

PanopticNeRF-360:快速生成大量新视点全景分割图像!
人工智能
描述
作者:泡椒味的口香糖 |
0. 笔者个人体会
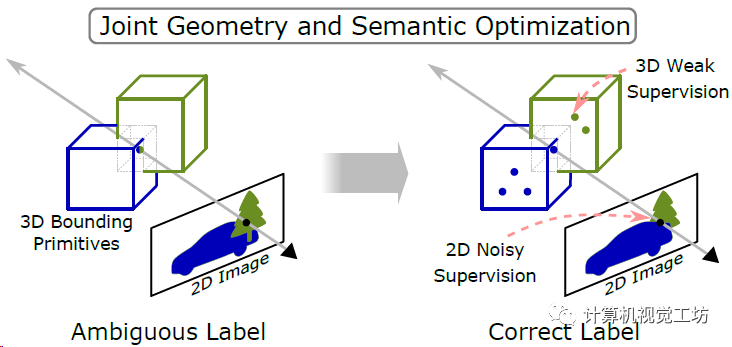
全景分割和实例分割任务的标注是非常庞大的工作量,很多生成模型和NeRF都在尝试直接合成全景分割训练集,但是都存在目标交叉区域的类别模糊问题。
今天笔者将为大家分享PanopticNeRF-360这项工作,是PanopticNeRF的扩展,可以使用3D粗标注快速生成新视点的大量高质量RGB和全景分割。号称将标注时间从1.5h降低到了0.75min(120倍)。
当然笔者水平有限,如果有理解不当的地方欢迎大家一起讨论~
1. 效果展示
PanopticNeRF-360用于生成全景分割,因此输入图像也需要鱼眼相机。整个框架的是输入是前视双目相机和侧视的两个鱼眼相机,还有3D粗标注(3D空间的立方体、椭球、多面体都可以),来生成连续的RGB、全景分割、实例分割。
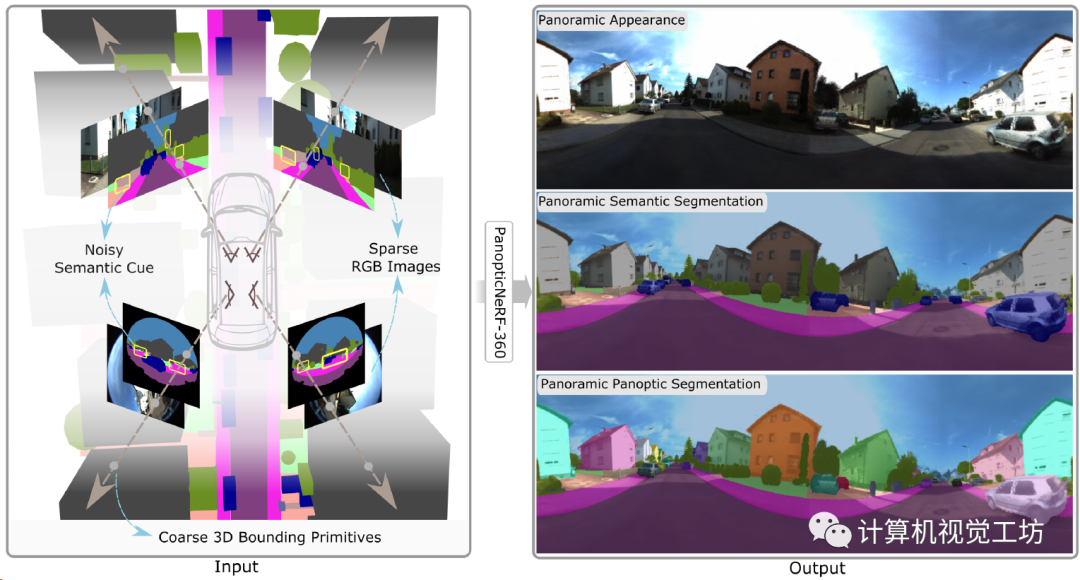
代码已经开源了,感兴趣的读者可以关注一下,下面来看具体的论文信息。
2. 摘要
训练自动驾驶汽车的感知系统需要大量的注释。然而,在2D图像中手工标记是高度劳动密集型的。虽然现有数据集为预先录制的序列提供了丰富的注释,但它们在标注很少遇到的视点方面存在不足,这潜在地阻碍了感知模型的泛化能力。在本文中,我们提出了PanopticNeRF-360,这是一种新的方法,它将粗糙的3D注释与嘈杂的2D语义线索相结合,以从任何视点生成一致的全景标签和高质量图像。我们的关键见解在于利用3D和2D先验的互补性来相互增强几何和语义。具体来说,我们建议利用3D和2D空间中的噪声语义和实例标签来指导几何优化。同时,改进的几何形状通过经由学习的语义场在3D空间中合并3D和2D注释来帮助过滤3D和注释中存在的噪声。为了进一步增强外观,我们结合MLP和哈希网格来产生混合场景特征,在高频外观和主要的连续语义之间取得平衡。我们的实验展示了PanopticNeRF-360在KITTI-360数据集的具有挑战性的城市场景上优于现有标签转移方法的一流性能。此外,PanopticNeRF-360支持高保真、多视图和时空一致的外观、语义和实例标签的全方位渲染。
3. 算法解析
PanopticNeRF和PanopticNeRF-360这两篇文章希望干件啥事?
