

开源LLM在各种基准上的代理能力
描述
作者:cola
自2022年底ChatGPT发布以来,其已经在人工智能的整个领域带来了翻天覆地的变化。通过对大型语言模型(LLM)进行指令微调,并从人类反馈中进行监督微调和强化学习,表明模型可以回答人类问题并在广泛的任务中遵循指令。在这一成功之后,对LLM的研究兴趣增强了,新的LLM在学术界和工业界频繁蓬勃发展。虽然非开源LLM(例如,OpenAI的GPT, Anthropic的Claude)通常优于它们的开源同行,但后者的进展很快。这对研究和商业都有至关重要的影响。在ChatGPT成立一周年之际,本文对这类LLMs进行了详尽的介绍。

就在一年前,OpenAI发布的ChatGPT席卷了AI社区和广泛的世界。这是第一次,基于应用程序的人工智能聊天机器人可以为大多数问题提供有用的、安全的和详细的答案,遵循指示,甚至承认和修复以前的错误。值得注意的是,它可以执行传统上由预训练然后定制的微调语言模型完成的任务,如摘要或问答(QA)。作为同类应用中的第一个,ChatGPT吸引了普通大众的关注,它在发布后的两个月内就达到了1亿用户,比其他流行应用如TikTok或YouTube快得多。它还吸引了巨大的商业投资,因为它具有降低劳动力成本、自动化工作流程甚至为客户带来新体验的潜力。
由于ChatGPT不是开源的,而且它的访问权限是由一家私人公司控制的,所以它的大部分技术细节仍然未知。尽管声称它遵循InstructGPT(也称为GPT-3.5)中介绍的过程,但其确切的架构、预训练数据和微调数据是未知的。这种闭源特性产生了几个关键问题。
在不知道预训练和微调程序等内部细节的情况下,很难正确估计其对社会的潜在风险,特别是知道LLM可以产生有毒、不道德和不真实的内容。
有报道称,ChatGPT的性能随着时间的推移而变化,妨碍了可重复性的结果。
ChatGPT经历了多次宕机,其中最主要的两次宕机发生在2023年11月,当时对ChatGPT网站及其API的访问被完全阻断。
采用ChatGPT的企业可能会担心API调用的巨大成本、服务中断、数据所有权和隐私问题,以及其他不可预测的事件,如最近关于董事会解雇CEO Sam Altman以及最终他回归的戏剧性事件。
而开源LLM提供了一个有希望的方向,因为它们可以潜在地修复或绕过上述大多数问题。因此,研究界一直积极推动在开源中维护高性能的LLM。然而,从今天的情况来看(截至2023年底),人们普遍认为开源LLM,如Llama-2或Falcon,落后于它们的非开源同行,如OpenAI的GPT3.5(ChatGPT)和GPT-4,Anthropic的Claude2或谷歌的Bard3,通常认为GPT-4是它们的冠军。
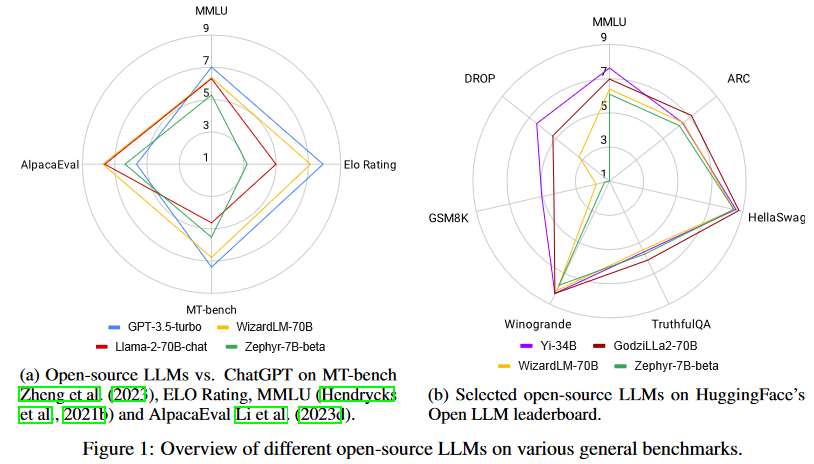
然而,令人鼓舞的是,差距越来越小,开源LLM正在迅速赶上。事实上,正如图1所示,最好的开源LLM在一些标准基准上的性能已经优于GPT-3.5-turbo。然而,对于开源LLM来说,这并不是一场简单的艰苦战斗。情况在不断发展:非开源LLM通过定期对更新的数据进行再训练来更新,开源LLM也不断更新以赶上形势变化,并且有无数的评估数据集和基准被用于比较LLM,这使得挑选出一个最好的LLM特别具有挑战性。
背景
训练方法
预训练
所有LLM都依赖于在互联网文本数据上进行大规模的自监督预训练。仅解码器的LLM遵循因果语言建模目标,通过该目标,模型学习根据之前的token序列预测下一个token。根据开源LLM分享的预训练细节,文本数据的来源包括CommonCrawl、C4、GitHub、Wikipedia、书籍和在线讨论,如Reddit或StackOverFlow。人们普遍认为,扩展预训练语料库的大小可以提高模型的性能,并与扩展模型大小密切相关,这种现象被称为缩放定律。现代的LLM在数千亿到数万亿token的语料库上进行预训练。
微调
微调的目的是通过使用可用的监督来更新权重,使预训练的LLM适应下游任务,这些监督通常时比预训练使用的数据集小一个量级的数据集。T5是最早将微调框架构建为文本到文本统一框架的之一,用自然语言指令描述每个任务。指令微调后来通过在几个任务上联合训练扩展了微调,每个都用自然语言指令进行描述。指令微调迅速流行起来,因为它能够大幅提高LLM的零样本性能,包括在unseen任务上,特别是在更大的模型规模上。使用多任务监督微调(通常称为SFT)的标准指令微调仍然可以保证模型在安全、道德和无害的同时遵循人类意图,并可以通过从人类反馈中强化学习(RLHF)进一步改进。
