

微软正式发布一个27亿参数的语言模型—Phi-2
描述
先后和 OpenAI、Meta 牵手推动大模型发展的微软,也正在加快自家小模型的迭代。就在今天,微软正式发布了一个 27 亿参数的语言模型——Phi-2。这是一种文本到文本的人工智能程序,具有出色的推理和语言理解能力。
同时,微软研究院也在官方 X 平台上如是说道,“Phi-2 的性能优于其他现有的小型语言模型,但它足够小,可以在笔记本电脑或者移动设备上运行”。
Phi-2 的性能真能优于大它 25 倍的模型?
对于 Phi-2 的发布,微软研究院在官方公告的伊始便直言,Phi-2 的性能可与大它 25 倍的模型相匹配或优于。
这也让人有些尴尬的事,不少网友评价道,这岂不是直接把 Google 刚发的 Gemini 最小型号的版本给轻松超越了?

那具体情况到底如何?
微软通过时下一些如 Big Bench Hard (BBH)、常识推理(PIQA、WinoGrande、ARC easy 和 Challenge、SIQA)、语言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、 SQuADv2、BoolQ)、数学(GSM8k)和编码(HumanEval)等基准测试,将 Phi-2 与 7B 和 13B 参数的 Mistral 和 Llama-2 进行了比较。
最终得出仅拥有 27 亿个参数的 Phi-2 ,超越了 Mistral 7B 和 Llama-2 7B 以及 13B 模型的性能。值得注意的是,与大它 25 倍的 Llama-2-70B 模型相比,Phi-2 还在多步推理任务(即编码和数学)上实现了更好的性能。
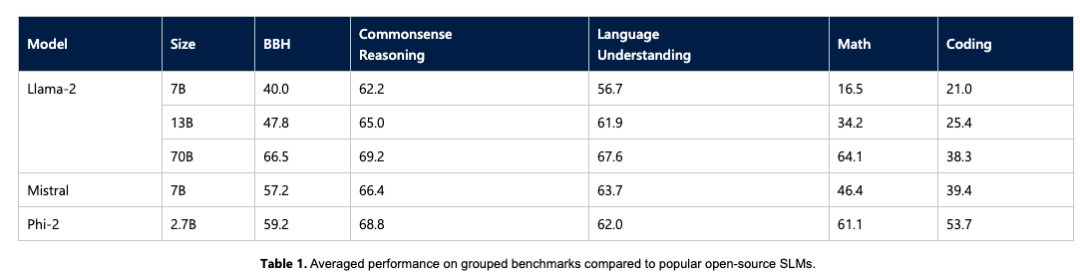
此外,如上文所提及的,微软研究人员也直接在基准测试中放上了其与Google 全新发布的 Gemini Nano 2 正面 PK 的结果,不出所料,Phi-2 尽管尺寸较小,但性能还是把 Gemini Nano 2 超了。

除了这些基准之外,研究人员似是在暗讽 Google 前几日在 Gemini 演示视频中造假一事,因为当时 Google 称其即将推出的最大、最强大的新人工智能模型 Gemini Ultra 能够解决相当复杂的物理问题,并且甚至纠正学生的错误。
事实证明,尽管 Phi-2 的大小可能只是 Gemini Ultra 的一小部分,但它也能够正确回答问题并使用相同的提示纠正学生。