全景分割和实例分割的数据标注太贵了,希望用深度学习实现自动或者半自动化标注。
主要思想是啥?
主体框架还是用NeRF,因为它的新视点合成能力太强了!可以建立3D语义场和实例场来渲染大量的全景分割和实例分割标注。不过这篇文章侧重的不是改进NeRF结构,而是利用NeRF的渲染结果去做联合优化。
PanopticNeRF-360的具体原理是啥?
整个框架的输入是前视双目相机、两个侧视鱼眼相机、3D粗标注(立方体、椭球、多面体都可以),对空间中的每个点x,先分别使用一个MLP f和哈希网格h建模几何、语义和外观信息,直接合并两个特征(f1和f2)。之后就是两个语义场,一个由3D粗标注建模的固定语义场和一个可学习的语义场,两个语义场分别去渲染得到2D语义标签,还有一个固定的3D实例场区渲染2D全景分割。用固定场渲染得到的实例分割和全景分割做为伪真值去引导几何优化(优化的还是语义场中的体密度),再做一个几何-语义的联合优化去解决类别模糊问题(3D场景中两个目标重叠区域该定义为什么类别)。
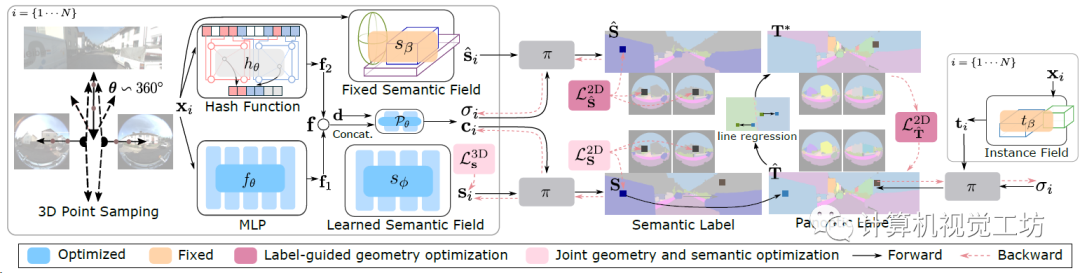
这篇文章主要是有两个创新点,一方面它是第一个基于3D粗标签来生成高质量全景分割的模型,另一方面它提出了两种优化策略来同时优化几何和语义预测。
这个优化策略具体是怎么搞的?
