

国产FPAI芯片的AI系统方案
描述
各位亲爱的老铁,继上次《漫谈人工智能与国产FPAI芯片》唠完已经过去一个多月了;真的是时间不等人呀,2023年马上就要over了,最后一个月,大家要继续努力卷呀,come on!!!
漫谈人工智能与国产FPAI芯片
今天,小弟和大家谈一谈某国产FPAI芯片的AI系统方案以及参考设计实例。
1)FPAI芯片架构:博采众长、兼容并蓄
首先,我们简单了解下FPAI(Field Programmable AI)芯片。FPAI芯片,创新性地采用了异构融合架构,即在一颗die上集成了高性能SOC(PS)、大容量FPGA(PL)、AI加速引擎(AI)三大模块。该异构融合架构,可谓“博采众长、兼容并蓄”,融合了各异构模块优势,特别适合AI计算。其中,高性能SOC优势在于控制和通用计算,使得能在单芯片上运行完成完整的AI计算;大容量FPGA优势在于可重构和高速接口,解决了长尾算子的难题,适应了AI算法不断的迭代升级趋势;AI加速引擎优势在于高性能、低功耗地完成卷积等计算密集型算子的计算。
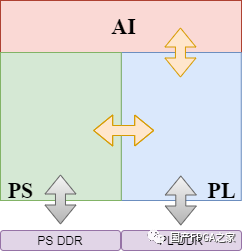
图1 FPAI芯片架构:异构融合
具体的,以下是某款国产FPAI芯片,该芯片资源很丰富。PS部分,有四核处理器CPU、视频编解码模块VPU、图像处理模块GPU等;PL部分,有444K的逻辑资源,16个高速接口GTX;AI部分,有高达27.52TOPS的int8算力,精度支持int8和int16,配合AI编译器支持快速部署
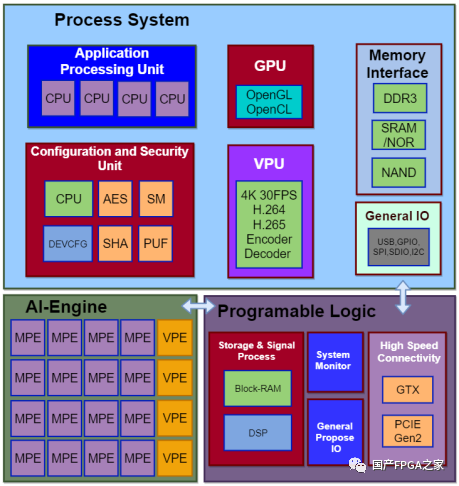
图2 某国产FPAI芯片资源
综上,该颗FPAI芯片支持丰富的AI应用场景,特别适合边缘融合端的AI应用场景。
2)FPAI系统方案:好马配好鞍,好船配好帆
从芯片到系统产品,还需设计硬件,开发FPGA程序,开发软件程序,部署AI网络等。系统方案及对应的参考实现,提供了一整套完整的解决方案参考,能够帮助用户方便、快速、高效、可靠地完成自己产品的设计。
所谓“好马配好鞍,好船配好帆”,不同芯片需要适合的系统方案以及对应的参考设计。