RLHF指的是人类标注者对微调模型的输出进行排序,用于通过强化学习再次微调。最近的工作表明,人类反馈可以被LLM的反馈取代,这一过程称为从人工智能反馈中强化学习(RLAIF)。直接偏好优化(DPO)绕过了像RLHF那样将奖励模型拟合人类偏好的需要,而是用交叉熵目标直接微调策略,实现了LLM与人类偏好的更有效对齐。
在构建不同任务的指令微调数据集时,重点是质量而不是数量:Lima仅在1000个示例上微调Llama-65B,表现优于GPT-3,而Alpagasus通过将其指令微调数据集从52k清理到9k,对Alpaca进行了改进。
再次预训练
再预训练包括从预训练的LLM执行另一轮的预训练,通常比第一阶段的数据量更少。这样的过程可能有助于快速适应新领域或在LLM中引出新属性。例如,对Lemur进行再次预训练,以提高编码和推理能力,对Llama-2-long进行扩展上下文窗口。
推理
存在几种使用LLM进行自回归解码的序列生成的替代方法,它们的区别在于输出的随机性和多样性程度。在采样期间增加温度使输出更加多样化,而将其设置为0则会退回到贪婪解码,这在需要确定性输出的场景中可能需要。采样方法top-k和top-p限制了每个解码步骤要采样的token池。
注意力复杂度是关于输入长度的二次型,因此一些技术旨在提高推理速度,特别是在较长的序列长度时。FlashAttention优化了GPU内存级之间的读写,加速了训练和推理。FlashDecoding将注意力机制中的key-value(KV)缓存加载并行化,产生8倍的端到端加速。推测解码使用一个额外的小型语言模型来近似来自LLM的下一个token分布,这在不损失性能的情况下加速了解码。vLLM使用PagedAttention加速LLM推理和服务,PagedAttention是一种优化注意力键和值的内存使用的算法。
任务域和评估
由于要执行的评估的多样性和广度,正确评估LLM的能力仍然是一个活跃的研究领域。Question-answering数据集是非常流行的评估基准,但最近也出现了为LLM评估量身定制的新基准。
开源LLMs vs. ChatGPT
综合能力
基准
随着大量LLM的发布,每个LLM都声称在某些任务上具有卓越的性能,确定真正的进步和领先的模型变得越来越具有挑战性。因此,至关重要的是全面评估这些模型在广泛任务中的性能,以了解它们的一般能力。本节涵盖使用基于LLM(如GPT-4)评估和传统(如ROUGE和BLEU)评估指标的基准。
MT-Bench:旨在从八个角度测试多轮对话和指令遵循能力。分别是写作、角色扮演、信息提取、推理、数学、编码、知识I (STEM)和知识II(人文/社会科学)。
AlpacaEval:是一个基于AlpacaFarm评估集的自动评估器,它测试了模型遵循一般用户指令的能力。它利用更强的LLM(如GPT-4和Claude)将候选模型与Davinci-003响应进行基准测试,从而生成候选模型的胜率。
开源LLMs榜单:使用语言模型评估工具在七个关键基准上评估LLM,包括AI2 Reasoning Challenge、HellaSwag、MMLU、TruthfulQA、Winogrande、GSM8K和DROP。该框架在零样本和少样本设置下,对各种领域的各种推理和一般知识进行评估。
BIG-bench:是一个合作基准,旨在探索LLM并推断其未来能力。它包括200多个新颖的语言任务,涵盖了各种各样的主题和语言,这些是现有模型无法完全解决的。
ChatEval:是一个多智能体辩论框架,它使多智能体裁判团队能够自主地讨论和评估不同模型在开放式问题和传统自然语言生成任务上生成的响应的质量。
Fairval-Vicuna:对来自Vicuna基准的80个问题进行了多证据校准和平衡位置校准。其在采用LLM作为评估的范式中提供了一个更公正的评估结果,与人类的判断密切一致。
LLMs的性能
Llama-270B是来自meta的著名开源LLM,已经在2万亿token的大规模数据集上进行了预训练。它在各种通用基准上展示了显著的结果。当与指令数据进一步微调时,Llama2-chat-70B变体在一般会话任务中表现出增强的能力。其中,Llama-2-chat-70B在AlpacaEval中取得了92.66%的胜率,将GPT-3.5-turbo的性能提升了10.95%。尽管如此,GPT-4仍然是所有LLM中表现最好的,胜率为95.28%。
