

模糊图像变高清:TPU-MLIR引领EDSR向MDSR的智能转换!
描述
模型介绍
EDSR模型,全称为enhanced deep super-resolution network(增强的深度学习超分辨率重建网络)。该模型可以对指定图片进行超分辨率操作,提高清晰度。
而MDSR是多尺度的超分模型,可以一次输出不同scale的图片,相比EDSR,可以在相同的性能下,减少很多的参数。
EDSR模型结构如下:
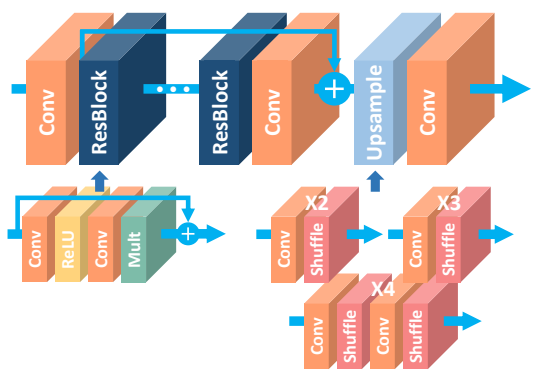
MDSR模型结构如下:
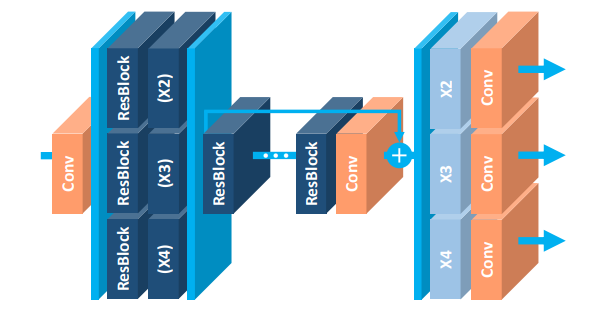
本期内容将会带领大家学习如何利用TPU-MLIR实现EDSR模型到MDSR模型的转换。
模型导出与转换
基本流程为将原项目与模型下载后导出为onnx模型。再利用TPU-MLIR工具将onnx模型转换为bmodel模型。
目录结构安排如下,其中dataset文件夹中是量化所用的DIV2K数据集,image文件夹下是测试图片,model文件夹中是待转换的onnx模型。
.
├── dataset
│ ├── x2
│ ├── x3
│ └── x4
├── image
└── model
├── EDSR_x2.onnx
├── EDSR_x3.onnx
├── EDSR_x4.onnx
├── MDSR_x2.onnx
├── MDSR_x3.onnx
└── MDSR_x4.onnx
以下命令均在TPU-MLIR的docker环境内进行。
进入EDSR-transform目录
设置参数
scale=4
size=100
echo scale=${scale} size=${size}
mkdir workspace_x${scale} && cd workspace_x${scale}
- 模型转换和量化
# 算子转换、图优化
model_transform.py \
--model_name EDSR_x${scale} \
--model_def ../model/EDSR_x${scale}.onnx \
--input_shapes [[1,3,${size},${size}]] \
--keep_aspect_ratio \
--pixel_format rgb \
--test_input ../image/0901x${scale}.png \
--test_result EDSR_x${scale}_outputs.npz \
--mlir EDSR_x${scale}.mlir
# 建立校准表
run_calibration.py EDSR_x${scale}.mlir \
--dataset ../dataset/X${scale} \
--input_num 50 \
-o EDSR_x${scale}_cali_table
# 多层优化和转换bmodel
##转换INT8模型
model_deploy.py \
--mlir EDSR_x${scale}.mlir \
--quantize INT8 \
--calibration_table EDSR_x${scale}_cali_table \
--chip bm1684x \
--test_input EDSR_x${scale}_in_f32.npz \
--test_reference EDSR_x${scale}_outputs.npz \
--tolerance 0.85,0.45 \
--model EDSR_x${scale}_1684x_int8_sym.bmodel
##转换FP16模型
model_deploy.py \
--mlir EDSR_x${scale}.mlir \
--quantize F16 \
--chip bm1684x \
--test_input EDSR_x${scale}_in_f32.npz \
--test_reference EDSR_x${scale}_top_outputs.npz \
--model EDSR_x${scale}_1684x_f32_sym.bmodel
##转换FP32模型
model_deploy.py \
--mlir EDSR_x${scale}.mlir \
--quantize F32 \
--chip bm1684x \
--test_input EDSR_x${scale}_in_f32.npz \
--test_reference EDSR_x${scale}_top_outputs.npz \
--model EDSR_x${scale}_1684x_f32_sym.bmodel
# 将以上所有EDSR改为MDSR即可转换MDSR模型
转换结果评估
评估过程说明
- 配置好BM1684X平台,上传并解压本项目EDSR-BM1684x.zip,同时下载benchmark数据集,确保benchmark与EDSR文件夹在同一目录内。进入EDSR/python目录下,运行以下命令:
#### predict on bm1684x
for model in {EDSR,MDSR}; do
for scale in {2,3,4}; do
echo -------------------------------------dataset=Set14-------------scale=${scale}-------------------------------------
cmd="python run_opencv_crop.py --input ../../benchmark/Set14/LR_bicubic/X${scale} \
--output results/${model}_Set14_x${scale}_int8 \
--bmodel ../models/BM1684X/${model}_x${scale}/${model}_x${scale}_1684x_int8_sym.bmodel"
echo ">>> Running: ${cmd}"
$cmd
done
done
- 推理结果保存在EDSR/python/results中,更改不同bmodel参数以使用不同bmodel
- 评估结果方法
#### 安装评估模型
pip install lpips
评估主要代码(eval.py)如下
...
