

一种通过视图合成增强预训练的2D扩散模型的可扩展技术
描述
1、导读
现有的3D物体检测方法通常需要使用完全注释的数据进行训练,而使用预训练的语义特征可以带来一些优势。然而,目前还没有利用扩散特征进行3D感知任务的研究。因此,我们提出了一种新的框架,通过视图合成任务来增强预训练的2D扩散模型的3D感知能力。该方法利用已知相对姿态的图像对进行训练,并通过扩散过程生成目标输出。此外,文章还介绍了如何将这些增强的特征用于3D物体检测,并通过引入辅助网络来保持特征质量。最后,文章通过实验证明了该方法在点对应和3D检测性能上的优越性。
2、研究内容
一种名为3DiffTection的新框架,该框架利用预训练的2D扩散模型来进行3D物体检测任务。该方法通过视图合成任务,将2D扩散特征增强为具有3D感知能力的特征。作者利用已知相对姿态的图像对进行特征提取和特征扩散过程,从而生成目标输出。文章还介绍了如何将这些增强的特征用于3D物体检测,并通过引入辅助控制网络来进一步适应目标任务和数据集。最后,作者通过多个合成视图生成检测提议,并通过非极大值抑制(NMS)来整合这些提议,从而提高检测性能。
3、贡献
介绍了一种通过视图合成增强预训练的2D扩散模型的可扩展技术,使其具有3D感知能力;
将这些特征适应于3D检测任务和目标领域;
利用视图合成能力通过集成预测进一步提高检测性能。
4、方法
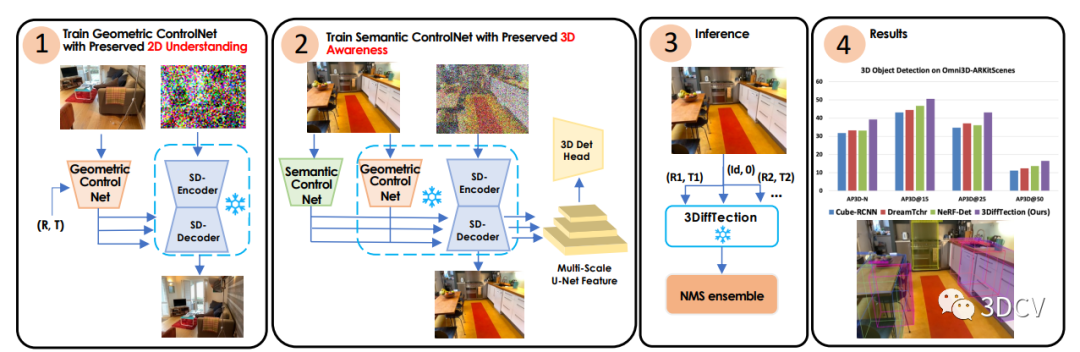
3DiffTection:它可以在3D物体检测任务中利用预训练的2D扩散模型。该方法的关键在于设计了一个视图合成任务,通过使用极线几何将源图像中的残差特征进行变形,从而增强了2D扩散特征的3D感知能力。通过去噪扩散过程,这些变形的特征有助于生成目标输出。我们的方法利用了具有已知相对姿态的图像对,这些图像对通常可以从视频数据中轻松获取。鉴于视频数据的不断增加,这使得我们的表示精炼解决方案具有高度的可扩展性。
4.1、2D扩散模型特征提取
在3DiffTection中,我们使用预训练的2D扩散模型作为特征提取器。扩散模型已经在图像分割等密集感知任务中展现出了强大的性能。我们利用这些模型学习到的语义特征,并通过视图合成任务增强这些特征的3D感知能力。通过提取源图像的残差特征,并利用极线几何将其映射到目标视图,我们能够生成目标输出。这样,我们就能够将预训练的2D扩散模型的特征转化为具有3D感知能力的特征。这种方法使得我们的模型能够更好地理解图像中的3D结构,并在3D目标检测任务中取得更好的性能。
4.2、3D感知融入扩散特征
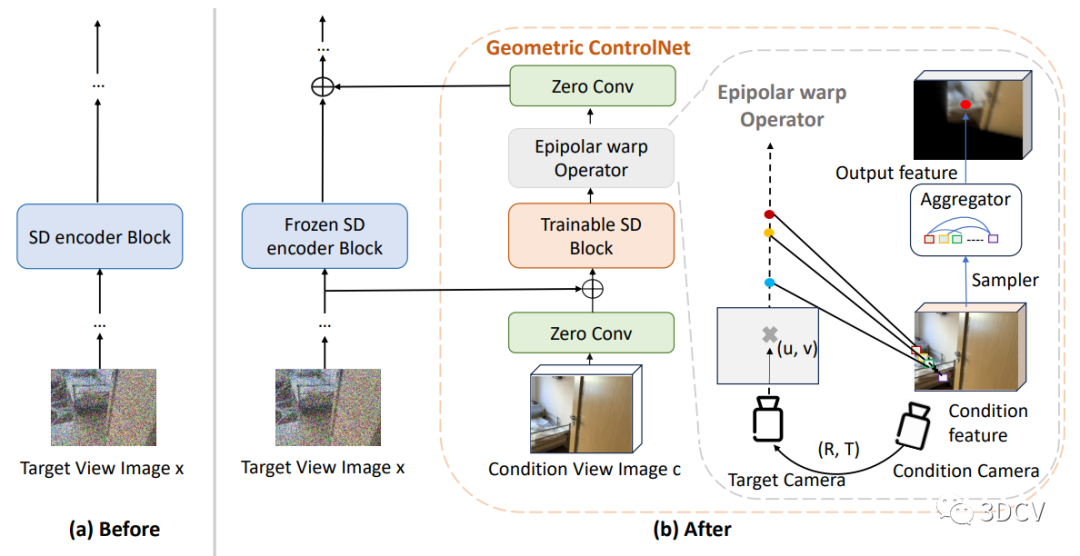
