

一种新颖的大型语言模型知识更新微调范式
人工智能
描述
先遗忘后学习:基于参数计算的大模型知识更新

最近,大型语言模型(LLMs)展示了其令人惊叹的文本理解和生成能力。然而,即使是更为强大的LLMs,仍有可能从训练语料库中学到不正确的知识,以及随时间而过时的知识。直接使用包含新知识的数据进行二次微调可能在更新知识时效果不佳,因为新旧知识之间存在冲突。在本文中,我们提出了一种新的微调范式,被称为F-Learning(先遗忘后学习),它基于参数计算,实现对旧知识的遗忘和对新知识的学习。在两个公开可用的数据集上的实验证明,我们提出的F-Learning显著改善了全量微调和LoRA微调的知识更新性能。此外,我们还发现,通过减去LoRA的参数来遗忘旧知识可以达到与减去全量微调参数相似的效果,有时甚至可以显著超越它。
论文:
Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models
地址:
https://arxiv.org/pdf/2311.08011.pdf
研究背景
大型语言模型(LLMs)具有出色的自然语言理解和生成能力。尽管LLMs在学习方面非常强大,但仍有可能在语料库中学到错误的知识。此外,现实世界中的许多知识不断更新,LLMs中的一些最初正确的知识随时间变得过时和无效。例如,“美国总统是谁?”在2020年的答案可能是“唐纳德·特朗普”,而现在的答案是“乔·拜登”。因此,LLMs需要在使用过程中不断更新其发现的过时和错误的知识。现有的模型编辑和知识更新方法通常会添加额外的参数、存储模块、知识库等,而编辑过程不像直接使用新知识进行微调那样简单明了。
目前,学习新知识时最常用的方法仍然是直接微调模型。当人类建立起自己的初始认知时,如果他们接触到与初始认知不一致的新知识,通常会感到冲突,难以学习和接受新知识。如果原始认知和知识被遗忘,那么待学习的新知识就不会与原始认知和知识发生冲突,这使得学习和吸收新知识变得更为简单。例如,如果一个人从小被教育认为“地球是扁平的”,那么当他们成年后接受与之相矛盾的“地球是圆的”知识将会是一项挑战。然而,如果他们能够忘记“地球是扁平的”这个错误的知识,或者在接触到错误信息之前学习和接受“地球是圆的”新知识,就会简单得多。
受以上经验观察的启发,我们提出了一种称为F-Learning(先遗忘后学习)的知识更新新范式。具体而言,我们首先使用旧知识微调初始模型,然后从初始模型参数中减去微调后的模型参数与初始模型参数的差值,这个过程被定义为“旧知识遗忘”。然后,我们使用新知识在遗忘旧知识后的模型上进行微调。这个过程我们定义为“新知识学习”。经过遗忘旧知识和学习新知识的两个阶段后,模型的知识得到更新。
研究方法
与引入外部知识库或额外参数不同,我们的方法主要基于全量微调和参数高效微调。它包括两个阶段:遗忘旧知识和学习新知识。
遗忘旧知识
假设在数据集上进行的有监督微调(SFT)向LLMs注入了新知识或激活了与新知识相关的拟合能力,这反映在模型参数的变化上。在这个阶段,对于给定的大型语言模型及其参数,我们定义增量参数为知识参数,计算如下: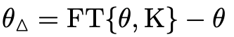 其中FT表示有监督微调,和分别表示包含知识的数据集以及原始模型的参数。类似地,我们首先在一个包含旧知识的数据集上对进行微调,然后用微调后的模型参数减去原始模型的参数得到表示旧知识的知识参数,如下所示:
其中FT表示有监督微调,和分别表示包含知识的数据集以及原始模型的参数。类似地,我们首先在一个包含旧知识的数据集上对进行微调,然后用微调后的模型参数减去原始模型的参数得到表示旧知识的知识参数,如下所示:
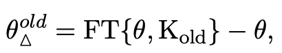
其中表示包含我们需要遗忘的旧知识的数据集。受先前工作启发,我们认为从参数θ当中减去参数能够帮助模型遗忘这部分旧知识,所以我们将遗忘旧知识的过程定义如下:
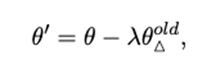
其中是控制遗忘比例的超参数。现在我们得到了一个参数为的新模型。值得注意的是这一遗忘旧知识的过程只有当模型充分掌握旧知识的情况下才成立,否则模型无需进行遗忘也不需要进行知识更新。
学习新知识
对于经历过遗忘旧知识过程的模型,接着我们将通过监督微调向注入新知识,以进行知识更新。同样地,我们定义学习新知识的过程如下:

其中表示有监督微调,表示学习了新知识的模型的参数,表示包含需要更新的的新知识的数据集。
实验
在实验中我们采用了ZsRE和COUNTERFACT两个广泛使用的数据集,并选择Reliability、Generality、Locality作为主要评测指标,分别评估知识更新的准确率、泛化性以及对无关知识的影响程度。我们将直接对原始模型进行新知识有监督微调得到的结果作为基线。实验结果如下所示:

