

ARM NEON在矩阵&向量计算中的加速概述
电子说
描述
一、概述
NEON是ARM上使用的一种SIMD(Single Instruction Multiple Data – 单指令多数据)指令集。可实现64位/128位的并行计算。简单理解就是一个计算指令,可以指定4个Float和4个Float并行计算(也可以是其他数据类型,但是必须包含在64位/128位内),得到4个Float结果。而不是一次只能一个Float和一个Float的计算。
比如在RGB颜色转灰色时,计算公式为:Gray = R *0.299 + G *0.587 + B * 0.114,计算过程是由3个float乘法,2个加发组成,共有5个计算指令;如果直接使用NEON指令,就是可以直接通过一个指令计算完成,提升80%的理论性能。
矩阵计算就更为明显,在4x4的矩阵和4个元素的向量相乘时,有16个float乘法和12个加法计算;NEON可以4个指令直接计算,提升的性能更明显。
当然,这种计算需要是一种矩阵或者像素计算密集型的场景,比如RGB图片转黑白色,不通过GPU加速,而是通过CPU计算的场景;有多个3D模型,每帧需要为每个3D模型进行矩阵计算等等。
二、NEON在矩阵&向量中的计算示例
向量的点积运算示例(这里向量以4个元素为例,前3个元素通常表示3D空间的xyz坐标,第4个元素w用于齐次坐标;也可以表示颜色的RGBA)。两个向量分别是:,,向量的点积计算公式:。对应的NEON加速代码如下:
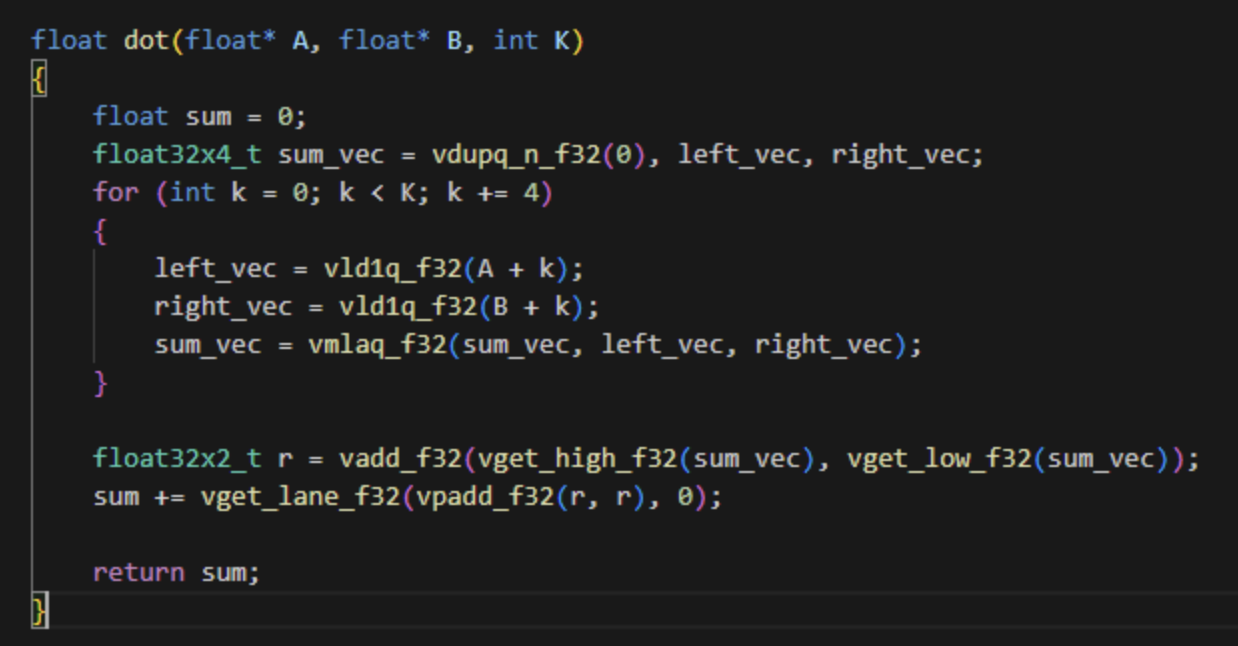
类似vdupq_n_f32、vld1q_f32、vmlaq_f32、vadd_f32、vget_lane_f32等等APIs,都是ARM NEON的intrinsics指令,C格式的API。并且这些APIs都定义在arm_neon.h头文件中。ARM NEON指令有两种实现方式,一种就是示例中的Intrinsics指令,另外一种就是直接使用NEON的汇编指令,嵌入到C语言代码中。我们这里只是以Intrinsics指令为例,汇编指令在原理上一样。
三、示例代码中APIs的说明
3.1 ARM NEON向量寄存器
向量寄存器用来存放向量数据,每个向量元素的类型必须相同。这个向量寄存器有128位,AArch64有32个这个寄存器,AArch32/Armv7有16个这个寄存器。
每个寄存器可以表示2个double float类型数据(每个数据占用64位),4个float类型数据(每个数据占用32位),8个short类型数据(每个数据占用16位),16个byte类型数据(每个数据占用8位)。数据类型可以是整形,也可以是浮点数,只要占用位数对齐,类型统一即可。

3.2 示例说明
在计算时,第一步是要把C代码中定义的数据(数组的形式存在,在运行栈中,或者在堆中)加载到向量寄存器中,第二步通过寄存器进行并行计算,第三步把结果写入到指定寄存器,第四步寄存器结果写入C代码对应的变量中(即C语言的栈或者堆中)。

