

优化DFX设计的方法
描述
避免RP和RP之间的直接路径
假定设计中存在两个RP,分别为RP1和RP2,那么就要避免出现RP1输出直接连接到RP2或者相反从RP2输出直接连接到RP1的路径。因为这时RP边界信号(连接RP1和RP2的net)的负载都在动态区,从而必然形成Partition Pin,由于边界信号没有经过静态区逻辑单元,这些PartitionPin最终会有相应的PPLOC,这其实就增加了后续的布线压力。这种情况下,最好将其优化为RP1->FF -> RP2。其中FF在静态区。
避免多个RP输出连接到同一个静态区的负载逻辑单元上
只有当与边界信号连接的静态区负载落在扩展的布线区域时才会触发PPLOC缩减。如果一个静态区的负载连接多个RP,那么显然这个静态区负载只可能落在其中一个RP的扩展布线区域,那么另一个RP就会形成PPLOC,如下图所示,两个RP的输出分别连接到静态区负载LUT4的I0和I1端口,这样就会形成PPLOC。
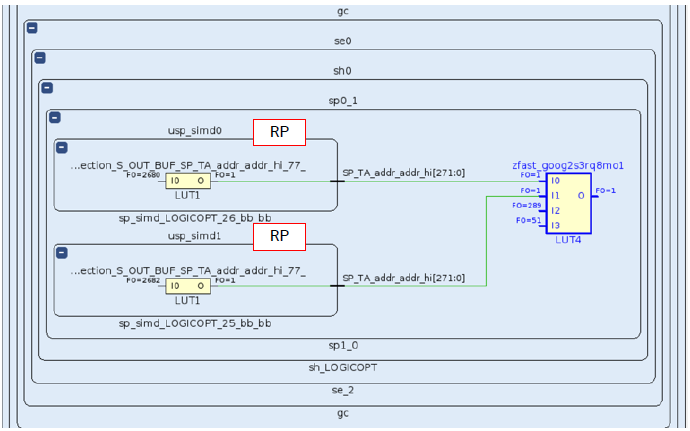
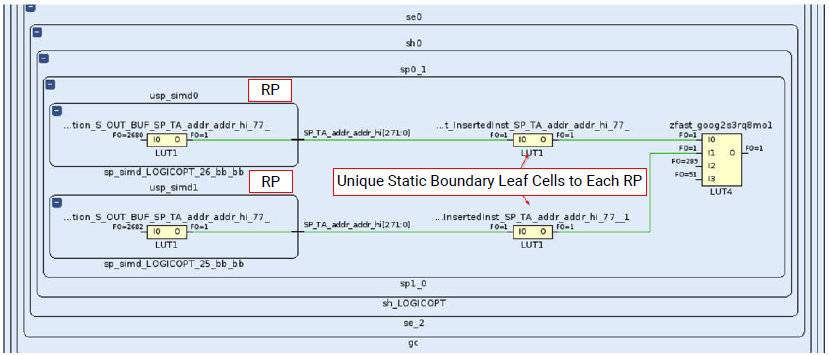
可将其优化为如下图所示方式,这样每个RP的输出都有独立的静态区负载,从而可能触发PPLOC缩减。
复制静态区寄存器驱动多个RP
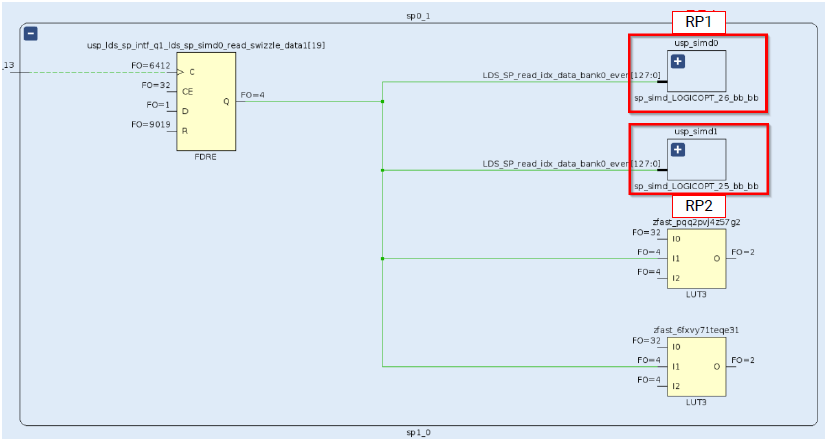
为了保证静态区边界负载对每个RP而言是独立的,那么就要避免同一个静态区触发器驱动多个RP。这种情况命令report_methodology会给报告出来。如下图所示,静态区触发器扇出为4,同时驱动了RP1和RP2。
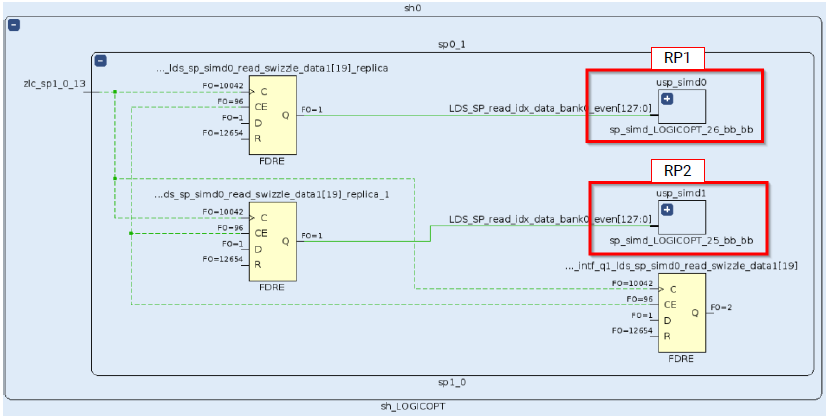
可对该触发器进行复制,如下图所示,这样就保证了每个RP有自己独立的静态区边界负载。
对RM的输入/输出进行寄存
AMD建议确保所有RM的输入是寄存器输入,而输出也都是寄存器输出。这样,时序路径就被隔离开来,即静态区到RP边界、RP内部、RP边界到静态区。对布局布线是有利的,自然对时序收敛也是有益的。同时,如果使用AbstractShell流程,这样还可以有效减少Abstract Shell的大小,从而可进一步缩短编译时间。
避免静态区的走线跑到动态区
默认情况下,DFX设计中静态区的net是可以使用整个芯片的布线资源,自然也包括动态区的布线资源,正因此,就可能出现静态区布线跑到了动态区。尽管从功能角度而言是允许的,但这会给动态区布线带来压力。因此,如果出现动态区布线拥塞时,可以检查一下是否存在上述情况。对于上述情况,我们可以对静态区设置相应的Pblock,将其属性CONTAIN_ROUTING设置为true。下图显示了静态区布线跑到动态区的情形,图中黄色走线即为静态区走线,有部分跑到了动态区。设置CONTAIN_ROUTING为true之后,可以看到这种情况就被消除了。
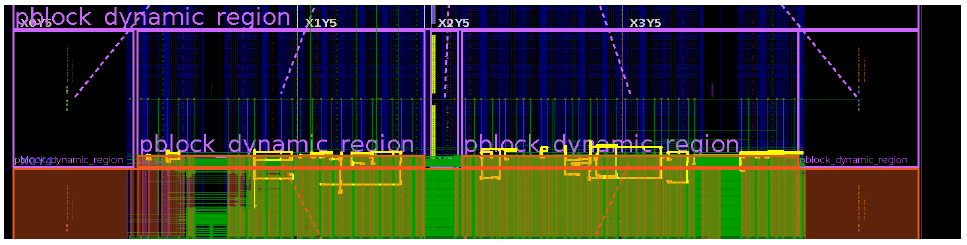

