

基于transformer和自监督学习的路面异常检测方法分享
电子说
描述
01
文章摘要
铺设异常检测可以帮助减少数据存储、传输、标记和处理的压力。本论文描述了一种基于Transformer和自监督学习的新方法,有助于定位异常区域。实验结果显示,自监督学习可以提高在小型未标记图像数据集上的性能。Transformer被证明在路面损坏检测领域是适用的。文章构建的类似于人脸识别的框架可以通过将新的补丁放入图库中来增强性能,而移除相似的补丁不会影响识别结果。该方法足够高效和小型化,以支持实时工作,并且可以直接应用于边缘检测。
02
主要工作与贡献
- 该论文提出了一种新颖的方法,将Transformer模型和自监督学习相结合,用于路面异常检测。Transformer是一种强大的神经网络架构,用于处理序列数据,在该研究中被应用于图像数据,并取得了显著的成果。
- 监督学习是一种无需人工标注的学习方法,可以从未标记的数据中学习有用的特征。该论文展示了自监督学习在小型未标记图像数据集上的应用,并证明它能够显著提高性能。
- 研究人员构建了一个类似于人脸识别的框架,通过将新的图像补丁加入图库中,来增强路面异常检测的性能。这种方法能够在不进行训练的情况下实现性能的提升。
- 该方法被证明足够高效和小型化,能够支持实时工作,因此可以在实际应用中进行边缘检测和路面异常监测。
03
所提方法
Transformer可能比CNN更好,因为Transformer天然具有全局感受野,可以捕捉长距离像素之间的关系。自注意力机制可能有助于解决缺乏数据的问题,因为在类似条件下,MAE(掩码自编码器)表现良好。本论文将自监督学习和Transformer应用于路面异常检测。使用ViT-S的自监督学习来重构未标记的路面图像,并提出了一种编码-检索-匹配的路面异常检测方法来解决分类重训练的问题。文章方法的框架如图1所示。主要由两个部分组成:图库和编码器。首先,图像将被划分为几个补丁,并且典型的补丁将被添加到图库中。这将降低分辨率并减少背景像素。在模型训练完成后,将提取编码器部分。所有的补丁都可以被编码成特征向量。一旦向量被编码,计算它们之间的距离得到一个距离向量(一列)。最后,将找到与预测类别最接近的补丁。

图1 论文方法总体架构
01.编码器
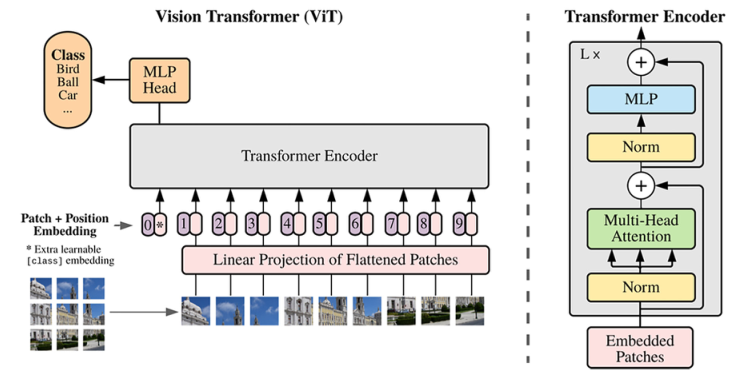
图2 ViT架构
