

选择处理器IP内核时需要考虑哪些
处理器/DSP
描述
作者:罗迪·厄克哈特(Roddy Urquhart)
大多数集成电路包括至少一个处理器内核和一些嵌入式软件。对于更复杂的片上系统 (SoC),可能有运行主软件和操作系统的应用程序处理器以及多个专门的子系统处理通信、安全性和传感器等功能。处理要求差别很大,有多种处理器 IP 内核可供选择。处理器 IP 供应商通常通过显示 PPA 数字(性能、 功耗和面积)相互竞争,但此类指标需要上下文信息,并且可能具有误导性。 那么, 设计人员在选择处理器 IP 内核时需要考虑哪些事项呢?
指令集架构 (ISA)
选择处理器最重要的考虑因素之一是指令集架构。30年前,许多集成设备制造商拥有自己的微控制器架构,市场被许多指令集架构分割。 然而 ,在当时 ,电脑市场由X86架构主导,X86不但击败了所有挑战产品 ,而且开发了大量的应用软件。
随着 20 世纪 90 年代处理器 IP 公司的出现,越来越多的半导体公司采用第三方处理器IP, Arm 成为手机和嵌入式的主导架构。这导致许多公司开发的产品具有与竞争产品相同的处理器内核,这限制了芯片产品的差异化。然而,随着Arm ISA的广泛使用,一个令人印象深刻的软件生态系统被开发出来。
数十年来,Arm一直被视为独立于半导体公司之外,提供某种“瑞士中立性”。软银公司(SoftBank)的收购破坏了这种中立性,这意味着Arm不再独立。这一点因Arm和Arm中国之间的紧张关系而加剧。如果Nvidia的收购通过,Arm将由持牌人拥有,完全失去任何中立的假象。许多半导体公司会因为竞争对手半导体公司的关键技术而感到不安。
在选择 ISA 时,您需要考虑许多事项。其中三项最重要,包括:
a)复杂性
b)软件生态系统
c)开放和中立
多年来,人们在增加ISA复杂性和减少ISA复杂性方面都做出了努力。坎皮纳斯大学的一项研究表明,在1986年至2013年之间,X86架构增长了3倍多。Arm 的 ISA 也发生了类似的增长。
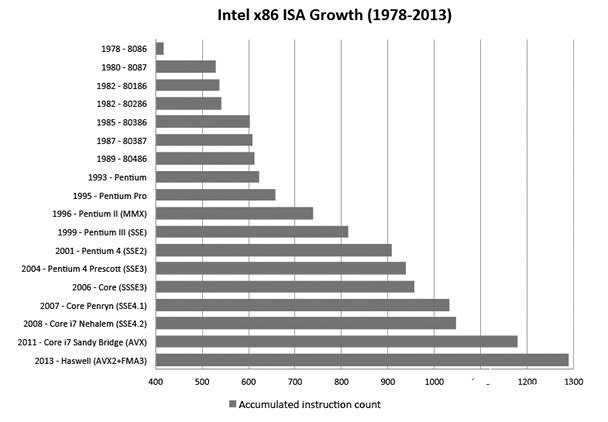
来源 - ISA Aging: A Case Study(《指令集架构老化:一项案例研究》),坎皮纳斯大学
相反,加州大学伯克利分校的 RISC 项目始于 1980 年,当时只使用了 32 条指令,但利用流水线设计和寄存器窗口实现性能。这个概念被太阳微系统公司商业化为SPARC。1981 年,斯坦福大学 MIPS 项目开发了一个小型 ISA,包含 16 位和 32 位指令的组合。
最近,加州大学伯克利分校的克尔斯特·阿萨诺维奇(Krste Asanović)开始了“3个月项目(3-month project)”,目的是开发一个干净利落的 ISA。这样做是因为专有 ISA 具有局限性,包括:
•专利保护 – 成本
•ISA 所有权与处理器设计之间的联系 – 单一供应商
•许多 ISA 的复杂性 – 通常不需要
•ISA 可能会随着其拥有公司而消亡 – 风险会随时间而变
这成为开放的 RISC-V ISA 标准。
RISC-V 的一个关键特征是它不是通用的 ISA。它认识到不同的应用需要不同程度的 ISA 复杂性。其中有一个非常小的基本指令集(只有 47 个指令的 32 位处理器),然后是一系列可根据需要使用的可选标准扩展。最后,还有用于创建非标准自定义指令的预配。