我们使用LLAMA2-7B作为实验的基础模型。我们主要评估将旧知识更新为新知识的能力,因此模型将首先在旧知识上进行为期3个时期的微调。表1中F-Learning中设置的超参数λ分别取值为0.3、0.7、0.1和1.5。所有实验的学习率和时期都设置为5e-5和3。为了确保模型输出的唯一性,在测试期间我们将模型的温度设置为0。在硬件方面,我们使用了总共4个A100-80G GPU进行实验。
实验表明在首次遗忘之后,无论是全量微调还是LoRA,在学习方面都有显著的提升。具体而言,与直接进行全量微调相比,F-Learning FT在ZsRE数据集上将Reliabilty和Generality分别提高了2.71和4.84点。与此同时,Locality指标基本保持不变,仅下降了0.43点。与直接进行全量微调相比,F-Learning LoRA在ZsRE数据集上将Reliabilty和Generality分别提高了2.71和4.84点。Locality指标基本保持不变,仅下降了0.43点。与LoRA微调相比,F-LearningLoRA在ZsRE数据集上将Reliabilty、Generality和Locality指标分别提高了3.81、4.01和1.67点。同样,在COUNTERFACT数据集上,与直接进行全体积微调相比,F-LearningLoRA将Reliabilty、Generality和Locality指标分别提高了3.54、1.48和0.07点。与LoRA微调相比,F-LearningLoRA在ZsRE数据集上将Reliabilty、Generality和Locality指标分别提高了0.61、0.39和0.34点。总体而言,全量微调比LoRA更具学习新知识的能力,而我们的F-Learning在一定程度上相对于全量微调和LoRA取得了提升。
LoRA遗忘然后全量学习
在上述实验设置中,我们采用的方法是同时基于全量微调(或LoRA)执行旧知识遗忘和新知识学习。然而,我们发现在某些情况下,通过减去全量微调的知识参数(即通过全量微调遗忘旧知识)会完全破坏我们基础模型的核心功能,导致评估指标显著下降。鉴于LoRA是一种参数高效的微调方法,与全量微调相比对参数的影响较小,我们尝试了一种新的方法,即通过LoRA遗忘旧知识,然后通过全量微调学习新知识,以寻求一种平衡。与上文类似,我们对这一过程定义如下:
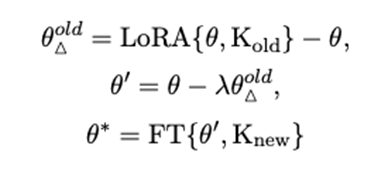
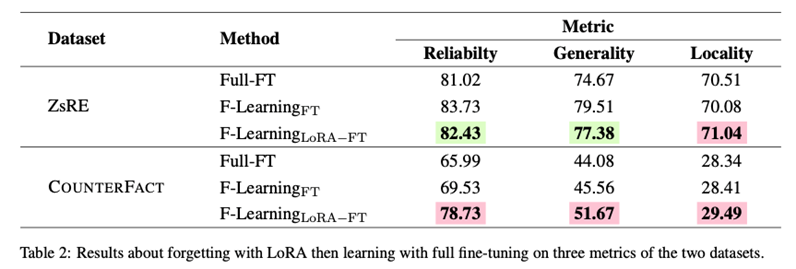
为了验证,我们保持与上述相同的实验设置并进行实验。结果如表2所示。注意,在表2中,F-Learning中设置的超参数λ分别取值为0.3、3、0.1和3。结果支持了通过LoRA遗忘旧知识,然后通过全量微调学习的方法完全超越了直接的全量微调,几乎实现了对遗忘并通过全量微调学习的方法的近似甚至超越。具体而言,与方法F-Learning FT相比,F-Learning LoRA−FT在COUNTERFACT数据集上将Reliabilty和Generality分别提高了9.20和6.11点。尽管F-Learning LoRA−FT在ZsRE数据集上的表现约低1-2点,但仍然在全量微调方面具有很大优势,并有提升的空间。至于Locality指标,F-Learning LoRA−FT在zsRE和COUNTERFACT数据集上都取得了约1点的提升。我们经验性地认为这是因为基于LoRA的遗忘对参数的影响较小,从而对无关知识造成的损害较小。实验证明通过减去LoRA的参数进行遗忘可以达到近似于减去全量微调参数的效果,这具有很大的价值,因为在大多数情况下,LoRA的时间成本和计算成本都远远低于全量微调。
总结
主要贡献:
提出了一种新颖的大型语言模型知识更新微调范式,称之为“先遗忘后学习”(F-Learning),
实验结果表明,我们提出的F-Learning显著改善了各种微调方法的知识更新性能,
实验结果显示,通过减去LoRA的参数进行遗忘可以达到近似于减去全量微调参数的效果。
审核编辑:黄飞
-
大型语言模型在关键任务和实际应用中的挑战2023-08-15 2477
-
探索高效的大型语言模型!大型语言模型的高效学习方法2023-12-13 1540
-
【大语言模型:原理与工程实践】大语言模型的应用2024-05-07 1300
-
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读2025-01-14 2293
-
一种新颖的ZVZCSPWM全桥变换器2009-07-11 1278
-
一种新颖的精密陀螺电源2009-07-27 1221
-
一种新颖的三维模型压缩算法2017-12-25 2193
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2551
-
大型语言模型有哪些用途?2023-02-23 6323
-
大型语言模型有哪些用途?大型语言模型如何运作呢?2023-03-08 9664
-
一套开源的大型语言模型(LLM)—— StableLM2023-04-24 3425
-
如何将ChatGPT的能力蒸馏到另一个大模型2023-06-12 3228
-
大型语言模型的应用2023-07-05 3055
-
四种微调大模型的方法介绍2024-01-03 27075
-
大语言模型中的语言与知识:一种神秘的分离现象2024-02-20 1358
全部0条评论

快来发表一下你的评论吧 !
