

SuperPoint语义 SLAM深度学习用于特征提取
描述
1. 概况
作者的写作思路很清晰,把各个技术点这么做的原因写的很清楚,全文共三篇,可以看清作者在使用深度学习进行位姿估计这一方法上的思路演变过程,为了把这一脉络理清楚,我们按照时间顺序对这三篇文章分别解读,分别是:
1)Deep Image Homography Estimation
2)Toward Geometric Deep SLAM
3)SuperPoint: Self-Supervised Interest Point Detection and Description
本期,我们首先对Deep Image Homography Estimation进行解读。
2. 第一篇
Deep Image Homography Estimation
矿视成果
参考R TALK | 图像对齐及其应用(https://zhuanlan.zhihu.com/p/99758095Deep)
1.1. 概述
Deep Image Homography Estimation 是通过端到端的方式估计一对图像的单应矩阵。训练数据集是从MS-COCO上选取图片,然后把这张图片进行单应性变换得到图象对的方式生成的。为了得到矩阵变换的置信度(比如slam中设置方差需要这些东西),作者把网络分成两部分,分别对应两种输出,一种输出单一变换结果,另一种输出多个可能的变换结果,并给出每种变换结果的置信度,实际使用时,选择置信度最高的那个。
1.2. 算法流程
1.2.1 基础知识
本篇文章所提出的方法输出的是单应性矩阵,所谓单应性矩阵,就是图象中的目标点认为是在一个平面上,相应的,如果不在一个平面上则被成为基础矩阵。
在实际的slam应用中,单应矩阵在以下这三种情况时需要用到:
相机只有旋转而无平移的时候,两视图的对极约束不成立,基础矩阵F为零矩阵,这时候需要使用单应矩阵H场景中的点都在同一个平面上,可以使用单应矩阵计算像点的匹配点。
相机的平移距离相对于场景的深度较小的时候,也可以使用单应矩阵H。
在大家熟悉的ORB-SLAM中初始化的时候,就是单应矩阵和基础矩阵同时估计,然后根据两种方法估计出的结果计算重投影误差,选择重投影误差最小的那个作为初始化结果。
1.2.2 建立模型
一个单应矩阵其实就是一个3X3的矩阵,通过这个矩阵,可以把图像中的一个点,投影到对应的图像对上去,对应的公式为
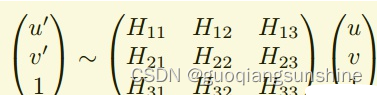
在这篇文章中,作者为了更好的训练模型和评估算法效果,采用了另外一种模型,来等效代替上面的公式。我们知道,一张图片进行单应性变换的时候,图像上的点的坐标会根据变换矩阵发生变化(如上式),那么反过来,如果我知道n个变换前后的点的坐标,那么这两张图片之间的变换矩阵便可以得到,在平面关系中,n为4,即至少知道四个点就可以。因此作者用四个点对应的变化量来建立一个新的模型,如下式所示
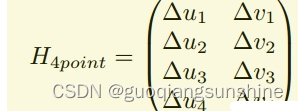
它和单应性矩阵具有一一对应的关系
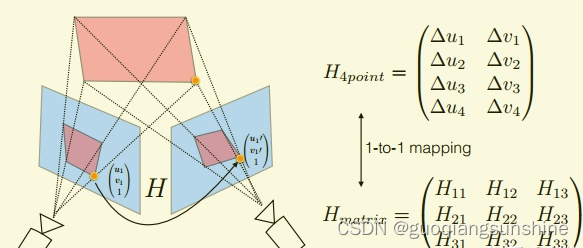
这样做的好处是,把图片对之间的矩阵关系,转换成了点和点之间的关系,在进行精度评估时,可以直接根据转换后的点的坐标与真实的坐标计算距离,作为误差评估指标,而且,还可以用于网络中损失函数的计算。
1.2.3 生成数据集
作者采用MS-COCO作为数据集,不过该数据集中没有图像对,也即没有单应矩阵的真值,这是没法进行训练的。因此作者根据数据集中原有图像,自动生成了图像对。具体方法如下图所示
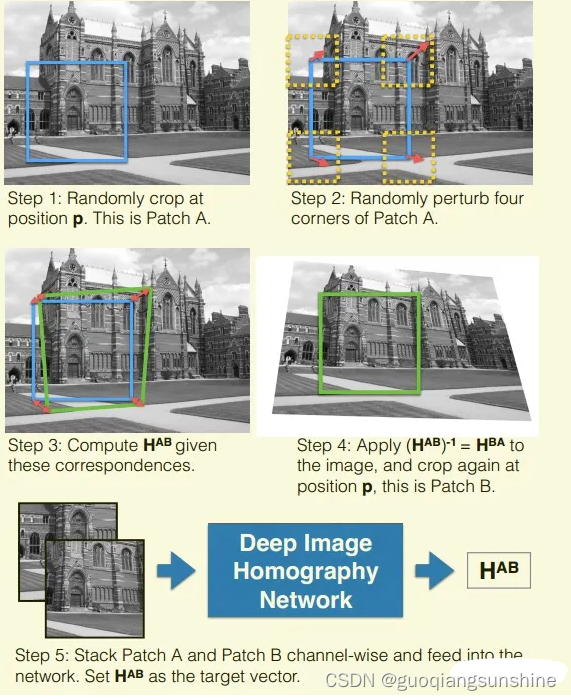
具体步骤为:
1.在图像中选取一个长方形区域,区域就可以用上面说的四个点的模型来表示;
2.把区域的四个点随机进行平移,这样就得到一个四边形,这两个四边形之间的单应矩阵也就是已知的;
3.把图像按照这个单应矩阵进行变换,并选取被四边形框住的区域;
4.这样1)中和3)中得到的图像就形成了一个已知真实单应矩阵的图像对。
1.2.4 设计网络结构
本文的网络结构如下图所示
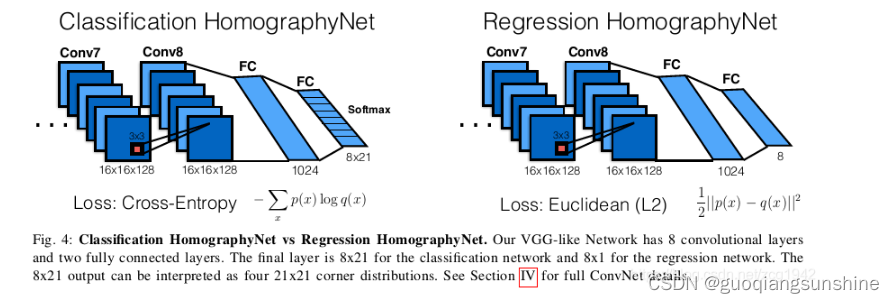
网络分成两部分,分别是Classification HomographyNet 和 Regression HomograhyNet,后者是直接输出8个量,这8个量自然就是四个点各自的x和y坐标值。但这样的缺点也很明显,就是不知道每个坐标值的置信度是多少,比如在slam中设置方差时就没有根据。因此Classification HomographyNet就是在Regression HomograhyNet的基础上,把输出端改成了8X21的输出向量,这里的8仍然是四个点各自的x和y坐标,这里的21是每个坐标值的可能值之一,并且给出了该值的概率,这样就可以定量分析置信度了。该网络所输出的置信度的可视化效果如下图所示