与专有商业 ISA 不同,RISC-V 使您能够将 ISA 与其设计需求相匹配。 例如,来自 Arm 的高端 Cortex-A 处理器将具有 800 多个指令,但它们都是必需的吗?使用 RISC-V 时,您可使用基本 ISA 加上具体所需的扩展,如 [G] 和 [P]。
软件的可用性是一个关键的考虑因素。某些软件仅在有限数量的 ISA 上可用,例如,安卓到目前为止仅移植到 Arm 和 MIPS。对于嵌入式软件 ,许多软件都有源代码,因此可以移植到几乎任何 ISA,而有些有二进制代码。对于Arm来说,二进制形式的软件有很多选择,但对于其他专有的 ISA,选择范围小得多。
使用 RISC-V,如果将嵌入式软件编译到基本指令集或标准扩展(如 RV32IMC)的通用组合,那么不管目标处理器是什么,它都可以轻松以二进制形式交付。
最后,考虑 ISA 的开放性很有用。专有架构通常与单个公司联系在一起,因此依赖于该公司的运行状况和生存能力。如果Arm和MIPS由半导体公司所有,其他开发集成电路的公司就不再认为它们是中立的。
RISC-V 开放 ISA 由独立的 RISC-V 国际组织所有,而不是由单个公司拥有。因此,因此,即使提供RISC-V处理器IP的公司资不抵债,也可以选择其他RISC-V内核供应商。投资针对 RISC-V 内核的软件是一种低风险选择。
性能
看看任何处理器 IP,您会发现其供应商强调 PPA(性能、功率和面积)数字。从理论上讲,它们应为比较不同的处理器IP内核提供一个公平的竞争环境,但实际上 情况更为复杂。 让我们考虑一下什么是“性能”。
首先要考虑的是,您关心性能的哪些方面?您更关心所需的绝对吞吐量(每秒性能),还是更关心每 MHz 的性能?在机器视觉等持续运行且需要使用复杂算法的应用中,您很可能会关心绝对吞吐量。但是,如果您有一个低占空比的无线传感器节点,当节点唤醒时,您将希望它在尽可能少的时钟周期内处于活动状态。这意味着您将关心每 MHz 实现的计算量。
大约 40 年前,计算机以MIPS(每秒数百万条指令)为基础进行比较,但问题是——什么是“指令”? 各种指令在复杂性和架构上有很大的不同,因此,在CISC处理器中的一个操作通常比在RISC处理器中需要的周期更少。MIPS 只有在将产品与类似体系结构进行比较时才有所帮助,有些人称之为“毫无意义的性能指数”!
另一个要考虑的事项是您最关心的计算类型。这是整数操作吗?如果是,是哪些操作?还是表示浮点计算?在过去,MFLOPS(每秒百万个浮点操作)是一种受欢迎的衡量标准。但同样,什么是“操作”?
如今,综合基准已普遍用于处理器 IP 内核。它们具有以下特征:
a)它们相对较小,便于携带,
b)它们代表常用的相关应用,
c)它们透明且可重复,
d)它们可以公平地应用于一系列处理器,
e)它们将基准结果表示为单个数字。
过去 36 年来流行的基准是 Dhrystone 基准。其名称取自与一度流行的“惠斯登基准”(Whetstone benchmark)相比较的文字游戏。惠斯登基准通专注于浮点操作,而 Dhrystone 则专注于整数和字符串操作。Dhrystone 基准结果通常被引用为 DMIPS(Dhrystone 分数除以名义上的 1MIPS 机器的分数)。该基准测试一直受到批评,因为现代编译器可以优化部分工作,这意味着它部分测试的是编译器,而不是处理器性能。
