

把数据缓存到文件系统有哪些优势
描述
1 背景
在读完kafka官方文档,kafka设计里的持久化一章后,给我的第一印象是内容很抽象,于是草拟和总结了给个副标题,并把相关内容进行了归类;有些生涩的句子,尽量用大白话和举例进行说明,并加入了总结。
2 磁盘IO速度的快和慢,不取决我们的主观认知,而是由我们的使用方式决定的
kafka 里消息的缓存和存储,严重依赖文件系统。(根据上下文推测,这里的缓存消息和存储消息,指的是broker端 缓存和存储消息)
在我们普遍的认知里,都觉得“磁盘IO速度是非常慢的”,这种固有的观点,使得人们怀疑持久性结构是否能够提供竞争性的性能。
(和其它MQ中间件相对,你把数据 存入到磁盘上,还有性能上的优势吗?)
但实际上,磁盘速度,取决于他们的使用方式,设计得当的磁盘结构往往可以和网络一样快。
从顺序写数据到磁盘的角度分析 ------顺序写磁盘,比随机访问内存的速度还快
事实上 关于磁盘性能,在过去十年中,硬盘驱动器的吞吐量与磁盘寻道的延迟一直存在差异。
在具有六个 7200rpm SATA RAID-5 阵列的 JBOD 配置上,线性写入性能约为 600MB/秒,但随机写入性能仅为约 100k/秒,相差超过 6000 倍。
这些线性读取和写入是所有使用模式中最可预测的,并且经过操作系统的大力优化。现代操作系统提供预读和后写技术,以大块倍数预取数据,并将较小的逻辑写入分组为较大的物理写入。
有关此问题的进一步讨论可以在这篇 ACM Queue 文章中找到;他们实际上发现顺序磁盘访问在某些情况下比随机内存访问更快!如下图所示:
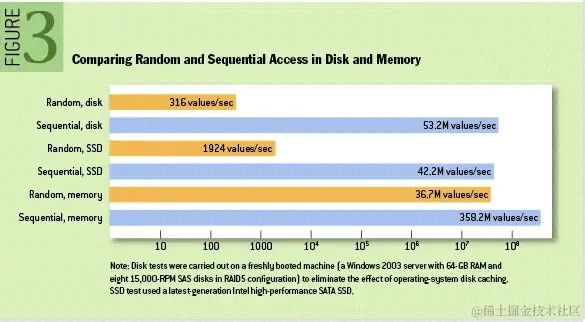
从磁盘读写数据的角度 ------使用磁盘缓存,加速磁盘读写速度
为了弥补这种性能差异,现代操作系统在使用主内存进行磁盘缓存方面变得越来越积极。
现代操作系统将所有空闲内存快乐地用于磁盘缓存,当内存被回收时几乎没有性能损失。
所有磁盘读写都将通过这个统一缓存进行。
这个特性很难关闭,即使进程在进程内保持数据缓存,这些数据也可能会在OS页面缓存中重复存储,实际上将所有东西存储两次。
(日常 数据在写入磁盘时,并没有刷新到磁盘上,只是写到了磁盘缓存里,而磁盘缓存其实是操作系统的主内存;即把数据写入文件的时候,其实还是写到内存中)
图 kafka broker端 数据写入过程
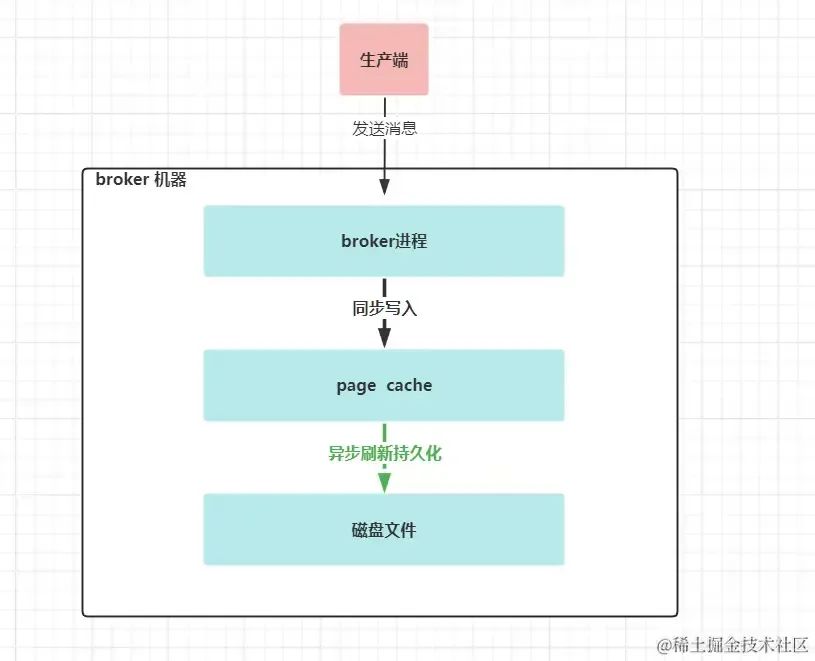
kafka在写入数据到文件系统时,同步写入到pagecache,异步刷新并持久化到磁盘里。
3 把数据缓存到JVM有哪些劣势了?
kafka构建在JVM之上,任何花费过时间了解过 Java内存使用的人都知道两件事:
对象的内存开销很高,通常会使存储的数据大小翻倍(或更糟)。(即原数据可能只有1K大小,但是转换为java对象,可能要3K)
随着堆内数据的增加,Java垃圾回收变得越来越繁琐和慢。(jvm里缓存的数据,会放到堆内存中;随这数据越来越多,达到GC的临界点会越来越快,导致GC越来越频繁 ;这样就会导致系统会把资源用于GC,而不是业务处理了)
4 把数据缓存到文件系统有哪些优势了?