尽可能使Pblock形状为矩形
一旦将Pblock属性CONTAIN_ROUTING设置为true时,对于Pblock的拐角处工具布线难度就会显著增大,如下图左侧所示。Pblock形状不是标准的矩形,在拐角处形成布线拥塞,图中白色高亮部分,拥塞等级为6。将其修正为标准矩形,如下图右侧部分所示,此时拥塞程度降低(图中白色高亮部分),降至5。

审核编辑:汤梓红
-
如何在AMD Vivado™ Design Tool中用工程模式使用DFX流程?2024-04-17 2672
-
采用UltraScale/UltraScale+芯片的DFX设计注意事项2024-01-18 2343
-
DFX可制造性设计与组装技术2023-12-11 1830
-
DFX设计如何分析2023-11-09 2083
-
芯片DFX:Coresight架构2023-11-05 2492
-
什么是DFX技术?DFX设计一定要执行设计规则检查吗?2023-09-21 10531
-
如何对传统的非DFX设计进行调试呢?2023-08-10 1935
-
优化Unity程序的方法2023-08-02 674
-
HarmonyOS对DFX能力的要求2021-12-17 5475
-
电源优化方法是什么2021-11-12 2206
-
简述DFX理念与产品研发(一)2021-09-28 4440
-
硬件电路常见的DFX设计环节详解2019-10-18 9623
-
招兼职dfx、dfm培训讲师2017-08-28 2453
-
PCB板DFX工艺性要求2016-07-26 1596
全部0条评论

快来发表一下你的评论吧 !