对于浮点,Whetstone 目前很少使用, 有时也会使用 LINPACK 等替代方法。LINPACK 涉及使用浮点数对矩阵进行 LU 分解。结果用 MFLOPS 表示。
自 2009 年以来,另一个流行的嵌入式应用综合基准是 EEMBC 的 CoreMark® ,CoreMark®旨在开展代表嵌入式整数处理需求的操作。其中包括列表处理、矩阵操作、有限状态机和 CRC。
由加州大学伯克利分校的戴夫·帕特森(Dave Patterson)领导的一个小组批评了所有的合成基准,转而建议Embench作为使用真实程序的替代方案。随着该行业的进一步发展,时间会告诉我们这种做法是否会赢得业内的关注,但计划采用浮点基准令人鼓舞。
正如您所看到的,那里有许多不同的基准测试系统,每个系统都适合度量略有不同的性能类型。那么,在为项目选择处理器IP时,如何评估性能呢? 如果您的嵌入式软件具有与综合基准类似的操作,则该基准可能会快速简单地为您提供有用的初始指导。但是,此类基准通常以 MHz 报价,例如 CoreMark/MHz。如果您在按周期寻找良好效果,每兆赫数字值通常是低功率应用的一个好指标。但是,如果您正在寻找高绝对性能,这可能是误导。相反,您应该考虑说,按您的目标时钟频率可实现的 CoreMarks。
如果您的主要问题是浮点性能,请记住 DMIPS 和 CoreMark 是整数基准。您最好根据浮点基准(如Whetstone或 LINPACK)比较内核; 然而,这些基准相当旧。
最后,强烈建议将时间投入在处理器内核上运行逼真的软件,以此评估内核是否为您提供所需的性能。即使综合基准测试给了你快速的指示,也没有什么可以替代使用真正的应用软件。如果您正在查看 RISC-V,那么可了解计算瓶颈在哪里的分析软件也会评估添加自定义指令是否可以提高性能。
复杂性
处理器内核越复杂,面积和功耗越大 。但是,增加复杂性并不是单一维度,因为处理器可能在不同的方面更为复杂。在选择处理器 IP 内核时,为项目选择正确的复杂类型非常重要。
思考复杂性的方法包括:
-字长
-执行单元
-特权/保护
-虚拟内存
-安全功能
通常,字长越小,内核越小,功率越低,但情况并非总是如此。8 位内核(如 8051)在栅极数上与最小的 32 位内核相当,但功耗通常更差。8 位内核需要更多的内存访问,每个时钟周期的计算更少,需要的周期更多,因此需要更多的动态功率来完成计算。
处理器内核在执行单元的复杂性方面差异很大。最简单的是基本的单个ALU(算术逻辑运算单元),需要通过简单的指令实现许多常见操作,例如使用 shift and add算法来实现乘法。因此,内核具有硬件乘法器和除法器是司空见惯的事。在需要良好的浮点性能时,添加硬件浮点单元将显著提高性能。此选项可用于 Codasip 的 Bk3 和 Bk5 RISC-V 内核,但代价是内核尺寸约扩大为两倍。
到目前为止,我们已经假设了一次执行一个指令的标量处理单元和一个计算线程。Superscalar 体系结构具有指令级并行性,能够获取多个指令并将它们发送到不同的执行单元。例如,西部数据 EH1 和 EH2 SweRV 内核有两个执行单元。处理一个线程的双发射内核处理理论上可以使单发射内核的性能翻倍。
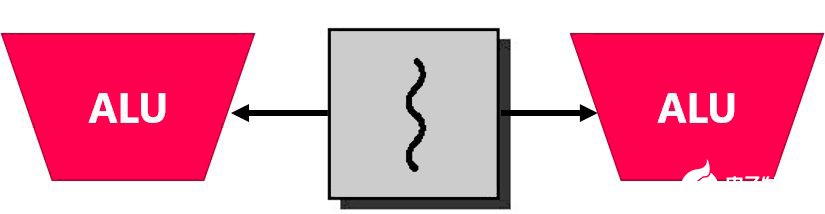
但是,线程可能会使两个执行单元暂时处于非活动状态。如果存在两个硬件线程(harts),如果一个线程停止,另一个线程可以继续执行。