for i, sr in enumerate(sr_list):
hr = Path(args.hr_path) / (sr.stem.split('x')[0] + sr.suffix)
if not hr.exists():
logging.error(f'{sr}: {hr} does not exist')
hr_list.append(None)
continue
hr_list.append(hr)
sr_img = Image.open(sr).convert('RGB')
hr_img = Image.open(hr).convert('RGB')
if hr_img.size != sr_img.size:
logging.info(f' cropping hr_img from {hr_img.size} to {sr_img.size}')
# hr_img = hr_img.resize(sr_img.size, resample=Image.Resampling.BICUBIC)
hr_img = hr_img.crop((0, 0, sr_img.size[0], sr_img.size[1]))
sr_img = np.array(sr_img)
hr_img = np.array(hr_img)
lpi = calculate_lpips(sr_img, hr_img, border=args.scale)
sr_img_y = rgb2ycbcr(sr_img, only_y=True)
hr_img_y = rgb2ycbcr(hr_img, only_y=True)
# sr_img_y = sr_img
# hr_img_y = hr_img
psnr = calculate_psnr(sr_img_y, hr_img_y, border=args.scale)
ssim = calculate_ssim(sr_img_y, hr_img_y, border=args.scale)
...
#### evaluate on bm1684x
scale=(2 3 4)
for model in {EDSR,MDSR}; do
for i in "${!scale[@]}"; do
echo -------------scale=${scale[$i]}-----------------
cmd="python eval.py --hr_path ../../benchmark/Set14/HR --sr_path results/${model}_Set14_x${scale[$i]}_int8 --scale ${scale[$i]}"
echo ">>> Running: ${cmd}"
$cmd
done
done
- 评价结果保存在results/*/result.log里
- 若是想测试自己的图片,请将图片放入image目录下然后运行以下命令,结果保存在results/image里。更改bmodel模型来更换模型与超分倍率
python run_opencv_crop.py --input ../image \