首先,FPAI芯片是PS+PL+AI的架构,对外接口管脚位于PS、PL模块,因此依据外部数据流输入的管脚,设计了PS_IN、PL_IN的系统方案,以此对应不同的内部控制流数据流方案;然后,FPAI芯片的AI峰值算力达27.52Tops,能够支持多路数据流的不同的AI计算,视频编解码模块能支持多路视频流的压缩,可编程逻辑资源也支持多输入的高速数据流接口,因此依据以上算力特点,设计了多源的系统方案,以此也符合了边缘融合端的AI应用特点;此外,PCIe加速板卡的系统方案,配合主机服务器,完成AI的推理计算加速。
综上,基于FPAI芯片的架构、算力、资源、输入数据流来源、应用场景等特点,分别制定了如下4种系统方案,基本能够涵盖FPAI单芯片下的各种应用场景。
(1)PS_IN系统方案
(2)PL_IN系统方案
(3)多源系统方案
(4)PCIe加速卡系统方案
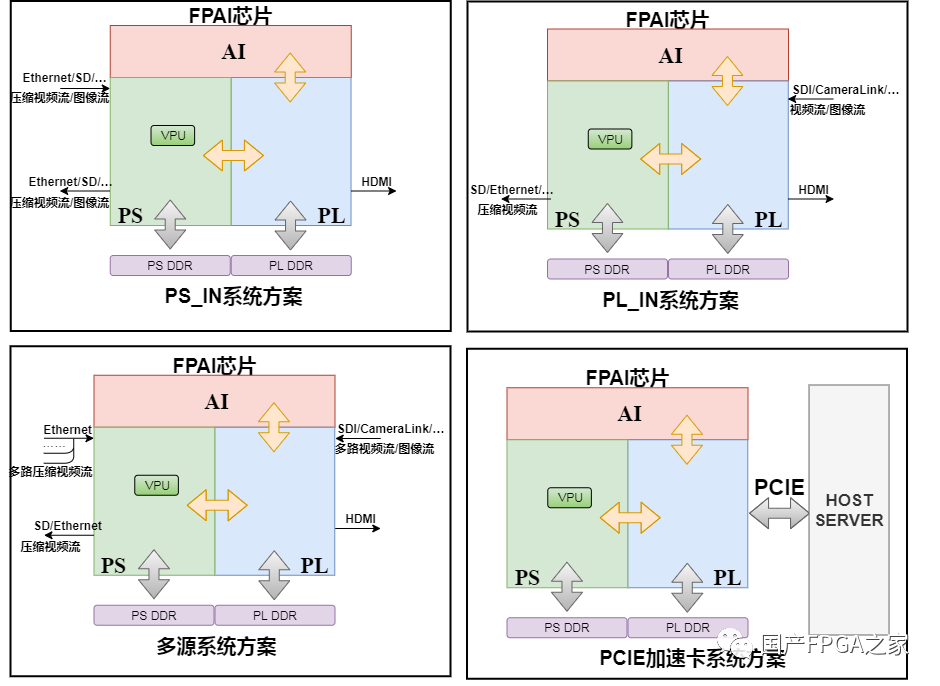
图3 FPAI芯片的系统方案
一个系统方案可能有多个具体的参考实现,但对应的设计架构是一致的,可能只是具体内部实现有区别。参考设计会提供一整套参考方案,包括硬件设计、FPGA设计、软件设计的代码和相应文档。因此,想要基于FPAI设计系统的朋友,可以依据自身的应用场景需求,选择上述系统方案的参考设计。
3)多路PL_IN+VPU编码的参考设计实例
好了,说了这么多,大家等不及要看具体的参考设计实例吧。以下会介绍多源系统方案的一个参考设计实例:多路PL_IN+VPU编码的参考设计,分别从参考设计概述、硬件板卡介绍、FPGA工程介绍、软件工程介绍、实例功耗介绍等5部分来介绍该实例。
3.1参考设计概述
输入:4路SDI摄像头,默认分辨率和帧率设置1080p@30Hz;
输出:SD卡,H.265/H.264格式文件格式;
VPU:分辨率1080p,YUV422输入, 输出 H.265/H.264,默认编码帧率设置30Hz;
检测:运行示例网络Yolov5s AI检测,带检测结果的视频压缩到SD卡。
性能:4路1080p@30Hz输入,AI+VPU编码,每一路30fps。
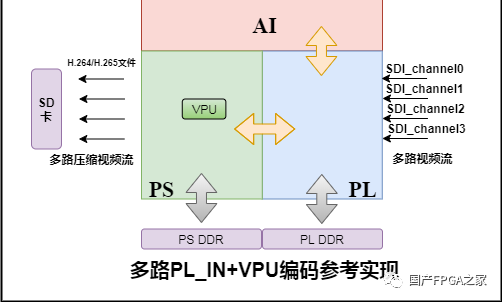
图4 多路PL_IN+VPU编码的参考实现框图
3.22
悟空硬件开发板简介
