

深度解读亚马逊AI芯片核心技术
人工智能
描述
亚马逊网络服务可能不是第一家创建自己的定制计算引擎的超大规模提供商和云构建商,但它紧随谷歌之后发布了自研的AI芯片——谷歌于 2015 年开始使用其自主研发的 TPU 加速器来处理人工智能工作负载。
AWS 于 2017 年开始使用“Nitro”DPU,并很快决定如果要在未来继续在服务器基础设施方面进行创新,就需要在所有方面对计算引擎进行创新。现在我们已经看到了多代 Nitro DPU、四代 Graviton Arm 服务器 CPU、两代 Inferentia AI 推理加速器,以及现在的第二代 Trainium AI 训练加速器。Trainium2 芯片与 Graviton4 服务器 CPU 一起在 AWS 最近于拉斯维加斯举办的 re:Invent 2023 大会上亮相,我们花了一些时间尝试了解这个新的 AI 训练引擎以及它与 Inferentia 系列的关系。
AWS 尚未公布有关这些 AI 计算引擎的大量详细信息,但我们(指代nextplatform)设法与 Gadi Hutt 进行了一些交流,他是 AWS Annapurna Labs 部门的业务开发高级总监,负责设计其计算引擎并通过代工厂和指导它们。深入了解 AWS 系统,更深入地了解 Inferentia 和 Trainium 之间的关系以及对 Trainium2 的期望;我们还对技术文档中的规格进行了一些挖掘,并尝试填补空白,就像我们发现信息缺乏时所做的那样。
不过,为了做好准备,我们先做一点数学计算,然后再了解 AWS AI 计算引擎的数据源和速度。
在 AWS 首席执行官 Adam Selipsky 的 re:Invent 主题演讲中,Nvidia 联合创始人兼首席执行官黄仁勋是一位惊喜嘉宾,他在讲话中表示,在“Ampere”A100 和“Hopper”H100 期间,AWS 购买了两百万个这样的设备。
有传言称,AWS 将在 2023 年完成大约 50,000 个 H100 订单,我们假设去年可能有 20,000 个订单。以每台 30,000 美元的价格——考虑到需求,Nvidia 几乎没有动力打折,而且最近几个季度的净利润率远高于其数据中心收入的 50% ——即 21 亿美元。这还剩下 193 万美元的 A100,按照 2020 年至今的平均价格约为 12,500 美元计算,总计 241.3 亿美元。
