

大模型+多模态的3种实现方法
电子说
描述
我们知道,预训练LLM已经取得了诸多惊人的成就, 然而其明显的劣势是不支持其他模态(包括图像、语音、视频模态)的输入和输出,那么如何在预训练LLM的基础上引入跨模态的信息,让其变得更强大、更通用呢?本节将介绍“大模型+多模态”的3种实现方法。
01
以LLM为核心,调用其他多模态组件
2023年5月,微软亚洲研究院(MSRA)联合浙江大学发布了HuggingGPT框架,该框架能够以LLM为核心,调用其他的多模态组件来合作完成复杂的AI任务(更多细节可参见Yongliang Shen等人发表的论文“HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace”)。HuggingGPT框架的原理示意图如图1所示。下面根据论文中提到的示例来一步一步地拆解 HuggingGPT框架的执行过程。
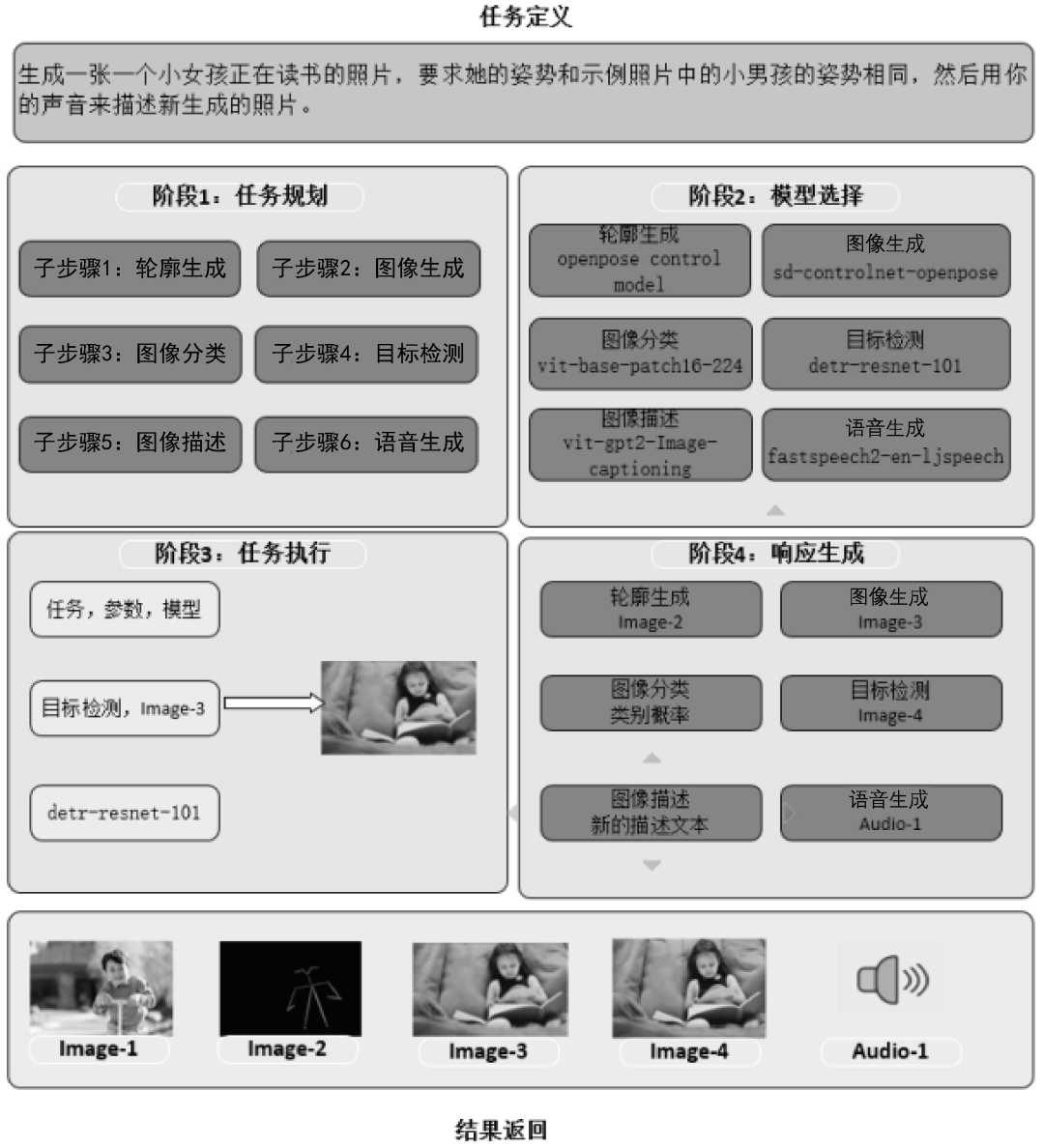
图1
假如现在你要执行这样一个复杂的AI任务:生成一张一个小女孩正在读书的照片,要求她的姿势和示例照片中的小男孩的姿势相同,然后用你的声音来描述新生成的照片。HuggingGPT框架把执行这个复杂AI任务的过程分成了4个步骤。
(1)任务规划(Task Planning)。使用LLM了解用户的意图,并将用户的意图拆分为详细的执行步骤。如图5-10左上部分所示,将输入指令拆分为6个子步骤。
子步骤1:根据小男孩的图像Image-1,生成小男孩的姿势轮廓Image-2。
子步骤 2:根据提示文本“小女孩正在读书”及小男孩的姿势轮廓Image-2生成小女孩的图像Image-3。
子步骤3:根据小女孩的图像Image-3,对图像信息进行分类。
子步骤4:根据小女孩的图像Image-3,对图像信息进行目标检测,生成带目标框的图像Image-4。
子步骤5:根据小女孩的图像Image-3,对图像信息进行描述,生成描述文本,并在Image-4中完成目标框和描述文本的配对。
子步骤6:根据描述文本生成语音Audio-1。
(2)模型选择(Model Selection)。根据步骤(1)中拆分的不同子步骤,从Hugging Face平台(一个包含多个模型的开源平台)中选取最合适的模型。对于子步骤1中的轮廓生成任务,选取OpenCV的openpose control模型;对于子步骤2中的图像生成任务,选取sd-controlnet-openpose模型;对于子步骤3中的图像分类任务,选取谷歌的vit-base-patch16-224模型;对于子步骤4中的目标检测任务,选取Facebook的detr-resnet-101模型;对于子步骤5中的图像描述任务,选取nlpconnect开源项目的vit-gpt2-Image-captioning模型;对于子步骤6中的语音生成任务,选取Facebook的fastspeech2-en- ljspeech模型。
