

网络安全性威胁的种类和防范方法
描述
计算机网络在给我们带来便利的同时,也存在很多安全隐患,比如信息伪造,病毒入侵,端点监听,SQL 注入等,给我们日常生活造成很严重的影响。
网络安全性威胁的种类
在网络通信中可能会受到各种各样的潜在的安全性威胁,这些威胁总的来讲可以大致分为下面几类:
截获(interception):攻击者从网络上窃听他人的通信内容。
中断(interruption):攻击者会强制中断其他人在网络上的通信。
篡改(modification):攻击者会修改他人在网络上发出的报文。
伪造(fabrication):攻击者会在网络上发出伪造信息产生误导。
在上面四种网络安全类型中,截获是属于被动攻击的,因为截获主要为了窃听信息,它并没有攻击行为;而中断、篡改和伪造都是主动攻击,他们会产生攻击行为。
这里先来认识一个新的概念叫 PDU ,PDU 的官方解释是协议数据单元,但是它其实指的就是计算机网络这几层模型里面所描述的数据单元,比如应用层交换的就是应用数据,TCP 层的 PDU 交换的就是段。
在被动攻击中,攻击者只是观察和分析 PDU ,并没有对通信内容造成干扰。通过观察和分析 PDU,进而了解通信双方的通信类型,通信双方的地址和身份,这种被动攻击又叫做流量分析(traffic analysis)。
主动攻击是指攻击者对通信内容中的 PDU 进行各种处理。比如有选择的更改、替换 PDU 中的记录,甚至还可以伪造 PDU ,记录之前截获的 PDU ,在其他连接中释放此 PDU ,造成通信干扰和破坏。
主动攻击还可以细分为下面三种类型:
更改报文信息:这个就是我上面说到的替换修改甚至伪造报文信息,对 PDU 的真实性和完整性进行攻击。
拒绝服务:攻击者会在网络上发送大量的分组,使得目标服务无法处理大量的分组信息,使得目标服务器无法提供正常有效的服务,这种攻击又叫做 拒绝服务 Dos(Denial of Service),还有一种由成千上万个分布式节点一起对目标服务器发起攻击的方式,叫做 分布式拒绝服务 DDos(Distributed Denial of Service)。
连接伪造:攻击者试图使用之前记录下来的信息和身份进行伪造发起连接请求。
那么我们该如何知道计算机被攻击了呢?
对于被动攻击,通常是无法检测出来的,对于主动攻击,我们通常会以下面这几个大前提进行防范:
防止析出报文内容
防止流量分析
检测更改报文内容
检测 DDos
检测伪造初始化连接
对于被动攻击,可以采用各种数据的加密技术;对于主动攻击,可以采用防范措施与加密技术结合防范。