室外采集的图像有大量的曝光,并且不同目标在3D空间中有很多重叠区域,因此直接做普通的几何-语义联合优化的话,改进效果不明显。
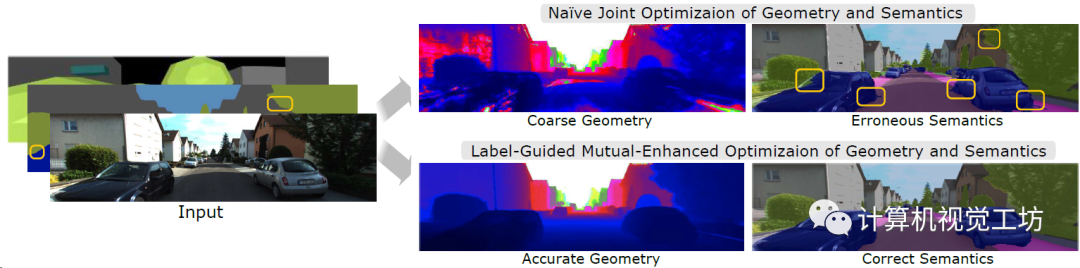
因此,作者提出了两种优化策略,分别是标签引导的几何优化和几何语义联合优化,实际上是引入了两个固定的语义和实例场。
标签引导的优化就是用固定场(还是来源于最初的3D粗标注)渲染得到的语义分割和全景分割做为真值去优化可学习语义场,更侧重渲染2D分割图中精确的物体边界。而联合优化也就是同时估计目标的3D类别和对应的2D分布,更侧重在不同物体的3D框有交集时解决类别模糊问题。
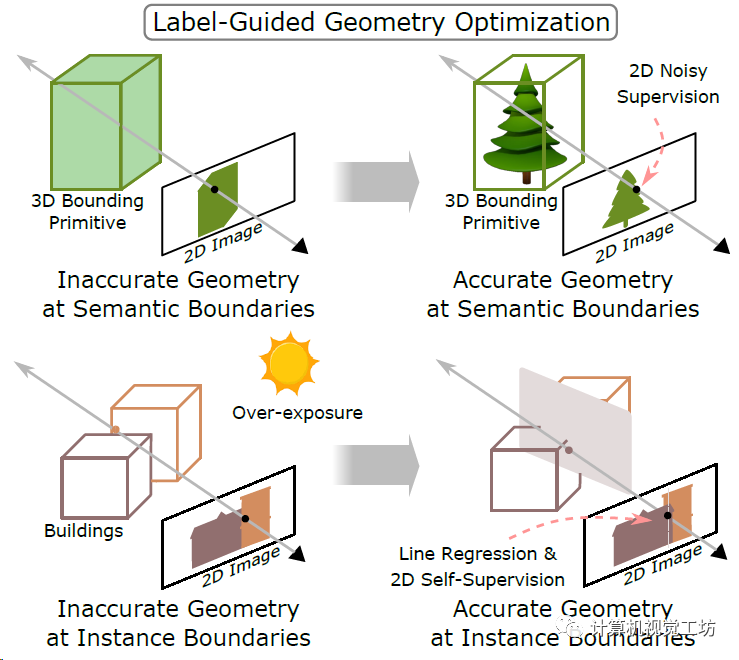
这里面还有个线回归,是用可学习语义场渲染的全景分割去优化固定场的渲染结果,实际运行中只用到了建筑物类别。这里也推荐工坊推出的新课程《国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程》。
到这里,渲染分割图够了,那如何渲染RGB图呢?
渲染RGB图最关键的是高频信息!语义标签在相同目标上是连续的,目标对应的外观却包含了大量高频细节,所以直接渲染RGB的话必然会损失高频信息。这也就是pipeline中最前面哈希网格的作用,这一点和NICE-SLAM很像。
有个问题,前面哈希网格和MLP直接合并是不是太简单了?
这里作者测试了直接合并,还有做element-wise "product"的方案(参考文章Factor fields: A unified framework for neural fields and beyond),发现直接合并的策略简单但有效。

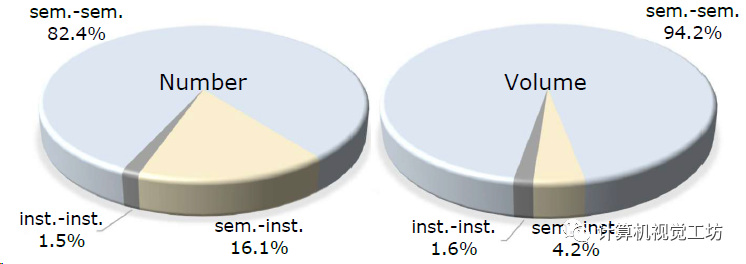
如果把固定的实例场也改为可学习的,会不会提高性能?
