

如何保证kafka消息不丢失
描述
如果在简历上写了使用过kafka消息中间件,面试官大概80%的概率会问你:"如何保证kafka消息不丢失?"反正我是屡试不爽。
如果你的核心业务数据,比如订单数据,或者其它核心交易业务数据,在使用kafka时,要保证消息不丢失,并让下游消费系统一定能获得订单数据,只靠kafka中间件来保证,是并不可靠的。
kafka已经这么的优秀 了,为什么还会丢消息了?这一定是初学者或者初级使用者心中的疑惑
kafka 已经这么的优秀了,为啥还会丢消息了?----太不省心了
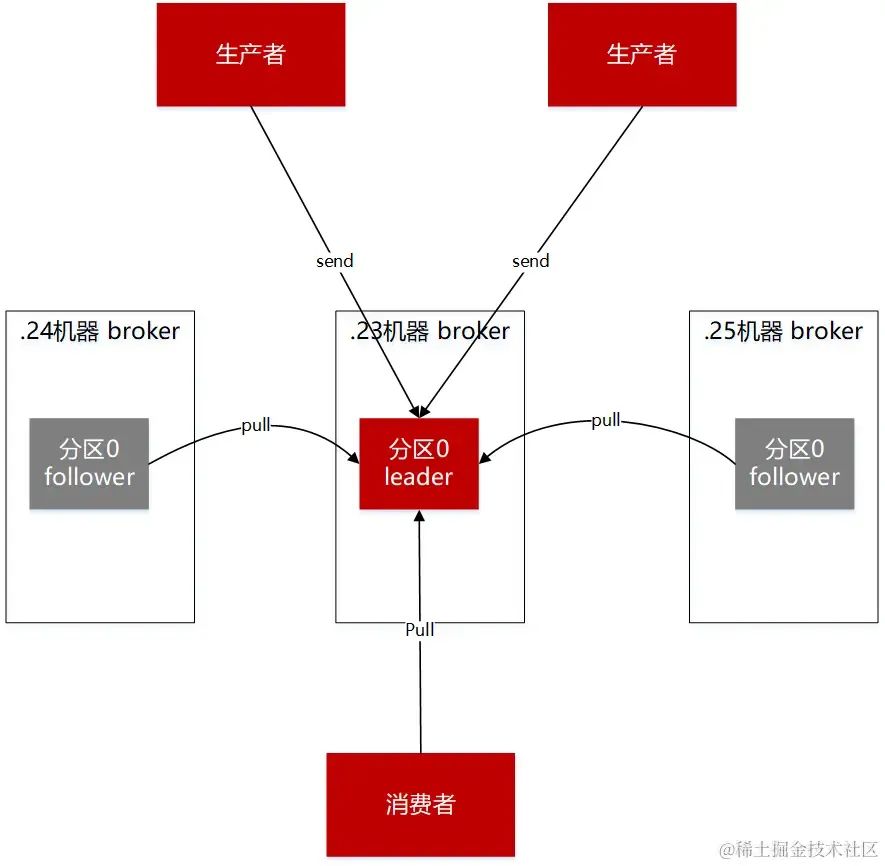
图一 生产者,broker,消费者
要解决kafka丢失消息的情况,需要从使用kafka涉及的主流程和主要组件进行分析。kafka的核心业务流程很简单:发送消息,暂存消息,消费消息。而这中间涉及到的主要组件,分别是生产端,broker端,消费端。
生产端丢失消息的情况和解决方法
生产端丢失消息的第一个原因主要来源于kafka的特性:批量发送异步提交。我们知道,kafka在发送消息时,是由底层的IO SEND线程进行消息的批量发送,不是由业务代码线程执行发送的。即业务代码线程执行完send方法后,就返回了。消息到底发送给broker侧没有了?通过send方法其实是无法知道的。
那么如何解决了?kafka提供了一个带有callback回调函数的方法,如果消息成功/(失败的)发送给broker端了,底层的IO线程是可以知道的,所以此时IO线程可以回调callback函数,通知上层业务应用。我们也一般在callback函数里,根据回调函数的参数,就能知道消息是否发送成功了,如果发送失败了,那么我们还可以在callback函数里重试。一般业务场景下 通过重试的方法保证消息再次发送出去。
90%的面试者都能给出上面的标准回答。
但在一些严格的交易场景:仅仅依靠回调函数的通知和重试,是不能保证消息一定能发送到broker端的
理由如下:
1、callback函数是在jvm层面由IO SEND线程执行的,如果刚好遇到在执行回调函数时,jvm宕机了,或者恰好长时间的GC,最终导致OOM,或者jvm假死的情况;那么回调函数是不能被执行的。恰好你的消息数据,是一个带有交易属性核心业务数据,必须要通知给下游。比如下单或者支付后,需要通知佣金系统,或者积分系统,去计算订单佣金。此时一个JVM宕机或者OOM,给下游的数据就丢了,那么计算联盟客的订单佣金数据也就丢了,造成联盟客资损了。
2、IO SEND线程和broker之间是通过网络进行通信的,而网络通信并不一定都能保证一直都是顺畅的,比如网络丢包,网络中的交换机坏了,由底层网络硬件的故障,导致上层IO线程发送消息失败;此时发送端配置的重试参数 retries 也不好使了。
如何解决生产端在极端严格的交易场景下,消息丢失了?