ViT是Transformer在计算机视觉领域的第一个成功应用,它简单地将图像划分为补丁作为输入序列,以便Transformer能够处理。参考了BERT,ViT在其中添加了一个[class]标记来融合用于分类的信息。如图2所示,ViT首先通过平均划分输入来获取图像补丁,然后进行线性投影以获取图像标记。一旦生成了标记,将添加位置嵌入以恢复丢失的位置信息。然后,它们将被输入到Transformer编码器中。最后,只有[class]标记将在分类中使用。多头注意力机制可以用公式(1)来描述。
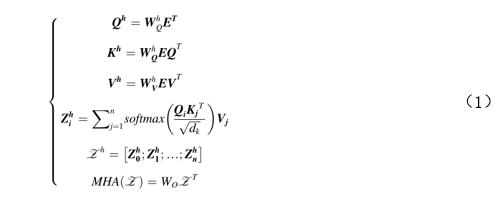
其中,n表示嵌入的数量,Zh是第h个注意头的输出,dk表示K的维度。嵌入E和可学习权重W进行点积运算,以得到查询(Query)Q,键(Key)K和值(Value)V。
最终输出是可学习权重和Z(堆叠Zh)的点生成。不同头部的权重是独立的,以确保从各种表示子空间中提取特征。整个过程可以大致描述为等式(2)-(5)。
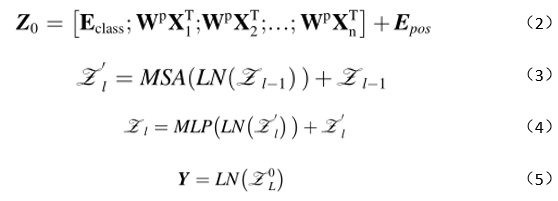
其中Z0表示输入向量,Y是用于分类的图像表示。Z0L是Z的位置0上的标记(也称为[class]标记)。LN表示层标准化。
02.Drop path
文章采用“drop path” 作为一种规范化方法来防止过拟合。简单来说,它会根据预先确定的概率随机地禁用每一层之间的路径,至少保留一条路径。在实现中,对于每一层的多个输入,会随机丢弃一些输入。这个效果类似于模型集成,其中不同的路径组合意味着不同的子网络,而在预测时不会丢弃路径来将它们组合起来。
03.监督学习
在实验中,文章使用图像补丁作为输入,输出为正常或异常。因此,这是一个二元分类任务;输出值是介于0到1之间的sigmoid输入得分。数值越接近0,输入越有可能是异常(类别0)。相反,越接近1,输入越有可能是正常的(类别1)。在训练过程中,sigmoid得分(x)与真实值(y)之间的差距越大,二元交叉熵损失就越大。在模型用于推断时,会设置一个阈值(通常为0.5)。当sigmoid得分低于阈值时,输入被视为异常,反之亦然。
04.自监督学习
MAE是一种基于部分掩膜图像的像素级重建任务的方法。编码器仅对可见的补丁进行编码。编码完成后,[mask]标记将添加到相应的位置。解码器将接收所有标记作为输入进行重建。
