

CPU的基本组成和工作过程
描述
CPU 按产品市场可分为 x86 系列和非 x86 系列。x86 系列 CPU 生产厂商只有 Intel、AMD、VIA 三家公司,x86 系列 CPU 在操作系统一级相互兼容,产品覆盖了 90%以上的桌面计算机市场。非 x86 系列 CPU 生产厂商有 IBM、Sun、HP、ARM、MIPS、日立、三星、现代、中国科学院计算研究所等企业和单位。非 x86 系列 CPU 主要用于大型服务器和嵌入式系统,这些产品大多互不兼容,在桌面计算机市场中占有份额极小。

Intel 与 AMD 公司的 CPU 虽然在性能和软件兼容性方面不相上下,但配套的硬件平台并不能相互完全兼容。例如,它们需要不同的主板进行产品配套。CPU制造工艺的逐步提升和硬件纠错是工艺步进提升的原因。通常来说,新步进的CPU超频能力更强,发热也会略低。如果两颗 CPU 型号相同,但工艺步进不同,从 CPU 超频角度看,CPU 升级步进工艺的同时,一般也会提高 CPU 的超频能力。

大部分 CPU 采用 LGA 或 FC-PGA 封装形式。FC-PGA 封装是将 CPU 核心封装在基板上,这样可以缩短连线,并有利于散热。LGA 采用无针脚触点封装形式。CPU 由半导体硅芯片、基板、针脚或无针脚触点、导热材料、金属外壳等部件组成。
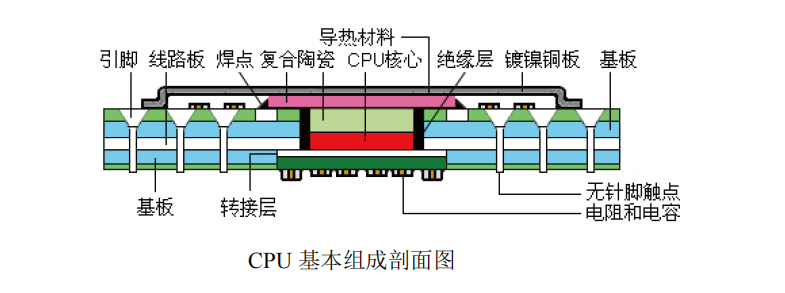
(1)外壳(IHS)。CPU 金属外壳采用镀镍铜板,它的作用是保护 CPU 核心不受外力的损坏。外壳表面非常平整光滑,这有利于与 CPU 散热片的良好接触。
(2)导热材料(TIM)。在金属外壳内部与复合陶瓷之间,填充了一层导热材料,导热材料一般采用导热膏,它具有良好的绝缘性和极佳的导热性能,它的功能是将 CPU 内核发出的热量传导到金属外壳上。
(3)CPU 核心(die)。CPU 核心是一个薄薄的硅晶片,尺寸一般为 12mm×12mm×1mm左右。目前 CPU 核心中有多个内核(2/4/6/8 个),8 内核的 Intel Xeon CPU 集成的晶体管数达到了 24 亿个。
(4)转接层。CPU 核心与基板之间有一个转接层,它的作用有三个:一是将非常细小的 CPU 内核信号线转接到 CPU 针脚上;二是保护脆弱的 CPU 核心不受损伤;三是将 CPU核心固定在基板上。转接层采用复合材料制造,有良好的绝缘性能和导热性能。在转接层上,采用光刻电路与 CPU 内核的电路直接相连。在转接层下面,采用焊点与基板上的线路相连。
(5)基板。金属封装壳周围是 CPU 基板,基板的功能一是连接转接层与 CPU 针脚,另外一个功能是设计一些电路,防止 CPU 内核的高频信号对主板产生干扰。
(6)电阻和电容。基板底部中间有的电容和电阻,主要用于消除 CPU 对外部电路的干扰,以及与主板电路进行阻抗匹配。每个系列的 CPU 产品,这些电容和电阻的排列方式都有所不同。