作者计算了整个视频序列上3D目标交叉的数量和体积,发现大部分都是语义目标有交集,但是实例和实例之间的交集很少,所以没必要再单独建立一个实例场。
最后再简单说一下这个联合优化
前面说了,这部分主要用来预测重叠区域的语义类别,这也是提出可学习场的主要原因,不然使用固定场就可以预测几何信息。这部分主要是两个交叉熵损失,对每个类别k都引入了一个权重w,同时对每个3D点都引入语义损失:
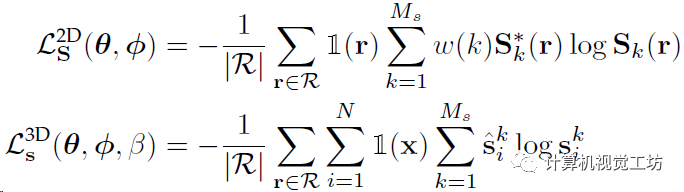
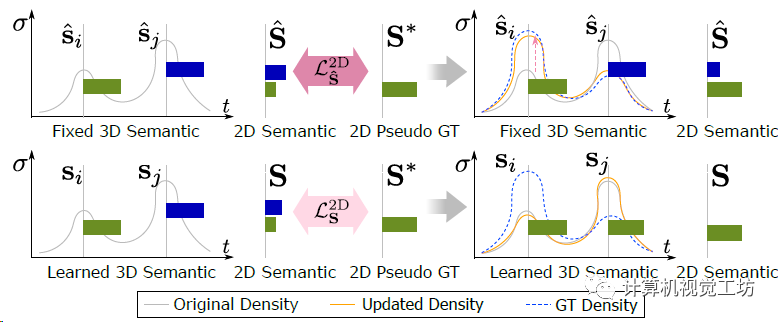
可以看一下引入联合优化的具体效果:
PanopticNeRF-360和PanopticNeRF的区别是什么?
PanopticNeRF是3DV 2022的文章,PanopticNeRF-360是它的扩展,主要区别如下:
1、普通全景分割生成->360°全景分割;
2、将实例标签合并到了标签引导的几何优化中,从而实现全景标签引导的几何优化;
3、提高生成质量,mIoU提升0.8,PQ提升2.3;
4、将场景特征从纯MLP改进为MLP和哈希网格的混合,提高训练速度(2.5倍加速)。
4. 实验结果
实验是在KITTI-360上搞的,对比方案包括其他3D-2D和2D-2D的标签迁移数据集,训练用了一块3090。
3D-2D语义标签迁移的定量对比,PanopticNeRF-360的mIoU和Acc最高,相对于CRF方案两个指标分别提升了2.4%和11.9%。