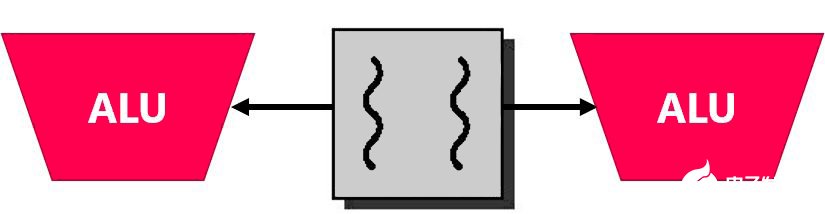
另一个复杂的领域是特权模式 - 通常模式越多,核心逻辑越复杂。许多嵌入式应用程序在机器模式下运行,这意味着其代码具有对内核的完全访问权限,就像 Linux 中的根权限一样。必须完全信任此类代码,才能避免负面后果。在更复杂的应用中,可能会提供一系列特权,如机器、主管和用户。普通应用将在用户模式下运行,保护量最大,某些需要更大权限的软件将使用主管模式。Linux 需要所有三种模式。 RISC-V 规范还定义了物理内存保护 (PMP),以此防止特权较低的模式访问某些内存空间。
虚拟内存还需要额外的处理器资源,如内存管理单元 (MMU) 和转译后备缓冲器 (TLB)来处理将虚拟内存地址转换为物理地址。这会在不提高处理器吞吐量的情况下,在面积和功耗方面带来额外的成本。然而,虚拟内存对于使用丰富的操作系统(如 Linux)很有必要,这些操作系统能够使用更复杂的软件。
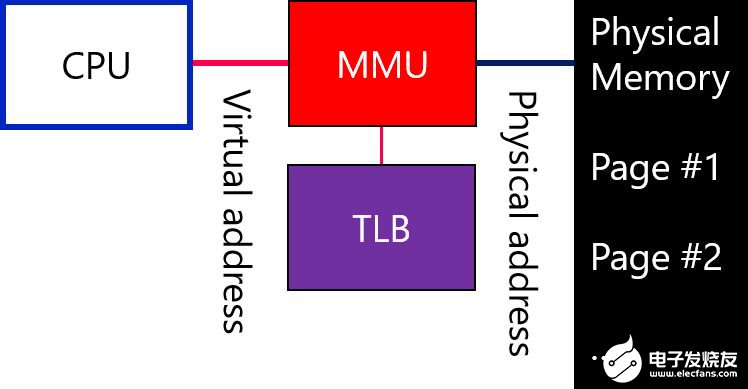
最后, 硬件安全功能增加了逻辑。这可能以向存储器提供电子加密/解密的形式,提供纠错编码和篡改检测块功能。
因此,选择处理器内核时,要弄清您需要什么样的执行单元、内存管理 、特权和安全。这种组合将决定内核的复杂性。
操作系统
对于每个嵌入式产品,软件开发人员需要考虑是否需要操作系统;如果是这样,操作系统的类型千差万别,包括内存占用很小的实时操作系统,以及具有丰富特性的通用操作系统(如Linux)。
为您的产品选择适当的操作系统类型,并因此确定嵌入式处理器所需的功能,很大程度上取决于您是否面临硬性实时要求。安全关键系统和工业系统(如防锁制动系统或电机控制)将具有最大硬响应时间。在该频谱的另一端,如果平均性能足够,则音频或游戏设备等消费类系统可能能够容忍缓冲。据说这样的系统有软实时要求。
硬实时需求可以通过编写直接控制底层硬件的所谓裸机软件来实现。有时,处理器资源非常有限、软件非常简单和/或实时要求非常严格,引入进一步的抽象层会使满足这些硬实时需求变得复杂时,这时通常会使用裸机编程。这种方法的缺点是,这样的裸机软件需要作为一个单一的任务(加上中断例程)来编写,这使得程序员很难在其复杂性增长时维护软件。
在处理更复杂的嵌入式软件时,使用实时操作系统 (RTOS) 通常比较有利。它允许程序员将嵌入式软件拆分为多个线程,这些线程的执行由RTOS的小而低开销的“内核”管理。使用多线程范式使开发人员能够创建和维护更复杂的软件,同时仍然允许足够的响应。RTOS 通常使用分配给单个线程的“优先级”概念进行操作。然后,RTOS 可以“抢占”(暂时停止)优先级较低的线程,这样做有利于那些具有较高优先级的线程,以此满足所需的实时限制。在采用复杂的库或协议堆栈(如 TCP/IP 或蓝牙)时,通常需要使用 RTOS,因为这种第三方软件通常已经包含多个线程。如今,许多开源和商业许可的RTOSes可供选择。
对于一个简单的RTOS(例如FreeRTOS或Zephyr)来说,嵌入式处理器的要求的确不高。拥有只配置机器模式 (M) 和定时器外设的 RISC-V 处理器就足够了。因此,这些 RTOS 可以在任何 Codasip RISC-V 内核或西部数据 SweRV 内核上运行。但是,由于机器模式对具有相关风险的所有内存和外围设备提供不受限访问权限,因此需要严密的软件开发。通过专门的 RTOS(例如为功能安全(如 SAFERTOS)或安全开发的 RTOS,可以提供额外的保护。
