

一个用于6D姿态估计和跟踪的统一基础模型
描述
0. 笔者个人体会
今天笔者将为大家分享NVIDIA的最新开源方案FoundationPose,是一个用于 6D 姿态估计和跟踪的统一基础模型。只要给出CAD模型或少量参考图像,FoundationPose就可以在测试时立即应用于新物体,无需任何微调,关键是各项指标明显优于专为每个任务设计的SOTA方案。
下面一起来阅读一下这项工作,文末附论文和代码链接~
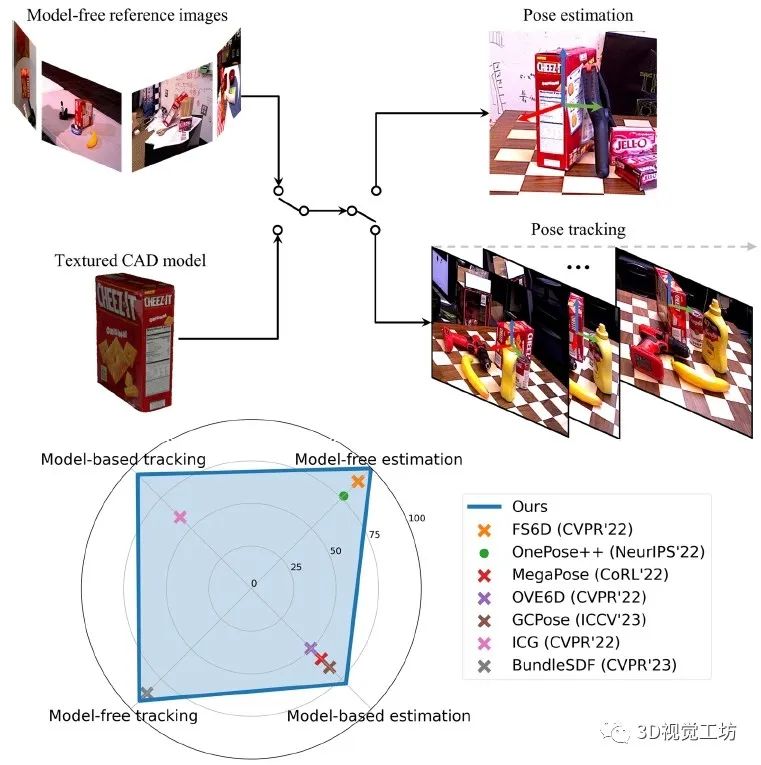
1. 效果展示
FoundationPose实现了新物体的6D姿态估计和跟踪,支持基于模型和无模型设置。在这四个任务中的每一个上,FoundationPose都优于专用任务的SOTA方案。(·表示仅RGB,×表示RGBD)。这里也推荐工坊推出的新课程《单目深度估计方法:算法梳理与代码实现》。
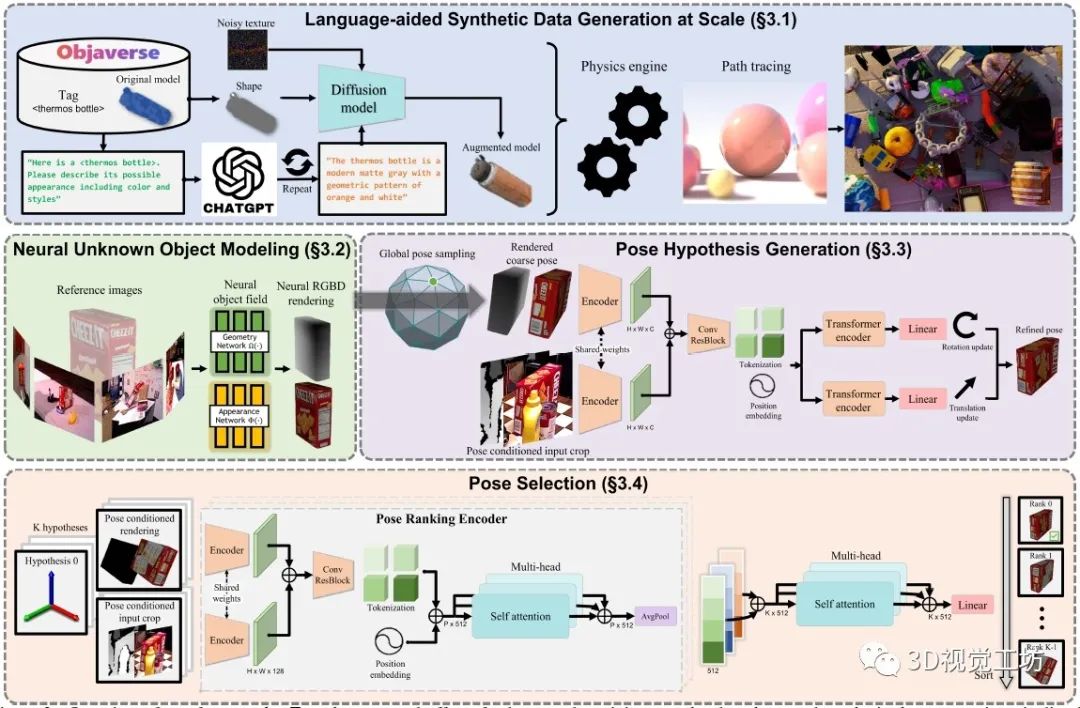
2. 具体原理是什么?
