

动态场景下的自监督单目深度估计方案
人工智能
描述
作者:泡椒味的口香糖
0. 笔者个人体会
自监督单目深度估计的训练可以在大量无标签视频序列来进行,训练集获取很方便。但问题是,实际采集的视频序列往往会有很多动态物体,而自监督训练本身就是基于静态环境假设,动态环境下会失效。
之前学习过TPAMI 2023的工作SC-Depth V3,也是动态场景下的自监督单目深度估计方案。最近在NeurlPS 2023中又看到了类似动态环境深度估计的工作Dynamo-Depth,就想对比学习一下。
1. 效果展示
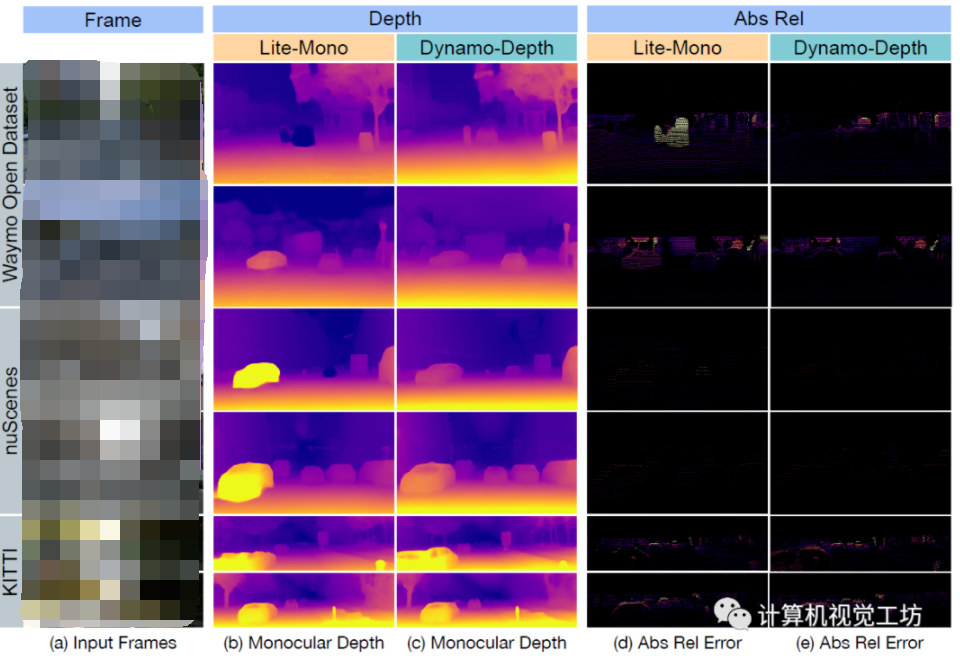
先看看这项工作的效果,对比方案是CVPR 2023的工作Lite-Mono,显然Dynamo-Depth的动态物体深度估计结果更准确。当然Lite-Mono本身不是针对动态场景的,而是结合CNN和Transformer实现嵌入式部署,作者这样对比主要是验证他们的Motivation。
2. 摘要
无监督单目深度估计技术已经展示了令人鼓舞的结果,但通常假设场景是静态的。当在动态场景中训练时,这些技术受到影响,在动态场景中,明显的物体运动可以通过假设物体的独立运动或改变其深度来解释。这种模糊性导致深度估计器对移动物体预测错误的深度。为了解决这个问题,我们引入了Dynamo-Depth,这是一种通过联合学习单目深度、3D独立光流场和来自未标记单目视频的运动分割来消除动态运动歧义的统一方法。具体而言,我们提供了我们的关键见解,即良好的运动分割初始估计足以用于联合学习深度和独立运动,尽管存在基本的潜在模糊性。我们提出的方法在Waymo Open和nuScenes数据集上实现了最先进的单目深度估计性能,显著改善了移动对象的深度。
3. 算法解析
先重述一下传统的自监督单目深度估计的原理:
网络包括DepthNet和PoseNet两部分,输入是单目视频序列中的前后两帧(也可以跳帧训练)。首先给第一帧图像估计深度图,同时估计两帧图像中的位姿,之后利用深度图和位姿重建第一帧图像,去计算重建图像和真实图像之间的光度损失。
注意,这个框架假设场景是完全静态的,动态物体的扰动会极大影响损失函数的计算。
当然这只是最基本的框架,还有很多优化策略,比如引入各种各样的损失函数。它也有很多问题,比如尺度不确定、帧间不连续。本文主要讨论动态场景,就不赘述这些问题了。
室外单目深度估计最主要的应用场景是哪里?