如果处理器内核同时支持机器 (M) 和用户 (U) 权限模式,并且具有物理内存保护 (PMP),则有可能在受信任代码(具有不受限访问权限)和其他应用程序代码之间建立隔离。使用 PMP,受信任的代码为应用程序代码的每个部分设置规则,并规定允许访问内存(或外围设备 )的哪些部分。例如,PMP 可用于防止第三方代码干扰应用程序其余部分的数据,或检测堆栈溢出。因此,使用 PMP 可提高系统的安全性,但代价是需要额外的硬件来支持它。
对于需要更高级用户界面、复杂 I/O 和网络(如机顶盒或娱乐系统)的应用程序,RTOS 可能过于简单化。如果有复杂的计算、对完整的进程隔离和多任务处理的要求、文件系统和存储支持,或者通过设备驱动程序将应用程序代码与硬件完全分离,也同样适用。此类系统通常具有软实时要求,且最好由通用丰富的操作系统(如 Linux)提供。如前所述,Linux 需要多种 RISC-V 特权模式(计算机、主管和用户模式(M、S、U))以及用于虚拟到物理地址转换的内存管理单元 (MMU)。此外,与简单的 RTOS 相比,此类系统的内存占用量要大得多。
最后,对于需要硬实时响应和 Linux 等丰富操作系统功能的嵌入式系统,通常使用两个通信处理器子系统进行设计,一个支持 RTOS,另一个运行 Linux。
子系统硅面积
设计中任何部分的面积都会影响硅成本和功耗。在处理器IP供应商的PPA编号中简单地遵循“A”可能会引起误解。处理器从来都不是孤立的,它是子系统的一部分,另外还包括指令存储器、数据存储器和外设。在大多数情况下,指令内存将占主导地位,而处理器面积则不那么重要。
指令内存的大小将受目标指令集、编译器和使用的编译器切换的影响。在 RISC-V 的情况下,选择可选的标准扩展和自定义扩展可以极大地影响代码大小。
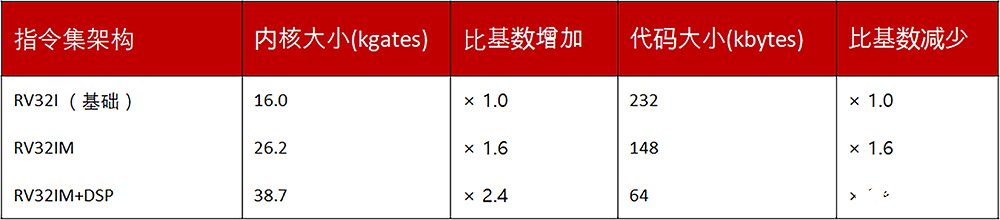
资料来源:《为物联网应用实施 RISC-V》,Dan Ganousis & Vijay Subramaniam,设计自动化会议 2017
为了说明这一点,上表显示了向内核和代码大小添加扩展的效果。在此示例中,Microsemi 使用 Codasip RISC-V Bk3 内核实现音频处理应用。从32位基指令集开始,它们的编码和循环计数高得令人无法接受。通过添加乘法 [M] 扩展实现了一些改进,但突破是使用自定义 DSP 指令。这使得编码大小减少了3.6倍,但与基础内核相比,以增加2.4倍的核心尺寸为代价。在指令内存占主导地位的情况下,这是一个很好的权衡; 此外,性能目标很容易实现。
对于典型的供应商 PPA 数据,通常使用一组复杂的编译器交换机引用一些综合基准(如 CoreMark/MHz)。但在实践中,嵌入式软件可能会使用常见的交换机(如-Os或-O3)进行编译。