第一步:vld1q_f32的意思就是把” A + k”地址指向的内容加载到向量寄存器。f32的意思是,一个值是32位。这个命令是从指定地址,连续复制数据到寄存器,并填满寄存器。比如,这里一个数据是32位,一个寄存器128位,也就是这个命令会连续填充4个f32值。说明:这里是多对(“K”个)向量进行点积计算。
第二步:vmlaq_f32意思是把两个寄存器中,并行4个通道的4个f32分别对应相乘,同时把结果和保存结果的寄存器对应通道进行累加。
第三步:vget_high_f32、vget_low_f32是取寄存器的高位和低位(按照f32的type,分别有2个通道),vadd_f32就是获取高位2通道和低位2通道分别相加,存到一个float32x2_t数据格式用(f32类型,2通道)。vpadd_f32中的p是pairwise,意思是将参数两个向量的相邻数据进行计算,这里就是r自己的2个相邻通道相加。
第四步:vget_lane_f32比较简单,就是获取第一个参数寄存器中指定通道的值。这里就是第0通道的值。并写会到一个float值中。
四、点积的推广
这里的点积相对比较复杂,考虑到了一些通用性。这里使用了一个for循环,当只是计算两个4元素向量的点积时,可以把for循环去掉,vmlaq_f32由vmull_f32替换即可。vmull_f32的原型:Result_t vmull_type(Vector_t N, Vector_t M),Result_t可以是float32x4_t,M和N就是left_vec和right_vec。
如果进行叉乘,则不需要进行第三步,直接返回一个float32x4_t的类型数据即可。
如果计算矩阵(4x4)和向量(4通道)相乘,就是计算点积4次,并且结果分别放到float32x4_t类型的4个通道中。
如果是矩阵(4x4)相乘则是4个叉乘。
这四种情况可以自己根据上方点积的计算方式,独立写出。
五、数据类型和函数指令说明
其实NEON Intrinsics指令中,对使用的变量类型、函数定义做了扩展,便于记忆和理解。
1.比如下方的数据类型:

A. int是数据类型,可以是int/uint/float/poly等等。
B. 后边几个数字由‘x’号链接,第一个数字就是每个元素的大小,这里是bit,而非Byte,可以是8/16/32/64。
C. 第二个数字是通道。比如表示颜色的RGBA,就是4通道,每个通道可以用一个byte表示(这里其实就是int8类型)。表示3D空间坐标,可以是xyz,就是3通道。如果是一个2D平面,就是一个xy,2通道了。
D. 最后一个数字表示有多少个。比如一个3D空间坐标xyz,一个四边形有4个顶点,这里就可以表示4(这个值通常是一个2的次幂数)。
这里可以根据实际情况选择自己的数据类型。不过要注意,这里要和128位对齐,符合自己实际数据对齐逻辑,不能超出。
2.函数也有类似的表达方式,例如:
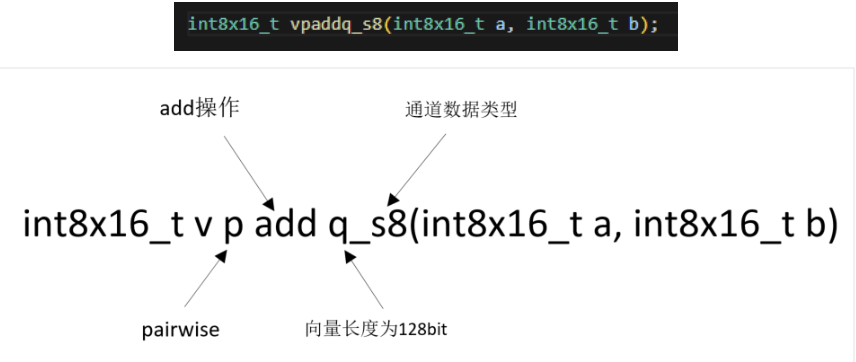
v表示的AArch32/Armv7的指令
p表示pairwise计算。这里表示的是a和b向量的相邻数据进行两两和操作,如下方的操作方式:

add就是加法,加减乘除普通计算,还有一些操作,比如加载、存储、移位、逻辑计算、类型转换等等。
q表示试用128位的向量计算器,不然就使用64位向量寄存器。
s8就是数类型了,可以是:u8、s8、u16、s16、u32、s32、f32、f64。
更多的内容可以在底部参考资料中,找到相关内容。
通过数据类型和函数类型,我们就可以根据实际情况,结合这些函数,封装我们自己的加速代码逻辑,达到优化的目的。
六、总结
这里只是对点积计算方式进行了解析,同时对于其他情况的推广。其实对于int、char等类型可以类比计算。对像素、向量、矩阵等等的计算会成倍提升(理论性能提升16、8、4、2倍不等,根据实际类型确定)。特别是在移动端,图形计算、图形处理领域,CPU性能遇到瓶颈,进行性能优化时,NEON指令是一个不错的优化点。
-
简述ARM SVE的发展以及和NEON的区别来探讨Vector在AI中的应用2022-09-19 3682
-
Vector向量计算技术与SIMD技术的对比简述2022-03-09 4689
-
Vector向量计算技术与SIMD技术的对比2021-09-01 1583
-
电池的电量计算2021-08-12 6313
-
基于Zipf's共生矩阵分解的事件向量计算方法2021-05-10 902
-
张量计算在神经网络加速器中的实现形式2020-11-02 3964
-
电感量计算软件2015-11-18 4985
-
常用流量计算软件2011-04-18 1458
-
MATLAB变量—标量,向量,矩阵2009-09-22 5357
-
CDMA的容量计算公式2009-09-18 15466
-
空心线圈电感量计算2009-08-07 3108
-
gprs流量计算软件2008-06-15 12426
-
流量计算机2008-05-19 2024
全部0条评论

快来发表一下你的评论吧 !