那肯定是自动驾驶了,而且这个场景的大多数情况是:自车在路上行驶,其他动态车辆共线行驶。
这个场景的深度估计有什么难点吗?
想象一个场景,我们开车的时候会感觉车辆附近的物体速度很快,但是远处的物体速度很慢(从数学上讲叫极线歧义)。也就是说,如果某个车辆与自车同向行驶,因为几乎相对静止,所以网络会认为车辆离自己非常远。同理,某个车辆与自车对向行驶,网络会认为车辆离自己非常近。
那么问题来了:错误的深度估计促成了正确的光流(位姿)估计!
直接添加正则化可行吗?
学习这种运动规律比学习静态背景的深度要困难得多。
那Dynamo-Depth这篇文章是怎么做的呢?
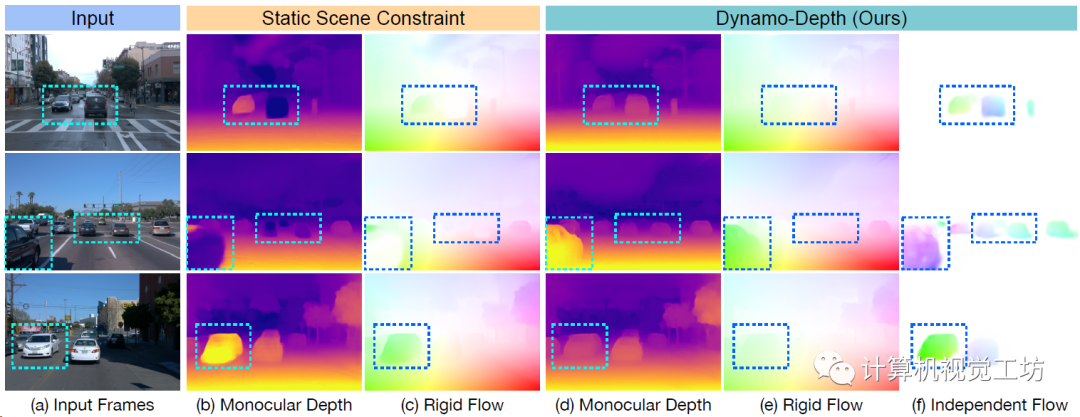
核心思想是,仅建模相机运动引起的刚性流的话,不能完整描述动态对象。因此要再学习一个独立的三维光流场(场景流?),捕捉动态对象的运动。
具体的Pipeline包括两部分,上半部分是依据静态假设,借助target帧的深度和位姿估计静态3D光流场,下半部分是借助独立光流估计和运动mask估计动态3D光流场。两个光流场叠加再去恢复target图像并做损失。
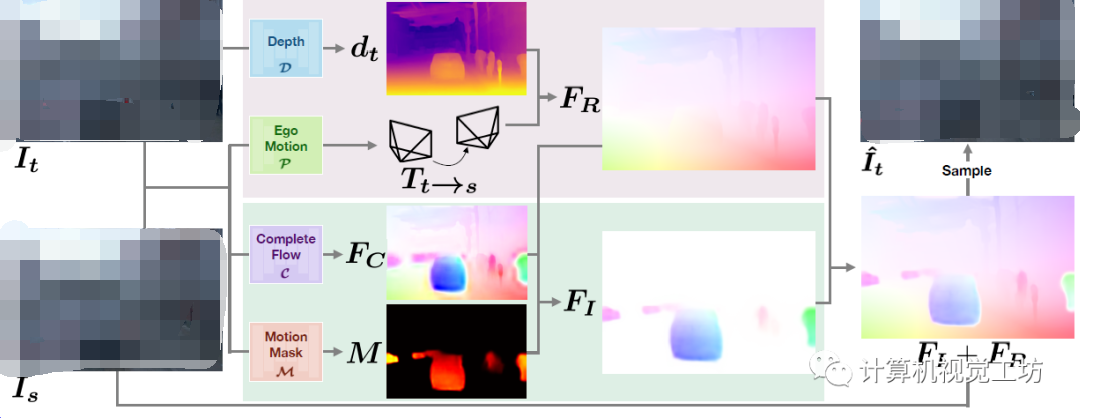
为啥不直接预测动态物体的3D光流场呢?