(3)任务执行(Task Execution)。调用步骤(2)中选定的各个模型依次执行,并将执行的结果返回给LLM。
(4)响应生成(Response Generation)。使用LLM对步骤(3)中各个模型返回的结果进行整合,得到最终的结果并进行输出。
HuggingGPT框架能够以LLM为核心,并智能调用其他多模态组件来处理复杂的AI任务,原理简单,使用方便,可扩展性强。另外,其执行效率和稳定性在未来有待进一步加强。
02
基于多模态对齐数据训练多模态大模型
这种方法是直接利用多模态的对齐数据来训练多模态大模型,《多模态大模型:技术原理与实战》一书5.3节中介绍了诸多模型,例如VideoBERT、CLIP、CoCa、CoDi等都是基于这种思路实现的。
这种方法的核心理念是分别构建多个单模态编码器,得到各自的特征向量,然后基于类Transformer对各个模态的特征进行交互和融合,实现在多模态的语义空间对齐。
由此训练得到的多模态大模型具备很强的泛化能力和小样本、零样本推理能力,这得益于大规模的多模态对齐的预训练语料。与此同时,由于训练参数量较大,往往需要较多的训练资源和较长的训练时长。
03
以LLM为底座模型,训练跨模态编码器
这种方法的特色是以预训练好的LLM为底座模型,冻结LLM的大部分参数来训练跨模态编码器,既能够有效地利用LLM强大的自然语言理解和推理能力,又能完成复杂的多模态任务。这种训练方法还有一个显而易见的好处,在训练过程中对LLM的大部分参数进行了冻结,导致模型可训练的参数量远远小于真正的多模态大模型,因此其训练时长较短,对训练资源的要求也不高。下面以多模态大模型LLaVA为例介绍这种方法的主要构建流程。
2023年4月,威斯康星大学麦迪逊分校等机构联合发布了多模态大模型LLaVA。LLaVA模型在视觉问答、图像描述、物体识别、多轮对话等任务中表现得极其出色,一方面具有强大的自然语言理解和自然语言推理能力,能够准确地理解用户输入的指令和意图,支持以多轮对话的方式与用户进行交流,另一方面能够很好地理解输入图像的语义信息,准确地完成图像描述、视觉问答、物体识别等多模态任务。LLaVA模型的原理示意图如图2所示。
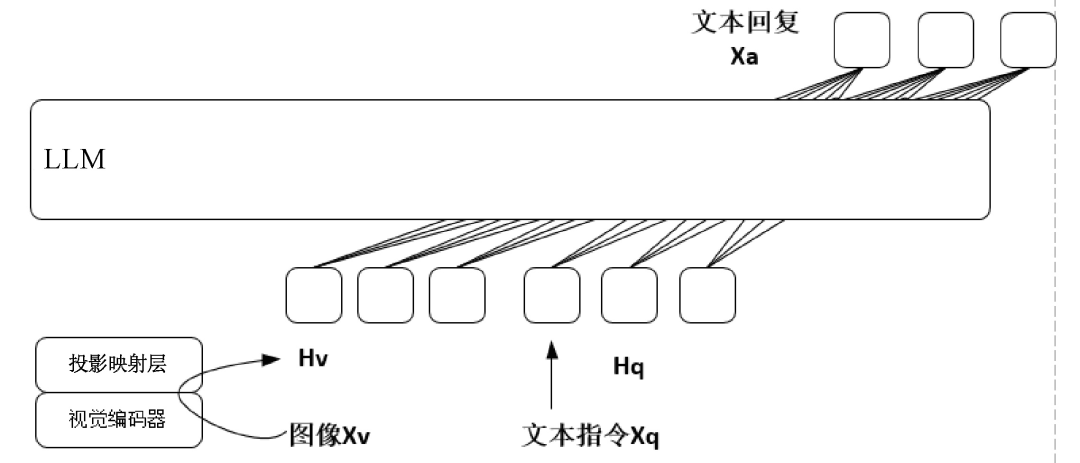
图2