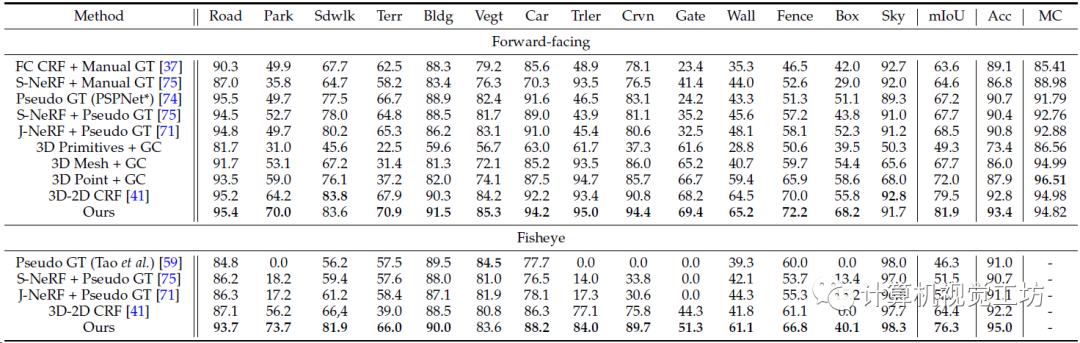
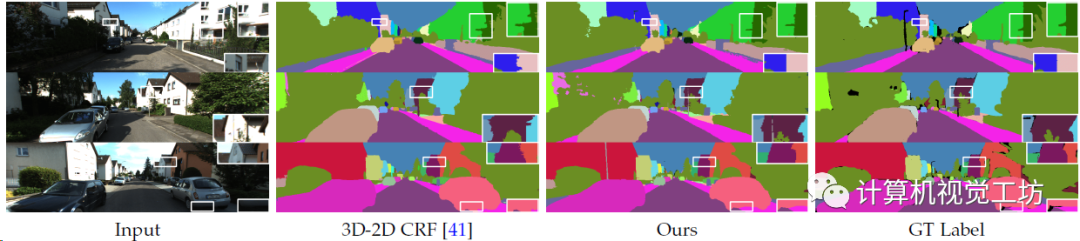
3D-2D语义标签迁移的定性对比,在低纹理、曝光、重叠区域的预测效果很好。
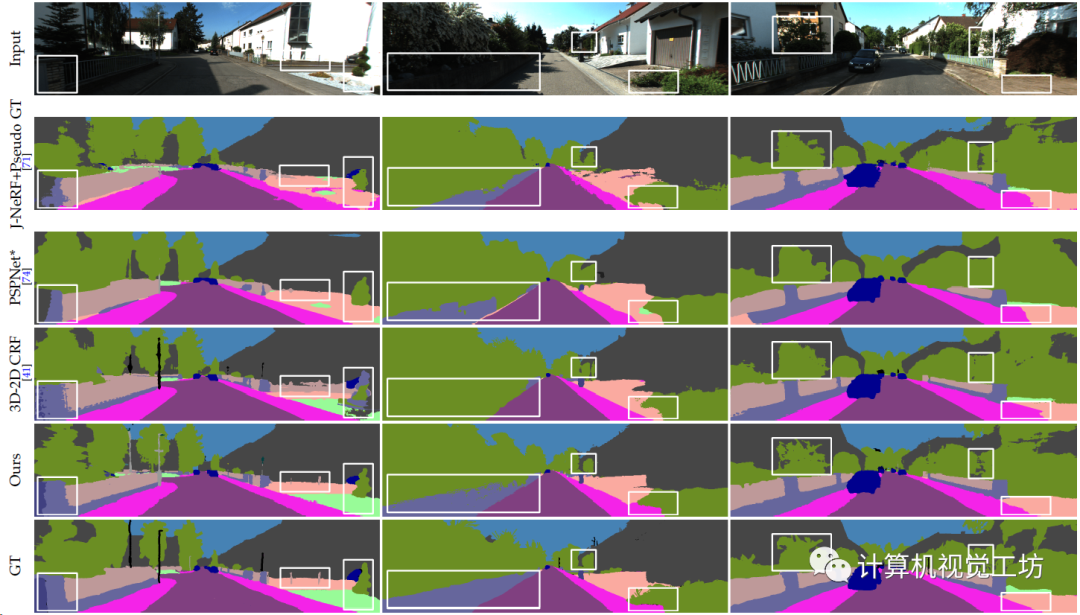
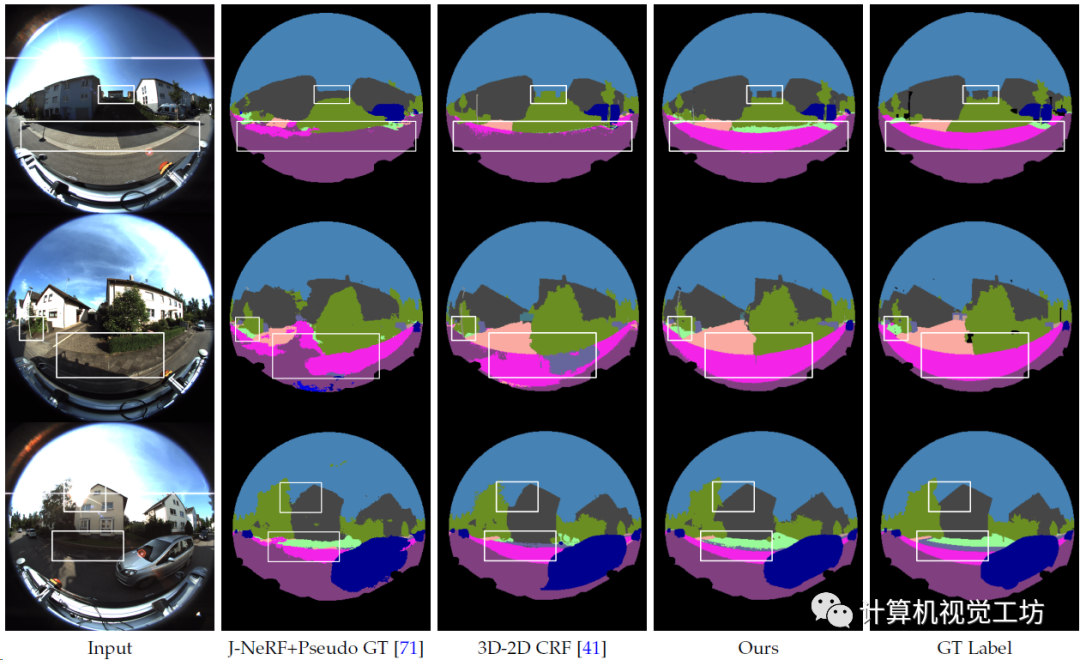
鱼眼3D-2D语义标签迁移,同样在曝光区域效果比较好。
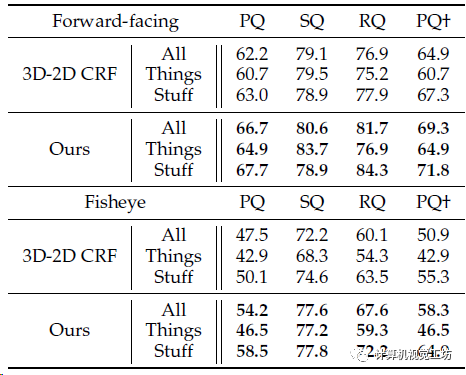
3D-2D全景标签迁移的定量结果,同样超过了CRF方案。
3D-2D全局分割标签迁移的定性对比。
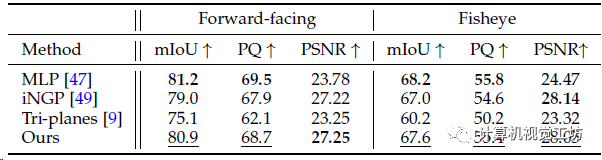
算是消融实验,对比不同方案做为场景表征的性能。
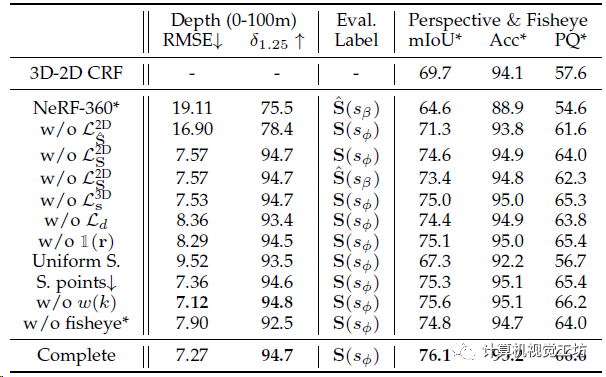
消融实验,对比整个pipeline中各个模块的影响。
消融实验的定性对比,主要是证明各个损失对分割目标物体边界的影响。

文章中做了大量的对比实验,受于篇幅限制只展示这些,感兴趣的读者可以阅读一下论文原文。
5. 总结
