

何恺明新作RCG:无自条件图像生成新SOTA!与MIT首次合作!
描述
大佬何恺明还未正式入职MIT,但和MIT的第一篇合作研究已经出来了:
他和MIT师生一起开发了一个自条件图像生成框架,名叫RCG(代码已开源)。
这个框架结构非常简单但效果拔群,直接在ImageNet-1K数据集上实现了无条件图像生成的新SOTA。
它生成的图像不需要任何人类注释(也就是提示词、类标签什么的),就能做到既保真又具有多样性。

这样的它不仅显著提高了无条件图像生成的水平,还能跟当前最好的条件生成方法一较高下。
用何恺明团队自己的话来说:
有条件和无条件生成任务之间长期存在的性能差距,终于在这一刻被弥补了。
那么,它究竟是如何做到的呢?
类似自监督学习的自条件生成
首先,所谓无条件生成,就是模型在没有输入信号帮助的情况下直接捕获数据分布生成内容。
这种方式比较难以训练,所以一直和条件生成有很大性能差距——就像无监督学习比不过监督学习一样。
但就像自监督学习的出现,扭转了这一局面一样。
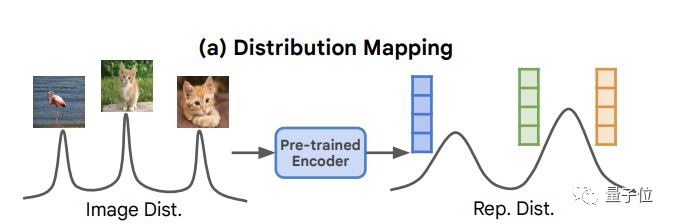
在无条件图像生成领域,也有一个类似于自监督学习概念的自条件生成方法。
相比传统的无条件生成简单地将噪声分布映射到图像分布,这种方法主要将像素生成过程设置在从数据分布本身导出的表示分布上。
它有望超越条件图像生成,并推动诸如分子设计或药物发现这种不需要人类给注释的应用往前发展(这也是为什么条件生成图像发展得这么好,我们还要重视无条件生成)。
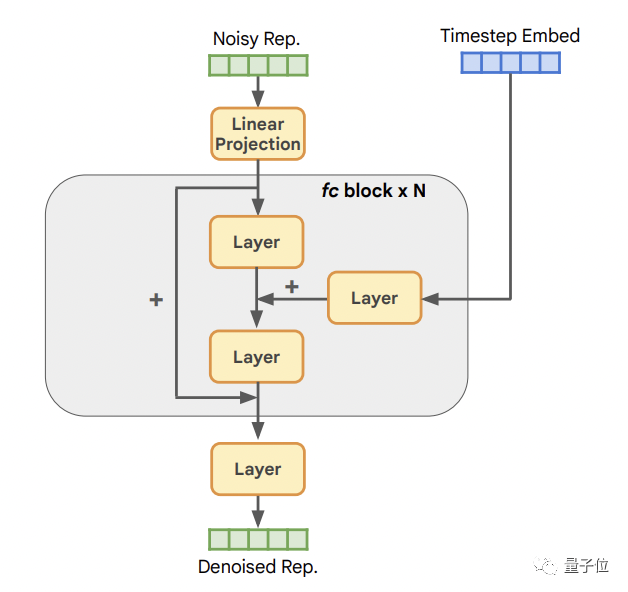
现在,基于这个自条件生成概念,何恺明团队首先开发了一个表示扩散模型RDM。
它主要用于生成低维自监督图像表示,方法是通过自监督图像编码器从图像中截取:
它的核心架构如下:
首先是输入层,它负责将表征投射到隐藏维度C,接着是N个全连接块,最后是一个输出层,负责把隐藏层的潜在特征重新投射(转换)到原始表征维度。