请考虑利用通用的 GCC 编译器使用不同的交换机编译 CoreMark 基准。在这种情况下,目标是具有 3 阶段流水线的 Codasip RV32IMC RISC-V 内核。下图显示了不同编译器设置的 CoreMark/MHzcodesize和代码大小度量值。最后一个示例是典型的供应商性能数据,其中许多交换机用于 CoreMark (CM = “-O3 -flto -fno-common -funroll-loops -finline-functions -falign-functions=16 -falign-jumps=8 -falign-loops=8 -finline-limit=1000 -fno-if-conversion2 -fselective-scheduling -fno-tree-dominator-opts -fno-reg-struct-return -fno-rename-registers --param case-values-threshold=8 -fno-crossjumping -freorder-blocks-and-partition -fno-tree-loop-if-convert -fno-tree-sink -fgcse-sm -fgcse-las -fno-strict-overflow”)。
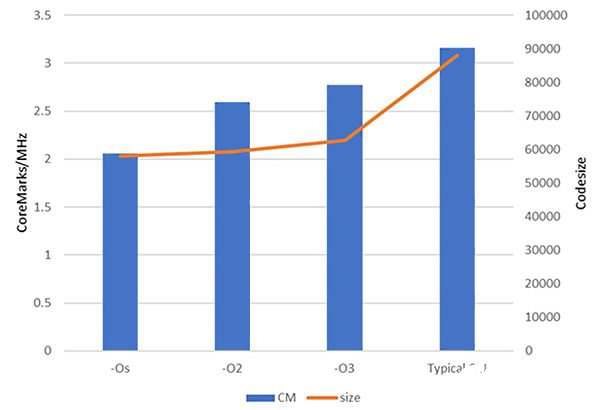
在此示例中,CoreMark/MHz 分数随着交换机从左到右的变化而增长。但是,有趣的是,最复杂的一组交换机在“-O3”上增加了40%的编码大小,而性能只提高了14%。
并不是每个示例都会这样运行,但编译器交换机会影响性能和代码大小。重要的是要实事求是地了解要使用的编译器交换机,并确保任何性能基准数据的交换机与用于评估代码大小的交换机相匹配。
许可模式
每个人都熟悉传统处理器 IP 供应商(如 Arm、Cadence 和 Synopsys) 的商业许可。但是,在讨论 RISC-V 开放指令集架构 (ISA) 时,普遍存在着术语上的混淆,即通常被描述为“开源”的RISC-V。有些人甚至指责商业RISC-V IP的供应商,如Codasip或Andes不符合RISC-V的精神。但现实是什么?
让我们简要地看一下定义。像C、Verilog或HTTP这样的开放标准是由独立组织维护的文档定义的。因此,C 由 ISO 维护,Verilog 由 IEEE 维护,HTTP 由 IETF 维护。这些组织使用一套公正的规则维护技术标准。这样的开放标准通常可自由访问。
使用开源, 软件包的源代码或硬件块的硬件描述语言源可使用许可证提供。开源许可证从限制性许可证(如非盈利版权许可证)到许可授权(如 Apache)各不相同。开源许可证定义使用、研究、修改和分发代码的权利。非盈利版权许可证将要求任何修改都是开源的,而许可授权则不开放。
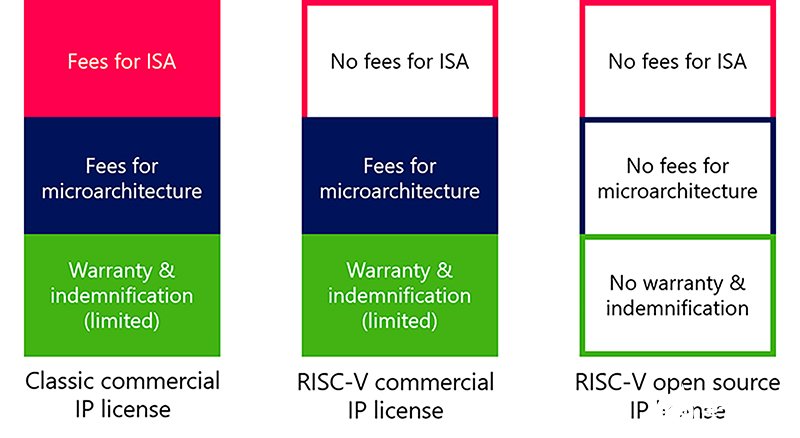
RISC-V是一个开放标准,ISA 不定义任何微体系结构或业务模型。因此,RISC-V 微体系结构可以作为商业 IP 许可证或作为开源许可证获得许可。没有规定。
如果我们想到一个经典的商业处理器IP许可证,您一般支付:
-使用供应商的 ISA 的权利,
-使用供应商的微观体系结构的权利,
-保修,
-供应商承诺修复错误,
-赔偿。
在实践中,保修通常有时限,赔偿有限。但是,对于被许可方,如果发现错误,尤其在日程紧张时发现的错误有价值,供应商有一些复设计的承诺。如果被许可人被指控专利侵权,知识产权赔偿意味着供应商将代表被许可人为指控辩护或解决。