还有一种威胁比较大的是恶意程序,会对互联网造成比较大的影响,据史料记载,互联网编年体到现在出现比较大规模影响的病毒有:计算机病毒、计算机蠕虫、特洛伊木马、逻辑炸弹、勒索软件等。
数据加密的模型
由于通信存在不安全性,所以出现了加密技术,使用加密技术对报文进行加密后,再传到目标服务器后再进行解密,一般的加密和解密模型如下图所示:
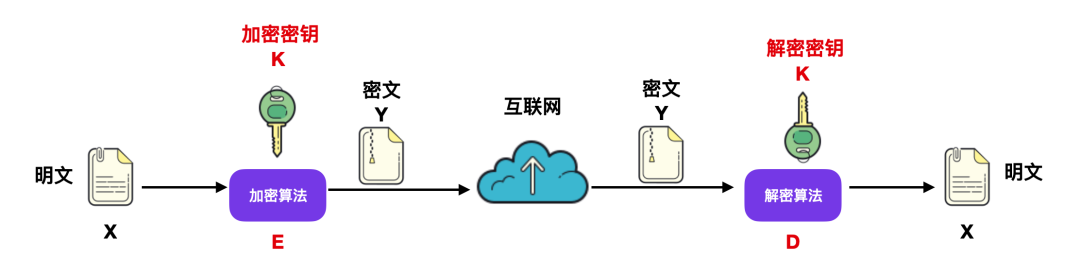
上图所示的加密密钥和解密密钥所使用的密钥 K 通常是一串字符串,一般来说会有下面这种公式
Y = Ek(X)
通过加密算法使用加密密钥对明文 X 进行加密。
解密算法是加密算法的逆运算,再进行解密时如果不使用事先约定好的密钥 K 就无法完成解密工作。
Dk(Y) = Dk(Ek(x)) = X
这里我们假设了加密密钥和解密密钥是相同的,但真实情况未必一定是相同的,只不过加密密钥和解密密钥存在着某种关联性,这个密钥通常由密钥中心提供。当密钥进行传输时,一定要经过安全信道,否则会有安全风险。
这里延伸出来了两个新的概念,密码编码学(cryptography) 和 密码分析学(cryptanalysis)。密码编码学着重对密码进行设计的学科,密码分析学着重对报文进行分析,提炼出加密所使用明文或者密钥的学科。这两个学科合起来就是密码学。其实密码学归根结底就是做好加密和解密的这个过程。
对称加密和非对称加密
从很早以前人类就有了对通话内容进行加密的思想,进入 20 世纪以来,随着电子信息、线性代数以及计算复杂性理论等学科的研究深入,密码学进入了一个新的发展阶段,一共出现了两种密码机制:对称加密和非对称加密。
对称加密
所谓的对称加密,起归根结底在于加密和解密的密钥是相同的。
数据加密标准 DES(Data Encryption Standard) 就是一种对称加密的标准,DES 可以说是用途最广泛的对称加密算法。
DES 是一种分组密码,在加密前首先先对整个报文进行分组,每一组都是 64 位的二进制数据。然后对每一个 64 位的二进制数据进行加密,产生一组 64 位的密文数据,最后将各组密文串起来,就是整个加密密文。使用的密钥是 64 位(实际使用 56 位,最后 8 位于奇偶校验)。
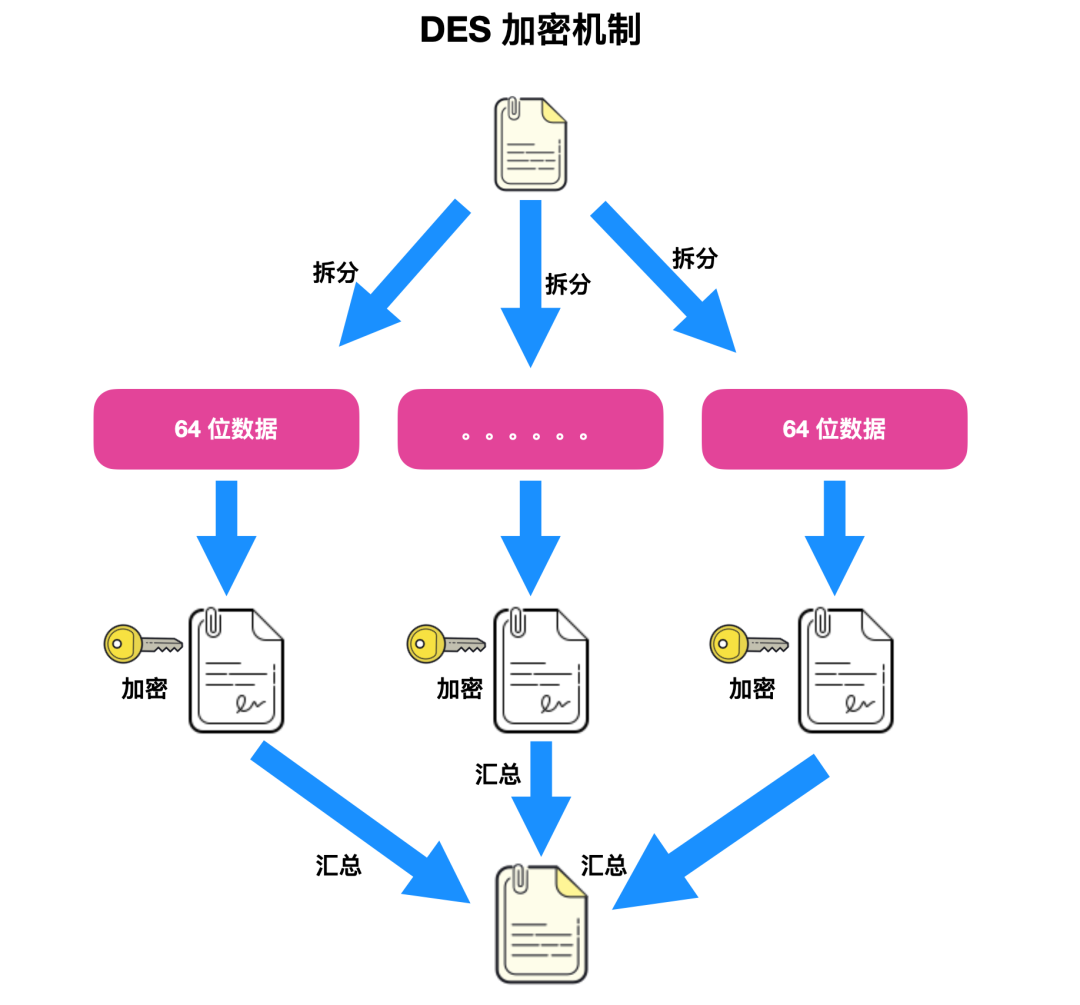
在 DES 分组加密机制中,进行保密的只是加密密钥,而加密算法是公开的。