另一个较小的模型Zephyr-7B使用蒸馏进行优化,在AlpacaEval上取得了与70B LLMs相当的结果,胜率为90.6%。它甚至超过了Llama-2-chat-70B。此外,WizardLM-70B已经使用大量具有不同复杂度的指令数据进行了指令微调。它以7.71的分数脱颖而出,成为MT-Bench上得分最高的开源LLM。然而,这仍然略低于GPT-3.5turbo(7.94)和GPT-4(8.99)。尽管Zephyr-7B在MT-Bench中表现最好,但它在Open LLM排行榜中不出色,得分仅为52.15%。另一方面,GodziLLa2-70B,将Maya Philippines 6和Guanaco Llama 2 1K数据集中的各种专有LoRAs与Llama-2-70b相结合,在Open LLM排行榜上取得了更有竞争力的67.01%的分数。Yi-34B从一开始就由开发人员进行了预训练。AI 7,以68.68%的显著分数在所有开源LLM中脱颖而出。该性能与GPT-3.5-turbo的70.21%相当。然而,两者仍然明显落后于GPT-4,后者以85.36%的高分领先。UltraLlama利用了增强多样性和质量的微调数据。它在其建议的基准中与GPT-3.5-turbo的性能相匹配,同时在世界和专业知识领域超过了它。
代理能力
基准
随着模型规模的不断扩大,基于LLM的智能体(也称为语言智能体)引起了NLP社区的广泛关注。鉴于此,本文研究了开源LLM在各种基准上的代理能力。根据所需的技能,现有的基准主要可以分为四类。
使用工具:已经提出了一些基准来评估LLM的工具使用能力。
API-Bank是专门为工具增强的LLM设计的。
ToolBench 是一个工具操作基准,包括用于现实世界任务的各种软件工具。
APIBench由HuggingFace、TorchHub和TensorHub的API组成。
ToolAlpaca通过多智能体仿真环境开发了多样化和全面的工具使用数据集。
MINT可以评估使用工具解决需要多轮交互的任务的熟练程度。
自调试(self-debugging):有几个数据集可用于评估LLM的自调试能力。
InterCode-Bash
InterCode-SQL
MINT-MBPP
MINT-HumanEval
RoboCodeGen。
遵循自然语言反馈:
MINT通过使用GPT-4来模拟人类用户,也可用于测量LLM利用自然语言反馈的能力。
探索环境:评估基于LLMs的智能体是否能够从环境中收集信息并做出决策。
ALFWorld
InterCode-CTF
WebArena。
LLMs的性能
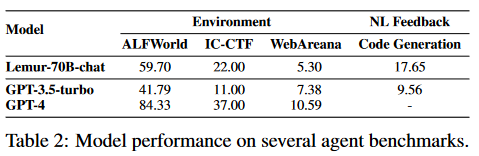
通过使用包含90B标记的代码密集型语料库对Llama-2进行预训练,并对包括文本和代码在内的300K示例进行指令微调,Lemur-70B-chat在探索环境或遵循编码任务的自然语言反馈时超过了GPT-3.5-turbo的性能。AgentTuning使用Llama-2对其构建的AgentInstruct数据集和通用域指令进行指令调整,产生AgentLlama。值得注意的是,AgentLlama-70B在未见过的代理任务上实现了与GPT-3.5-turbo相当的性能。通过在ToolBench上对Llama-2-7B进行微调,ToolLLaMA在工具使用评估中展示了与GPT3.5-turbo相当的性能。FireAct,它可以对Llama-2-13B进行微调,以在HotpotQA上超越提示GPT-3.5-turbo。此外,从Llama-7B进行微调的Gorilla在编写API调用方面优于GPT-4。
逻辑推理能力
基准
逻辑推理是高级技能的基本能力,如程序设计、定理证明、算术推理等。我们将介绍以下基准:
GSM8K:由人类问题作者创造的8.5K个高质量的小学数学问题组成。解决这些问题需要2到8步,解决这些问题主要涉及使用基本算术运算以得到最终答案。
MATH:是一个包含12,500个具有挑战性的数学竞赛问题的数据集。数学中的每个问题都有一个完整的分步解决方案,可用于教模型生成答案的推导和解释。
TheoremQA:是一个定理驱动的问答数据集,旨在评估人工智能模型应用定理解决挑战性科学问题的能力。TheoremQA由领域专家策划,包含800个高质量的问题,涵盖了数学、物理、EE&CS和金融的350个定理。
HumanEval:是一组164个手写编程问题。每个问题包括一个函数签名、文档字符串、函数体和几个单元测试,平均每个问题7.7个测试。
