

谷歌Gemini模型AI网络及TPU拆解
描述
Gemini 是一款新型的多模态大语言模型,此前多模态大模型在处理视频、文字、图像等多维度输入信息时是采用分别训练分别输出再进行拼接的方式,这种方式的缺点在于面对复杂逻辑问题时,大模型的回复略显迟钝。
Gemini 采用了全新的训练方式,直接在多模态数据上进行预训练,并利用额外的多模态数据进行微调,因而可在处理复杂逻辑问题上更加智能。
下载链接:
Gemini 模型一共包括三个版本,可以在不同设备上进行使用。
1)Gemini Nano—端侧设备上最高效的模型。这款模型专为智能手机设计,可以在没有连接外部服务器的情况下完成 AI 处理任务。
2)Gemini Pro—运行在谷歌数据中心。Pro 版本将在最新版本的 AI 聊天机器人 Bard 提供支持,是 Bard推出以来的最大升级。目前为 170 多个国家和地区提供英语服务,计划未来几个月内支持新的语言和地区,并应用于搜索、广告、Chrome 和 Duet AI 等更多谷歌产品。
3)Gemini Ultra —规模最大且功能最强大的模型,专用于高度复杂的任务,会在完成当前测试阶段后的明年初向开发者和企业客户提供。届时还会推出基于 Gemini Ultra 的 Bard Advanced 更新版本。
Gemini 模型训练基于谷歌自研 TPU 芯片,发布 TPU v5P,性能全部升级。谷歌较早就开始布局 AI 市场,2015 年便发布了专门用于 AI 领域的专用芯片 TPU v1,2015 年至今,谷歌已经完成了五个版本的迭代。目前现阶段谷歌展示的 Gemini 1.0 模型就是基于 TPU v4 和 TPU v5e 两类芯片来完成训练过程。
在发布 Gemini 模型的同时,谷歌发布了最新的 TPU v5p 系列。v5p 进一步增强了方案可拓展性,并为了应对复杂模型的推理训练与调整需求,设计了新的硬件架构。在 v5p 构建的集群,每个 Pod 计算单元由 8960颗芯片互联,数量较之前的版本翻倍。计算性能上,新的 pod 浮点运算能力相比 v4 提升了两倍,训练速度相比 v4 提升 2.8 倍以上。