在如此巨大的投资流中,性价比曲线显然还有弯曲的空间,而且 AWS 创建了自己的 Titan 模型,以供母公司 Amazon 和数以万计的企业客户使用,并提供其他模型,重要的是来自 Anthropic 的Claude 2,在其本土开发的 Inferentia 和 Trainium 上运行。
我们认为这条曲线看起来与 AWS 使用 Graviton 服务器 CPU 所做的没有太大不同。AWS 非常乐意销售 Intel 和 AMD 的 CPU,但它的价格/性能比“传统”高出 30% 到 40%。由于它通过 Graviton 省去了中间商,因此可以以更低的价格提供 Arm CPU 实例,这对越来越多的客户有吸引力。我们预计 Nvidia 和 AMD GPU 以及 AWS 制造的 Inferentia 和 Trainium 设备之间也会存在同样的传统定价差距。
抛开这些数学问题,我们来谈谈 Inferentia1,并概览一下 Inferentia2 和 Trainium1,这样我们就可以了解 Trainium2,它将与当前在 Hopper H100 GPU 加速器上运行的工作负载进行正面竞争。如您所知,H100 的价格几乎与黄金一样昂贵(目前 SXM5 版本每盎司的价格约为黄金的一半),并且像稀土矿物一样难以获得,并且是支撑人工智能经济的不可或缺的一部分。
推断 TRAINIUM 的架构
所有计算引擎都是计算元素、存储元素和将它们连接在一起的网络的层次结构,并且围绕这些元素的抽象级别可能会发生变化,特别是当架构是新的并且工作负载快速变化时。
Inferentia1 芯片由 Annapurna Labs 的人员创建,于 2018 年 11 月首次发布,一年后全面上市,是 AWS AI 引擎工作的基础,以下是该设备的架构:
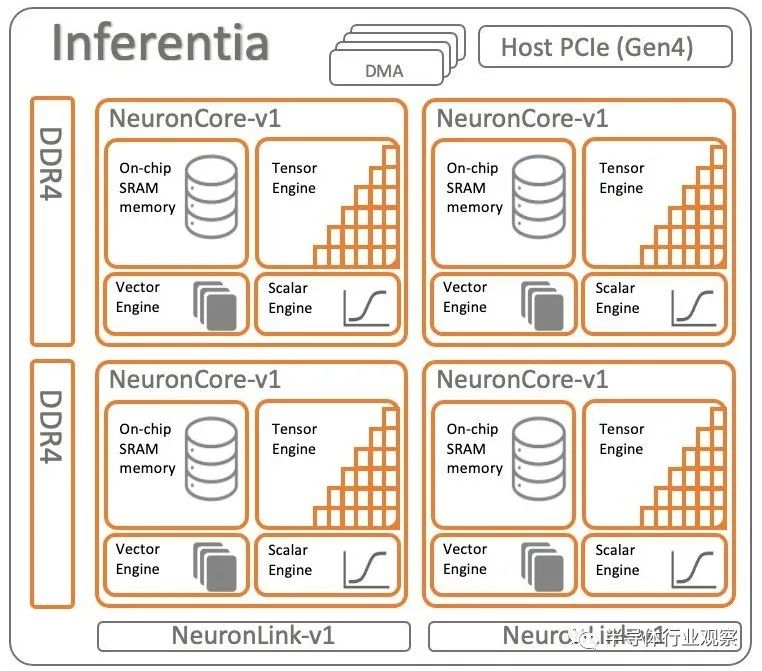
该器件有四个内核,具有四个不同的计算元件,以及用于片上存储的片上 SRAM 存储器和用于片外存储的 DDR4 主存储器,这与当今许多 AI 芯片制造商一样。AWS 没有提供 Inferentia1 设备的 SRAM 内存和缓存大小或时钟速度的详细规格,甚至没有提供设备中使用的每个 NeuronCore 内的元件数量。不过在 Inferentia 和 Trainium 芯片的 Neuron SDK 中,AWS 确实讨论了 Inferentia2 和 Trainium1 中使用的 NeuroCore-V2 核心的架构,我们可以以此为基础来弄清楚 Inferentia1 是什么,并推断出 Trainium2 可能是什么是。
