

AWS成为第一个提供NVIDIA GH200 Grace Hopper超级芯片的提供商
描述
2023年的AWS re:Invent大会上,AWS和NVIDIA宣布AWS将成为第一个提供NVIDIA GH200 Grace Hopper超级芯片的云服务提供商。这一超级芯片通过NVIDIA DGX Cloud与NVIDIA NVLink技术相连,将在Amazon Elastic Compute Cloud(Amazon EC2)上运行,为云计算带来了一场技术革命。
一)大杀器NVIDIA GH200 NVL32
NVIDIA GH200 NVL32 是针对 NVIDIA GH200 Grace Hopper 超级芯片的机架级参考设计,通过 NVLink 连接,面向超大规模数据中心。支持 16 个与 NVIDIA MGX 机箱设计兼容的双 NVIDIA Grace Hopper 服务器节点,并且可以采用液体冷却,以最大限度地提高计算密度和效率。
NVIDIA GH200 NVL32 的主要特点如下:
● 拥有 32 个 GPU NVLink 域,每个 GPU NVLink 域包含一个 GH200 Grace Hopper 超级芯片,可以访问网络中任何其他 Grace Hopper 超级芯片的内存,从而提供 19.5 TB 的 NVLink 可寻址内存。这意味着它可以突破单个系统的内存限制,实现更大的并行性和可扩展性。
● 使用 9 个 NVLink 交换机,每个交换机包含一个第三代 NVSwitch 芯片,将 32 个 GH200 GPU 连接在一起,形成一个完全连接的胖树网络。这意味着它可以实现高速的通信和低延迟的同步,提高人工智能的性能和效率。
●由 NVIDIA HPC SDK 以及全套 CUDA、NVIDIA CUDA-X 和 NVIDIA Magnum IO 库支持,可加速超过 3,000 个 GPU 应用程序。这意味着它可以提供丰富的软件生态系统,让开发者和研究者可以轻松地开发和部署人工智能应用程序。
二)NVIDIA GH200 NVL32的应用场景
NVIDIA GH200 NVL32 非常适合以下几种人工智能应用场景:
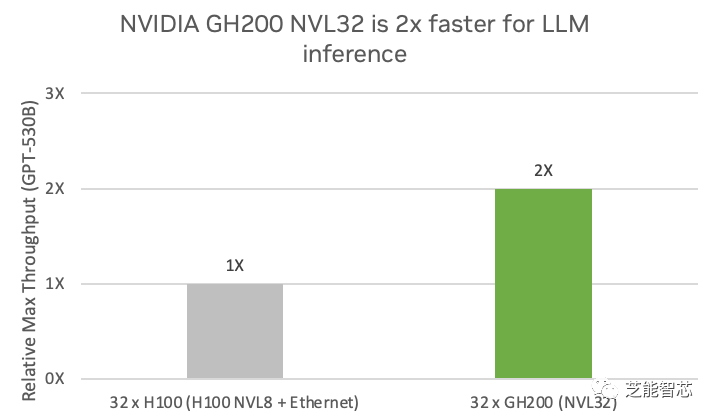
1)AI推理和训练:生成式人工智能模型可以根据给定的文本或上下文生成自然语言,广泛应用于聊天机器人、文本摘要、文本生成、机器翻译等领域,为用户提供智能的交互和服务。法学硕士需要大规模、多 GPU 训练,参数数量非常庞大,例如 GPT-3 有 1750 亿个参数,GPT-4 有 1.5 万亿个参数。NVIDIA GH200 NVL32 专为推理和训练下一代法学硕士而构建。该系统利用 32 个 NVLink 连接的 GH200 Grace Hopper 超级芯片突破了内存、通信和计算瓶颈,训练万亿参数模型的速度比 NVIDIA HGX H100 快 1.7 倍 以上。在 GPT-530B 推理模型上,NVIDIA GH200 NVL32 系统的性能比四个 H100 NVL8 系统高出 2 倍。
2)推荐系统:人工智能模型可以根据用户的偏好和行为,向用户推荐最相关和最感兴趣的内容或产品。它们广泛用于电子商务和零售、媒体和社交媒体、数字广告等领域,以实现内容个性化。
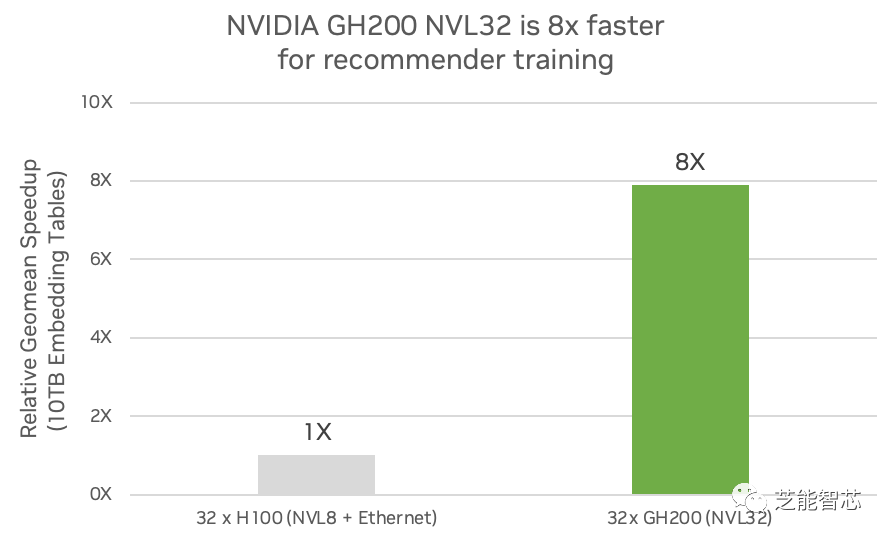