谷歌 TPU:创新网络拓扑结构,采用光交换技术(OCS)。传统数据中心网络结构为 leaf-spine 叶脊架构,英伟达 AI 集群采用的是无收敛胖拓扑结构,谷歌的 AI 网络集群在 spine 层进行创新,用 OCS 交换机(光路开关,optical circuit switch)代替传统的电交换机(以太网交换机)。传统数据中心在 spine 层需要进行大量的电光转换,会产生较多的功耗,并且随着数据量增加 spine 层每 2-3 年都需要进行更换。谷歌的 OCS 的目的是替代当下的电网络交换机,从而实现近一步成本和功耗的降低。
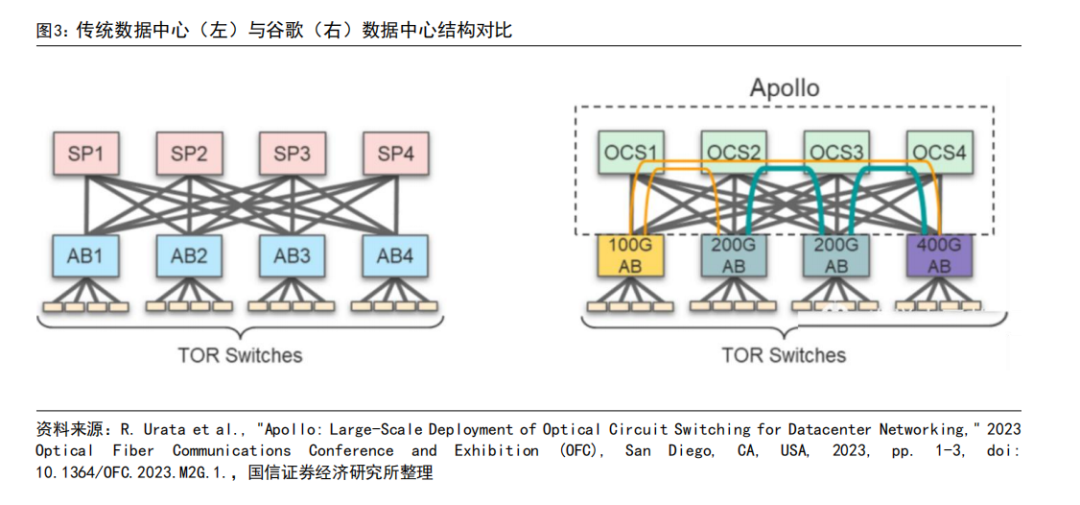
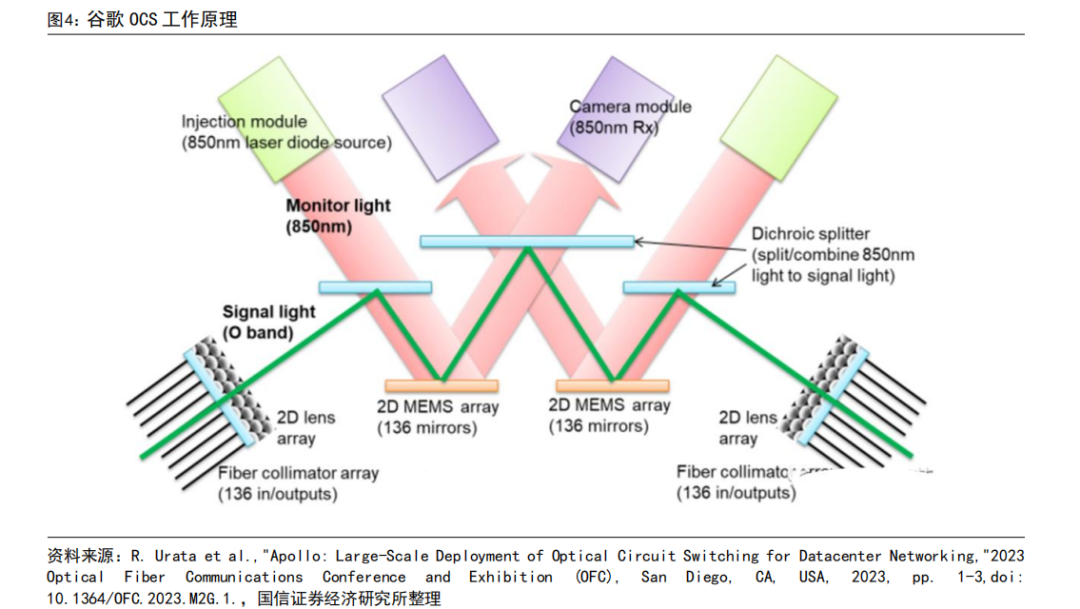
谷歌的 OCS 称为为 Palomar,内部结构为:输入输出为光纤准直器阵列,光纤准直器包括光纤阵列和微透镜阵列,输入和数据均为 136 个通道(128 个端口+8 个备用端口)。当光通过光纤进入 OCS 系统后,会通过两个 2D 的 MEMS 阵列,每个 MEMS 阵列含有 136 个平面镜,用于调整光的传播方向。波长为 850nm。
谷歌 AI 网络结构拆解:TPU v4 为例。在 TPU v4 网络结构设计时候,每个基础单元是 4*4*4=64 颗 TPU 组成,每个面有 16 个链路,因此每个单元一共有 16*6=96 个链路连接到 OCS 的光链路.此外因为提供 3D 环面的环绕链接,相对侧的链接必须连接到同一个 OCS。因此,每个基础单元需要 6×16/2=48 个 OCS。
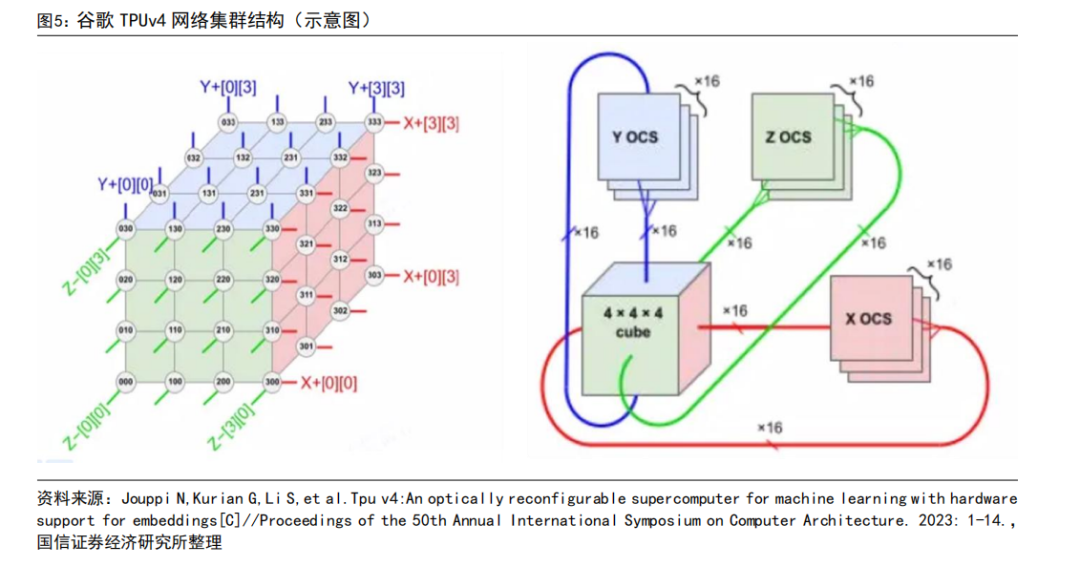
谷歌 TPU v4 支持 4096 颗 TPU 互联,具体方案为一共使用 64 个机柜,每个机柜内部构建 4*4*4=64 颗 TPU的 3D 网络结构,其中 3D 结构的外表部分连接到 OCS,中间部分采用无源电缆互联。在 4096 颗 TPU 互联的系统中一共使用 48 了个 OCS,每个 OCS128 个端口。此外因为 OCS 本身直接进行光信号的传输,所以每个端口只需要 1 个光模块。因为该集群需要 48*128=6144 个光模块。TPU:光模块用量=4096:6144=1:1.5
AMD MI300X 对标英伟达 H100。MI300X 由台积电代工,基于自研的第三代 CDNA 架构,集成了 1530 亿个晶体管。
