

三项SOTA!MasQCLIP:开放词汇通用图像分割新网络
描述
1. 效果展示
MasQCLIP在开放词汇实例分割、语义分割和全景分割三项任务上均实现了SOTA,涨点非常明显。这里也推荐工坊推出的新课程《彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析》。
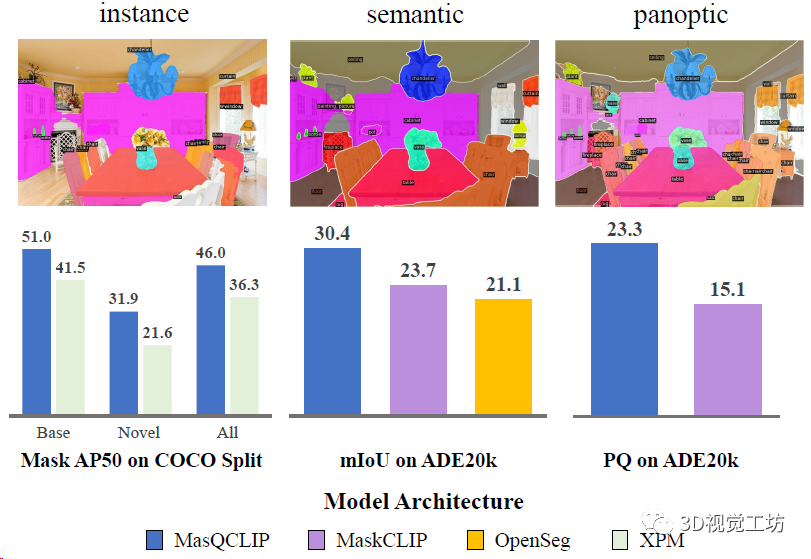
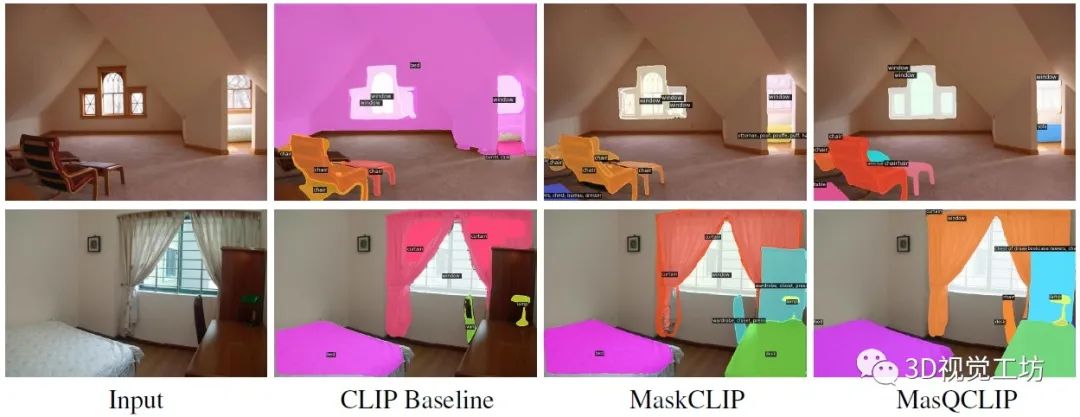
再来看看开放词汇全景分割的定性效果,图片来源于ADE20k,可以发现MasQCLIP分割出的Mask和类别精度更高。

