

单目深度估计开源方案分享
描述
0. 笔者个人体会
单目深度估计网络可以估计RGB图像的稠密深度图,但大家可以发现大多数模型的深度图并不准确,尤其是物体边界的深度值非常模糊。而且很多深度估计模型只能处理分辨率很小的图像,图像一大就模糊。这就会导致SLAM/SfM等任务生成的3D场景的物体边界质量非常差。
今天笔者将为大家分享一项最新的开源工作PatchFusion,可以产生极高分辨率的单目深度图,还可以助力之前的SOTA方案ZoeDepth等网络涨点!
1. 效果展示
可以看一下单目深度估计效果,这个深度图的分辨率是真的高,物体边界分割的非常干净!


2. 具体原理是什么?
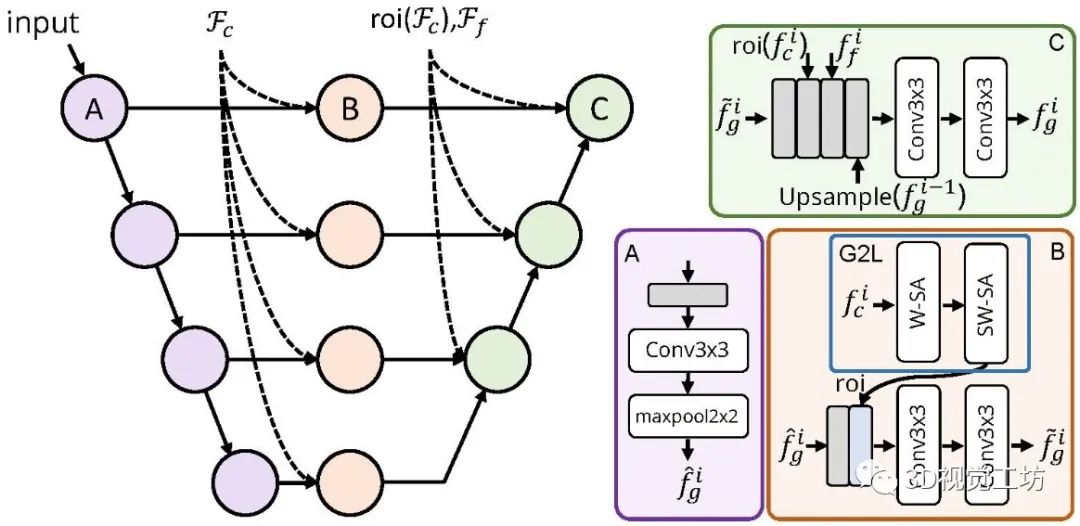
PatchFusion是基于图块的框架,具有三个关键组件:
(1)patch式融合网络,通过高层将全局一致的粗略预测与更精细、不一致的图块预测融合到一起;
(2) 全局到局部 (G2L) 模块,为融合网络添加重要上下文,无需patch选择启发式方法;
(3) 一致性感知训练 (CAT) 和推理 (CAI) 方法,强调patch重叠一致性,从而消除后处理。
3. 和其他SOTA方法对比如何?
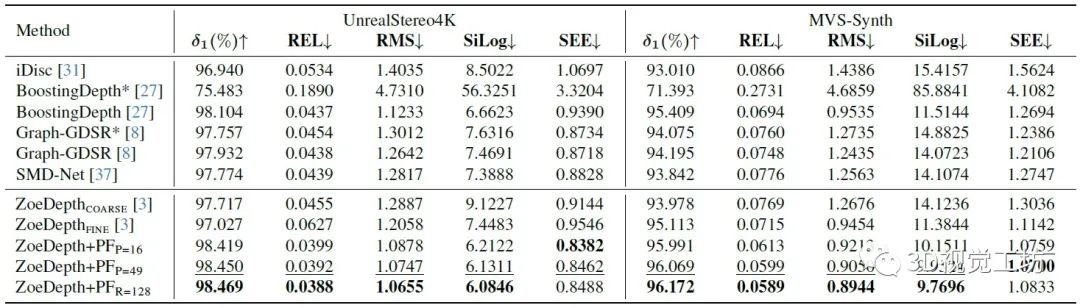
分别在UnrealStereo4K、MVS-Synth 和 Middleburry 2014 上做了实验,证明PatchFusion可以生成具有复杂细节的高分辨率深度图。
更重要的一点是,PatchFusion可以增强之前的SOTA方案 ZoeDepth,在 UnrealStereo4K 和 MVS-Synth 上的均方根误差 (RMSE)分别提高了 17.3% 和 29.4%。
审核编辑:黄飞
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Firefly RK3399Pro开源主板 + 单目摄像头,人体特征点检测方案2022-04-01 2745
-
基于单目深度估计的红外图像彩色化方法_戈曼2017-03-17 696
-
基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度2018-06-04 36460
-
采用自监督CNN进行单图像深度估计的方法2021-04-27 1296
-
基于几何单目3D目标检测的密集几何约束深度估计器2022-10-09 1982
-
一种用于自监督单目深度估计的轻量级CNN和Transformer架构2023-03-14 4072
-
介绍第一个结合相对和绝对深度的多模态单目深度估计网络2023-03-21 8948
-
一种利用几何信息的自监督单目深度估计框架2023-11-06 1156
-
动态场景下的自监督单目深度估计方案2023-11-28 1628
-
【AIBOX 应用案例】单目深度估计2025-03-19 1382
-
双目视觉是如何实现深度估计的?2025-12-31 833
全部0条评论

快来发表一下你的评论吧 !