其中每一层都包含一个LayerNorm层、一个SiLU层以及一个线性层。
这样的RDM具有两个优点:
一是多样性强,二是计算开销小。
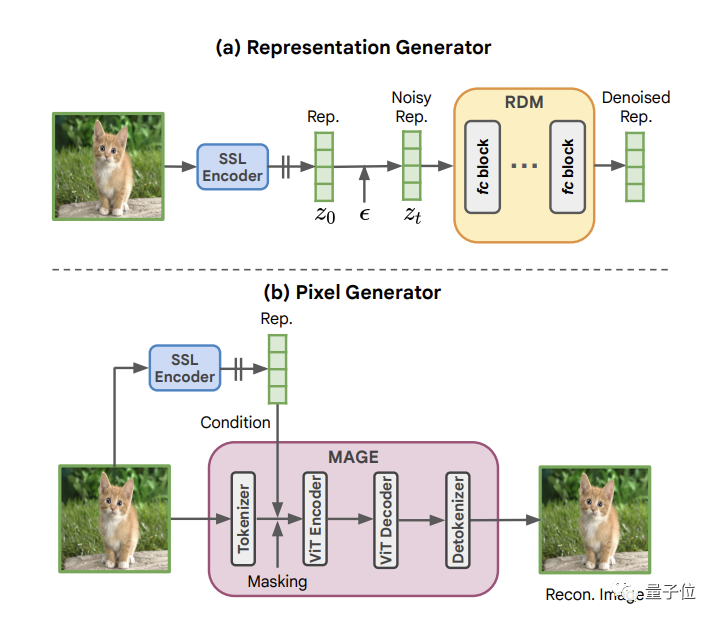
接着,利用RDM,团队就提出了今天的主角:表示条件图像生成架构RCG。
它是一个简单的自条件生成框架,由三个组件组成:
一个是SSL图像编码器,用于将图像分布转换为紧凑的表示分布。
一个是RDM,用于对该分布进行建模和采样。
最后是一个像素生成器MAGE,用于根据表示来处理图像像。
MAGE的工作方式主要是向token化的图像中添加随机掩码,并要求网络以从同一图像中提取的表示为条件来重建丢失的token。
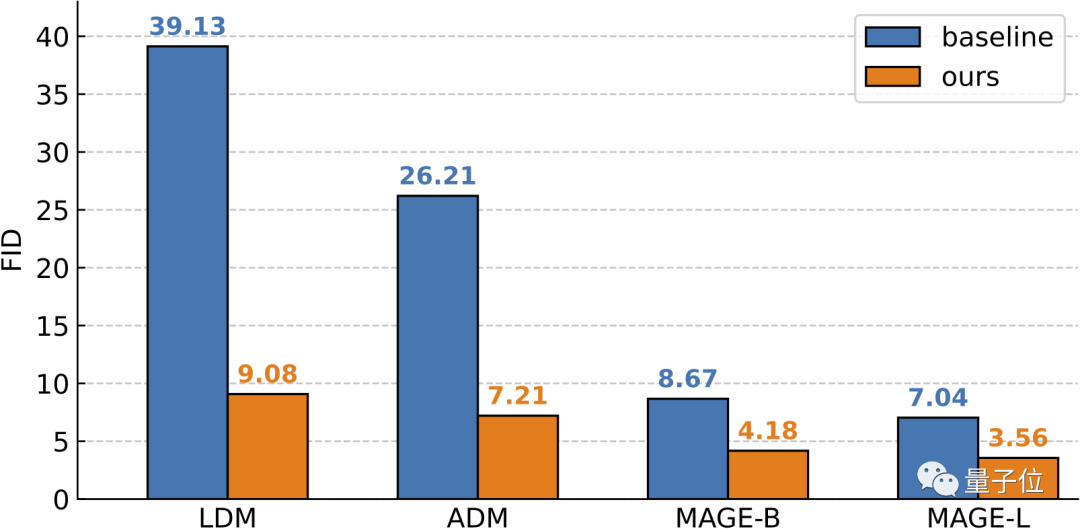
最终,测试表明,这个自条件生成框架虽结构简单但效果非凡:
在ImageNet 256×256上,RCG实现了3.56的FID和186.9的IS(Inception Score)得分。
相比之下,在它之前最厉害的无条件生成方法FID分数为7.04,IS得分为123.5。
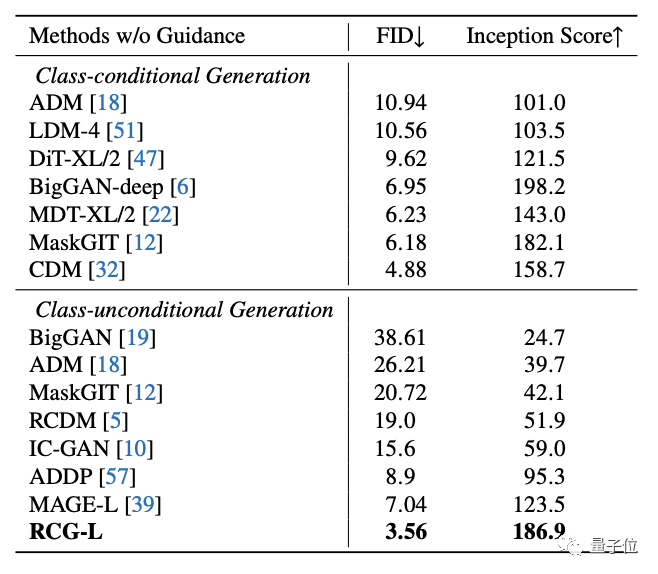
以及,相比条件生成,RCG也丝毫不逊色,可以达到相当甚至超过该领域基准模型的水平。
最后,在无分类器引导的情况下,RCG的成绩还能进一步提高到3.31(FID)和253.4(IS)。
团队表示:
这些结果表明,自条件图像生成模型拥有巨大潜力,可能预示这一领域新时代的到来。
团队介绍
本文一共三位作者:

代码:https://github.com/LTH14/rcg
论文:https://arxiv.org/abs/2312.03701
一作是MIT博士生黎天鸿,本科毕业于清华姚班,研究方向为跨模态集成传感技术。