有两个原因:
1、在训练过程中,当输入帧中的目标运动是相机和独立运动的叠加时,直接预测目标的独立运动非常困难;
2、独立刚体运动FI更倾向稀疏化,也就是倾向没有动态物体。在训练初期,当深度和位姿的预测有噪音时,会出现一个高稀疏项导致网络直接收敛。
4. 实验结果
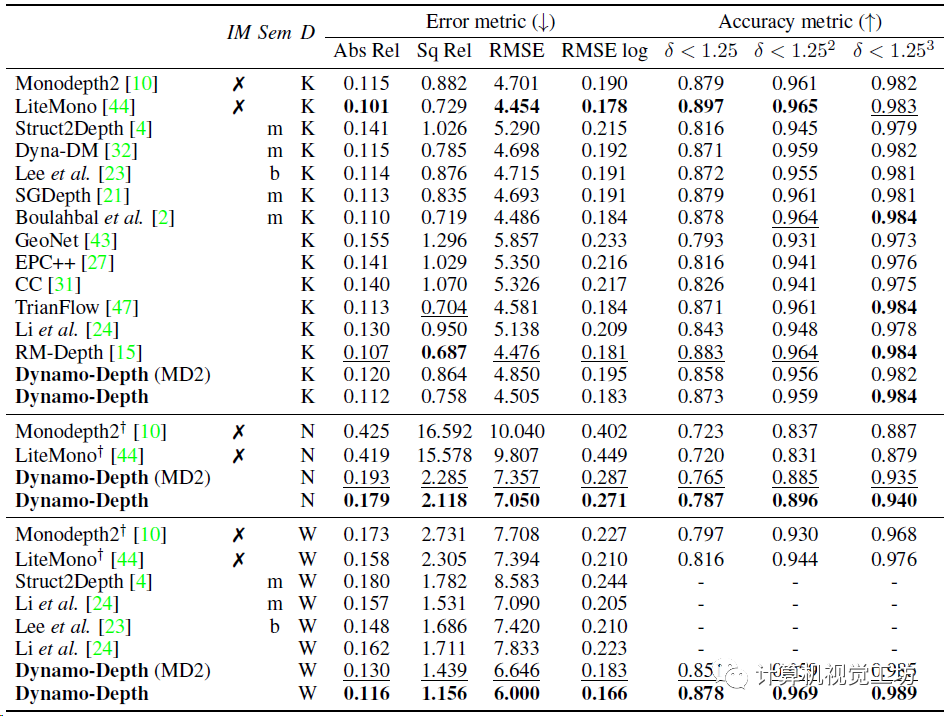
数据集使用的Waymo Open、nuScenes还有KITTI Eigen split,训练使用了4块NVIDIA 2080 Ti,batch size为12,初始学习率5e-5(深度估计的bs和lr都很小)。平均指标就用的普通的Abs Rel、Sq Rel、RMSE、RMSE log还有三个准确率。
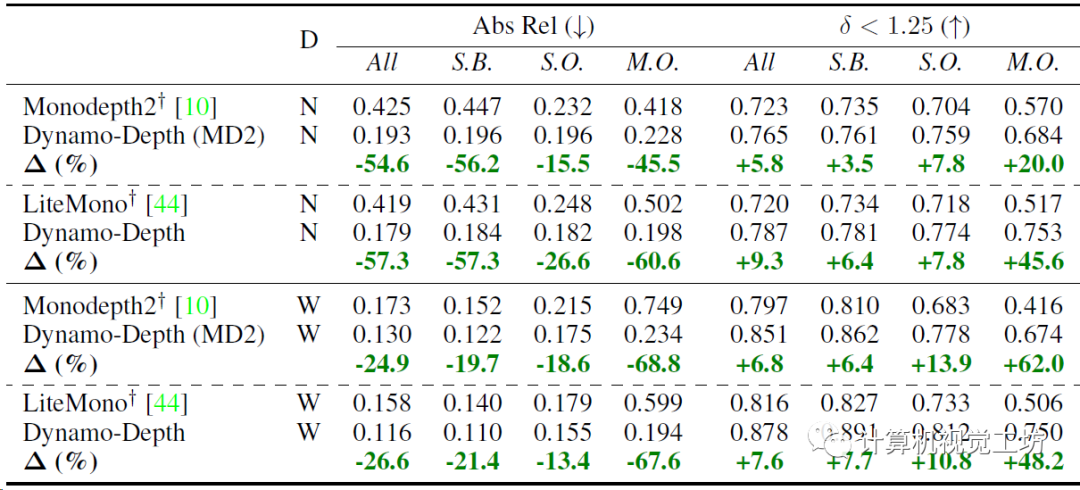
深度估计的精度定量对比,K表示KITTI,N表示nuScenes,W表示Waymo Open。nuScene和Waymo Open的Abs Rel分别降低了57%和21%,性能提升明显。KITTI上的效果不太好,作者认为这是因为KITTI上的动态目标太少。
动态和静态区域深度估计性能对比,分割nuScene、Waymo Open为静态背景和动态对象,并评估每个区域上的深度估计性能。Waymo Open效果最明显,精度提高了48.2%,误差减少了67.6%。
深度和光流估计的定性对比,可以发现他们这种方法解决了极线歧义问题。也就是说,不会用错误的深度值去预测正确的光流场。
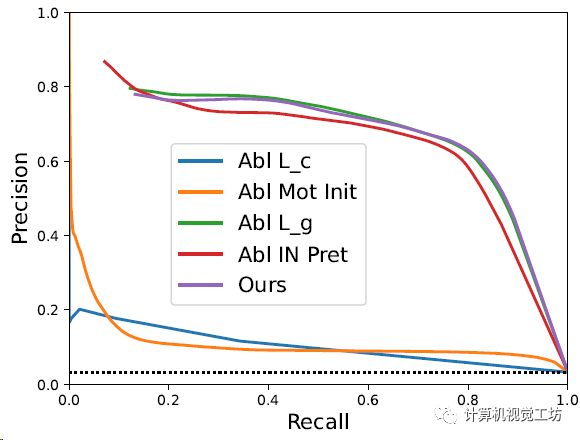
Waymo Open上的曲线对比,也算是消融实验,使用精确度和召回率评估联合学习的二进制运动掩码网络的质量。随着召回率的增加,Dynamo-Depth也有很高的精确度,在Waymo Open上达到了71.8%的F1得分。