如下图,采用SDI接口摄像头输入4路视频到板卡,悟空硬件板卡上主芯片FPAI芯片;SD卡,储存和启动Linux操作系统启动文件和根文件系统;1GB PS DDR和2GB PL DDR,用于运行操作系统和AI;通过子卡接入的4路SDI视频接口;网口、串口、JTAG调试接口等。

图5 悟空硬件开发板
3.32
FPGA设计介绍
首先,整体数据流如图所示:
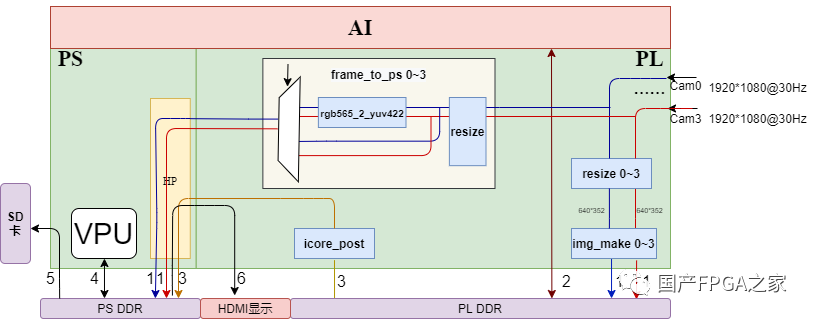
图6 多路PL_IN+VPU编码的数据流
Step1:对应图中的数据流1,Cam0~Cam3为4路不同的SDI摄像头视频流,帧率1080p@30Hz。对于每一路SDI摄像头视频流,复制成两路,一路经过resize、image_make模块完成AI预处理后存入PL_DDR,供AI检测使用;另一路经过resize、rgb565转为yuv422(可选)通过HP接口存入PS_DDR,供后续画上检测结果后VPU压缩用或者HDMI显示用。
Step2:对应图中的数据流2,启动AI访问PL_DDR完成AI的计算。
Step3:对应图中的数据流3,最后一层特征图,经过icore_post模块处理后,通过HP接口写入PS_DDR。PS完成剩余后处理计算,得出AI检测结果,画在PS DDR上的视频帧上。
Step4:对应图中的数据流4,启动VPU,对含有结果的视频帧压缩成H.264/H.265格式。
Step5:对应图中的数据流5,将压缩视频流写回SD卡。
Step6(可选):对应图中数据流6,将检测框的视频显示到HDMI显示屏。
其次,介绍以下子数据流通路的实现
(1)Camera -> PLDDR的逻辑通路实现
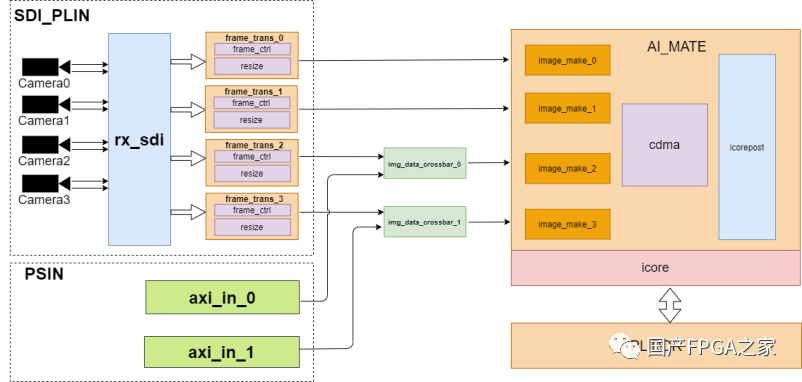
图7 子逻辑通路Camera -> PLDDR
输入的4路视频流帧率为1080p@30Hz,均以serdes 差分对接入FPGA端口,通过rx_sdi模块解析为rgb888数据格式。然后经过frame_trans模块resize成AI计算所需要的尺寸。
在一些应用场景中,输入数据可能预先存储在了PS DDR中,因此本工程也预留了2路独立的PSIN数据通路,通过HP口读取数据,转变成AI_MATE接口规范好的数据总线格式。这两路PSIN数据通过img_data_crossbar_0/1模块分别与CAM2/3视频流数据进行仲裁,各自选出1路输入给AI_MATE端。
