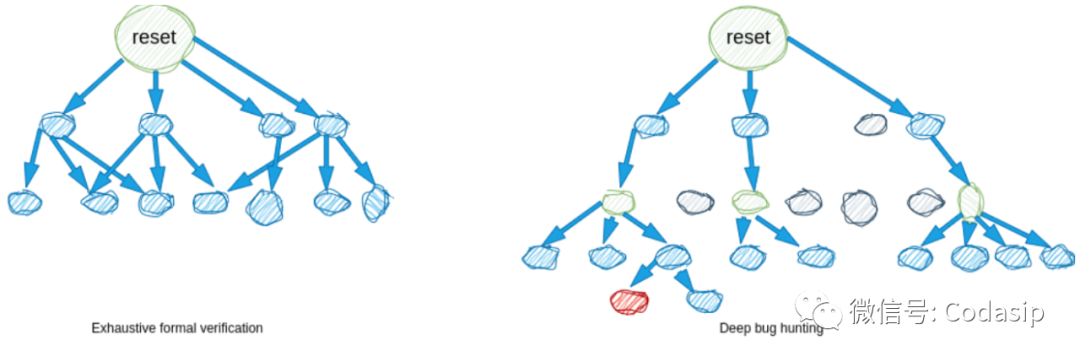
在深度错误查找中,当从跟踪结束处开始新的形式分析时,跟踪前缀会被冻结。我们所说的 "死循环状态 "是指由于某些约束条件在其后适用,因此无法进入下一个状态。死端状态越多,深度错误查找的效率就越低。
如何消除死锁状态
假设高速缓存接收到一个地址 A 的请求。然后,该请求触发了对 CAM 的访问,访问的索引 I 取决于 A。针对 A 的请求本应在几个周期前就避免。
遵循这个简单的规则可以大大缓解死锁状态问题:尽快对事物进行约束。在本例中,它包括对高速缓存输入端的地址进行限制,这样对于可缓存请求,只有在 CAM 中匹配地址的请求才会被发出。
为 tagram 和 dirtyram 添加 CAM 以及相关限制并不容易。只有在调试重要断言(如 hit_onehot 断言)失败时,才能逐步添加抽象和约束。不过,这也是一种投资。你会看到,我们在缓存验证的其余部分中都使用了它。最后,我们没有发现任何关于 hit_onehot 的失败,但即使过了很长时间,也没有得到任何证明。这并不奇怪,因为这个断言几乎验证了设计的全部控制(在分析覆盖率时可以看到......在下一集中)。然而,手动添加一些令人讨厌的错误,很快就会被视为该断言的失败,这是一个好兆头。
关于这次的收获可以来回顾一下。
我们已经看到了如何大大增强(或复杂化!)我们的正式测试平台。这需要验证一个基本的控制断言,之后还需要验证数据完整性断言。以下是我们确定的最佳实践。

审核编辑:黄飞
-
鉴源论坛 · 观模丨形式化验证——以操作系统任务调度算法验证为案例2022-11-09 2228
-
芯片开发中形式化验证的是一个误区2022-11-29 3078
-
形式化方法的工程化2023-03-24 2909
-
EDA形式化验证漫谈:仿真之外,验证之内2023-09-01 2525
-
ACRN 之InterruptWindow功能正确性形式化验证2020-06-18 1631
-
老化验证和封装形式有关系吗?2022-09-13 11583
-
VaaS平台已支持区块链平台智能合约的形式化验证2018-12-14 1649
-
闪电网络通过形式化验证结果表明和比特币一样安全2019-09-24 1087
-
安全测试之离线免费版自动形式化验证工具Beosin—VaaS2019-11-23 1219
-
基于定理证明其的有限域及其形式化研究2021-04-25 906
-
虹科PagerDuty通过端到端自动化响应实现最佳实践2021-08-10 2092
-
从小众走向普及,形式化验证对系统级芯片开发有多重要?2023-04-21 1525
-
国内首例!空运“端到端”碳中和实践获圆满成功2023-07-12 1465
-
阿卡思微电子携前沿形式化验证技术亮相DVCon China 20262026-05-18 229
-
西门子EDA形式化验证技术网络研讨会预告2026-06-05 248
全部0条评论

快来发表一下你的评论吧 !