MAE的关键方面可以分为四个部分:掩膜策略、编码器、解码器和重建目标。掩膜策略通常选择随机掩膜,掩膜比例较大。在这种情况下,被掩膜部分占据了图像的大部分区域,很难找到掩膜周围的未掩膜区域,迫使模型学习不依赖局部信息。文章选择纯粹的ViT作为编码器,因为它没有引入过多的修改,导致对特定领域过拟合,并且重建目标是均方损失。
05.类似面部识别的框架
通常,模型在超出其训练数据分布范围的数据上表现较差。不同地区之间存在明显的道路差异,例如路面分类,将会降低模型的精度。文章从最佳ViT-S模型中提取编码器作为帧中的编码器。选择第11、12、13、10、9、8和6列的图像块作为输入,因为这些位置的异常概率较高。如果Sigmoid输出低于某个阈值,该类别被认为是异常(类别0)。一旦预测为异常,整个输入图像都被视为异常。
04
实验验证
1
监督学习结果
表1 ViT-S在不同DA和drop path下的精度比较
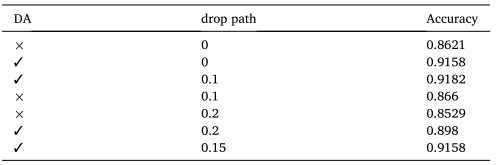
监督学习的结果显示在表格1和图3、图4中。表格1显示数据增强(DAs)比随机删除路径(drop paths)可以带来更多的性能提升。从图3和图4可以看出,两个模型在最后几个周期开始过拟合。Resnet的结果较好,因为它收敛到一个更好的局部最优点。CNN具有局部相关性等先验知识,当数据较少时会导致这样的结果。而Transformer没有这样的知识,因此需要从更多数据中进行学习。
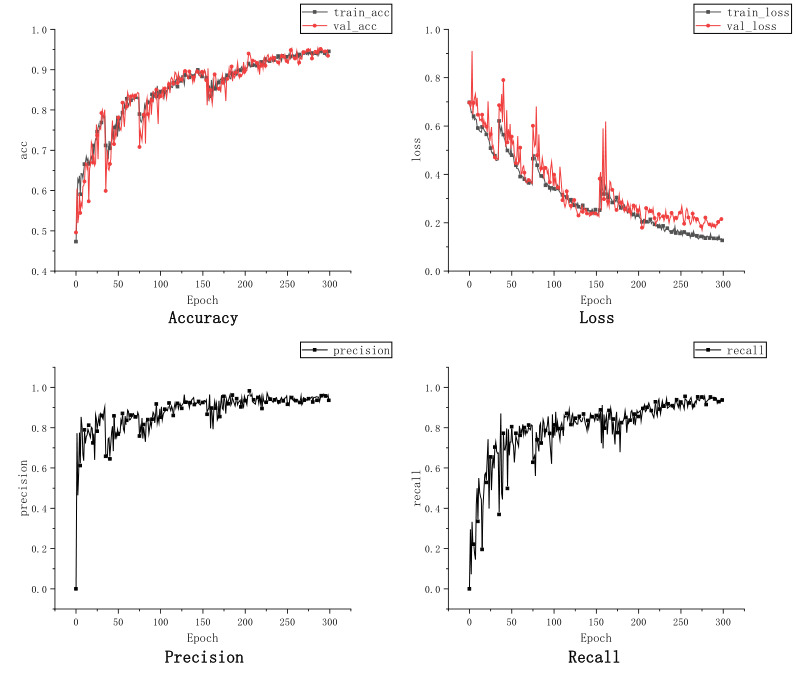
图3 resnet34的学习曲线
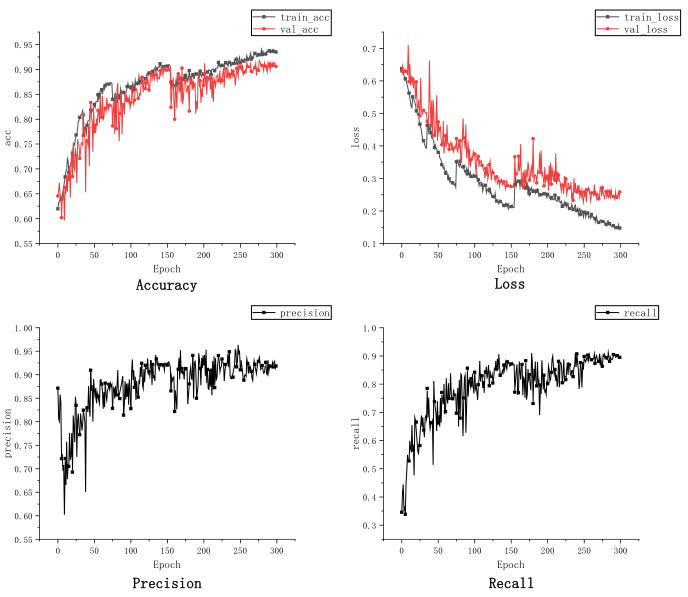
图4 ViT–S的学习曲线
2
自我监督学习结果
表2证明,在微调中应用DA对于提高性能是必要的,因为最高精度主要取决于微调,使模型适应二进制分类任务。如果微调数据的数量不足,模型仍然会过拟合。根据有监督和自监督学习图,MAE可以显著加速收敛并提高精度。
表2 在不同位置应用DA的准确性

3
可视化视角讨论
文章使用GradCAM(梯度加权类激活映射)来直观地分析文章的路面异常检测算法。选择了两张分别具有两种类型的明显遇险的测试图像。图5图6显示了结果。混合结果意味着所有头的平均值。图中的响应越高,它与分类的相关性就越大。图6与无MAE的ViT相比,有MAE的ViT在遇险周围有更集中的活动区域。这一事实支持了像MAE这样的自监督学习可以帮助模型在数据集几乎没有标记数据的情况下学习更好的表示。此外,我们可以看到,最后两个区块比其他区块更关注遇险区域。有一些像Block_9这样的块具有统一的响应。这一发现在图5中更为明显。