1.2.5 实验结果
实验结果的精度评测方法就是根据每个点的坐标按照单应矩阵进行转换后,和真实坐标进行L2距离测量,再把四个点的误差值取平均得到。作者把网络两部分的输出和ORB特征计算的结果分别进行了评测,对比结果如下:
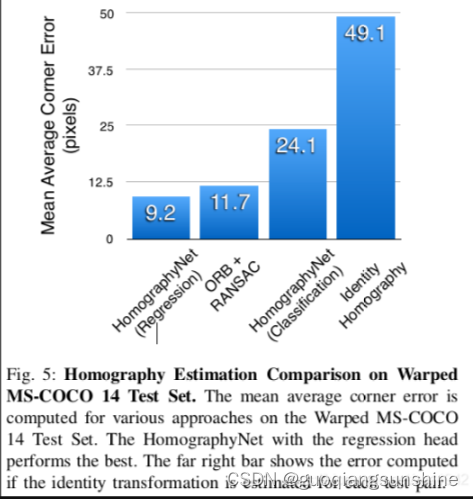
从这张表里看,并没有比ORB表现出明显的优势,但是作者展示了几张图片,每个图片里显示了矫正之后的方框对,从方框对中可以明显看出区别。左边是ORB方法的,右边是本文方法的。
1.3. 总结与思考
设计了一种端到端的单应矩阵的估计方法,采用提取定点的结构等效单应矩阵,基于这种结构设计了数据集产生方法和精度评测方法,最终的结果显示效果要明显高于ORB进行的提取。
可以看到回归的方法效果最好,但是分类的方法可以得到置信度,且可以可视化地纠正实验结果,在某些应用中是有优势的。
作者总结了这个系统的两个优势:
第一,速度快,借助英伟达的泰坦显卡,可以实现每秒处理300帧的图像。
第二,将计算机视觉中最基础的单应矩阵的估计问题转化为机器学习的问题,可以针对应用情景如使用SLAM的室内导航机器人做特定优化。
事实上,单应矩阵在图像拼接,ORB-SLAM算法和Augmented Reality(AR),相机标定中都有很重要的应用。这篇文章的三个作者都来自Magic Leap公司,一家做AR的公司,已经得到了Google和阿里巴巴等公司是十几亿美金的投资。
新的思考:
1)这种将深度学习用于解决传统方法中遇到的困难的设计模式值的我们思考与学习,这样可以充分的将诶和传统与深度学习的共同特点。
2)这种从图像中产生真值,然后在利用这些图像去估计矩阵的方式是由于过拟合导致效果好?
3)单应矩阵一般特征共面时使用,论文中最后对比效果所列的图片明显不是这种情况(展示数据可以理解为远视角场景),它之所以能对齐,是因为它用这个训练的,而ORB是根据真实的场景估计的,没有共面假设,对比实验设计的合理性。
-
基于卷积神经网络的双重特征提取方法2023-10-16 1952
-
模拟电路故障诊断中的特征提取方法2016-12-09 5435
-
HOOFR-SLAM的系统框架及其特征提取2021-12-21 1757
-
基于已知特征项和环境相关量的特征提取算法2009-04-18 939
-
故障特征提取的方法研究2006-03-11 1965
-
基于Gabor的特征提取算法在人脸识别中的应用2013-01-22 1380
-
峭度滤波器用于电机轴承早期故障特征提取_安国庆2017-01-07 982
-
Curvelet变换用于人脸特征提取与识别2017-11-30 6001
-
基于LBP的深度图像手势特征提取算法2017-12-11 1303
-
基于主成分分析方向深度梯度直方图的特征提取算法2017-12-26 1726
-
基于HTM架构的时空特征提取方法2018-01-17 1316
-
机器学习之特征提取 VS 特征选择2020-09-14 4998
-
计算机视觉中不同的特征提取方法对比2022-07-11 5215
-
为什么目前落地的主流SLAM技术很少用神经网络进行特征提取?2023-05-19 2055
-
深度解析深度学习下的语义SLAM2024-04-23 2362
全部0条评论

快来发表一下你的评论吧 !