这推动了收入和商业价值。推荐器使用代表用户、产品、类别和上下文的嵌入,大小可达数十 TB。高度准确的推荐器将提供更具吸引力的用户体验,但也需要更大的嵌入和更精确的推荐器。嵌入对于人工智能模型具有独特的特征,需要大量内存、高带宽和闪电般快速的网络。NVIDIA GH200 NVL32 可提供 7 倍 的快速访问内存,并且与基于 x86 的传统设计中与 GPU 的 PCIe Gen5 连接相比,可提供 7 倍 的带宽。与采用 x86 的 H100 相比,它可以实现 7 倍 详细的嵌入。NVIDIA GH200 NVL32 还可以为具有大量嵌入表的模型提供高达 7.9 倍 的训练性能。
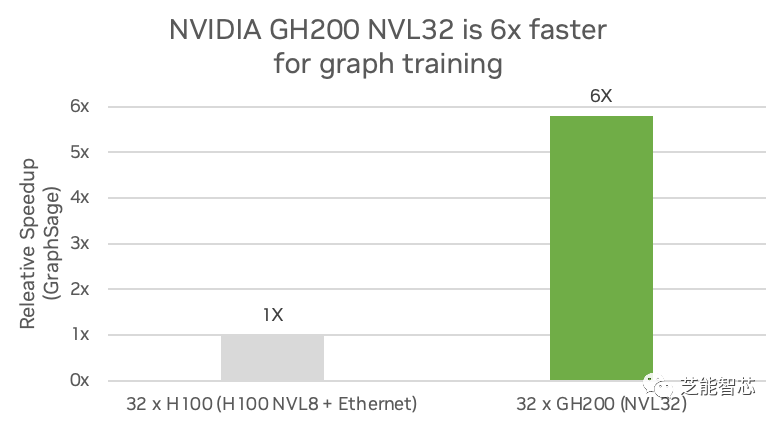
3)图神经网络:图神经网络是一种人工智能模型,可以将深度学习的预测能力应用于丰富的数据结构,这些数据结构将对象及其关系描述为图中由线连接的点。科学和工业的许多分支已经将有价值的数据存储在图数据库中。深度学习用于训练预测模型,从图表中挖掘新的见解。
总结:
Amazon和NVIDIA推动NVIDIA DGX Cloud即将在AWS上推出,将成为首家在DGX云中提供NVIDIA GH200 NVL32,并将其作为EC2实例的云服务提供商。NVIDIA GH200 NVL32解决方案包含32个GPU NVLink域和19.5 TB的大容量统一内存。在GPT-3的训练和LLM推理方面明显优于先前的模型。NVIDIA GH200 NVL32的CPU-GPU内存互连速度非常快,提高了应用程序的内存可用性。该技术是超大规模数据中心可扩展设计的一部分,由NVIDIA软件和库提供支持,可加速数千个GPU应用程序。NVIDIA GH200 NVL32特别适用于LLM训练和推理、推荐系统、GNN等任务,为人工智能和计算应用程序带来显著的性能改进。
审核编辑:刘清
-
NVIDIA AI Enterprise荣获金奖2024-05-29 1399
-
亚马逊云科技与 NVIDIA 宣布开展战略合作,为生成式 AI 提供全新超级计算基础架构、软件和服务2023-11-29 1474
-
英伟达GH200、特斯拉Dojo超级算力集群,性能爆棚!算力之争加剧!2023-09-14 4905
-
NVIDIA Grace Hopper超级芯片横扫MLPerf推理基准测试2023-09-13 1268
-
NVIDIA Grace Hopper 超级芯片横扫 MLPerf 推理基准测试2023-09-12 1135
-
全球GPU呈现“一超一强”竞争格局2023-08-14 3142
-
NVIDIA CPU+GPU超级芯片大升级!2023-08-10 2768
-
SIGGRAPH主题演讲:NVIDIA首席执行官带来生成式AI多项创新2023-08-09 3510
-
COMPUTEX2023 | NVIDIA 推出 DGX GH200 AI 超级计算机2023-05-30 3077
-
全球领先系统制造商加速采用NVIDIA Grace和Grace Hopper2022-05-31 1856
-
Arm Neoverse NVIDIA Grace CPU 超级芯片:为人工智能的未来设定步伐2022-03-29 5167
-
NVIDIA发布最新Hopper架构的H100系列GPU和Grace CPU超级芯片2022-03-26 4252
全部0条评论

快来发表一下你的评论吧 !