2. 具体原理是什么?
先介绍一下基础的CLIP模型:ICML-2021的工作,多模态视觉-语言模型代表。主要用来提取zero-shot目标的特征。核心思想是,很多模型需要预定义图像类别,但是文本实际上就已经提供了未见类别的信息,融合文本就可以极大增强模型的泛化性。
而MasQCLIP的思想是,利用稠密特征与预训练的CLIP模型无缝集成,从而避免训练大规模参数。MasQCLIP在使用CLIP模型构建图像分割时侧重两方面:
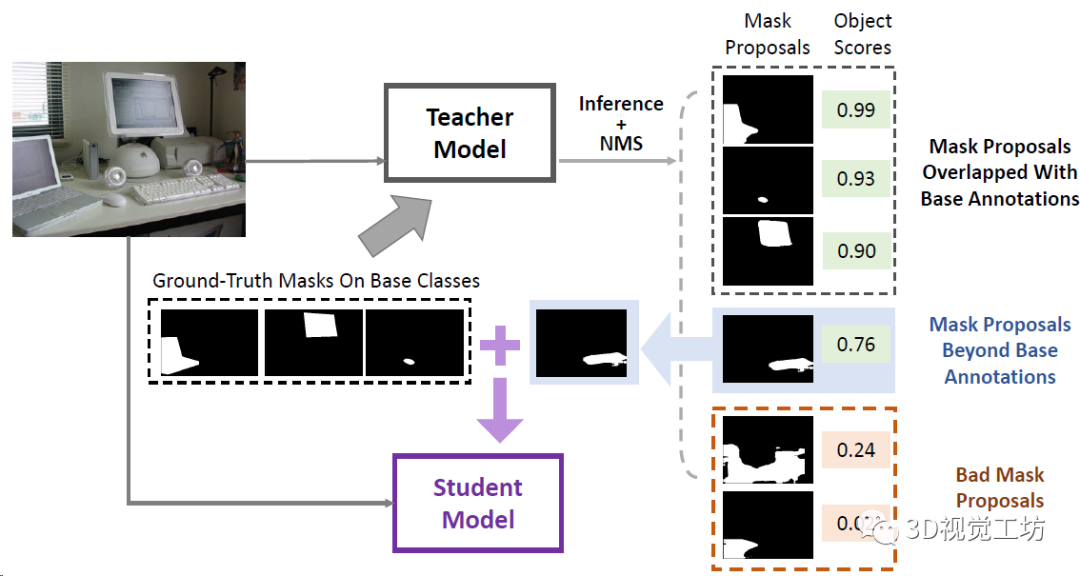
(1)学生-教师模块,通过从基础(已见)类中提取信息来处理新(未见)类的Mask;
(2)更新CLIP模型中查询的模型参数的微调过程。
具体Pipeline是,MasQCLIP由类无关Mask提议网络和基于CLIP的Mask分类模块组成。在Mask提议网络中,应用渐进蒸馏来分割基类之外的Mask。之后将预测的Mask送入分类模块以获得标签。为了有效利用密集CLIP特征,还提出了MasQ-Tuning策略。
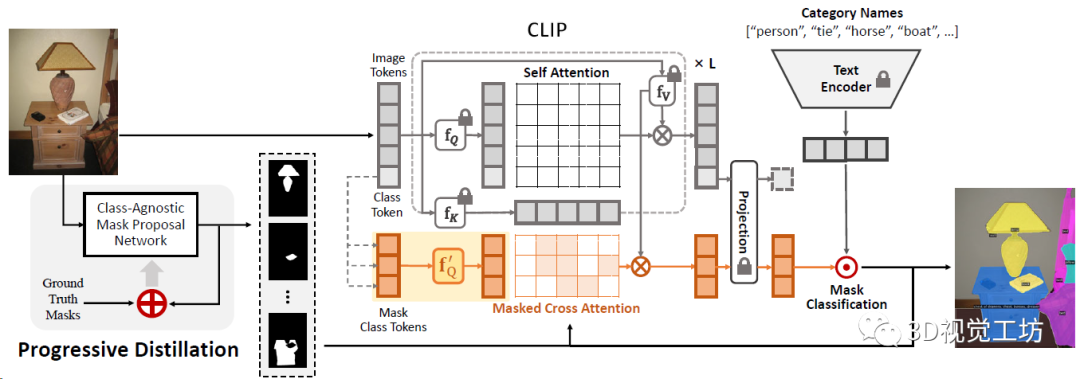
再来看看这个渐进蒸馏,就是从教师模型的分割图中提取和基础类别没有重叠的Mask,用来做辅助训练,将这些额外的标注蒸馏到学生模型中,然后不停的迭代循环来提高泛化性。
3. 再来看看效果如何
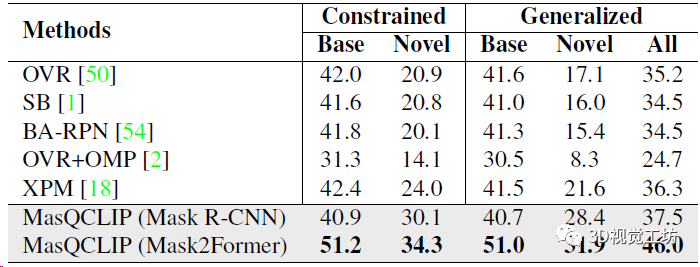
开放词汇通用图像分割的定量结果,直接对比了实例分割、语义分割、全景分割三个任务。三大任务涨点都非常明显!
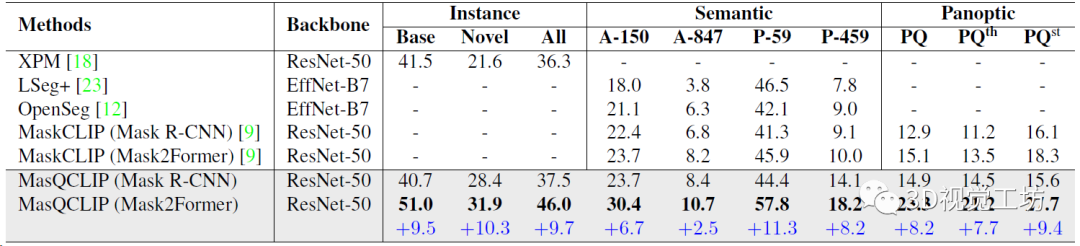
开放词汇实例分割结果,分别对比基类和新类别的定量精度,展示了模型的泛化性。这里也推荐工坊推出的新课程《彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析》。
开放词汇实例分割定性对比,可以发现MasQCLIP分割精度更高!
审核编辑:刘清
-
使用全卷积网络模型实现图像分割2019-05-28 2453
-
安规三项2021-08-03 6707
-
中兴_5G三项提案入选网络5.0领先创新科技成果有哪些?2021-10-15 10057
-
图像分割—基于图的图像分割2015-11-19 951
-
基于二次图像分割的目标提取算法2017-11-07 924
-
图像分割技术的原理及应用2017-12-19 42033
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1475
-
在NGC上玩转图像分割!NeurIPS顶会模型、智能标注10倍速神器、人像分割SOTA方案、3D医疗影像分割利器应有尽有2022-11-21 1953
-
3D UX-Net:超强的医学图像分割新网络2023-02-01 3962
-
CVPR 2023 | 华科&MSRA新作:基于CLIP的轻量级开放词汇语义分割架构2023-07-10 2699
-
什么是图像分割?图像分割的体系结构和方法2023-08-18 8740
-
ODCC 2023 | 华为数据中心网络荣膺2023开放数据中心大会三项大奖2023-09-13 1795
-
NeurlPS'23开源 | 首个!开放词汇3D实例分割!2023-11-14 1839
-
不同型号的三项电容可以串联吗?2023-11-15 3659
-
格科微电子荣膺三项权威认可2025-12-01 755
全部0条评论

快来发表一下你的评论吧 !