(7)针脚。基板下面的镀金无针脚触点,是 CPU 与外部电路连接的通道。
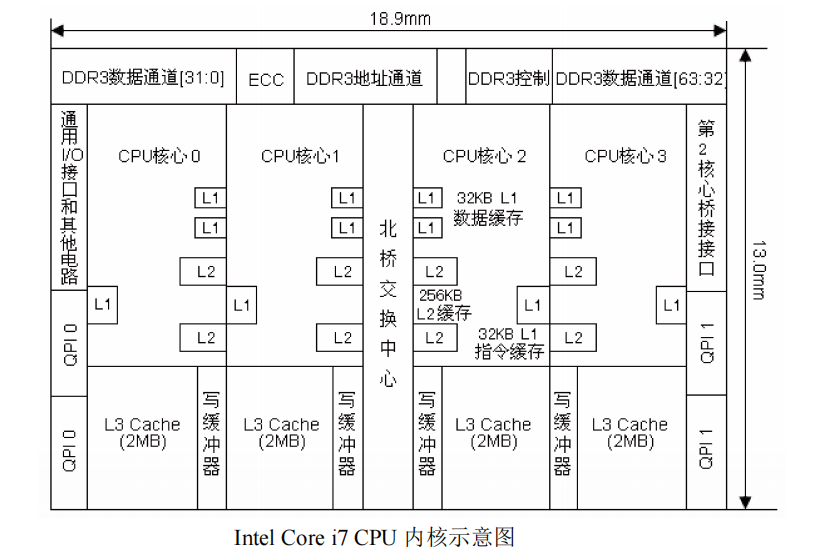
Core i7 CPU 内核分为核心(Core)与非核心(UnCore)两大部分。核心部分包括 CPU执行流水线和 L1、L2 级高速缓存。非核心部分为 L3 级高速缓存、集成内存控制器(IMC)、快速路径互连总线(QPI),以及功耗与时钟控制单元等。
CPU 工作过程大致如下:指令和数据在执行前,首先要加载到内存或 CPU 内核的高速缓存(L1/L2/L3 Cache)中,这个过程称为缓存。CPU 根据指令指针(PC)寄存器指示的地址,从高速缓存或内存中获取指令;然后对分支指令进行预测工作,这个过程称为取指令(IF)。
CPU取到指令后,需要判断这条指令是什么类型的指令,需要执行什么操作,并负责把取出的指令译码为微操作(μOP)指令,这个过程称为译码(DEC)。指令译码后可以得到操作码和操作数地址,然后根据地址取操作数。然后需要对多条微操作指令分配计算所需要的资源(如寄存器、加法器等),这个过程称为指令控制(ICU)或指令分派。
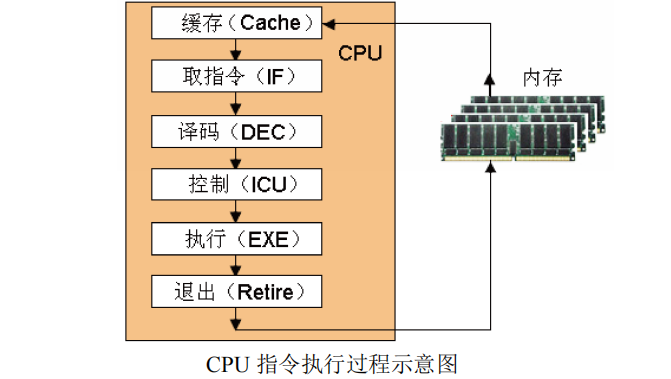
当操作数被取出来以后,计算单元(如 ALU)根据操作码的指示,就可以对操作数进行正确的计算了,指令的计算过程称为执行(EXE)。执行结束后,计算结果被写回到 CPU内部的寄存器堆中,有时需要将计算结果写回到缓存和内存中,这个过程称为退出(Retire)或写回。到此为止,一条指令的整个执行过程就完成了。
Core i7 CPU 包括几十个系统单元。从体系结构层次看,CPU 的内部结构主要有缓存单元(Cache)、取指单元(IF)、译码单元(DEC)、控制单元(ICU)、执行单元(EXE)、退出单元(RU)等。
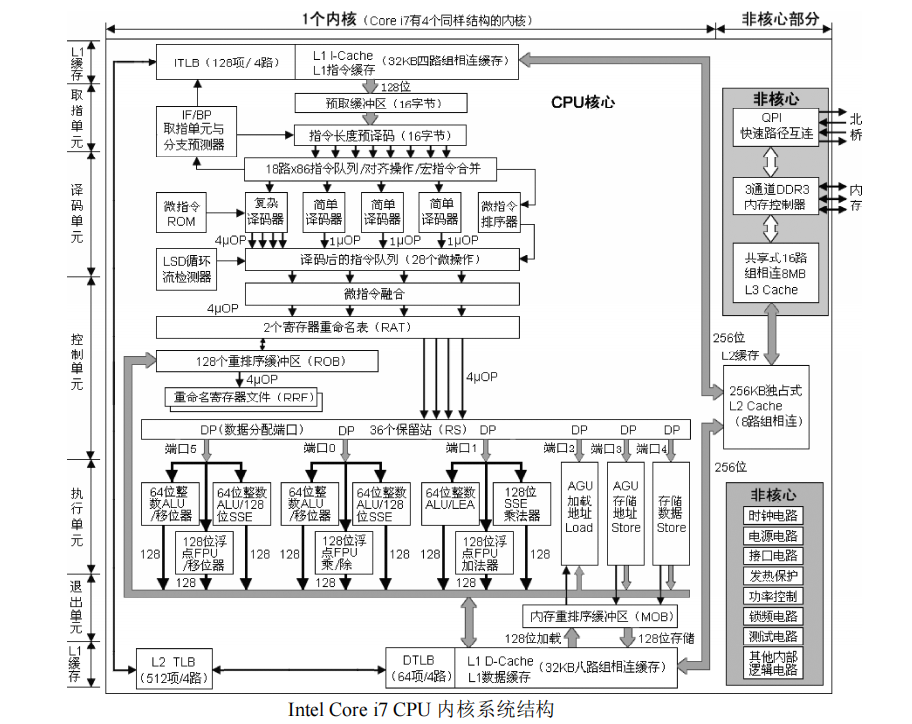
Core i7CPU 每个单核有 5 个 64 位整数算术逻辑运算单元(ALU),3个 128 位的浮点处理单元(FPU)。CPU 中每个核心在最好的情况下,理论上每个时钟周期可以进行以下操作:取指令或数据 128 位/周期;译码 4 条 x86 指令(1 个复杂指令,3 个简单指令)/周期;发送 7 条微指令/周期;重排序和重命名 4 条微指令/周期;发送 6 条微指令到执行单元/周期;执行 5×64 位=320 位整数运算/周期;或执行 3×128 位=384 位浮点运算/周期;完成并退出 4 条微指令(128 位)/周期。CPU 在 3.2GHz 频率下的峰值浮点性能为 51GFLOPS(双精度)或者 102GFLOPS(单精度)。
CPU 访问存储系统时,在存储系统中找到所需数据的概率称为命中率,命中率计算方法如下所示,命中率越接近于 1 越好。