不过 DES 的这种加密机制是存在弊端的:由于 DES 会把报文拆开成为一组一组的 64 位数据,64 位二进制数据有 56 位可用,所以数据总量是 2 ^ 56 次方,它的密码生命周期非常段,这个数据总量在现在的计算机世界非常容易被破解!在 1999 年当时价值 100 万和 1000 万美元的超级计算机暴力破解 DES 的密码分别用了 3.5 小时和 21 分钟。
在 DES 之后出现了 IDEA(International Data Encryption Algorithm) 算法,IDEA 使用的是 128 位密钥进行加密,这个长度很难被破解了。
非对称加密
非对称加密其实还有一个叫法是公钥密码加密,非对称加密使用的是不同的加密密钥和解密密钥。
非对称加密出现的原因大概是基于两个方面:一是由于对称加密的密钥分配问题,二是由于对数字签名的要求。在对称加密中,加密解密双方用的是同一种密钥,这是如何做到的呢?一种是事先约定,另外一种是使用互联网信使来传送。在大规模互联网中,用信使来传输密钥显然是不太合适的,但是如果采用事先约定的方式,那么对于后续的更新和迭代来说又比较困难。还有一种方式是使用安全系数比较高的密钥分配中心(Key Distribution Center),也会使网络的成本增加。
同时,一些需要对信息内容进行保密的机构越来越需要数字签名,根据数字签名,对方才知道某项内容是由特定的人或者公司产生的。根据这两项原因导致了非对称加密的出现。
非对称加密主要的算法有三种:RSA、DSA、ECDSA,目前使用最广泛、最普遍的非对称加密算法就是 RSA。RSA 采用的是数论中的大数分解方式。
非对称加密的特点是这样的:
某些能够生产公钥和私钥的密钥生成器会生产出一对公钥和私钥给接受者 B :即加密密钥 PKB 和 解密密钥 SKB。发送者所使用的加密密钥也是 PKB,这个密钥是公开的,而接受者的解密密钥 SKB 是非公开的,接受者 B 特有的。
发送者利用接受者的密钥 PKB 通过加密算法 E 对密钥进行加密,得出了密文 Y 再发送给接受者 B:
Y = E(PKB(X))
接受者 B 用自己的私钥通过解密算法 D 对密文 Y 进行解密,得出密文 X :
D(SKB(Y))= D(SKB)( E(PKB(X))) = X
下图是这个加密解密过程:
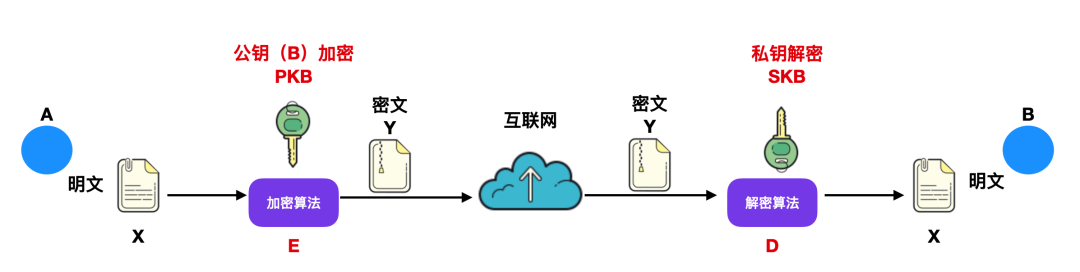
这里需要注意一点的是,任何加密方法的安全性都取决于密钥的长度,以及攻破密文所需要的计算量,而不是简单的取决于加密本身。
数字签名