5. 总结
Dynamo-Depth这项工作面向自动驾驶场景中的车辆共线运动,感觉还像是特殊场景的应用,主要原理是联合学习深度、位姿、3D独立运动和运动分割。在Waymo Open和nuScenes数据集效果比较好,但感觉应用场景很局限。从动态物体的处理上,还是SC-DepthV3要更胜一筹。
审核编辑:黄飞
-
Firefly RK3399Pro开源主板 + 单目摄像头,人体特征点检测方案2022-04-01 2776
-
基于单目深度估计的红外图像彩色化方法_戈曼2017-03-17 713
-
基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度2018-06-04 36552
-
UC Berkeley大学的研究人员们利用深度姿态估计和深度学习技术2018-10-12 3645
-
场景视频景深学习领域,谷歌AI公布三项最新研究突破2019-04-29 3246
-
采用自监督CNN进行单图像深度估计的方法2021-04-27 1338
-
一种用于自监督单目深度估计的轻量级CNN和Transformer架构2023-03-14 4149
-
介绍第一个结合相对和绝对深度的多模态单目深度估计网络2023-03-21 9064
-
TUM&谷歌提出md4all:挑战性条件下的单目深度估计2023-09-04 1646
-
一种利用几何信息的自监督单目深度估计框架2023-11-06 1206
-
使用自监督学习重建动态驾驶场景2023-12-16 1851
-
单目深度估计开源方案分享2023-12-17 1965
-
【AIBOX 应用案例】单目深度估计2025-03-19 1448
-
双目视觉是如何实现深度估计的?2025-12-31 936
全部0条评论

快来发表一下你的评论吧 !