如果要解决jvm宕机,或者JVM假死;又或者底层网络问题,带来的消息丢失;是需要上层应用额外的机制来保证消息数据发送的完整性。大概流程如下图
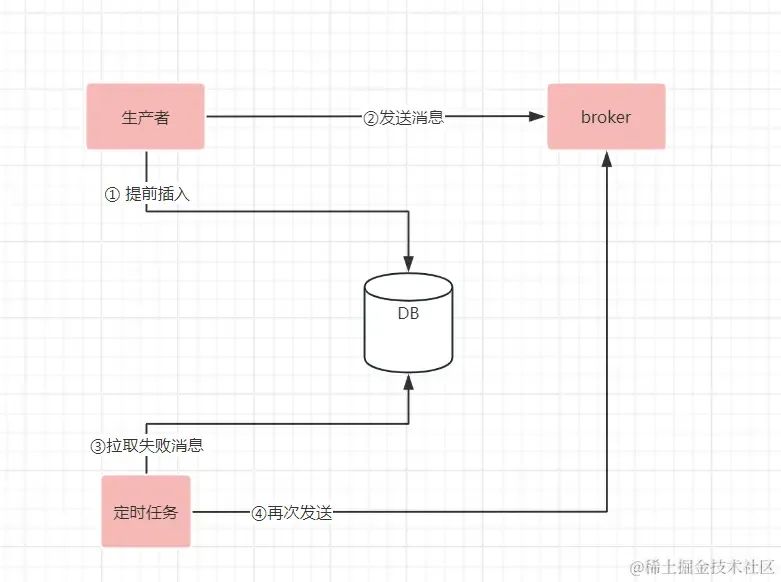
1、在发送消息之前,加一个发送记录,并且初始化为待发送;并且把发送记录进行存储(可以存储在DB里,或者其它存储引擎里);2、利用带有回调函数的callback通知,在业务代码里感知到消息是否发送成功;如果消息发送成功,则把存储引擎里对应的消息标记为已发送 3、利用延迟的定时任务,每隔5分钟(可根据实际情况调整扫描频率)定时扫描5分钟前未发送或者发送失败的消息,再次进行发送。
这样即使应用的jvm宕机,或者底层网络出现故障,消息是否发送的记录,都进行了保存。通过持续的定时任务扫描和重试,能最终保证消息一定能发送出去。
broker端丢失消息的情况和解决方法
broker端接收到生产端的消息后,并成功应答生产端后,消息会丢吗? 如果broker能像mysql服务器一样,在成功应答给客户端前,能把消息写入到了磁盘进行持久化,并且在宕机断电后,有恢复机制,那么我们能说broker端不会丢消息。
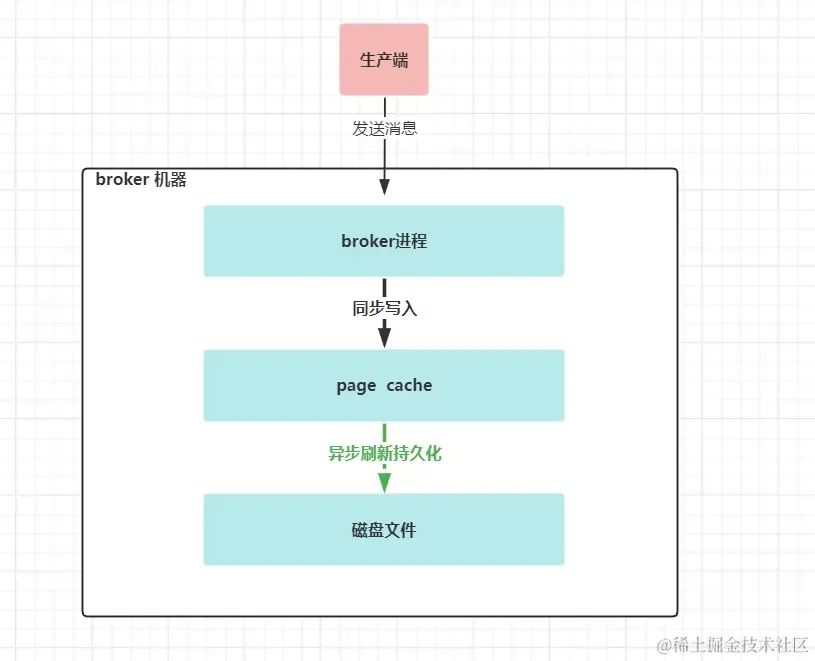
但broker端提供数据不丢的保障和mysql是不一样的。broker端在接受了一批消息数据后,是不会马上写入磁盘的,而是先写入到page cache里,这个page cache是操作系统的页缓存(也就是另外一个内存,只是由操作系统管理,不属于JVM管理的内存),通过定时或者定量的的方式( log.flush.interval.messages和log.flush.interval.ms)会把page cache里的数据写入到磁盘里。
如果page cache在持久化到磁盘前,broker进程宕机了,这个时候不会丢失消息,重启broker即可;如果此时操作系统宕机或者物理机宕机了,page cache里的数据还没有持久化到磁盘里,此种情况数据就丢了。
kafka应对此种情况,建议是通过多副本机制来解决的,核心思想也挺简单的:如果数据保存在一台机器上你觉得可靠性不够,那么我就把相同的数据保存到多台机器上,某台机器宕机了可以由其它机器提供相同的服务和数据。
要想达到上面效果,有三个关键参数需要配置
第一:生产端参数 ack 设置为all
代表消息需要写入到“大多数”的副本分区后,leader broker才给生产端应答消息写入成功。(即写入了“大多数”机器的page cache里)
第二:在broker端 配置 min.insync.replicas参数设置至少为2
此参数代表了 上面的“大多数”副本。为2表示除了写入leader分区外,还需要写入到一个follower 分区副本里,broker端才会应答给生产端消息写入成功。此参数设置需要搭配第一个参数使用。
第三:在broker端配置 replicator.factor参数至少3
此参数表示:topic每个分区的副本数。如果配置为2,表示每个分区只有2个副本,在加上第二个参数消息写入时至少写入2个分区副本,则整个写入逻辑就表示集群中topic的分区副本不能有一个宕机。如果配置为3,则topic的每个分区副本数为3,再加上第二个参数min.insync.replicas为2,即每次,只需要写入2个分区副本即可,另外一个宕机也不影响,在保证了消息不丢的情况下,也能提高分区的可用性;只是有点费空间,毕竟多保存了一份相同的数据到另外一台机器上。
另外在broker端,还有个参数unclean.leader.election.enable