我们在日常写信、上交某些材料的时候都需要亲笔签名或者使用手印、印章的方式来验证真实性,那么在互联网中如何验证其真实性呢?在网络通信中,使用数字签名的方式来验证,数字签名必须实现下面三点功能:
接受者能够核实发送者对报文的签名,确定报文是由发送者发出的,别人无法进行伪造,这叫做报文鉴别。
接受者确信所收到数据和发送者发送的数据是一致的,没有被篡改过,这叫做报文完整性。
发送者事后不能抵赖自己发送的报文,这叫做不可否认。
下面来讨论一下数字签名的鉴别过程:
首先,发送者 A 用自己的私钥 SKA 对报文 A 经过算法 D 后得出密文 D(SKA(X)),算法 D 不是解密运算,它只是一个能得到不可读的密文的算法。A 把经过算法 D 运算后得出来的密文传给 B,B 对其进行验签。B 会用 A 的公钥进行 E 运算,还原出报文 X 。
这里需要注意一点:任何人用 A 的公钥 PKA 进行 E 运算后都会得出 A 发送的明文 X ,所以下图中的 D 和 E 算法并不是加密解密算法。
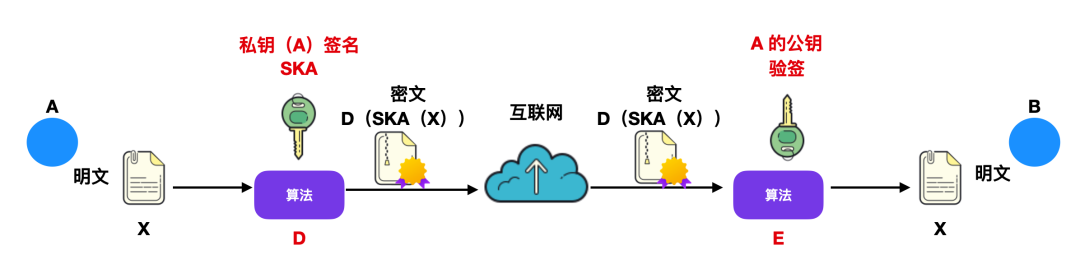
除了 A 之外没有人持有 A 的私钥 SKA ,所以除 A 外没有人能产生密文 D(SKA(X))。这样,B 就相信报文 X 是签名 A 发送的,这就叫做报文鉴别。如果其他人篡改过报文,但是却无法使用私钥 A 的签名 SKA,那么 B 使用公钥解密后就知道报文被篡改过,这样就保证了报文的完整性。如果 A 想要抵赖自己层发给过报文 B ,那么 B 就可以把 X 以及密文 D(SKA(X))拿给公证的第三者,很容易证明。这就是不可否认。
但是上述过程仅仅对报文进行了签名,却并没有对报文本身进行任何加密操作,如果传输的过程中被攻击者截获到了 D(SKA(X))并且知道发送者身份的人,就可以通过查阅相关手册知道 A 的公钥,从而得知 A 的明文,这显然是不安全的,如何解决呢?
需要使用上面的非对称加密算法再对明文 X 进行加密一波,示意图如下。
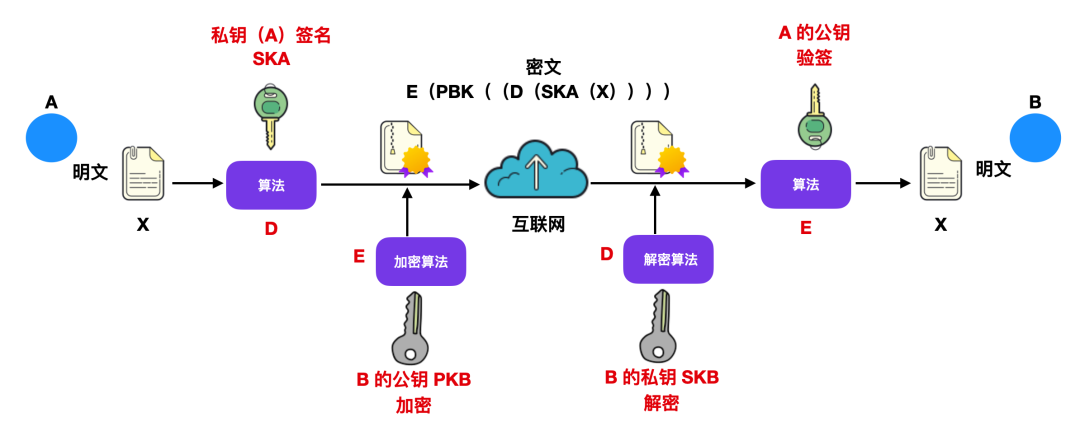
示意图画出来,估计大家也好理解,无非就是增加了一步用 B 的公钥加密,在用 B 的私钥解密的过程。
鉴别
在网络应用中,通常为了保证网络安全性,我们需要对通信的对象进行鉴别,鉴别是网络安全中一个很重要的方式。上面探讨了两种加密手段和加密模型,加密能够实现报文的安全传输,从而保证报文的安全性;而鉴别和加密并不相同,鉴别是要验证通信的对方是否是自己所要通信的对象,从而避免冒充者冒充。
