

香港大学最新提出!实现超现实的人类图像生成:HyperHuman
描述
1、导读
尽管大规模文本到图像模型取得了重大进展,但实现超现实的人类图像生成仍然是一项理想但尚未解决的任务。现有模型(例如稳定扩散和DALL·E2)往往会生成部分不连贯或姿势不自然的人体图像。为了应对这些挑战,我们的主要见解是,人类图像本质上具有多个粒度的结构,从粗粒度的身体骨骼到细粒度的空间几何。因此,在一个模型中捕获显式外观和潜在结构之间的这种相关性对于生成连贯且自然的人类图像至关重要。为此,我们提出了一个统一的框架HyperHuman,它可以生成高度真实和多样化布局的野外人类图像。具体来说:
我们首先构建一个以人类为中心的大规模数据集,名为HumanVerse,它由3.4亿张图像组成,具有人体姿势、深度和表面法线等全面注释。
接下来,我们提出了一种潜在结构扩散模型,该模型可以同时对深度和表面法线以及合成的 RGB 图像进行去噪。我们的模型在统一网络中强制执行图像外观、空间关系和几何形状的联合学习,其中模型中的每个分支在结构意识和纹理丰富性方面相互补充。
最后,为了进一步提高视觉质量,我们提出了一种结构引导细化器来组合预测条件,以更详细地生成更高分辨率。大量的实验表明,我们的框架具有最先进的性能,可以在不同的场景下生成超逼真的人类图像。
2、介绍

所提出的HyperHuman同时生成以文本和骨架为条件的粗略 RGB、深度、法线和高分辨率图像。可以创建逼真的图像和风格化的渲染。

我们与最近的T2I模型进行比较,显示出更好的真实性、质量、多样性和可控性。请注意,在每个2x2网格(左)中,左上角是输入骨架,而其他部分是联合去噪的法线、深度和512x512的粗略 RGB。对于完整模型,我们合成的图像高达 1024x1024(右)
3、方法
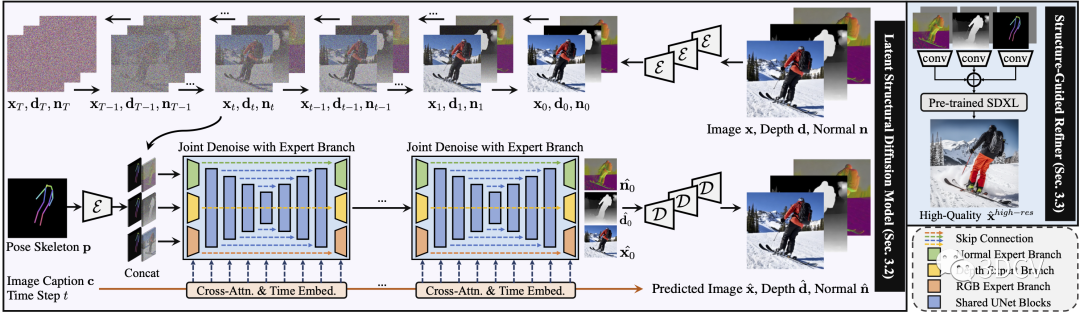
在潜在结构扩散模型(紫色)中,图像x、深度d和表面法线n对标题c和姿势骨架p进行联合去噪调节。在结构引导精炼器(蓝色)中,我们构建了更高分辨率生成的预测条件。请注意,灰色图像是指随机丢弃条件,以实现更稳健的训练。
4、实验
MS-COCO 2014 验证人类的零样本评估
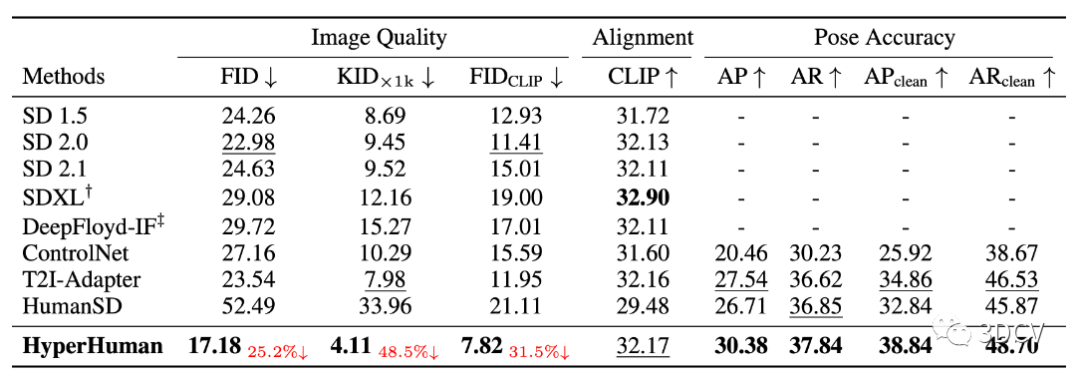
我们将我们的模型与最近的 SOTA 通用 T2I 模型(Stable Diffusion v1.5、v2.0、v2.1;SDXL;DeepFloyd-IF)和可控方法(ControlNet;T2I-Adapter;HumanSD)进行比较。请注意,SDXL 生成 512x512 的艺术风格,而 IF 仅创建固定大小的图像,我们首先生成 1024x1024 结果,然后针对这两种方法将大小调整回 512x512。
MS-COCO 2014 验证人类子集的评估曲线
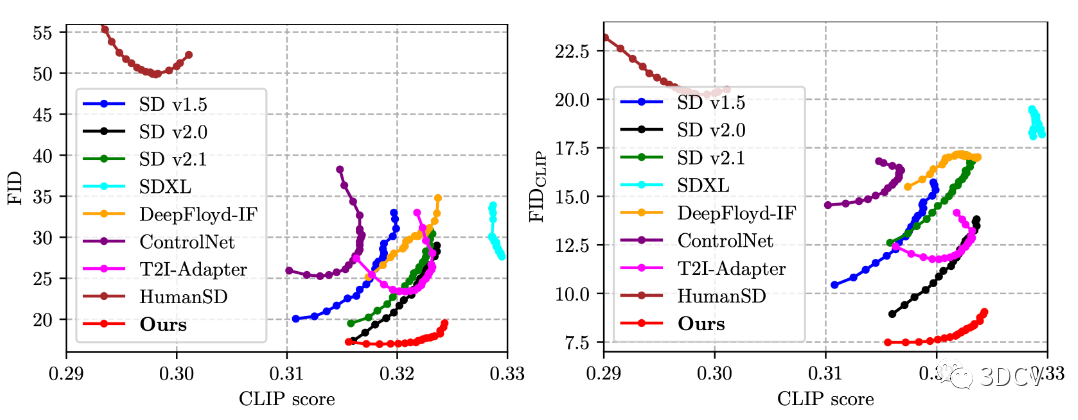
我们展示了所有方法的FID-CLIP(左)和FID CLIP -CLIP(右曲线,CFG比例范围为4.0至20.0。
用户偏好比较

