

Pod一直处于Pending状态?什么是Pod拓扑约束?
描述
起因: 今天在部署组件的时候,发现组件的pod一直处于Pending状态,报错显示的原因是:不满足Pod拓扑分布约束,看了代码发现是原来同事给组件新增了Pod拓扑约束。对于Pod拓扑约束,我先前并没有认真了解过,刚好可以借这个排查问题的机会深入了解什么是Pod拓扑约束。
文档参考主要是上述两篇k8s官方的文档,建议英文功底好的可以直接看第二篇文档。
topologySpreadConstraints是一个Pod Spec层级的字段,其定义的结构体如下:
spec: topologySpreadConstraints: - maxSkew:topologyKey: whenUnsatisfiable: labelSelector:
在官方文档里还描述了许多beta特性的字段,但如果是刚上手Pod拓扑约束的小伙伴,可以从这上面的四个基本字段入手,先把这四个字段的含义吃透。
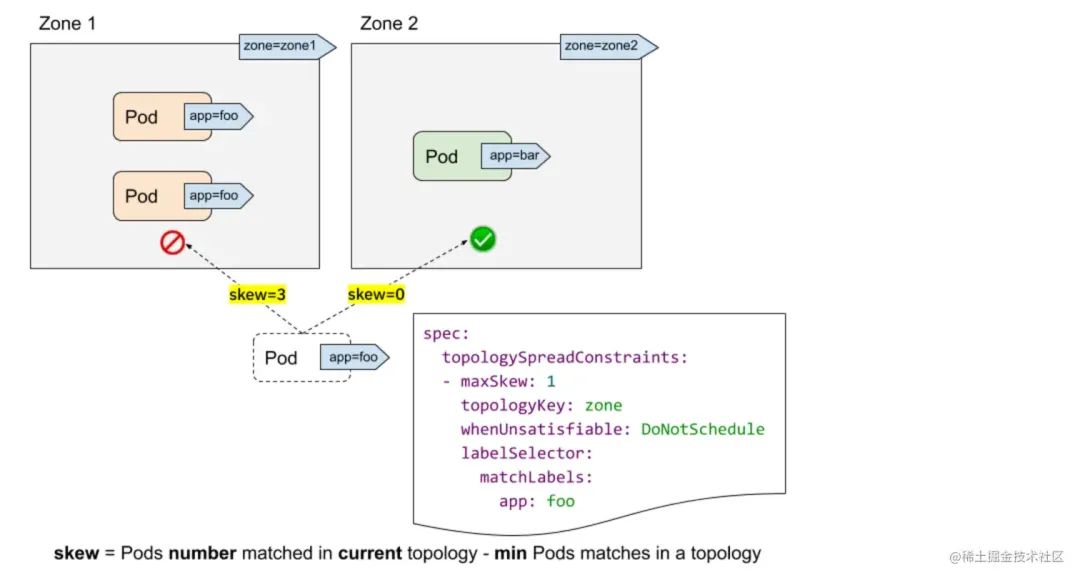
labelSelector:labelSelector是用来寻找匹配标签的Pod,对于每一个拓扑域来说,k8s调度器会计算其中匹配labelSelector的Pod数量。在上图中,我们定义的拓扑约束只针对含有label app=foo的Pod生效。
topologyKey:topologyKey用于一个拓扑域,这个值通常情况下是定义在节点上的标签。在上图中,我们定义的拓扑域就是zone,也就是含有zone这个label的节点才算在我们的拓扑域中。
maxSkew:maxSkew指的就是Pod分布在不同的拓扑域中的数量差异。maxSkew要求其设定的值大于0,其值越小,说明我们期望Pod能够越均衡地打散分布在拓扑域中,其值越大,则反之。在上图中,如果新的Pod调度到Zone1中,则Zone1和Zone2的skew就是3-0=3,如果新的Pod调度到Zone2中,则Zone1和Zone2的skew就是2-1=1.
whenUnsatisfiable:whenUnsatisfiable指当skew不满足maxSkew时,调度器会执行的动作,可选值为:
DoNotSchedule:(默认值)不调度。
ScheduleAnyway:仍然调度,但会趋向于调度到使skew最小的拓扑域中。
了解到这里,我就已经排查出来调度不上去的原因了:集群是一个两节点的集群(1master+1worker),但这两个节点属于同一个可用区,但有一点奇怪的是,按照算法,应该会有一个Pod调度上去,另一个Pod处于Pending状态,但现实却是两个Pod都处于Pending状态。继续看代码,我发现了同事不仅用了topologySpreadConstraints,还结合了亲和性反亲和性一起使用。
Pod拓扑约束可以结合亲和和反亲和特性一起使用,达到更丰富的效果,以实际业务场景中的代码为例:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app.kubernetes.io/name: app-server
topologyKey: kubernetes.io/hostname
schedulerName: default-scheduler
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedulable
labelSelector:
matchLabels:
app.kubernetes.io/instance: app-server
app.kubernetes.io/name: app-server
可以看到,我们设置了Pod 反亲和性,禁止符合条件的Pod调度到同一个节点上(可能是出于容灾或其他方面的考虑),再看Pod拓扑约束,要求Pod均匀地分布在每个可用区中,且每个可用区之间符合条件的Pod的数量差值最大为1,如果不满足的条件下,禁止调度。(强打散Pod到每个可用区中,可能是出于网络带宽,cpu内存等资源角度的考虑)。
因此,在仅有两个节点的集群中,且这两个节点还是属于同一个可用区的情况下,无法满足上述的调度条件,因此两个Pod均处于Pending状态。
解决方式有两种,可以设置maxSkew的值为2,或者设置whenUnsatisfiable的值为ScheduleAnyway。
链接:https://juejin.cn/post/7245179553886486584
审核编辑:刘清
-
Pod资源配置2019-10-22 1791
-
Land Pattern and POD2021-03-05 766
-
Kubernetes组件pod核心原理2021-09-02 2708
-
pod底层网络和数据存储是如何进行的2021-09-24 2527
-
如何利用Docker实现Pod2022-11-14 1965
-
Kubernetes中的Pod简易理解2023-02-15 2350
-
什么是CNI,基于Calico的Pod网络介绍2023-04-20 4490
-
POD到底是什么?聊聊POD2023-06-19 9008
-
如何快速查看Kubernetes Pod崩溃前的日志2023-07-06 2500
-
Pod是如何在底层实现的?如何使用Docker创建Pod?2023-08-14 2295
-
Kubernetes Pod常用管理命令详解2025-02-17 1845
-
详解Kubernetes中的Pod调度亲和性2025-06-07 1219
-
Kubernetes Pod异常问题排查实战2026-03-18 561
-
Kubernetes Pod启动失败的各种场景及其排障方法2026-04-13 252
-
Kubernetes中Pod一直Pending无法启动的故障排查2026-05-28 252
全部0条评论

快来发表一下你的评论吧 !