鉴别的方式主要有两种:一种是对报文进行鉴别,即所收到的报文的确是报文的发送者所发送的,而不是其他人篡改和伪造的,这种方式我们通常称作报文鉴别;另外一种方式是对通信的端点进行鉴别,这个端点可以是一个人,也可以是一个进程(包括客户和服务器),这种方式我们通常称为实体鉴别。
下面我们就针对报文鉴别和实体鉴别进行探讨:
报文鉴别
在网络上传输的报文有些是并不需要加密的,比如某些不涉密的报文,但是却需要数字签名,以此来让接收者能够鉴别报文的真伪。对于某些长报文来说,对其进行数字签名比较耗费时间,这样会增大 CPU 的负担,所以当报文不需要加密解密的情况下,需要一种简便的方式鉴别报文的真伪。
我们通常使用报文摘要 MD(Message Digest)算法来进行报文鉴别,如下图所示:
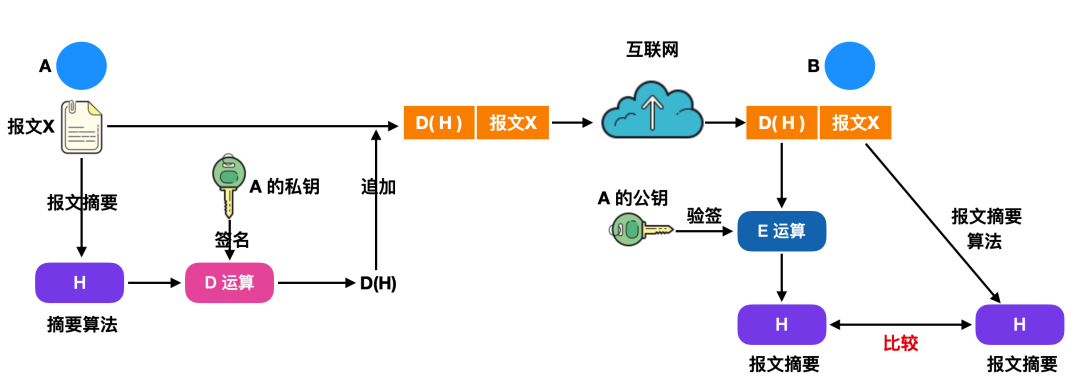
上图中 A 发送的报文 X 通过报名摘要算法得出摘要 H,然后用自己的私钥对 H 进行 D 运算,也就是进行数字签名。得出来已签名的报文摘要 D(H) 后,将其追加在报文 X 后面,通过互联网传输到目标主机 B。B 收到报文后,首先把已签名的 D(H) 和报文 X 分离,然后再需要做两件事:一是用 A 的公钥对 D(H) 报文摘要进行 E 运算,得出一个报文摘要 H ,二是对报文 X 使用报文摘要算法得出报文摘要 H ,再与一中的 H 进行比较,以此进行报文鉴别。报文摘要的优点是:相较于长报文来说,对短一些的定长报文进行数字签名要比整个长报文进行数字签名要简单很多,所耗费的资源也比较少,但是对报文 X 来说效果差不多。报文 X 和报文摘要 D(H) 合在一起是不可伪造并且可检验的。
报文摘要算法其实就是一种散列函数,这种散列函数其实是 hash 算法的一种,但它不同于 hash 算法,报文摘要算法是密码编码的校验和,校验和我们知道,就是用来检验消息是否存在丢失情况的一种标志。用来防止偶然出现的差错,但是报文摘要算法是防止报文被人恶意修改的。
报文摘要算法是一种单向(one-way)函数,单向的意思是不可逆。校验和算法也是一种单向的,这种单向说的是给出一个报文,我们很容易能够计算出它的校验和,因为校验和的长度固定并且比较短,但我们不能通过校验和逆推出原始报文。报文摘要算法也是一样的,我们可以计算出一个长报文 X 的摘要 H ,但是不能从摘要 H 逆推出报文 X 。并且,不同报文的报文摘要也是不同的,这就是说若是想找到两个相同的报文摘要也是不可能的。