PanopticNeRF-360是PanopticNeRF的扩展版本,借助3D粗标注快速生成大量的新视点全景分割和RGB图,并引入几何-语义联合优化来解决交叉区域的类别模糊问题,对于数据标注领域有一定价值。但感觉这个方案还是需要3D粗标注,而一步本身就需要很大的工作量,不值得后续能否不使用粗标注就生成2D分割呢。
审核编辑:黄飞
-
【MiCOKit申请】360度全景泊车系统2015-07-24 2962
-
【TL6748 DSP申请】360全景泊车2015-11-06 1998
-
分析一种360°全景摄像头的设计解决方案2021-05-31 2496
-
基于RK3588的360°全景相机2022-12-16 2008
-
图像分割—基于图的图像分割2015-11-19 949
-
基于Matlab图像分割的研究2016-01-04 992
-
图像分割和图像边缘检测2017-12-19 11935
-
基于内容的图像分割方法综述2018-01-02 1301
-
基于三维分层图像融合的虚拟视点绘制算法2021-05-27 925
-
基于柔性超像素(Soft Superpixel)的SAR图像快速分割方法2022-04-17 3062
-
360全景环视系统2022-10-25 1463
-
AI算法说-图像分割2023-05-17 3009
-
360全景环视发展历程2022-01-14 4689
-
图像分割和语义分割的区别与联系2024-07-17 3099
-
生成大量独立的PWMs2024-09-19 537
全部0条评论

快来发表一下你的评论吧 !