无论是哪代,NeuronCore 都有一个处理标量计算的 ScalarEngine 和一个处理各种精度的整数和浮点数据向量计算的 VectorEngine。这些大致相当于 Nvidia GPU 中的 CUDA 核心。根据 Neuron SDK,NeuronCore-v1 ScalarEngine 每个周期处理 512 个浮点运算,VectorEngine 每个周期处理 256 个浮点运算。(我们认为AWS的意思是ScalarEngine上每个周期有512位处理,VectorEngine上每个周期有256位处理,然后您通过这些以选择的格式泵送数据以进行特定类型的计算。
NeuronCore 架构还包括一个 TensorEngine,用于加速矩阵数学,超出了通过 VectorEngine 推动代数矩阵数学的能力,而矩阵数学对于 HPC 和 AI 工作负载至关重要,它们通常会完成大量工作并提供最大的吞吐量。TensorEngine 大致类似于 Nvidia GPU 中的 TensorCore,在 NeuronCore-v1 内核中,它们可以在 FP16/BF16 粒度下提供 16 teraflops。
Trainium1 芯片于 2020 年 12 月发布,并以两个不同的实例(Trn1 和 Trn1n)发货。我们当时对 Trainium1 和2021 年 12 月的这些实例进行了尽可能多的分析,坦率地说,AWS 没有提供大量有关这些本土 AI 计算引擎的数据。Trainium1 使用了新的 NeuroCore-v2 核心,它具有相同的元素,但核心数量更少,如下所示:
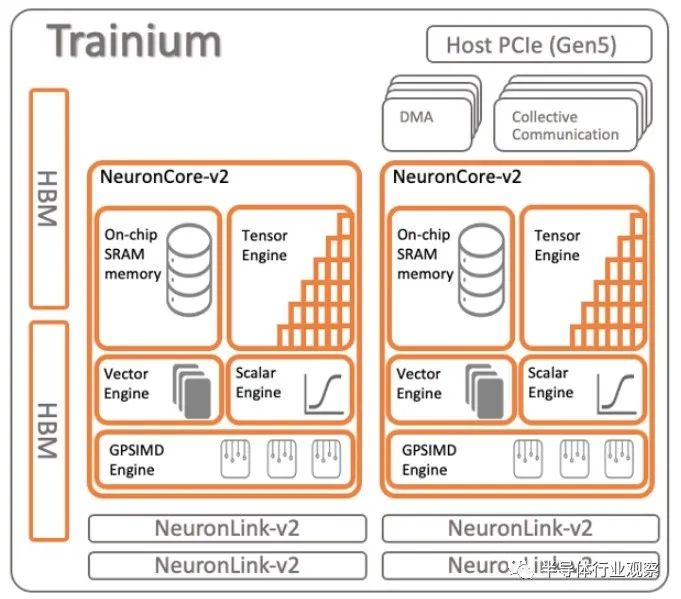
通过 Trainium1 芯片,AWS 添加了 32 GB HBM 堆叠 DRAM 内存以提高设备的带宽,转向 PCI-Express 5.0 外形尺寸和 I/O 插槽,并增加了 NeuronLink 芯片间互连链路的数量其带宽提高了 2 到 4 倍,同时带宽也提高了 2 倍。
我们没有证据证明这一点,但我们认为,通过 Trainium1,AWS 将每个芯片的 NeuronCore 数量比 Inferentia1 减少了一半(两个而不是四个),然后每个核心内的标量、矢量和张量引擎的数量增加了一倍。当时的变化实际上是缓存和内存层次结构抽象级别的变化,基本上使 NeuronCore 在每个计算元素类型中实现多线程。