报文摘要算法中用途最广泛的算法就属 MD5 加密算法,MD5 算法的过程是将任意的数据映射成为一个 128 位长的函数,这个函数也是摘要信息,并且这个压缩过程不可逆,压缩完成后的消息摘要无法再还原成原始报文信息。MD5 算法最终会压缩成为一个 128 位长的数据,由 0 和 1 组成,这种组成理论上有 2 ^ 128 种可能,这个数据量非常庞大,约等于 3.14 乘 10 ^ 38 次方,虽然这个数据非常庞大,但自然界理论上的数据是无限的,仍然存在碰撞的可能,只不过这个概率非常小,MD 5 可用于数字签名、信息完整性校验。
对于信息安全要求比较高的数据,一般会改用其他算法,比如 SHA-2,MD5 算法无法检测碰撞,因此不适用于安全验证。
SHA-2 是一种密码散列标准,它的前身是 SHA-1 ,同属于 SHA 算法,除此之外还有 SHA-3,MD 5 和 SHA - 1 算法存在安全性问题,而 SHA-2 和 SHA 3 是比较安全的。
实体鉴别
实体鉴别是在整个过程中对与自己通信的实体进行鉴别,整个过程中只需要鉴别对端主机一次,而报文鉴别是对每一个收到的报文都进行鉴别,这是这两个鉴别方式的不同。
下面是一个实体鉴别的过程:
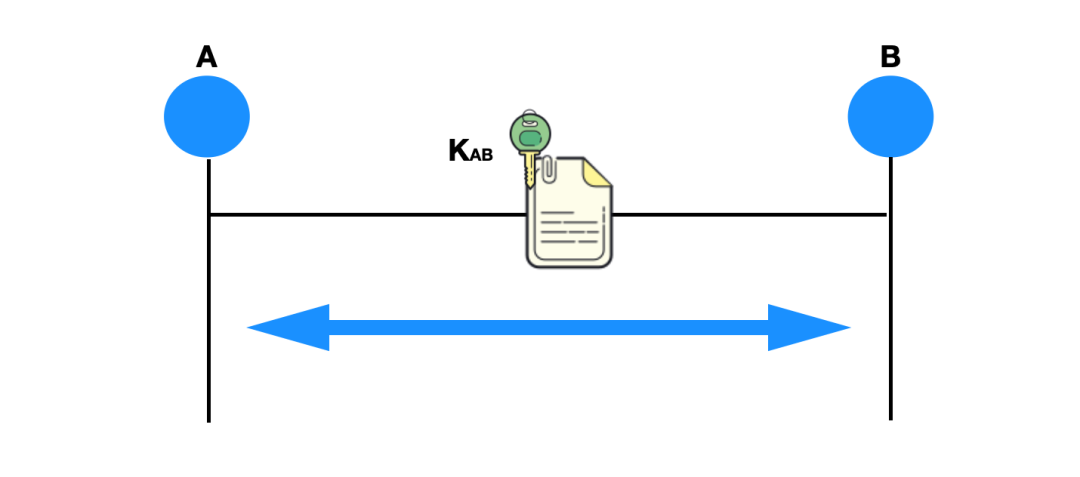
上图 A 向 B 发送有自己身份信息的报文,并且使用了双方共同协商好的对称密钥 KAB 进行加密,B 收到报文后再用对称密钥 KAB 进行解密。
大家认为这种传输方式安全吗?有没有什么问题?
实际上这种鉴别方式有着比较明显的漏洞,比如这时候有个入侵者 C 监听了 A 和 B 传输的这条链路,等 A 把报文发给 B 的过程中,入侵者 C 就会截获 A 发送给 B 的报文,入侵者并不用关心这个报文的内容如何,也不用解密报文的内容,它只需要伪装成报文的发送者把消息发给 B,就会让 B 误以为是 A 发送的报文,进而与伪造者 C 进行通信,这样就会把很多应该发送给 A 的报文发送给伪造者 C ,这种方式就叫做重放攻击(reply attack)。伪造者 C 还可以伪装 A 的 IP(IP 欺骗),这样更能够让 B 上当。
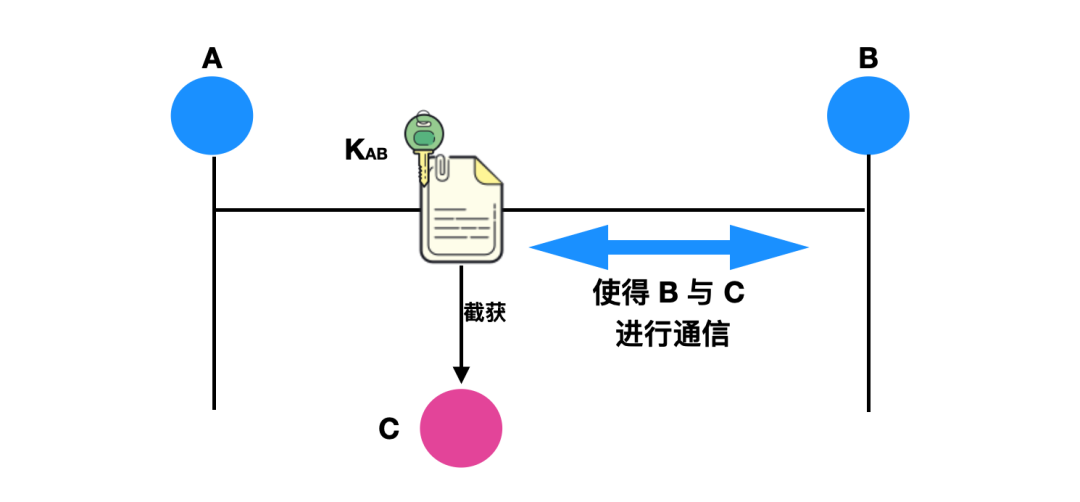
解决这种问题可以使用一种不重数机制,不重数顾名思义就是一个不重复使用的大随机数,每次发送报文都会生成一次随机数,每个随机数只使用一次。
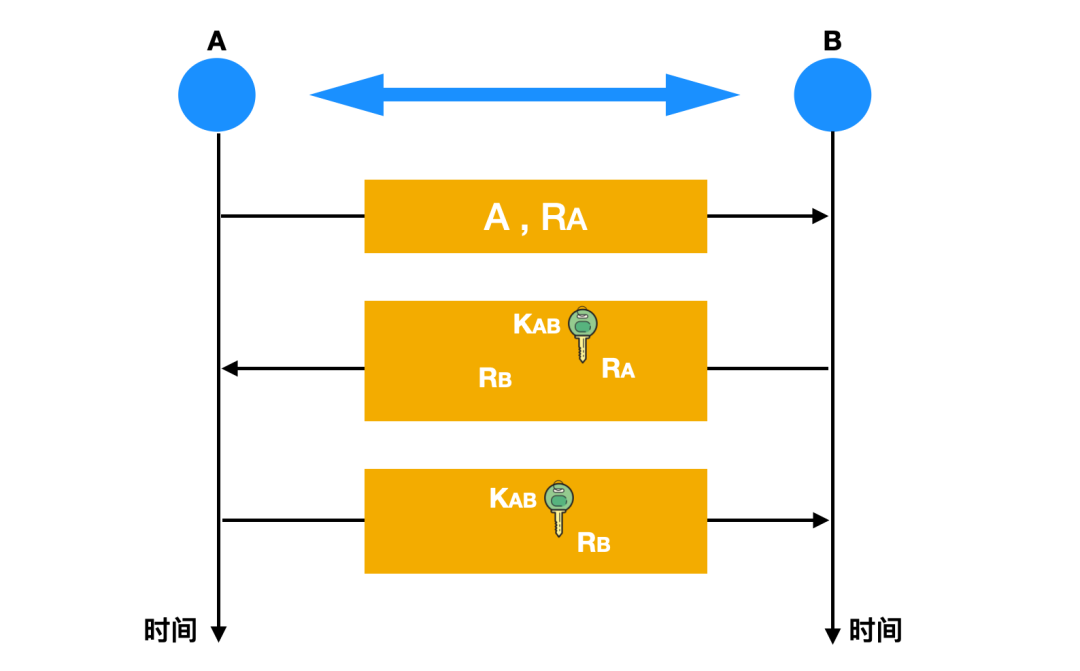