微软的改进
Phi-2 小模型之所以有如此亮眼的成绩,微软研究院在博客中解释了原因。
一是提升训练数据的质量。Phi-2 是一个基于 Transformer 的模型,其目标是预测下一个单词,它在 1.4T 个词组上进行了训练,这些词组来自 NLP 和编码的合成数据集和网络数据集,包括科学、日常活动和心理理论等用于教授模型常识和推理的内容。Phi-2 的训练是在 96 个 A100 GPU 上耗时 14 天完成的。
其次,微软使用创新技术进行扩展,将其知识嵌入到 27 亿参数 Phi-2 中。
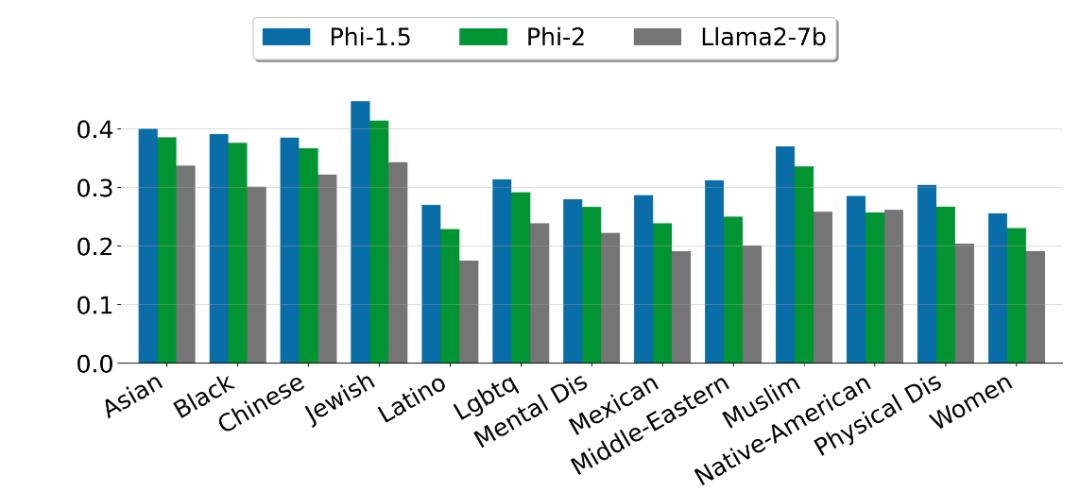
微软指出,Phi-2 是一个基础模型,没有通过人类反馈强化学习(RLHF)进行调整,也没有经过指导性微调。尽管如此,与经过对齐的现有开源模型相比,微软观察到在毒性和偏差方面,Phi-2 有更好的表现。
写在最后
话说 Phi-2 的发布的确在小模型的性能上实现了突破,不过也有媒体发现它还存在很大的局限性。
因为根据微软研究许可证显示,其规定了 Phi -2 只能用于“非商业、非创收、研究目的”,而不是商业用途。因此,想要在其之上构建产品的企业就不走运了。
审核编辑:刘清
-
OpenAI宣布,发布了7.74亿参数GPT-2语言模型2019-09-01 3805
-
谷歌训练开发一个万亿参数的AI语言模型2021-01-18 2477
-
一个GPU训练一个130亿参数的模型2021-02-11 3286
-
浪潮、英伟达微软相继发布2500亿、5300亿参数的巨量模型,超过GPT-32021-10-18 4903
-
微软Phi-2 2.7B性能领先谷歌Gemini Nano-2 3.2B2023-12-13 1628
-
微软宣布推出一个27亿参数的语言模型Phi-22023-12-15 663
-
优于10倍参数模型!微软发布Orca 2 LLM2023-12-26 1384
-
微软发布phi-3AI模型,性能超越GPT-3.52024-04-23 1349
-
NVIDIA加速微软最新的Phi-3 Mini开源语言模型2024-04-28 2236
-
微软自研5000亿参数大模型曝光2024-05-08 1034
-
微软发布视觉型AI新模型:Phi-3-vision2024-05-27 1491
-
微软发布PhI-3-Vision模型,提升视觉AI效率2024-05-28 1239
-
在英特尔酷睿Ultra7处理器上优化和部署Phi-3-min模型2024-08-30 2439
-
谷歌与耶鲁大学合作发布最新C2S-Scale 27B模型2025-11-06 1263
-
瑞芯微(EASY EAI)RV1126B AI模型转换2026-05-13 483
全部0条评论

快来发表一下你的评论吧 !