如何将3D感知融入扩散特征。具体而言,作者通过训练一个视图合成任务来增强预训练的2D扩散模型的3D感知能力。这个任务的关键是从源图像中提取残差特征,并使用极线几何将它们映射到目标视图上。通过这种映射,可以通过去噪扩散过程生成目标输出。这些经过映射的特征有助于增强模型对目标的生成能力。这种方法利用了具有已知相对姿态的图像对,这些图像对通常可以从视频数据中轻松获取。我们接下来利用这些增强的3D特征进行3D检测,通过在3D框注释下训练一个标准的检测头。虽然我们的模型的基线性能已经显示出对现有方法的改进,但我们的目标是进一步将训练好的特征适应目标任务和数据集,这可能与用于视图合成预训练的数据不同。
由于训练数据有限,直接微调模型来弥合任务和领域差距可能会导致性能下降。为了解决这个问题,作者引入了一个辅助的ControlNet,它有助于保持特征的质量。这个过程还保留了模型的视图合成能力。在测试时,我们通过从多个合成视图生成检测提议,并通过非极大值抑制(NMS)来合并这些提议,从而充分利用几何和语义能力。
5、实验结果
本研究采用了两种实验方法来评估提出的3DiffTection框架的性能。
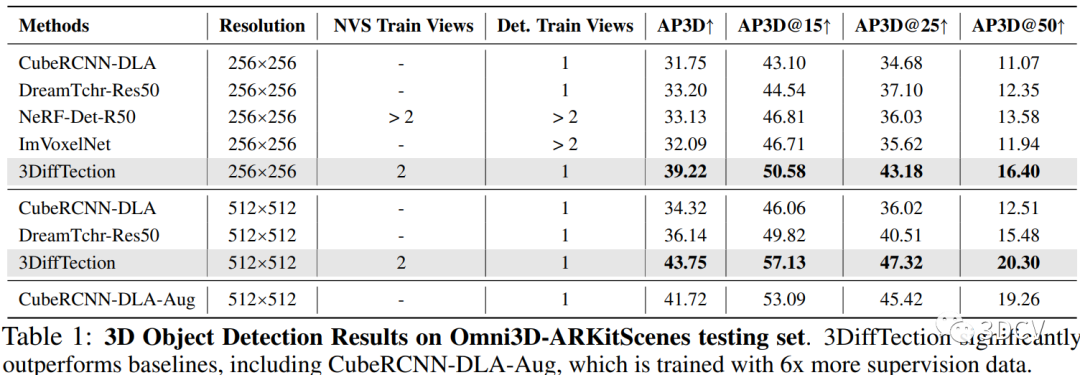
第一种实验方法是在Omni3D-ARKitscene数据集上进行的。首先,使用预训练的2D扩散模型进行视图合成,以增强2D特征的3D感知能力。然后,使用训练好的3D检测头在3D边界框监督下对特征进行3D检测。为了进一步适应目标任务和数据集,引入了一个辅助的控制网络来维持特征质量。最后,通过生成多个合成视图的检测提议,并通过非最大抑制(NMS)进行整合,来进行3D检测。实验结果表明,与现有方法相比,3DiffTection在Omni3D-ARKitscene数据集上取得了显著的改进。
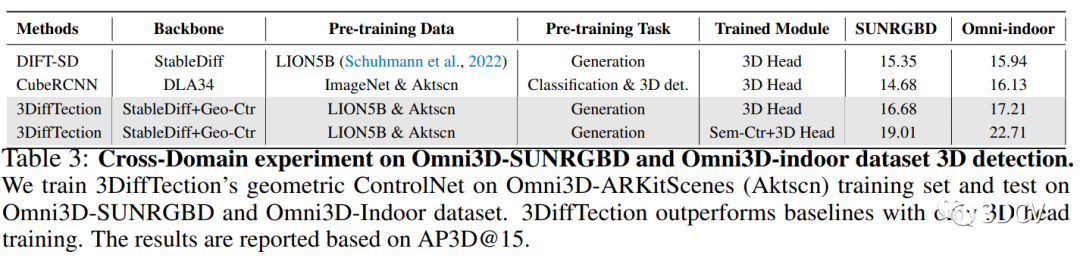
第二种实验方法是在跨数据集上进行的。首先,在Omni3D-ARKitscene数据集上训练了具有几何控制网络的3DiffTection模型,并仅在跨域数据集上训练了3D检测头。然后,将3DiffTection与CubeRCNN进行比较。实验结果显示,即使在目标域中没有对几何控制网络进行训练,3DiffTection仍然能够超越完全微调的CubeRCNN。


6、创新性
主要体现在以下几个方面:
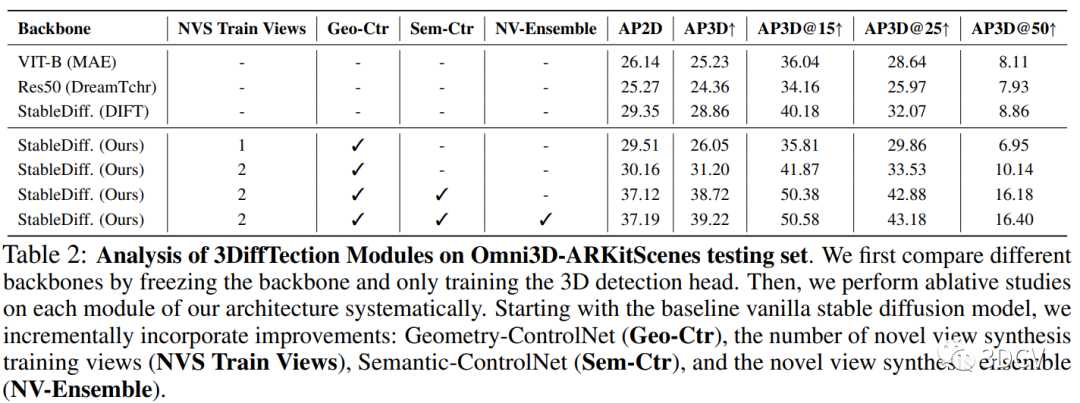
引入了几何感知的稳定扩散特征:本研究通过在稳定扩散特征中引入几何感知,提高了3D目标检测的性能。通过训练几何控制网络,将相机姿态信息与扩散特征结合起来,实现了对3D空间的感知。这种几何感知的稳定扩散特征在目标检测任务中表现出更好的性能。