MBPP:(主要基础编程问题)数据集包含974个短Python程序,这些程序是通过具有基本Python知识的内部众包人员构建而成。每个问题都分配了一个独立的Python函数来解决指定的问题,以及三个测试用例来检查函数的语义正确性。
APPs:是代码生成的基准,衡量模型采用任意自然语言规范并生成令人满意的Python代码的能力。该基准包括10,000个问题,从简单的单行解决方案到巨大的算法挑战。
增强指令微调
与传统的基于知识蒸馏的指令微调不同,通过构建特定于任务的高质量指令微调数据集,其中种子指令已经进化到在知识边界或任务复杂度深度上扩展的指令。此外,研究人员还纳入了PPO算法,以进一步提高生成的指令和答案的质量。在获得扩展的指令池之后,通过收集另一个LLM(如GPT-3.5-turbo)的响应来生成新的指令微调数据集。得益于改进的查询深度和宽度,微调后的模型取得了比GPT-3.5-turbo更好的性能。例如,WizardCoder在HumanEval上的性能优于GPT3.5-turbo,有19.1%的改进。与GPT-3.5-turbo相比,WizardMath在GSM8K上也获得了42.9%的改进。
在具有更高质量的数据上进行预训练
Lemur验证了自然语言数据和代码能更好的融合,并证实在函数调用、自动编程和代理能力方面具有更强能力。Lemur-70B-chat在HumanEval和GSM8K上都比GPT-3.5-turbo取得了显著的改进,而无需特定任务的微调。Phi-1和Phi-1.5走了一条不同的道路,将教科书作为预训练的主要语料库,这使得在更小的语言模型上可以观察到强大的能力。
上下文建模能力
基准
处理长序列仍然是LLM的关键技术瓶颈之一,因为所有模型都受到有限的最大上下文窗口的限制,通常从2k到8k token长度。对LLM的上下文能力进行基准测试涉及对几个自然具有长上下文的任务进行评估,如抽象摘要或多文档QA。以下基准已被提出用于LLMs的长上下文评估:
SCROLLS:是一个流行的评估基准,由7个具有自然长输入的数据集组成。任务涵盖摘要、问答和自然语言推理。
ZeroSCROLLS:建立在SCROLLS上(丢弃ContractNLI,重用6个其他数据集,并添加4个数据集),并且只考虑零样本设置。
LongBench:在6个任务中设置了21个数据集的英汉双语长上下文基准。
L-Eval:重用了16个现有的数据集,并从头创建了4个数据集,以创建一个多样化的长上下文基准,每个任务的平均长度超过4k token。作者主张使用LLM进行评估(特别是GPT-4),而不是N-gram进行长上下文评估。
BAMBOO:创建了一个长上下文LLM评估基准,通过仅收集评估数据集中的最新数据,专注于消除预训练数据污染。
M4LE:引入了一个广泛的基准,将36个数据集划分为5种理解能力:显式single-span、语义single-span、显式multiple-span、语义multiple-span和全局理解。
模型
在LongBench、L-Eval、BAMBOO和M4LE基准上,GPT-3.5-turbo或其16k版本的性能基本上超过了所有开源LLM,这表明提高开源LLM在长输入任务上的性能并非易事。Llama-2-long使用16k上下文窗口(从Llama-2的4k增加到400B token)继续对Llama-2进行预训练。由此产生的Llama-2-long-chat-70B在ZeroSCROLLS上的性能比GPT-3.5-turbo-16k高出37.7到36.7。解决长上下文任务的方法包括使用位置插值的上下文窗口扩展,这涉及另一轮微调与较长的上下文窗口,以及检索增强。研究人员结合了这两种看似相反的技术,在7个长上下文任务(包括来自ZeroSCROLLS的4个数据集)中,平均推动Llama-2-70B超过GPT-3.5-turbo-16k。
特定应用能力
面向查询摘要
基准:聚焦查询或基于方面的摘要需要生成关于细粒度问题或方面类别的摘要。面向查询的数据集包括AQualMuse、QMSum和SQuALITY,而基于方面的数据集包括CovidET、NEWTS、WikiAsp等。
模型:与ChatGPT相比,训练数据上的标准微调在性能上仍然更好,比CovidET、NEWTS、QMSum和SQuALITY平均提高了2点ROUGE-1。
开放式QA