他的主页很有意思,还专门放了一个菜谱合集——做研究和做饭是他最热爱的两件事。
另一位作者是MIT电气工程与计算机科学系(EECS)教授、MIT无线网络和移动计算中心主任Dina Katabi,她是今年斯隆奖的获得者,并已当选美国国家科学院院士。
最后,通讯作者为何恺明,他将在明年正式回归学界、离开Meta加入MIT电气工程和计算机科学系,与Dina Katabi成为同事。
-
NB81是否支持OneNet SOTA功能?应该如何激活SOTA?2024-06-04 620
-
最新作品2014-04-10 3536
-
labview RT中利用MIT工具包调用simulink生成的模型dll文件的方法2020-07-21 3902
-
基于暗原色先验的单幅图像去雾算法2015-11-19 673
-
探讨条件GAN在图像生成中的应用2018-01-11 12791
-
FAIR何恺明团队最新论文提出“全景FPN”,聚焦于图像的全景分割任务2019-01-11 7391
-
何恺明等人再出重磅新作:分割任务的TensorMask框架2019-04-04 5083
-
基于谱归一化条件生成对抗网络的图像修复算法2021-03-12 1202
-
一种具有语义区域风格约束的图像生成框架2021-04-13 1057
-
基于自注意力机制的条件生成对抗网络模型2021-04-20 1735
-
谷歌新作Muse:通过掩码生成Transformer进行文本到图像生成2023-01-09 1946
-
基于扩散模型的图像生成过程2023-07-17 4714
-
Nvidia AI剑走偏锋;MIT水泥破局出奇2023-08-02 1126
-
人工智能SOTA什么意思2023-08-22 27614
-
Mamba入局图像复原,达成新SOTA2024-12-30 2392
全部0条评论

快来发表一下你的评论吧 !