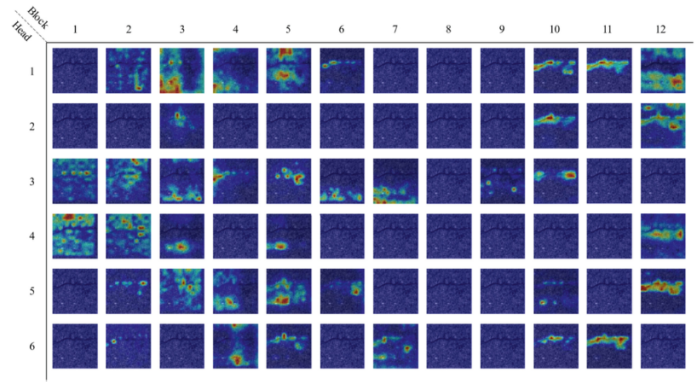
图5 测试图像A中ViT w/MAE的单独结果
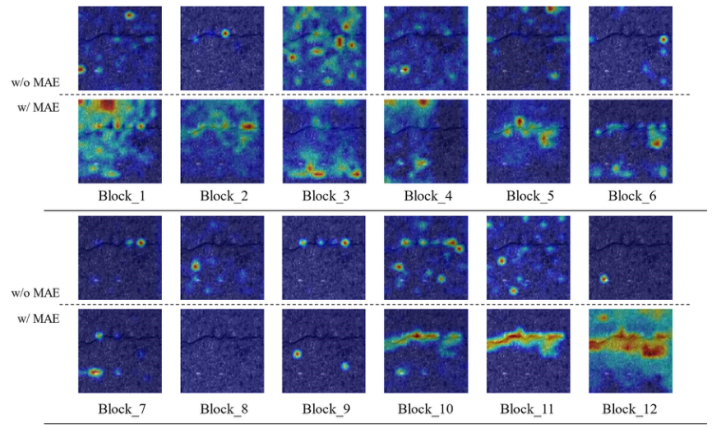
图6 测试图像A中ViT w/MAE和ViT w/o MAE的混合结果
05
结论
研究旨在快速检测道路异常,以减少路面损坏识别、数据存储和标注的工作量。通过验证异常检测任务,自监督学习对这个问题产生了显著影响,其价值比数据增强(准确率为0.9268 vs 0.9183)更为重要。Transformer在道路领域适用,因为它具有捕捉长距离关系的强大能力。第二个重要发现是,通过定制画廊,类似于人脸识别的框架可以快速识别不同的损坏类型。基于ViT(Visual Transformer)和MAE,本研究设计了一种新颖的方法来检测异常的路面部分。
- 相关推荐
- 热点推荐
- 解码器
- 编码器
- 人脸识别
- 计算机视觉
- Transformer
-
使用MATLAB进行无监督学习2025-05-16 1748
-
深度学习中的无监督学习方法综述2024-07-09 3266
-
适用于任意数据模态的自监督学习数据增强技术2023-09-04 2004
-
自监督学习的一些思考2022-01-26 614
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5648
-
如何用卷积神经网络方法去解决机器监督学习下面的分类问题?2021-06-16 3016
-
基于人工智能的自监督学习详解2021-03-30 7143
-
半监督学习:比监督学习做的更好2020-12-08 2303
-
为什么半监督学习是机器学习的未来?2020-11-27 4790
-
自监督学习与Transformer相关论文2020-11-02 3462
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6822
-
基于半监督学习框架的识别算法2018-01-21 1081
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 1048
全部0条评论

快来发表一下你的评论吧 !