在训练数据上,LLaVA模型使用了高质量的多模态指令数据集,并且这些数据都是通过GPT-4生成的。这个指令数据集包含基于图像的对话数据、详细描述数据和复杂推理数据,共15万条,数据的质量和多样性较高。LLaVA模型将多模态指令数据集应用到了多模态任务上,这是指令微调扩展到多模态领域的第一次尝试。
在模型架构上,LLaVA模型使用Vicuna模型作为文本编码器,使用CLIP模型作为图像编码器。
第一个阶段,基于59.5万条CC3M文本-图像对齐数据,训练跨模态编码器,以便将文本特征和图像特征进行语义对齐。这里的跨模态编码器其实是一个简单的投影映射层,在训练时冻结LLM的参数,仅仅对投影映射层的参数进行更新。
第二个阶段,基于15万条多模态指令数据,对多模态大模型进行端到端的指令微调,具体针对视觉问答和多模态推理任务进行模型训练。值得注意的是,LLaVA模型在训练的第二个阶段会对LLM和投影映射层的参数都进行相应的更新,仍然存在一定的时间开销和训练资源依赖,这也是后续研究工作的一个重要方向。
2023年5月2日,LLaVA官方发布了轻量级的LLaVA Lightning模型(可以翻译为轻量级的LLaVA模型),使用8个RTX A100型号的显卡,3小时即可完成训练,总训练成本仅为40美元。
审核编辑:刘清
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 180
-
基于多模态特征数据的多标记迁移学习方法的早期阿尔茨海默病诊断2017-12-14 1044
-
基于超图的多模态关联特征处理方法2018-03-07 1359
-
单张消费级显卡微调多模态大模型2023-06-30 4251
-
VisCPM:迈向多语言多模态大模型时代2023-07-10 1552
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1673
-
探究编辑多模态大语言模型的可行性2023-11-09 1177
-
从Google多模态大模型看后续大模型应该具备哪些能力2023-12-28 2646
-
利用OpenVINO部署Qwen2多模态模型2024-10-18 3135
-
一文理解多模态大语言模型——下2024-12-03 1380
-
商汤日日新多模态大模型权威评测第一2024-12-20 1935
-
爱芯通元NPU适配Qwen2.5-VL-3B视觉多模态大模型2025-04-21 4015
-
亚马逊云科技上线Amazon Nova多模态嵌入模型2025-10-29 465
-
格灵深瞳多模态大模型Glint-ME让图文互搜更精准2025-11-02 1970
-
海光DCU完成Qwen3.5多模态MoE模型全量适配2026-03-26 991
全部0条评论

快来发表一下你的评论吧 !