基准:开放式QA有两个子类:答案要么是短形式,要么是长形式。短格式数据集包括SQuAD 1.1、NewsQA、TriviaQA、SQuAD 2.0、NarrativeQA、Natural Question (NQ)、Quoref和DROP。长格式数据集包括ELI5和doc2dial。对于短文和长篇数据集,评估指标都是答案中单词的精确匹配(EM)和F1。回答开放式QA要求模型理解提供的上下文,或者在没有提供上下文的情况下检索相关知识。
模型:InstructRetro在NQ、TriviaQA、SQuAD 2.0和DROP上比GPT-3有很大的改进,同时在一系列长短开放式QA数据集上,与类似大小的专有GPTinstruct模型相比,有7-10%的改进。InstructRetro从预训练的GPT模型初始化,通过检索继续预训练,然后进行指令微调。
医学领域
基准:对于心理健康,IMHI基准使用10个现有的心理健康分析数据集构建,包括心理健康检测:DR、CLP、Dreaddit、loneliness、SWMH和T-SID;心理健康原因检测:SAD、CAMS;心理风险因素检测:MultiWD、IRF。对于放射学,OpenI数据集和MIMIC-CXR数据集都包含有发现和印象文本的放射学报告。
模型:为了心理健康,MentalLlama-chat-13B在IMHI训练集上对Llama-chat-13B模型进行了微调。零样本提示的MentalLlama-chat-13B模型在IMHI的10个任务中有9个表现优于少样本提示或零样本提示的ChatGPT。还有研究人员对Llama检查点进行微调,以根据放射学报告发现生成印象文本。由此产生的Radiology-Llama-2模型在MIMIC-CXR和OpenI数据集上都以很大的优势优于ChatGPT和GPT-4。
生成结构化响应
基准:Rotowire包含NBA比赛摘要和相应的得分表。Struc-Bench介绍了两个数据集:Struc-Bench-Latex,其中输出为Latex格式的表格,Struc-Bench-HTML输出为HTML格式的表格。
模型:Struc-Bench在结构化生成数据上微调Llama-7B模型。微调后的7B模型在上述所有基准上的表现都优于ChatGPT。
生成评论
基准:LLM的一个有趣的能力是对问题的回答提供反馈或批评。为了对这种能力进行基准测试,人们可以使用人工标注者或GPT-4作为评估者,直接对评论进行评分。原始问题可以来自上述任何具有其他功能的数据集。
模型:Shepherd是一个从Llama-7B初始化的7B模型,并在社区收集的批判数据和1,317个高质量人工标注数据示例上进行训练。Shepherd在一系列不同的NLP数据集上生成评论:AlpacaFarm、FairEval、CosmosQA、OBQA、PIQA、TruthfulQA和CritiqueEval。使用GPT-4作为评估器,Shepherd在60%以上的情况下会赢或等于ChatGPT。在人工评估方面,Shepherd几乎可以与ChatGPT相提并论。
走向值得信赖的AI
为了确保LLM在现实世界的应用中可以被人类信任,一个重要的考虑因素是它们的可靠性。例如,幻觉和安全性可能会恶化用户对LLM的信任,并在高影响的应用中导致风险。
幻觉
基准:为了更好地评估LLM中的幻觉,人们提出了各种基准。具体来说,它们由大规模数据集、自动化指标和评估模型组成。
TruthfulQA:是一个基准问答(QA)数据集,由跨越38个类别的问题组成。这些问题被精心设计,以至于一些人类也会由于误解而错误地回答它们。
FactualityPrompts:是一个为开放式一代测量幻觉的数据集。它由事实提示和非事实提示组成,以研究提示对LLM的持续影响。
HaluEval:是一个由生成的和人工标注的幻觉样本组成的大型数据集。它跨越了三个任务:问答、以知识为基础的对话和文本摘要。
FACTOR:提出了一种可扩展的语言模型真实性评估方法,它自动将事实语料库转换为忠实度评估基准。该框架用于创建Wiki-FACTOR和News-FACTOR基准。
KoLA:构建了一个面向知识的LLM评估基准(KoLA),具有三个关键因素分别是,模仿人类认知进行能力建模,使用维基百科进行数据收集,以及设计用于自动幻觉评估的对比指标。
FActScore:提出了一种新的评估方法,首先将LLM的生成分解为一系列原子事实,然后计算可靠知识源支持的原子事实的百分比。
Vectara’s Hallucination Evaluation Model:是一个小型的语言模型,它被微调为二进制分类器,以将摘要分类为与源文档事实一致(或不一致)。然后,用它来评估和基准各种LLM生成摘要的幻觉。