如上图所示,A 首先用明文发送一个自己身份 A 和一个不重数 RA 给接收者 B,B 收到之后会用自己的公钥 KAB 对不重数 RA 进行加密,并生成一个不重数 RB 一起发送给 A,A 收到消息后再用共享密钥对 RB 加密之后再发送给 B 。
这个过程可能大家看的云里雾里的,那么就让我给大家举一个浅显易懂的例子:
发送者 A 给接收者 B 发送了一个不重数为 10001 的数据;
接收者 B 向发送者 A 回送数据时,会用自己的私钥对这个 10001 的不重数进行加密,并给 A 发送自己的不重数 10086;
发送者收到上述数据后,再使用接收者的公钥将密文进行解码,发现解码后的不重数是 10001,然后再使用自己的私钥对 10086 进行加密,跟随数据一起发送给 B。
上面举例的私钥和公钥就是一对公钥密码体制,他们可以对不重数进行签名,用来验证对方的身份。上述中的接收者 B 用私钥签名后不重数发给 A ,A 就能够用公钥对不重数进行解密,进而验证 B 的身份。同样的 B 也可以采用同样的方式验证 A 的身份。
但是这种加密方式也存在风险:
比如这时有个攻击者 C 截获了 A 对 B 的消息说,我是 A ,于是 B 生成一个不重数发送给本应该是 A 接收,但是却被 C 截获的消息,于是 C 用自己的私钥对不重数进行加密,然后发送给 B ,B 向 A 发送报文,要求 A 把公钥发送过来,但是这条消息也被 C 截获了,于是 C 把自己的公钥冒充是 A 的公钥发给了 B ,然后 B 用收到的公钥对不重数进行解密,此结果当然是正确的,因为 C 完全冒充了 A ,于是 B 给 A 发送的很多敏感消息也都被 C 截获了。
不过这种冒充方式不太高明,B 很容易就能够与 A 进行沟通来揭穿 C 的骗局。
是不是觉得有些简单?不过下面的中间人攻击(man-in-the-middle attack) 就不好揭穿了,因为这更具有隐秘性。
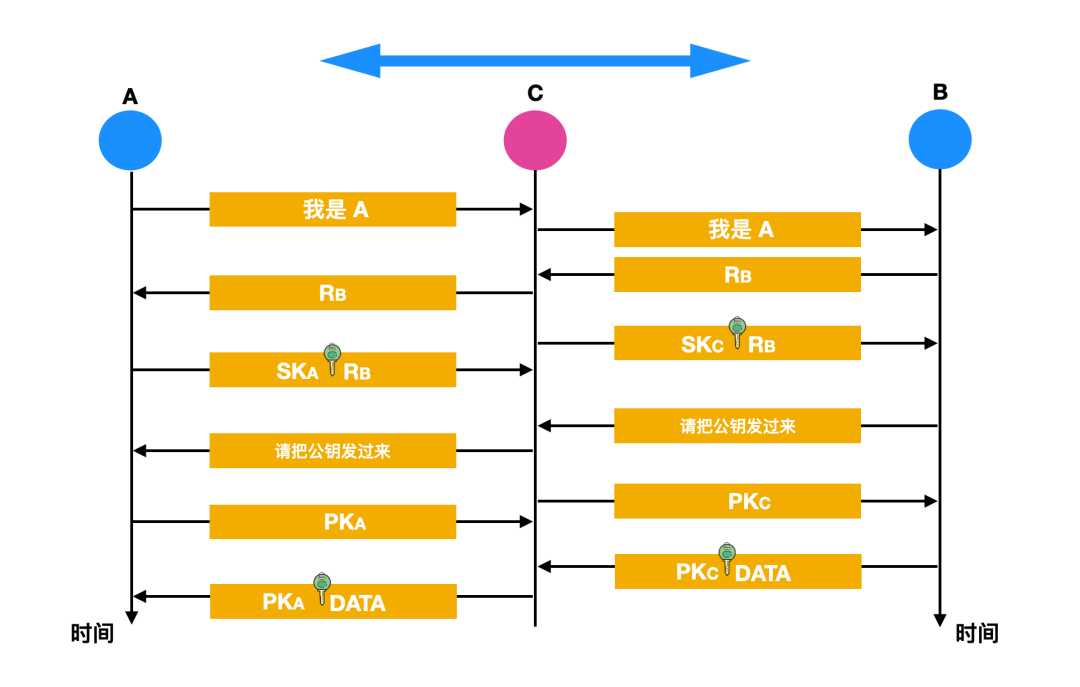
这里的 C 其实更像是扮演了潜伏者和攻击者的角色,让 A 和 B 以为在沟通的时候比较安全,其实这都在 C 的掌控之中:
这里的 A 想和 B 进行通信,会向 B 发送自己的身份验证信息,比如这个信息就叫"我是 A",然后呢这个链路其实已经被中间人 C 所监听了,而 A 发送的消息也已经被 C 所截获,不过这里的 C 并没有伪造信息而是直接把消息转发给 B 。
B 收到消息后会生成不重数 RB,这个不重数 RB 会通过链路传给 A ,但是在这个链路上会被 C 所截获。
