

如何训练这些神经网络来解决问题?
人工智能
描述
本文介绍了如何训练这些神经网络来解决问题。
神经网络的训练过程
本系列第一部分将讨论的CIFAR网络由不同层的神经元组成,如图1所示。来自 32 像素× 32 像素的图像数据被呈现给网络并通过网络层。CNN的第一步是检测和研究要区分的对象的独特特征和结构。为此使用过滤器矩阵。一旦设计人员对CIFAR等神经网络进行了建模,这些滤波器矩阵最初仍未确定,并且此阶段的网络仍然无法检测模式和对象。
为此,首先需要确定矩阵的所有参数和元素,以最大限度地提高检测对象的精度或最小化损失函数。这个过程被称为神经网络训练。对于本系列第一部分所述的常见应用程序,网络在开发和测试期间进行一次训练。之后,它们就可以使用了,不再需要调整参数。如果系统正在对熟悉的对象进行分类,则无需进行额外培训。只有当系统需要对全新的对象进行分类时,才需要进行训练。
训练网络需要训练数据,然后使用一组类似的数据来测试网络的准确性。例如,在我们的 CIFAR-10 网络数据集中,数据是十个对象类别中的一组图像:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。然而,这是人工智能应用程序整体开发中最复杂的部分,在训练CNN之前,必须对这些图像进行命名。本文将讨论的训练过程根据反向传播原理工作;网络连续显示大量图像,每次同时传达一个目标值。在我们的示例中,此值是关联的对象类。每次显示图像时,都会优化筛选器矩阵,以便对象类的目标值和实际值匹配。完成此过程后,网络还可以检测图像中在训练期间未看到的对象。
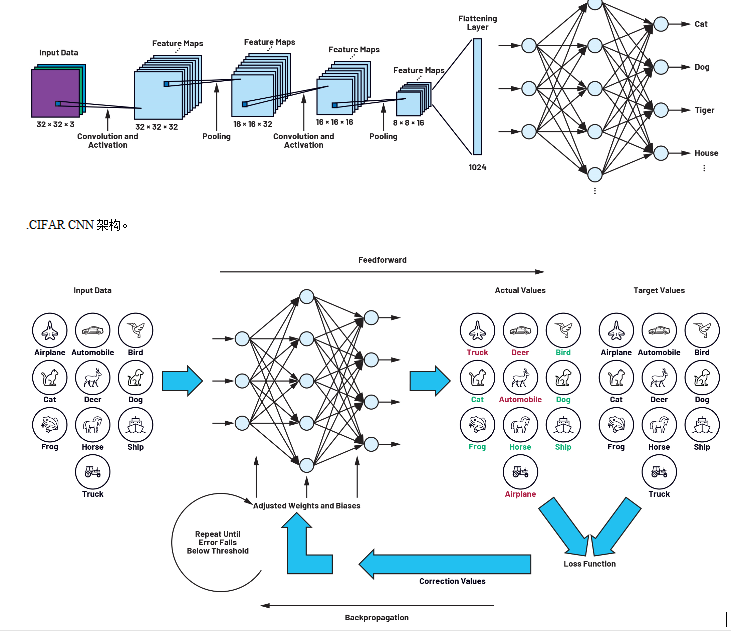
2.由前馈和反向传播组成的训练循环。
过拟合和欠拟合
在神经网络建模中,经常会出现关于神经网络应该有多复杂的问题,即它应该有多少层,或者它的滤波器矩阵应该有多大。这个问题没有简单的答案。与此相关,讨论网络过拟合和欠拟合非常重要。过拟合是模型过于复杂且参数过多的结果。我们可以通过比较训练数据损失和测试数据损失来确定预测模型对训练数据的拟合是太差还是太好。如果训练期间的损失很低,而当网络呈现以前从未显示过的测试数据时,损失会过度增加,这强烈表明网络已经记住了训练数据,而不是泛化了模式识别。这主要发生在网络有太多的参数存储或太多卷积层时。在这种情况下,应减小网络大小。
损失函数和训练算法
学习分两步完成。在第一步中,向网络显示一个图像,然后由神经元网络处理以生成输出向量。输出向量的最大值表示检测到的对象类,就像我们示例中的狗一样,在训练情况下,它不一定是正确的。此步骤称为前馈。
输出端产生的目标值和实际值之间的差值称为损耗,相关函数称为损耗函数。网络的所有元素和参数都包含在损失函数中。神经网络学习过程的目标是以最小化损失函数的方式定义这些参数。这种最小化是通过一个过程实现的,在这个过程中,输出端产生的偏差(损耗=目标值减去实际值)通过网络的所有组件向后反馈,直到到达网络的起始层。学习过程的这一部分也称为反向传播。
因此,在训练过程中会产生一个循环,该循环以逐步方式确定滤波器矩阵的参数。重复此前馈和反向传播过程,直到损耗值降至先前定义的值以下。
优化算法、梯度和梯度下降方法
为了说明我们的训练过程,图 3 显示了一个仅由两个参数 x 和 y 组成的损失函数。z 轴对应于损失。函数本身在这里不起作用,仅用于说明目的。如果我们更仔细地观察三维函数图,我们可以看到该函数具有全局最小值和局部最小值。
可以使用大量的数值优化算法来确定权重和偏差。最简单的一种是梯度下降法。梯度下降方法基于这样一种想法,即在使用梯度的逐步过程中,从损失函数中随机选择的起点找到一条路径,该起点导致全局最小值。梯度作为数学运算符,描述了物理量的进程。它在损失函数的每个点上都提供一个向量(也称为梯度向量),该向量指向函数值最大变化的方向。向量的大小与变化量相对应。在图 3 中的函数中,梯度向量将指向右下角某处的最小值(红色箭头)。由于表面的平坦度,幅度会很低。在接近进一步区域的峰值时,情况会有所不同。在这里,矢量(绿色箭头)陡峭地向下指向,并且由于地势很大,因此具有较大的幅度。