FacTool:是一个任务和领域无关的框架,用于检测LLM生成的文本的事实错误。
除了新引入的幻觉基准,之前基于现实世界知识的QA数据集也被广泛用于测量忠实度,如HotpotQA、OpenBookQA、MedMC-QA 和TriviaQA。除了数据集和自动化指标,人工评估也被广泛采用作为忠实度的可靠度量。
模型:超越当前GPT-3.5-turbo性能的方法可以在微调期间纳入,也可以只在推理时纳入。所选性能指标如表3所示。在微调过程中,提高数据质量的正确性和相关性,可以减少模型的幻觉。研究人员策划了一个内容过滤、指令微调的数据集,重点关注STEM领域的高质量数据。一个LLM族在这个过滤后的数据集上进行微调并合并,由此产生的家族,名为Platypus,与GPT-3.5-turbo相比,在TruthfulQA上有了实质性的改进(约20%)。
在推理过程中,现有技术包括特定的解码策略、外部知识增强和多智能体对话。对于解码有Chain-of-Verification(CoVe),其中LLM起草验证问题并自验证响应。CoVe使FactScore比GPT-3.5-turbo有了实质性的改进。
对于外部知识扩充,各种框架结合了不同的搜索和提示技术,以提高当前GPT-3.5-turbo的性能。Chain-ofKnowledge(CoK)在回答问题之前从异构的知识源中检索。LLM-AUGMENTER用一组即插即用模块增强LLM,并迭代修订LLM提示,以使用效用函数生成的反馈改善模型响应。Knowledge Solver (KSL)试图通过利用自身强大的通用性,教会LLM从外部知识库中搜索基本知识。CRITIC允许LLM以类似于人类与工具交互的方式验证和逐步修正自己的输出。Parametric Knowledge Guiding(PKG)框架为LLM配备了一个知识指导模块,以在不改变参数的情况下访问相关知识。与使用GPT-3.5-turbo的朴素提示策略相比,这些推理技术提高了答案的准确性。目前,GPT-3.5-turbo还包含了一个检索插件,可以访问外部知识以减少幻觉。
对于多智能体对话,研究人员促进了生成声明的考生LLM和引入问题以发现不一致的另一个考官LLM之间的多轮交互。通过交叉检查过程,各种QA任务的性能得到了提高。另外的方法要求多个语言模型实例在多轮中提出并辩论各自的响应和推理过程,以得出共同的最终答案,这在多个基准上都有所提高。

安全性
基准:LLM中的安全问题主要可以分为三个方面:社会偏见、模型鲁棒性和中毒问题。为了收集更好地评估上述方面的数据集,人们提出了几个基准:
SafetyBench:是一个由11435个不同的选择题组成的数据集,涵盖7个不同的安全问题类别。
Latent Jailbreak:引入了一个评估LLM安全性和鲁棒性的基准,强调了平衡方法的必要性。
XSTEST:是一个测试套件,系统地识别夸张的安全行为,例如拒绝安全提示。
RED-EVAL:是一个基准,用于执行red-teaming以使用基于Chain of Utterances(CoU)的提示对LLM进行安全评估。
除了自动化基准之外,安全性的一个重要衡量标准是人工评估。一些研究也试图从GPT-4中收集此类标签。
模型:基于当前评估,GPT-3.5-turbo和GPT-4模型在安全性评估方面仍然处于领先地位。这在很大程度上归因于人类反馈强化学习(RLHF)。RLHF首先收集人类对响应的偏好数据集,然后训练一个奖励模型来模仿人类的偏好,最后使用RL训练LLM来对齐人类的偏好。在这个过程中,LLM学习展示所需的行为,并排除有害的反应,如不礼貌或有偏见的答案。然而,RLHF过程需要收集大量昂贵的人工注释,这阻碍了它用于开源LLM。为推动LLM安全对齐的努力,研究人员收集了一个人类偏好数据集,以从人类偏好得分中分离出无害和有用性,从而为两个指标提供了单独的排名数据。另有研究人员试图通过人工智能反馈(RLAIF)来提高RL的安全性,其中使用LLM生成的自我批评和修正来训练偏好模型。直接偏好优化减少了学习奖励模型的需要,并通过简单的交叉熵损失直接从偏好中学习,这可以在很大程度上降低RLHF的成本。结合和改进这些方法可能会导致开源LLM安全性的潜在改进。
讨论
LLMs的发展趋势
自从研究人员证明了冻结的GPT-3模型可以在各种任务上实现令人印象深刻的零样本和少样本性能以来,人们为推进LLM的发展做出了许多努力。研究重点是扩大模型参数,包括Gopher、GLaM、LaMDA、MT-NLG和PaLM,最终达到540B参数。尽管这些模型表现出了非凡的能力,但闭源的性质限制了它们广泛应用,从而导致人们对开发开源LLM的兴趣日益浓厚。