--output results/image \
--bmodel ../models/BM1684X/EDSR_x2_1684x_int8_sym.bmodel
评价代码如下
python eval.py --sr_path results/image --hr_path ../image --scale {sacle}
评估结果
精度测试方法
测试数据集采用Set14数据集,指标采用与原论文一致的PSNR+SSIM指标来衡量图像质量。因为我们在模型固定输入大小的情况下,对原图进行裁切,超分,拼合的形式达到动态输入的效果,所以有的精度指标在测试中不仅不会降低反而会升高。同时又由于不同放大倍数的模型输入大小和模型参数不一样,推理时间的比例也会发生变化。
fp32结果
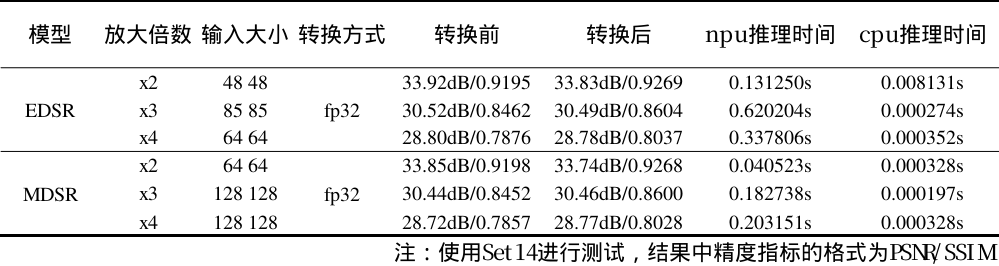
fp32
fp16结果
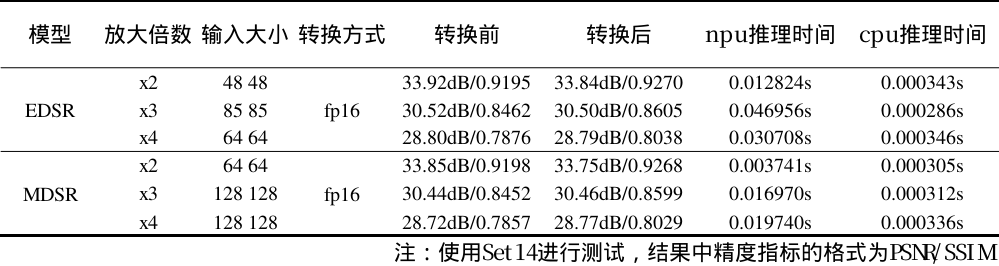
fp16
int8结果
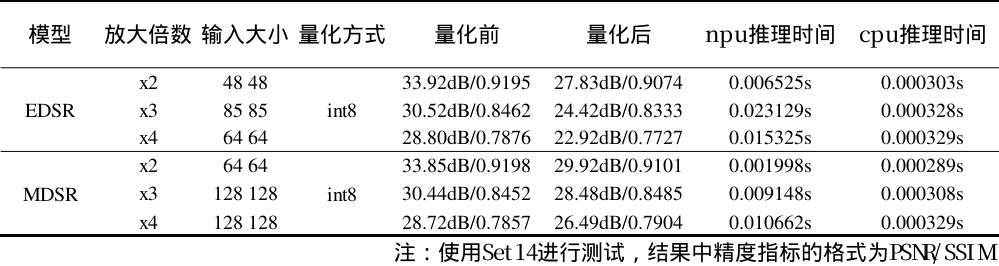
int8
精度对比
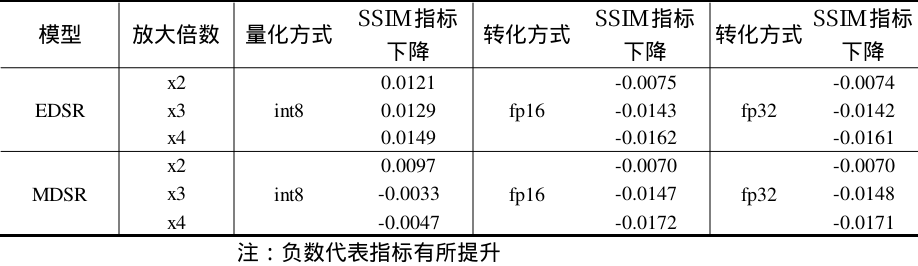
precise
性能对比
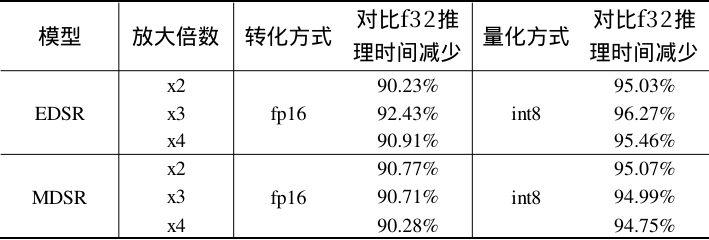
precise
结论
本次转换了EDSR和MDSR超分辨率模型,分别实现了fp32, fp16, int8多种精度模型转换, TPU-MLIR对这两个模型支持较好,转换过程中比较顺利。从最终评估结果上看,这两个超分模型对推理的数值精度不敏感,经过量化后,相关指标损失较少,甚至有些指标还会提升。另外,在BM1684X的平台上,INT8推理时间最短,故在部署时,推荐使用量化后的INT8模型部署。
-
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:2,图像识别2024-07-14 1530
-
TPU-MLIR开发环境配置时出现的各种问题求解2024-01-10 1214
-
深入学习和掌握TPU硬件架构有困难?TDB助力你快速上手!2023-12-22 2790
-
如何适配新架构?TPU-MLIR代码生成CodeGen全解析!2023-11-02 3381
-
TPU-MLIR量化敏感层分析,提升模型推理精度2023-10-10 3238
-
在“model_transform.py”添加参数“--resize_dims 640,640”是否表示tpu会自动resize的?2023-09-18 576
-
如何使用TPU-MLIR进行模型转换2023-08-21 1869
-
TPU-MLIR中的融合处理2023-08-18 1493
-
ClearAi人工智能如何把模糊图片变清晰和模糊视频变清晰(自动补帧)2021-08-07 8102
-
如何让模糊的图片变清晰,视频变高清2020-12-16 2533
-
一种张量总变分的模糊图像盲复原算法2017-12-09 1239
全部0条评论

快来发表一下你的评论吧 !