提出了基于视图合成的训练方法:本研究利用视图合成技术,通过生成新的视图来增强模型的泛化能力。通过训练模型生成与输入图像不同视角的合成图像,使得模型能够学习到更多的视角信息,从而提高了模型在不同数据集上的性能。
结合语义控制网络进行联合训练:本研究还引入了语义控制网络,通过与3D检测头部联合训练,进一步提高了2D和3D检测的性能。语义控制网络能够适应感知任务,并优化特征的使用,从而提高检测的准确性。
7、总结
我们提出了一种名为3DiffTection的新框架,该框架利用预训练的2D扩散模型增强了3D物体检测任务的性能。作者通过视图合成任务,将源图像中的残差特征提取出来,并利用极线几何将其变形到目标视图中,从而增强了2D扩散特征的3D感知能力。作者还通过训练一个标准的检测头来利用这些增强的特征进行3D检测。实验证明,这种方法在点对应和物体检测性能上都优于基准模型。此外,作者还介绍了一个辅助的控制网络,用于保持特征质量,并通过生成多个合成视图的检测提案来进一步提高检测性能。总体而言,作者的方法在3D物体检测任务中取得了显著的改进,并展示了其在不同数据集上的泛化能力。
审核编辑:刘清
-
一文详解知识增强的语言预训练模型2022-04-02 11199
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1597
-
探索一种降低ViT模型训练成本的方法2022-11-24 1581
-
为什么要使用预训练模型?8种优秀预训练模型大盘点2019-04-04 24735
-
一种脱离预训练的多尺度目标检测网络模型2021-04-02 1876
-
一种侧重于学习情感特征的预训练方法2021-04-13 1237
-
HarmonyOS测试技术与实战-2D负载模型2021-10-23 1974
-
如何实现更绿色、经济的NLP预训练模型迁移2022-03-21 3294
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2722
-
利用视觉语言模型对检测器进行预训练2022-08-08 2545
-
什么是预训练 AI 模型?2023-04-04 2835
-
2D Transformer 可以帮助3D表示学习吗?2023-07-03 2025
-
介绍一种使用2D材料进行3D集成的新方法2024-01-13 2587
-
预训练模型的基本原理和应用2024-07-03 6159
-
大语言模型的预训练2024-07-11 2037
全部0条评论

快来发表一下你的评论吧 !