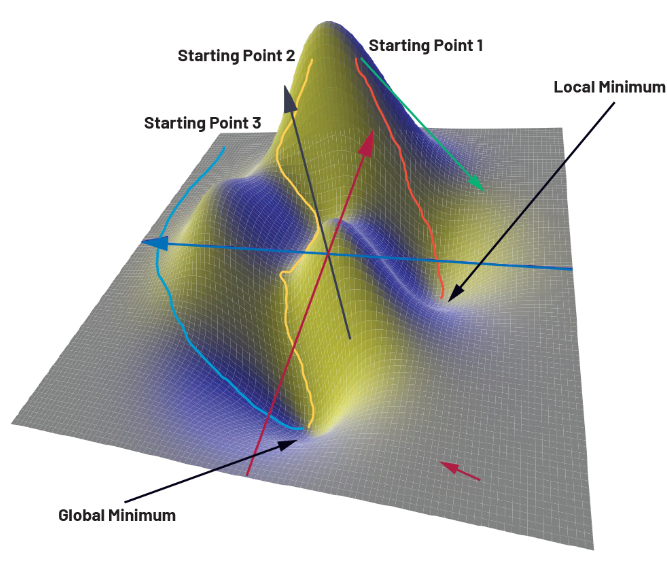
3.使用梯度下降法到达目标的不同路径。
使用梯度下降方法,从任意选择的点开始,迭代地寻找通往最陡峭下降山谷的路径。这意味着优化算法在起点处计算梯度,并在最陡峭的下降方向上迈出一小步。在这个中间点,重新计算坡度,并继续进入山谷的路径。这样,就创建了一条从起点到山谷中某个点的路径。这里的问题是起点不是预先定义的,而是必须随机选择的。在我们的二维地图中,细心的读者会将起点放在函数图左侧的某个地方。这将确保(例如,蓝色)路径的末尾处于全局最小值。另外两条路径(黄色和橙色)要么要长得多,要么以局部最小值结束。由于优化算法不仅要优化两个参数,还要优化数十万个参数,因此很快就会发现,起点的选择只能是偶然的正确。在实践中,这种方法似乎没有帮助。这是因为,根据所选的起点、路径,训练时间可能很长,或者目标点可能不在全局最小值,在这种情况下,网络的精度会降低。
因此,在过去几年中,已经开发了许多优化算法来绕过上述两个问题。一些替代方案包括随机梯度下降法、动量、AdaGrad、RMSProp 和 Adam,仅举几例。实践中使用的算法由网络开发人员确定,因为每种算法都有特定的优点和缺点。
训练数据
如前所述,在训练过程中,我们向网络提供标有正确对象类别(如汽车、船舶等)的图像。在我们的示例中,我们使用了已经存在的 CIFAR-10 数据集。在实践中,人工智能的应用可能超出了猫、狗和汽车的识别范围。例如,如果必须开发一个新的应用程序来检测制造过程中螺钉的质量,那么网络也必须使用来自好螺钉和坏螺钉的训练数据进行训练。创建这样的数据集可能非常费力和耗时,并且通常是开发 AI 应用程序中最昂贵的步骤。编译数据集后,将其分为训练数据和测试数据。如前所述,训练数据用于训练。测试数据在开发过程结束时用于检查经过训练的网络的功能。
结论
在本系列的第一部分“理解卷积神经网络”中,我们描述了一个神经网络,并详细研究了它的设计和功能。现在我们已经定义了函数所需的所有权重和偏差,我们可以假设网络可以正常工作。在本系列的最后一篇文章中,我们将通过将神经网络转换为硬件来测试我们的神经网络来识别猫。为此,我们将使用MAX78000人工智能微控制器和ADI公司开发的基于硬件的CNN加速器。
审核编辑:黄飞
-
在Ubuntu20.04系统中训练神经网络模型的一些经验2025-10-22 322
-
人工神经网络原理及下载2008-06-19 9932
-
当训练好的神经网络用于应用的时候,权值是不是不能变了?2016-10-24 4643
-
请问Labveiw如何调用matlab训练好的神经网络模型呢?2018-07-05 9419
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3324
-
基于光学芯片的神经网络训练解析,不看肯定后悔2021-06-21 3047
-
matlab实现神经网络 精选资料分享2021-08-18 1762
-
优化神经网络训练方法有哪些?2022-09-06 1762
-
如何进行高效的时序图神经网络的训练2022-09-28 3216
-
Kaggle知识点:训练神经网络的7个技巧2023-12-30 1330
-
如何训练和优化神经网络2024-07-01 1885
-
卷积神经网络训练的是什么2024-07-03 2009
-
怎么对神经网络重新训练2024-07-11 1613
-
脉冲神经网络怎么训练2024-07-12 2164
-
Python自动训练人工神经网络2024-07-19 1305
全部0条评论

快来发表一下你的评论吧 !