使用文件系统并依赖页面缓存方式,比维护内存中缓存或其他结构要更优 。主要原因:
相对于把数据缓存到jvm中,直接使用操作系统页面缓存,可让程序能使用的缓存加倍。(因为jvm 对象的内存开销很高,他会膨胀。1K的数据放入到页面缓存还是1K;但是转换为JVM对象,可能就占用了3K空间)
把消息数据使用字节结构并且压缩的方式进行存储,比单个对象的存储更节约空间,并且还可能进一步带来缓存内存的加倍使用。
这样做即使在 32GB 机器上也可产生高达 28-30GB 的缓存,而不会造成 GC 损失。(---即使缓存中的数据变大,也不会带来频繁的GC)
即使kafka 服务重新启动,此缓存也将保持热状态。(页面缓存中数据还在,因为kafka进程重新,而操作系统可能不会重启) 而如果把数据放入到进程内缓存,kafka服务重启时将需要在内存中重建(对于 10GB 缓存可能需要 10 分钟),否则它将需要以完全冷的缓存启动 (这可能意味着糟糕的初始性能)。
极大地简化了代码,因为用于维护缓存和文件系统之间一致性的所有逻辑现在都在操作系统中,这往往比一次性进程内尝试更有效、更正确。
如果您的磁盘使用有利于顺序读取的方式,那么操作系统的预读实际上是在每次磁盘读取时使用有用的数据预先填充此缓存。
(这里涉及到操作系统读取磁盘上的数据时的一种优化---预读。即往磁盘里读一行数据,操作系统实际上是把这一行数据,和他后面的5K数据,都会一次性读出来,放入到缓存里。这对于kafka这种顺序消费消息的模式,非常适用,因为多读出来的数据,其实在后续消费的时候,是需要的,这避免了重复从硬盘多次读取数据,非常类似于一次性加载大块的数据到内存中;然后还没有浪费内存空间,因为这些数据后续马上也是需要被消费者消费的)
5 kafka 以文件系统进行存储和缓存的设计建议
我们不是在内存中保留尽可能多的内容,而是在空间不足时将其全部刷新到文件系统,而是将其反转。所有数据都会立即写入文件系统上的持久日志,而不必刷新到磁盘。实际上,这仅仅意味着它被转移到内核的页面缓存中
(我们不会把数据 缓存到jvm进程内存里,当空间不足时,再刷新到缓存里;而是采用了相反的方式:即所有数据会立即写入到文件系统里,即磁盘缓存里(即页缓存里),但不会写入后马上刷新数据到磁盘里)
============以下为个人总结和观点==============
6 kafka 这种同步写文件缓存,异步顺序刷新数据到磁盘的方式就不怕,操作系统挂了,数据会丢失吗?
如果page cache在持久化到磁盘前,broker进程宕机了,这个时候不会丢失消息,重启broker即可;如果此时操作系统宕机或者物理机宕机了,page cache里的数据还没有持久化到磁盘里,此种情况数据就丢了。
kafka应对此种情况,建议是通过多副本机制来解决的,核心思想也挺简单的:如果数据保存在一台机器上你觉得可靠性不够,那么我就把相同的数据保存到多台机器上,某台机器宕机了可以由其它机器提供相同的服务和数据。 更加详细的配置 请看《kafka 消息“零丢失”的配方》 broker端丢失消息的情况和解决方法一节
7 那能不能自己控制这个数据刷盘行为了?
可以的,在kafka的官方配置文档里有两个参数:
log.flush.interval.messages 和 log.flush.interval.ms
一个控制消息量达到了多少,一个控制间隔时间多少;会把页缓存里消息刷新到磁盘里;但这个控制刷盘行为也是异步的
8 总结
1、kafka broker端会把文件系统,做为消息缓存和存储;因为操作系统在写数据到磁盘时,已进行了优化
2、kafka broker 在写入数据到文件系统时,同步写入到磁盘缓存里(即内存里),异步把缓存中的数据写入到磁盘里。这是kafka 写数据到文件系统高效的主要原因,也是核心业务 写数据主流程 高效的主原因;异步顺序刷新数据到磁盘里,我觉得是性能高的次要原因,毕竟不阻塞到主流程
3、kafka 作为消息系统,天生就是顺序写入数据到文件系统,并顺序读取文件系统的,这种天然的顺序性,恰好可以利用操作系统的预读功能:即一次磁盘IO 读取数据时,会把数据附近其他磁盘数据也读写到内存中;下一次读取下一条消息时,不需要磁盘IO了,直接从内存中获取数据,减少磁盘IO 这种非常慢的读取次数,加速取数过程。
审核编辑:汤梓红
-
如何正确选择嵌入式文件系统?2025-03-17 1413
-
Linux的文件系统特点2023-11-09 2597
-
如何把文件系统烧到EMMC并从EMMC加载2023-10-30 5976
-
谈谈什么是文件系统 文件系统的功能与特点2023-08-30 4609
-
适用于Linux的最佳通用文件系统 Linux文件系统的安装2023-08-03 932
-
Linux的文件系统及文件缓存的知识点2023-02-13 1756
-
根文件系统有何功能2021-12-15 1030
-
FATFS文件系统详解2021-11-29 1718
-
xv6的文件系统是如何实现的2021-10-12 3639
-
文件系统是什么?浅谈EXT文件系统历史2018-06-28 6376
-
Ceph文件系统的数据缓存备份2018-02-08 1204
-
SPI—外部FLASH文件系统2017-12-13 2137
-
NTFS文件系统,NTFS文件系统是什么意思2010-03-29 6702
-
Linux文件系统课程2009-04-10 577
全部0条评论

快来发表一下你的评论吧 !