C 截获了不重数 RB 后,会用自己的私钥对 RB 加密然后发给 B,让 B 误以为是 A 发过来的。
在这之后 A 把用私钥加密后的 RB 通过链路想要发给 B,但其实在链路上就已经被 C 所截获,C 截获后会把 SKA 加密后的 RB 丢弃。
B 收到加密后的不重数后,会向 A 索取公钥,这个报文也被 C 截获后转发给 A 。
C 截获到 B 发给 A 的公钥后,会把自己的公钥 PKC 冒充是 A 的公钥发送给 B,而 C 也截获到 A 发送给 B 的公钥 PKA。
B 用收到的公钥 PKC(这里其实本来是 A 的公钥)对数据 DATA 进行加密,并发送给 A,在经过链路后被 C 截获,C 会用自己的私钥 SKC 解密,保存一份,然后再用 A 的公钥 PKA 对数据 DATA 加密后发送给 A 。
A 收到数据后,会用自己的私钥 SKA 解密,以为和 B 进行了保密通信,但其实 B 发给 A 的加密数据已经被中间人 C 截获并解密了一份,但 A 和 B 都不知道。
中间人攻击会在通信的两个端点之间进行冒充,拦截数据,中间人 C 既可以拦截解密 B 的数据,又可以冒充 A 的数据,由此可见,公钥的分配和认证以及真实性也是一个比较重要的问题。
-
汽车网络安全 ISO/SAE 21434是什么?(一)2026-04-07 766
-
专家呼吁:网络安全建设亟需开放与合作2010-09-29 2653
-
【assingle原创】试论网络入侵、攻击与防范技术2011-02-26 4003
-
网络安全隐患的分析2012-10-25 2978
-
蓝牙mesh系列的网络安全性2019-07-22 2388
-
2020 年网络安全的四大变化2020-02-07 4089
-
人工智能和机器学习提高网络安全性的方法2021-01-25 2680
-
实现网络安全工业4.0的三个步骤2021-02-19 2370
-
什么是蓝牙mesh网络安全性2021-02-25 3451
-
如何采用Zynq SoC实现Power-Fingerprinting网络安全性?2021-05-21 1321
-
计算机网络安全问题与防范方式2012-04-20 854
-
5G时代网络安全形势,破解网络安全新威胁2019-08-26 6096
-
物联网网络安全威胁怎样防范2019-12-13 2994
-
网络安全基础之网络协议与安全威胁的关系2022-10-20 916
-
必须了解的五种网络安全威胁2023-05-18 3383
全部0条评论

快来发表一下你的评论吧 !