此参数表示:没有和leader分区保持数据同步的副本分区是否也能参与leader分区的选举,建议设置为false,不允许。如果允许,这这些落后的副本分区竞选为leader分区后,则之前leader分区已保存的最新数据就有丢失的风险。注意在0.11版本之前默认为TRUE。
消费端侧丢失消息的情况和解决方法
消费端丢失消息的情况:消费端丢失消息的情况,主要是设置了 autoCommit为true,即消费者消费消息的位移,由消费者自动提交。
自动提交,表面上看起来挺高大上的,但这是消费端丢失消息的主要原因。实例代码如下
while(true){
consumer.poll(); #①拉取消息
XXX #②进行业务处理;
}
如果在第一步拉取消息后,即提交了消息位移;而在第二步处理消息的时候发生了业务异常,或者jvm宕机了。则第二次在从消费端poll消息时,会从最新的位移拉取后面的消息,这样就造成了消息的丢失。
消费端解决消息丢失也不复杂,设置autoCommit为false;然后在消费完消息后手工提交位移即可 实例代码如下:
while(true){
consumer.poll(); #①拉取消息
XXX #②处理消息;
consumer.commit();
}
在第二步进行了业务处理后,在提交消费的消息位移;这样即使第二步或者第三步提交位移失败了又或者宕机了,第二次再从poll拉取消息时,则会以第一次拉取消息的位移处获取后面的消息,以此保证了消息的不丢失。
总结
在生产端所在的jvm运行正常,底层网络通顺的情况下,通过kafka 生产端自身的retries机制和call back回调能减少一部分消息丢失情况;但并不能保证在应用层,网络层有问题时,也能100%确保消息不丢失;如果要解决此问题,可以试试 记录消息发送状态+定时任务扫描+重试的机制。
在broker端,要保证消息数据不丢失;kafka提供了多副本机制来进行保证。关键核心参数三个,一个生产端ack=all,两个broker端参数min.insync.replicas 写入数据到分区最小副本数为2,并且每个分区的副本集最小为3
在消费端,要保证消息不丢失,需要设置消费端参数 autoCommit为false,并且在消息消费完后,再手工提交消息位置
审核编辑:汤梓红
-
kafka设计原理的深度探讨2020-10-08 2923
-
kafka数据可靠性深度解读2018-05-08 2853
-
流水线设计提高数据处理有没有办法保证数据不丢失?2018-08-16 2759
-
sja1000跟51外部中断只能保证8帧不丢失2019-04-29 1811
-
基于发布与订阅的消息系统Kafka2020-03-05 1875
-
Kafka基础入门文档2020-03-12 1281
-
Kafka集群环境的搭建2021-01-05 1290
-
基于臭氧的Kafka自适应调优方法ENLHS2021-05-13 734
-
Kafka的概念及Kafka的宕机2021-08-27 3300
-
Kafka 的简介2023-07-03 1518
-
物通博联5G-kafka工业网关实现kafka协议对接到云平台2023-07-11 1588
-
Kafka架构技术:Kafka的架构和客户端API设计2023-10-10 3338
-
kafka基本原理详解2024-01-03 1863
-
面试官:Kafka会丢消息吗?2024-04-29 1884
-
Kafka生产环境应用方案2025-07-09 776
全部0条评论

快来发表一下你的评论吧 !