有趣的是,Trainium 芯片中首次使用的 NeuronCore-v2 还包括称为 GPSIMD 引擎的东西,它是一组 8 个 512 位宽的通用处理器。(确实非常有趣。)这些设备可以直接使用 C 和 C++ 进行寻址,并且可以访问片上 SRAM 和内核上的其他三种类型的引擎,并用于实现需要加速且不需要加速的自定义操作。直接受其他引擎中的数据和计算格式支持。(我们必须查阅Flynn 的分类法,试图弄清楚这个 GPSIMD 引擎是如何适应的,并且从文档中并不清楚我们看到的是这是一个阵列处理器、管道处理器还是关联处理器.)
用于推理的 Inferentia2 芯片基本上是一个 Trainium1 芯片,其数量只有一半的 NeuronLink-v2 互连端口。芯片的某些元件也可能未激活。时钟速度和性能似乎大致相同,HBM 内存容量和带宽也是如此。
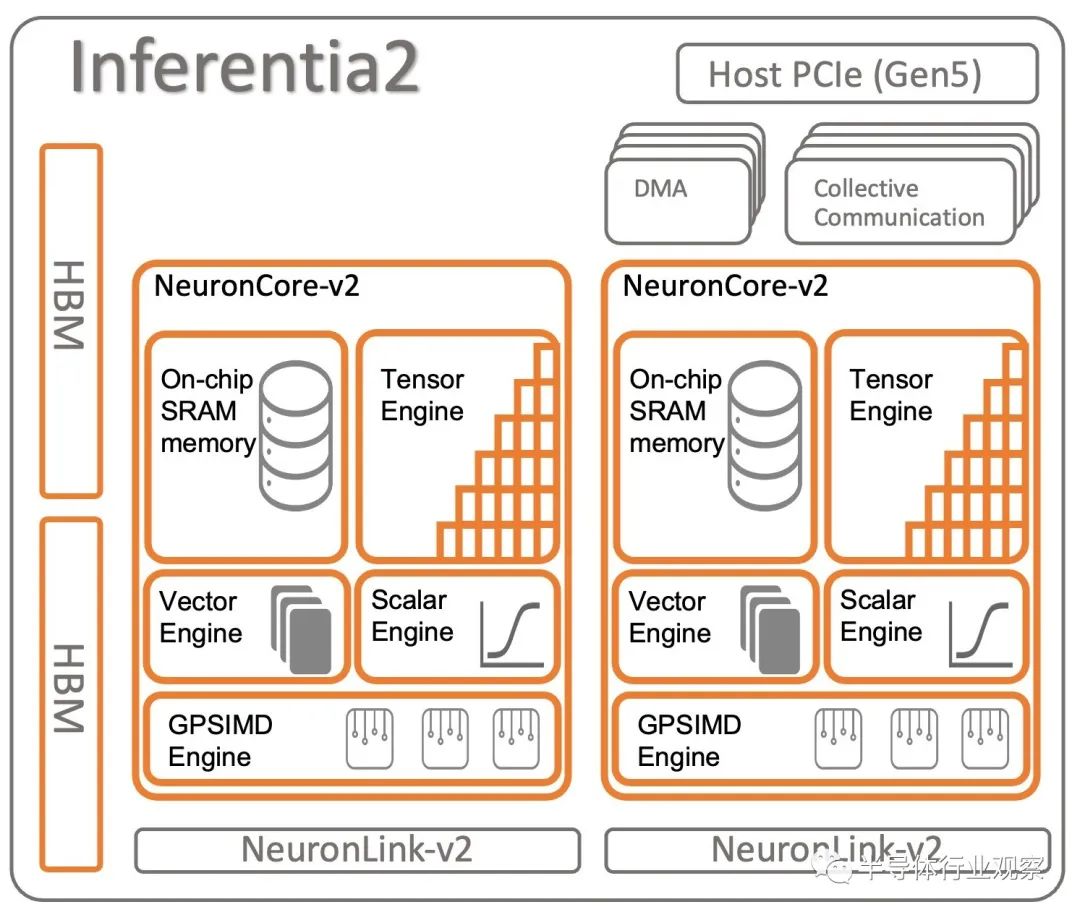
“Inferentia2 和 Trainium1 之间的芯片架构几乎相同,”Hutt 告诉The Next Platform。“我们为 Inferentia2 保留了 HBM 带宽,因为这对于推理非常重要,而不仅仅是训练。LLM 推理实际上受内存限制,而不是计算限制。因此,我们实际上可以采用类似的硅架构并尽可能降低成本 - 例如,我们不需要那么多的 NeuronLink。通过推理,当我们从一个加速器移动到另一个加速器时,我们只需要环形的链接来生成token。当然,通过训练,您需要完整的网状连接,最大限度地减少服务器内部每个加速器之间的跳数。当然,当你访问训练服务器时,你需要大量的网络带宽。”
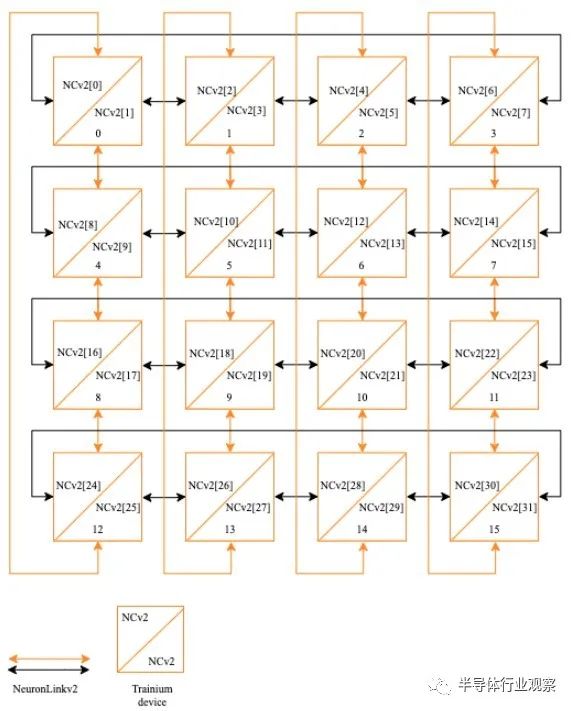
使用 16 个 Trainium1 芯片的服务器上的互连是一个 2D 环面或 3D 超立方体,根据 Hutt 的说法,它们是同一件事,具体取决于你想如何谈论它,它看起来像这样:
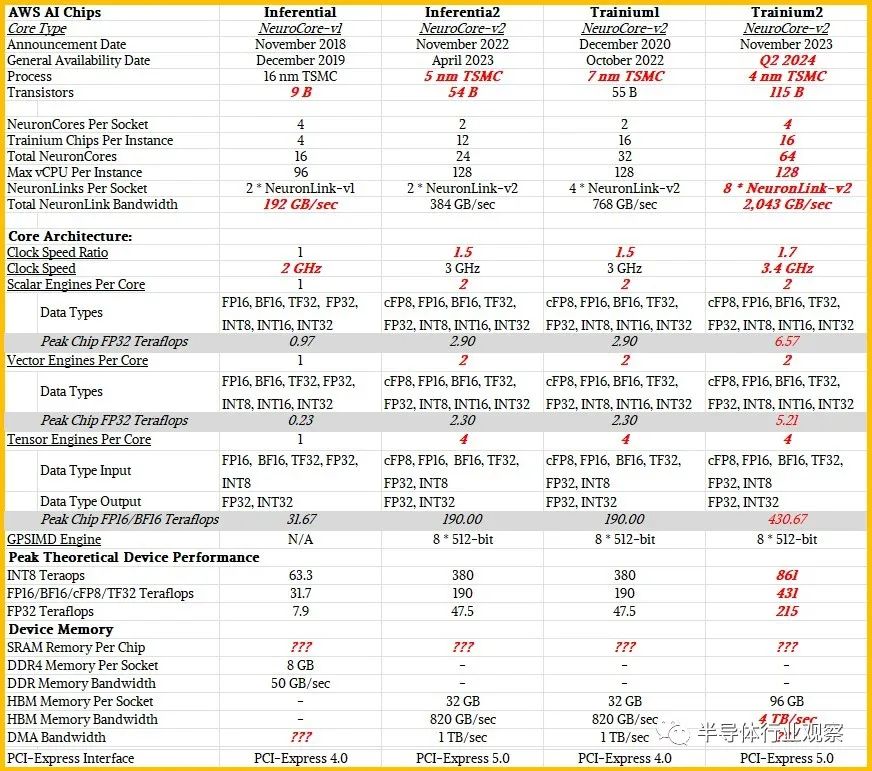
下面的表格汇集了我们所知道的 Inferentia1、Inferentia2 和 Trainium1 的馈送和速度,以及我们对 Trainium2 的预测(以粗体红色斜体显示)。Neuron SDK 尚未使用有关 Trainium2 的任何信息进行更新。
根据如下所示的 Trainium2 芯片封装图片,我们认为它本质上是两个 Trainium1 芯片互连在一起,要么作为单片芯片,要么作为两个小芯片插槽,通过某种高速互连将它们连接在一起:
Hutt 没有透露 Trainium 芯片的任何数据和速度,但他确实确认 Trainium2 拥有更多的内核和更多的内存带宽,并进一步补充说,芯片的有效性能将扩展到 4 倍——他称这是一个保守的数字,也许超出了现实世界人工智能训练工作负载的 Trainium1 的数字,因为这些工作负载更多地受到内存容量和内存带宽的限制,而不是受计算的限制。
我们认为Trainium2芯片将有32个核心,并将从Trainium 1使用的7纳米工艺缩小到4纳米工艺,这样核心的加倍就可以在与Trainium1相同或稍高的功率范围内完成。我们还认为,Trainium2 中的时钟速度将从 Trainium1 中使用的 3 GHz(AWS 已透露的数字)适度提高到 3.4 GHz。我们还认为(仅基于预感),Trainium2 上的总 NeuronLink 带宽将增加 33%,达到每个端口 256 GB/秒,从 Trainium2 产生 2 TB/秒,并且仍然允许 2D环面互连。每个芯片上的 NeuronLink 端口数量可能会增加,以增加环面的维数,并减少设备共享数据时设备之间的一些跳数。2D 环面意味着集群中任意两个 NeuronCore 芯片之间有固定的两跳。网络似乎不太可能增加到全面配置,但这是可能的。(SGI 曾经用其超级计算机芯片组来做到这一点。)
我们还认为,鉴于 AWS 希望使用 Trainium2 将 UltraCluster 扩展到 100,000 个设备,它将减少 Trainium2 上的实际核心数量,使其比我们在上表中显示的 64 个核心少很多。
很难说它会在哪里,假设大约 10% 的核心将是无用的,因此芯片的产量将会高得多。您可以打赌,AWS 将保留任何可以在一组单独的机器中运行所有核心的 Trainium2 设备,很可能供每个核心都很重要的内部使用。这将使 Trainium2 拥有 56 个核心或 58 个核心,甚至可能高达 56 个核心,并且所有带宽都可供它们使用。AWS 承诺的 96 GB 可能仅用于我们认为在设备上看到的四个内存堆栈中的三个,该设备可能具有 128 GB 的实际 HBM 内存。我们强烈怀疑这将是 HBM3 内存,但 Hutt 没有证实任何事情。
但他多次说过,性能是由内存驱动的,而不是指望原始峰值理论计算的增长速度快于内存带宽,如果我们是对的,内存带宽将增长 5 倍位于 Trainium1 和 Trainium2 之间。