(2)Camera -> PSDDR的逻辑通路实现
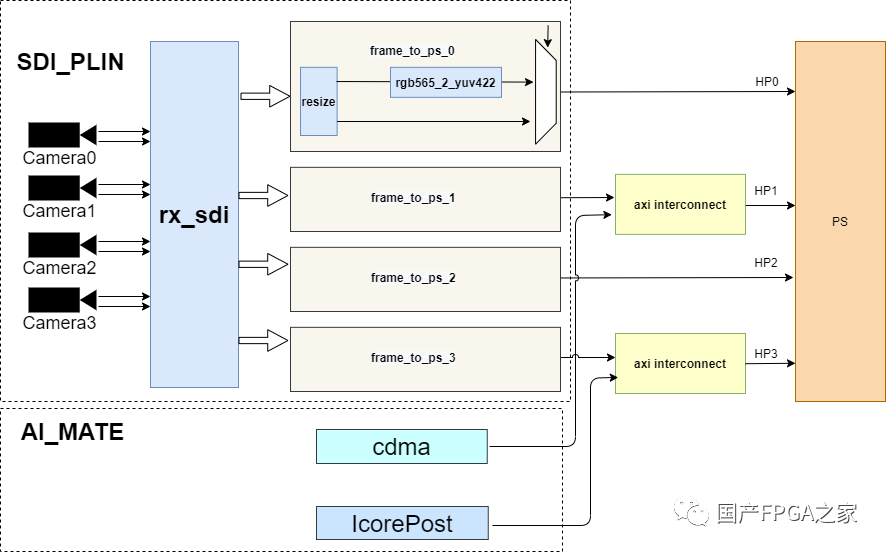
图8 子逻辑通路Camera -> PSDDR
将CAM视频流数据resize成VPU压缩需要的尺寸,注意此处的resize与CAM->PL DDR通路中的resize相互独立,即AI计算尺寸和VPU压缩尺寸独立配置。为了减少写入PS DDR的数据量,这里将rgb565数据格式转为yuv422(16bit),相比于rgba(32bit)格式,数据量可减少50%,而图像色度分量完整保留,基本不影响图像质量。
每一路CAM数据均需要通过HP口写入PS DDR,PS端共有4个HP口,有很多模块会对它发起请求,因此工程中在BlockDesign中调用axi interconnect IP进行仲裁。
最终,实现的FPGA资源占用情况如下所示:
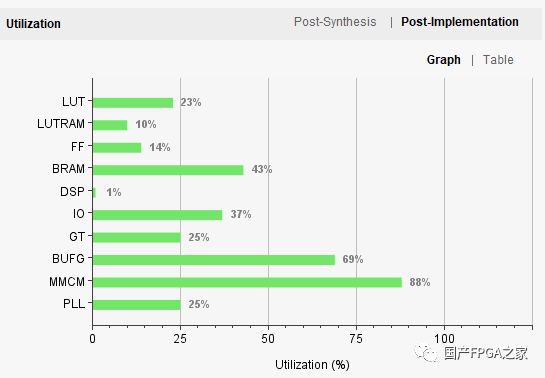
图9 FPGA实现资源占用情况
3.42
软件设计介绍
参考实现软件整体流程可以归结如下:
摄像头输入视频数据 > AI检测 > AI结果绘制 > vpu编码h264/h265视频 > 输出数据流
软件中按功能将代码封装为多个模块:摄像头模块、神经网络模块、VPU模块。则在实现一次完整数据流通路对应的模块调用为:摄像头模块取帧 > 神经网络模块计算与后处理 > 摄像头模块得到图像数据 > vpu模块压缩 > vpu模块输出数据。
在AI调度过程中,采用了任务队列的实现方式。主要参考了生产者消费者设计模式,前处理、icore前向、后处理运行在各自的线程中,互相之间通过任务队列的方式通信。
对于多路的情况,则会使用多个前处理线程与多个后处理线程,以4路为例,4路不同的输入图像数据、icore推理结果会存放在ddr的不同位置,不同路之间数据不会相互干扰。任务队列还提供了可以控制不同路是否做AI或者设置优先级的功能。
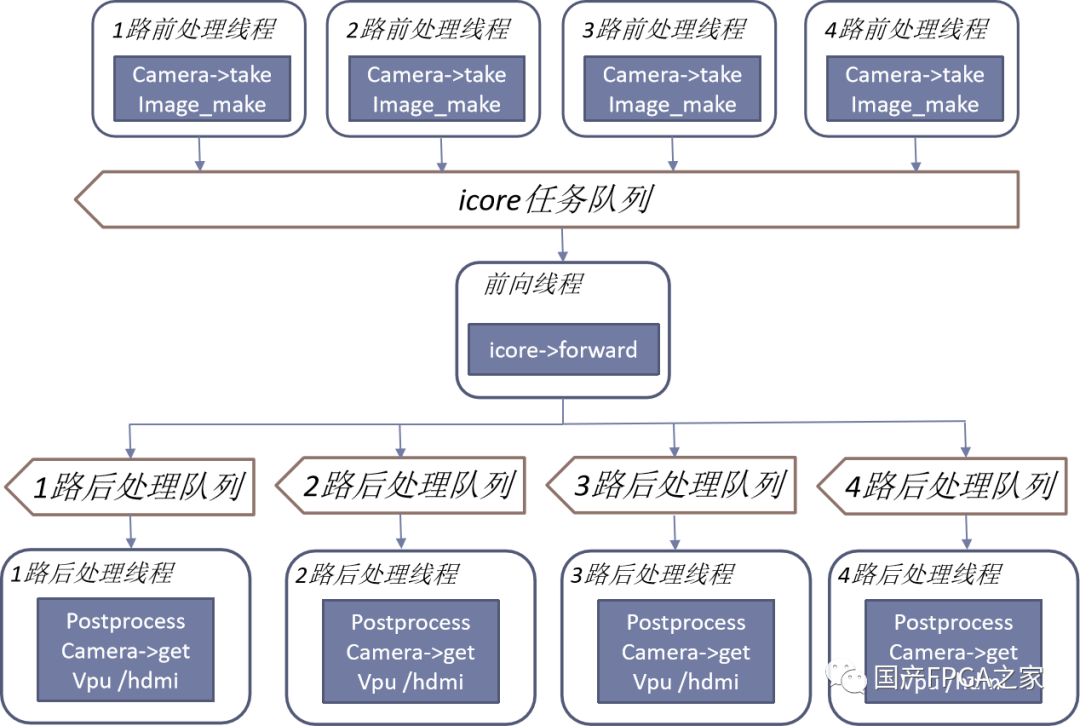
图10 软件任务队列调度框图
具体的AI神经网络部署,基于icraft编译器,直接编译生成json和raw文件,就能够更新参考设计的AI网络部署。