另一项研究没有扩大模型大小,而是探索了预训练较小模型的更好策略或目标,如Chinchilla和UL2。除了预训练之外,还将相当大的精力用于研究语言模型的指令微调,例如FLAN、T0和FLAN-T5。
一年前OpenAI的ChatGPT的出现极大地改变了NLP社区的研究重点。为了赶上OpenAI,谷歌和Anthropic分别引入了Bard和Claude。虽然它们在许多任务上表现出与ChatGPT相当的性能,但与最新的OpenAI模型GPT-4之间仍然存在性能差距。由于这些模型的成功主要归功于从人工反馈中强化学习(RLHF),研究人员探索了各种改进RLHF的方法。
为了促进开源LLM的研究,Meta发布了Llama系列模型。从那时起,基于Llama的开源模型开始爆炸式地出现。一个有代表性的研究方向是利用指令数据对Llama进行微调,包括Alpaca、Vicuna、Lima和WizardLM。正在进行的研究还探索了改进代理、逻辑推理和长上下文建模等能力。此外,许多工作都致力于从头开始训练强大的LLM,而不是基于Llama开发,例如MPT、Falcon、XGen、Phi、Baichuan、Mistral、Grok和Yi。我们相信,开发更强大、更高效的开源LLM,使闭源LLM的能力民主化,应该是一个非常有前途的未来方向。
结果总结
对于一般功能,Llama-2-chat-70B在一些基准中显示了比GPT3.5-turbo的改进,但仍然落后于大多数其他测试。Zephir-7B 通过蒸馏直接偏好优化接近70B LLMs。WizardLM70B和GodziLLa-70B可以实现与GPT-3.5-turbo相当的性能,这表明了一条有前途的道路。
开源的LLM能够通过更广泛和特定任务的预训练和微调超越GPT-3.5-turbo。例如,Lemur-70B-chat在探索环境和跟踪编码任务的反馈方面表现更好。AgentTuning改进了未见过的代理任务。ToolLLama可以更好地掌握工具的使用。Gorilla在编写API调用方面优于GPT-4。对于逻辑推理,WizardCoder和WizardMath通过增强的指令微调来提高推理能力。Lemur和Phi通过对更高质量的数据进行预训练,实现了更强的能力。对于长上下文建模,Llama-2-long可以通过使用更长的token和更大的上下文窗口进行预训练来提高选定的基准。对于特定应用的能力,InstructRetro通过检索和指令微调的预训练,改进了开放式QA。通过特定任务的微调,MentaLlama-chat13B在心理健康分析数据集上的表现优于GPT-3.5-turbo。RadiologyLlama2可以提高放射学报告的性能。只有7B参数的Shepherd在生成模型反馈和批评方面可以实现与GPT-3.5-turbo相当或更好的性能。对于可信的人工智能,可以通过对更高质量的数据进行微调、上下文感知解码技术、外部知识增强来减少幻觉。
还有一些领域GPT-3.5-turbo和GPT-4仍然是不可战胜的,例如人工智能安全。由于GPT模型涉及大规模的RLHF,它们被认为表现出更安全、更符合道德的行为,这可能是商业LLM比开源LLM更重要的考虑因素。然而,随着最近对RLHF进程民主化的努力,我期待看到开源LLM在安全性方面的更多性能改进。
最佳的开源LLMs配方
训练LLM涉及复杂和资源密集的实践,包括数据收集和预处理,模型设计和训练过程。虽然定期发布开源LLM的趋势越来越大,但遗憾的是,主要模型的详细实现细节往往保密。下面我们列出了一些社区广泛认可的最佳实现要点。
数据
预训练涉及使用数万亿的数据tokens,这些tokens通常是公开。从伦理上讲,至关重要的是排除任何包括私人信息的数据。与预训练数据不同,微调数据的数量更少,但质量更高。具有高质量数据的微调LLM表现出了更好的性能,特别是在特定领域。
模型结构
虽然大多数LLM利用只有解码器的Transformer架构,但模型中采用了不同的技术来优化效率。Llama-2实现了Ghost注意力以改进多轮对话控制。Mistral利用滑动窗口注意力来处理扩展的上下文长度。
训练