对比英伟达 H100,集成了 800 亿个晶体管。在性能指标上:1)AI 芯片算力:8 位精度浮点数(FP8)计算水平来看,MI300X 为 42petaFLOPs(每秒千万亿次浮点运算),H100 则为 32petaFLOPs;2)内存:MI300X为 192GB,英伟达 H109 为 120GB。目前,集合 8 张 MI300X 的 Instinct 工作台已经可以支持运行 Llama2(700 亿参数)、BLOOM(1760 亿参数)大模型的训练与推理。
MI300A:首款高性能 APU。具体参数上,MI300A 具有 228 个 CDNA3 架构的计算核心,24 个 Zen4 架构的 X86核心,4 个 I/O DIe,8 个 HBM3,128GB 显存,5.3TB 峰值带宽,256MB 的 Infinity 缓存,采用 3.5D 的封装形式。
审核编辑:汤梓红
-
“吊打”TPU!谷歌Frozen v2“开造”,Gemini专供版芯片来了?2026-07-22 1042
-
谷歌推出Gemini 3.5系列模型2026-05-21 930
-
谷歌正式推出最新Gemini 3 AI模型2025-11-24 1591
-
谷歌新一代 TPU 芯片 Ironwood:助力大规模思考与推理的 AI 模型新引擎2025-04-12 4370
-
谷歌 Gemini 2.0 Flash 系列 AI 模型上新2025-02-07 1546
-
谷歌发布“深度研究”AI工具,利用Gemini模型进行网络信息检索2024-12-16 1431
-
谷歌发布Gemini 2.0 AI模型2024-12-12 1324
-
谷歌计划12月发布Gemini 2.0模型2024-10-29 1785
-
谷歌Gemini 1.5 Flash模型升级,AI聊天速度飙升50%2024-09-06 1814
-
谷歌最新人工智能模型Gemini Pro已在欧洲上市2024-02-04 2203
-
谷歌发布多模态Gemini大模型及新一代TPU系统Cloud TPU v5p2023-12-12 2798
-
成都汇阳投资关于谷歌携 Gemini 王者归来,AI 算力和应用值得期待2023-12-11 2528
-
谷歌揭秘Gemini,AMD对峙英伟达2023-12-07 1733
全部0条评论

快来发表一下你的评论吧 !