我们报告了用户更喜欢我们的模型而不是基线的比率
5、结论
我们提出了一种新颖的框架HyperHuman来生成高质量的野外人体图像。为了在统一网络中加强图像外观、空间关系和几何形状的联合学习,我们提出了潜在结构扩散模型,该模型可同时对深度和法线以及RGB进行去噪。然后我们设计了结构引导优化器来构建详细生成的预测条件。大量的实验证明我们的框架具有卓越的性能,可以在不同的场景下生成逼真的人类。
-
香港大学首创光热电统一理论可解决LED灯泡发光不均与寿命问题2017-12-27 6309
-
香港大学借助基因工程造出世界首个人造心脏2018-02-28 931
-
一场探索人类与太阳关系的VR舞蹈体验2018-04-19 2051
-
清华大学将与香港大学合作进行AI研究2018-12-03 4655
-
香港大学发布新冠肺炎AI成果,准确率高达88%2020-05-22 4193
-
人体图像合成制作可信和逼真的人类图像2020-12-14 4245
-
香港大学实现机器人触觉传感器的自解耦和超分辨率2021-03-03 3472
-
香港大学机器鱼创下吉尼斯世界纪录2021-05-07 2644
-
基于残差生成对抗网络的人脸图像复原方法2021-06-16 1306
-
中科院&香港大学:使用新方法进行多任务学习的可穿戴传感器内储层计算2023-02-09 1283
-
上海人工智能实验室发布自动驾驶视频生成模型GenAD2024-03-26 1396
-
香港大带宽服务器连接失败怎么办?2024-09-04 973
-
华为携手香港大学建设新一代智慧校园2024-12-13 1418
-
华为与香港大学共建智慧校园,推动教育数字化转型2024-12-24 1262
-
利用NVIDIA 3D引导生成式AI Blueprint控制图像生成2025-06-05 1102
全部0条评论

快来发表一下你的评论吧 !