使用指令微调数据进行监督式微调(SFT)的过程至关重要。对于高质量的结果,数万个SFT注释就足够了,Llama-2使用的27540个注释就证明了这一点。在RLHF阶段,近端策略优化(PPO)通常是首选的算法,以更好地使模型的行为与人类偏好和指令遵循相一致,在增强LLM安全性方面发挥着关键作用。PPO的另一种选择是直接偏好优化(DPO)。例如,Zephyr-7B采用了蒸馏的DPO,并在各种通用基准上显示了与70B-LLMs相当的结果,甚至超过了AlpacaEval上的GPT-3.5-turbo。
潜在问题
预训练期间的数据污染
随着基础模型的发布,数据污染的问题变得越来越明显,这些模型模糊了其预训练语料库的来源。这种透明度的缺乏可能会导致人们对LLM的真正泛化能力的偏见。忽略基准数据通过人类专家的注释或更大的模型手动集成到训练集的情况,数据污染问题的根源在于基准数据的收集来源已经包含在预训练语料库中。虽然这些模型不是故意使用监督数据进行预训练,但它们仍然可以获得准确的知识。因此,解决检测LLM的预训练语料的挑战至关重要,需要探索现有基准和广泛使用的预训练语料之间的重叠,以及评估对基准的过拟合。这些努力对于提高LLM的忠实度和可靠性至关重要。
对齐
基于RLHF在利用一般偏好数据进行对齐方面的应用受到了越来越多的关注。然而,只有有限数量的开源LLM使用RLHF进行对齐,这主要是由于高质量的、公开可用的偏好数据集和预训练奖励模型的稀缺。一些研究人员试图为开源社区做出贡献。然而,在复杂的推理、编程和安全场景中,仍然面临缺乏多样化、高质量和可扩展的偏好数据的挑战。
难以持续提高基本能力
回顾本文概述的基本能力的突破,揭示了一些具有挑战性的场景:
在预训练期间,在探索改进的数据混合方面投入了大量努力,以增强构建更有效的基础模型的平衡性和鲁棒性。然而,相关的勘探成本往往使这种方法不切实际。
超越GPT-3.5-turbo或GPT-4的模型主要是基于从闭源模型中提取的知识和额外的专家注释。虽然效率很高,但在扩展到教师模型时,对知识蒸馏的严重依赖可能会掩盖所提出方法的有效性的潜在问题。LLM被期望充当代理并提供合理的解释以支持决策,而注释代理风格的数据以使LLM适用于现实世界的场景也是昂贵和耗时的。本质上,仅通过知识蒸馏或专家注释的优化无法实现持续改进,可能会接近一个上限。未来的研究方向可能涉及探索新的方法,如无监督或自监督学习范式,以实现基本LLM能力的持续进步,同时减轻相关的挑战和成本。
总结
主要贡献:
整合了对开源LLM的各种评估基准,提供开源LLM与ChatGPT的公正和全面的看法。
系统地回顾了在各种任务中性能与ChatGPT相当或超过ChatGPT的开源LLM并进行分析。我们还维护了一个实时网页来跟踪最新的更新:https://github.com/ntunlp/OpenSource-LLMs-better-than-OpenAI/tree/main
介绍了对开源LLM发展趋势的见解,训练开源LLM的最佳方法和开源LLM的潜在问题。
审核编辑:黄飞
-
对比解码在LLM上的应用2023-09-21 1338
-
无法在OVMS上运行来自Meta的大型语言模型 (LLM),为什么?2025-03-05 349
-
使用开源的麦克风阵列的唤醒识别能力和拾音能力,是否能够在硬件和软件上对当前开源的代码进行分离?2018-08-08 5460
-
邱锡鹏团队提出具有内生跨模态能力的SpeechGPT,为多模态LLM指明方向2023-05-22 1614
-
LLM在各种情感分析任务中的表现如何2023-05-29 3724
-
Macaw-LLM:具有图像、音频、视频和文本集成的多模态语言建模2023-06-19 2421
-
基准数据集(CORR2CAUSE)如何测试大语言模型(LLM)的纯因果推理能力2023-06-20 3528
-
适用于各种NLP任务的开源LLM的finetune教程~2023-07-24 2656
-
Nvidia 通过开源库提升 LLM 推理性能2023-10-23 1761
-
深度解读各种人工智能加速器和GPU上的LLM性能特征2023-10-25 1718
-
Ambarella展示了在其CV3-AD芯片上运行LLM的能力2023-11-28 2971
-
100%在树莓派上执行的LLM项目2024-02-29 2701
-
什么是LLM?LLM的工作原理和结构2024-07-02 20247
-
什么是LLM?LLM在自然语言处理中的应用2024-11-19 5204
-
Google正式发布LLM评测基准Android Bench2026-03-14 2039
全部0条评论

快来发表一下你的评论吧 !