以下是使用 Inferentia 和 Trainium 芯片可用的实例:
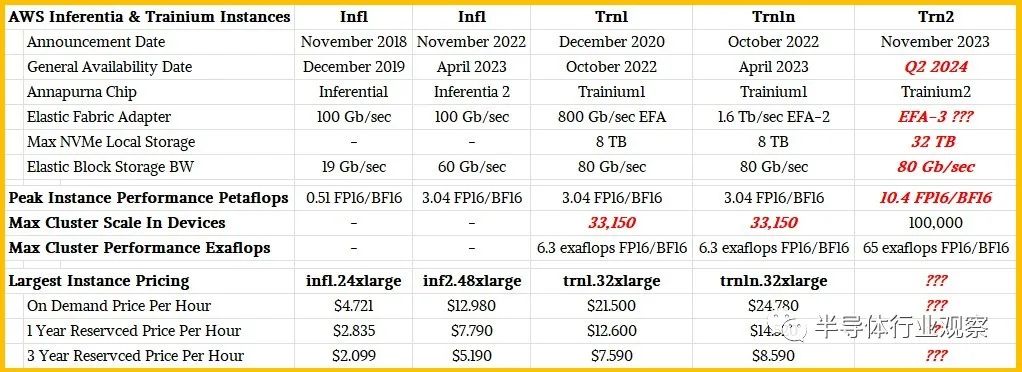
任何人都在猜测 Trn2 实例在价格或性能方面的比较,但根据暗示和预感,我们坚信 Trainium2 将提供 Nvidia H100 大约 2 倍的性能,这意味着它将与之旗鼓相当- Nvidia 刚刚发布的 H200 配备了更大、更快的 HBM3e 内存,适用于许多型号。当我们建议 AWS 可能会对基于 Trainium2 的 EC2 实例相对于使用 Nvidia 的 H100 和 H200 GPU 的实例进行定价时,其比率与其自己的 Graviton CPU 与 AMD 和 Intle X86 处理器之间的比率相同 - 介于 30% 到 40% 之间物有所值——Hutt并没有劝阻我们放弃这种想法。但Hutt也没有做出任何承诺,只是说性价比肯定会更好。
这并非毫无意义,而是将 100,000 个设备以 FP16 精度以 65 exaflops 连接在一起,并且没有任何稀疏技巧,而是真正的 FP16 分辨率,有机会成为世界上最大的人工智能集群。
审核编辑:黄飞
-
小鹏图灵AI芯片深度解读2025-03-12 9453
-
最新视频编码标准H.264及其核心技术2008-06-25 8920
-
蓝牙核心技术概述2014-11-24 10253
-
【原创】Android视频直播核心技术2016-07-26 4254
-
31岁无核心技术,迷茫2018-03-27 3154
-
MATLAB机器学习与深度学习核心技术应用培训班2018-10-23 3549
-
云计算的五大核心技术2019-06-28 3037
-
五大核心技术如何实现物联网2019-07-25 3064
-
AI芯片怎么分类?2019-08-13 4846
-
深度学习推理和计算-通用AI核心2020-11-01 3588
-
无线远程监控系统主要包括哪些核心技术?2021-05-25 1824
-
视频标准核心技术对比分析哪个好2021-06-07 1801
-
单片机应用的核心技术是什么?2021-11-02 3100
-
解读可穿戴设备代表性产品核心技术原理2023-10-31 576
-
炬芯科技 ATS288X AI-Party Speaker 芯片的核心技术解读2025-06-06 4175
全部0条评论

快来发表一下你的评论吧 !