CPU 访问存储系统时,通常先访问 Cache,由于 CPU 所需要的信息不会百分之百地在Cache 中,这就存在一个命中率的问题。从理论上说,只要 Cache 的大小与内存的大小保持适当比例,Cache 的命中率是相当高的。对于没有命中的指令或数据,CPU 只好再次访问内存,这时 CPU 将会浪费更多的时间。
为了保证 CPU 访问 Cache 时有较高的命中率,Cache 中的内容一般按一定的算法进行替换。较常用的算法有“最近最少使用算法”(LRU),它是将最近一段时间内最少被访问过的 Cache 数据行淘汰出局。目前 CPU 高速缓存的命中率可达到 95%以上。
审核编辑:汤梓红
-
电气设备的组成和工作过程2024-06-06 5903
-
Zeta拓扑电源原理及工作过程解析2023-11-24 7696
-
STM32 PWM工作过程2022-01-06 1816
-
计算机硬件的基本组成2021-12-23 2228
-
CPU工作过程——MCU2021-10-25 661
-
计算机的基本组成及工作原理是什么2021-09-16 1500
-
计算机的分类及基本组成2021-07-16 1522
-
计算机的基本组成和工作原理是什么2021-06-30 1341
-
大功率开关电源工作原理及基本组成2019-11-20 14653
-
开关电源的基本组成及工作原理2018-10-15 2184
-
IPOA的工作过程是怎样的?2010-04-07 791
-
数控机床的工作过程2009-05-06 5260
-
DS1302 的基本组成和工作原理2008-01-14 1772
全部0条评论

快来发表一下你的评论吧 !