经典 IP 供应商小心翼翼地保护自己的 ISA 以及他们的微观体系结构。普通许可证将 ISA 的使用与微体系结构捆绑在一起,并且没有修改可交付结果的权利。此类供应商很少提供架构许可证,允许被许可方在自己的微体系结构中使用ISA,但是这样的许可要求的费用很高。RISC-V非常具有破坏性的一个原因是,免费开放的ISA是最有价值的可交付产品之一,而且不需要支付许可费。
鉴于 RISC-V 没有规定微体系结构或如何获得许可,因此既有商业许可,也有开源的 RISC-V IP 内核。使用开源许可证时,您无需为微型体系结构支付许可证费用,但您也无法获得商业许可证的所有好处。通常,交付物没有担保,并要接受“现状”。同样,商业许可证也不存在赔偿。如果发现错误,则许可证方或开源社区需要修复它们。
对于商业许可的 RISC-V 内核,只有费用与微体系结构相关,因为 RISC-V ISA 是免费许可的。有了此许可证,您可以获得通常与商业许可证相关的保修、赔偿和错误修复承诺。
那么,RISC-V 的哪个选择正确呢?商业许可证和开源许可证都有优点和缺点。您需要权衡最适合您的设计项目。
在Codasip, 我们提供商业RISC-V IP许可证,并支持采用开源SweRV内核。过去,商业许可证和开源许可证一直被视为激烈的竞争对手。然而, 在软件界,微软等公司已经接受了这两种模式。Microsoft 提供商业许可证,支持开源项目,并且具有基于云的业务模型。Codasip 深信,商业和开源 RISC-V 许可证可以共存并相互补充。
结论
选择处理器是一项复杂的任务,需要明确评估您的底层需求。对诸如供应商PPA数据或基准测试之类的度量进行肤浅的评估可能会产生误导,并最终导致对处理器的次优选择。
出发点应该是清楚地了解 SoC 项目需要什么。您是希望打开 ISA 还是由单个公司控制?您是否关心绝对吞吐量或每个时钟周期的计算量?您面临的是硬实时需求,还是需要一个丰富的操作系统? 实现计划性能需要哪些计算单位?您需要在处理器内核上运行什么软件, ISA 和编译器怎样组合会让您实现所需的整个子系统领域?最后,比起避免许可证费, 您更关心获得保修, 承诺修复潜在的错误和赔偿?
审核编辑:黄飞
-
盛显科技:选择投影融合处理器时,需要考虑哪些方面?2024-08-08 1041
-
选择处理器的几个关键因素2023-12-15 2045
-
如何选择合适的处理器内核2023-01-10 1156
-
如何考虑选择微处理器(MPU)或者单片机(MCU)2022-02-18 3138
-
如何选择处理器的三个关键:工作频率(时钟速度)、缓存和内核数量2021-06-17 4728
-
选择处理器IP内核时应遵循哪些原则?2021-06-11 2112
-
选择DSP处理器ADSP-2115与TMS320C5x的考虑因素2021-05-24 844
-
AN-400:选择DSP处理器的考虑因素--为什么购买ADSP-2181?2021-05-10 882
-
微处理器或单片机哪个才是更好的选择?2021-01-28 1683
-
嵌入式微处理器如何选择2020-05-20 3580
-
ARM处理器内核的详细资料概述2019-10-14 1840
-
选择处理器过程中需要考虑哪些因素?2019-09-03 3160
-
一颗好的处理器需要什么样的好IP?2015-10-29 6106
-
选择处理器需要考虑哪些问题2011-05-11 1287
全部0条评论

快来发表一下你的评论吧 !