3.52
实例结果介绍
性能:能够稳定完成4路1080p@30Hz视频的AI检测和视频编码。
功耗:整体芯片功耗(含DDR)是12.32W。
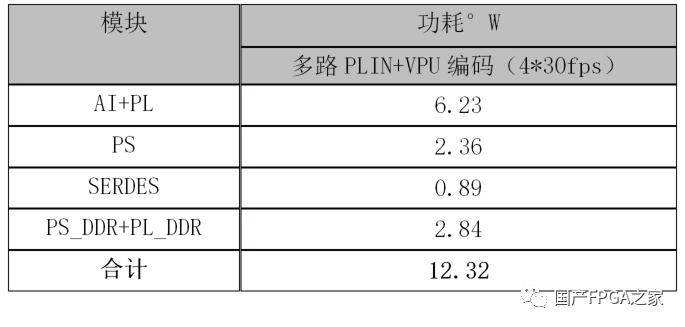
表1 多路PL_IN+VPU编码的功耗
4)小结:海阔凭鱼跃,天高任鸟飞
好了,经过以上的参考设计实例的介绍,相信大家对FPAI芯片的系统方案以及参考设计有了更深层次的了解。
近几年,边缘端AI计算的市场份额逐年增长明显,越来越多的落地应用需求提出。“海阔凭鱼跃,天高任鸟飞”,如何选择一款AI芯片及系统方案,能够满足边缘融合端的各种应用场景,能够适应算法迭代的需求,能够解决长尾算子的问题,形成高性能、低功耗、灵活可靠的产品?相信FPAI芯片及系统方案,会是一个不错的选择!
审核编辑:汤梓红
-
国产FSV8023替代方案|ISO15693远距离NFC芯片国产替代落地体验,兼容进口方案无需改板2026-07-24 121
-
基于米尔RK3576核心板的国产割草机器人解决方案2026-04-24 572
-
国产AI芯片厂商燧原科技正式入驻Gitee2026-03-20 1001
-
deepseek国产芯片加速 DeepSeek的国产AI芯片天团2025-02-10 6817
-
国产RISC-V芯片性能稳定吗?2024-05-20 1365
-
谈一谈FPAI芯片的AI系统方案以及参考设计实例2023-11-28 6873
-
AI系统供电电源芯片及解决方案2021-08-30 7460
-
国产自动驾驶AI芯片应该如何快速发展2020-09-20 3087
-
首颗国产车规级AI芯片即将量产 国产汽车芯片即将迎来一大突破2020-03-09 3414
-
【免费直播】AI芯片专家陈小柏博士,带你解析AI算法及其芯片操作系统。2019-11-07 3827
-
通用型AI语音识别芯片音旋风611如何?2019-09-11 3440
-
手把手教你设计人工智能芯片及系统--(全阶设计教程+AI芯片FPGA实现+开发板)2019-07-19 8996
-
国产芯片RK3066 RK3188 RK3288 这些芯片性能怎么样呢2015-12-29 11440
全部0条评论

快来发表一下你的评论吧 !