为减少大规模训练的人工工作,FoundationPose利用3D模型数据库、大型语言模型和扩散模型等新技术,开发了一种新的合成数据生成Pipeline。为了弥补无模型和基于模型的设置之间的差距,FoundationPose利用以对象为中心的神经场来进行随后的渲染和新视图RGBD渲染。
对于姿态估计,首先在物体周围均匀地初始化全局姿态,然后通过细化网络对其进行细化。最后将改进的位姿转发给姿态选择模块,预测位姿的分数,输出得分最高的位姿。
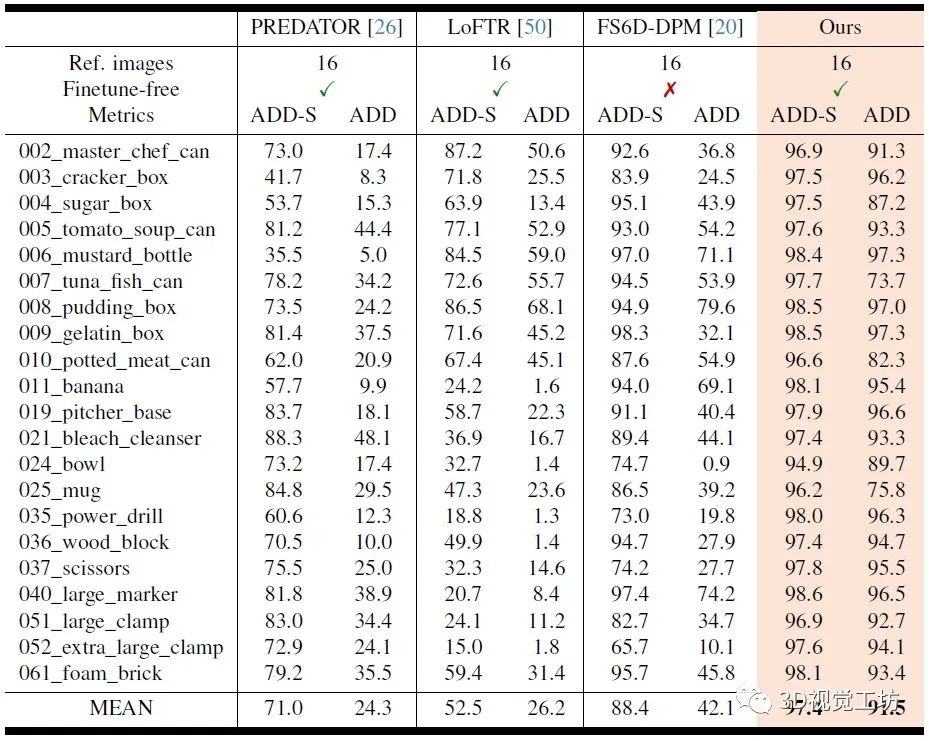
3. 和其他SOTA方法对比如何?
YCB-Video数据集上Model-free方案的位姿估计定量结果对比。
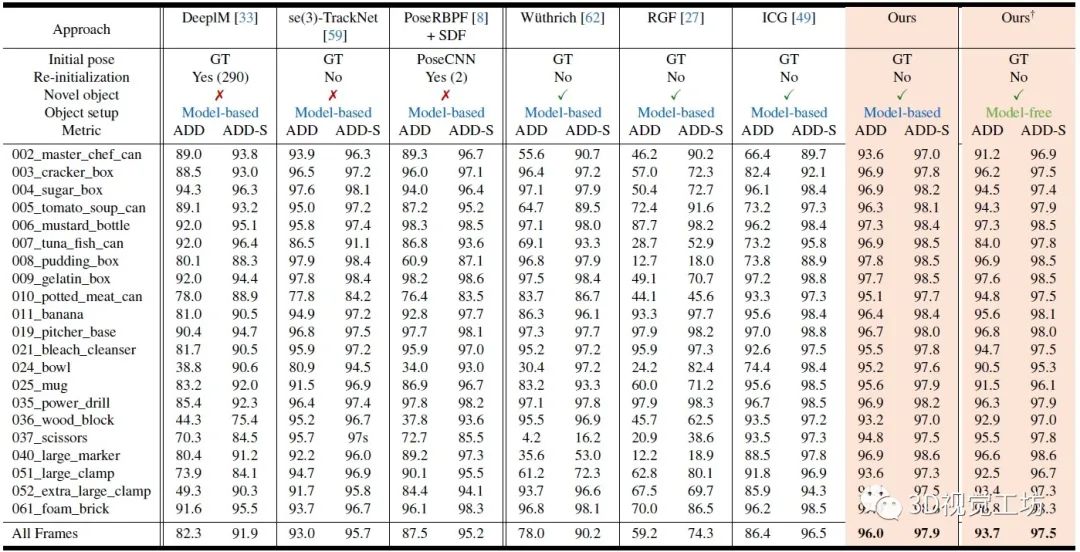
YCB-Video数据集上位姿跟踪的定量对比。这里也推荐工坊推出的新课程《单目深度估计方法:算法梳理与代码实现》。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
4. 论文信息
标题:FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
作者:Bowen Wen, Wei Yang, Jan Kautz, Stan Birchfield
机构:NVIDIA
原文链接:https://arxiv.org/abs/2312.08344
代码链接:https://github.com/NVlabs/FoundationPose
审核编辑:刘清
-
【爱芯派 Pro 开发板试用体验】人体姿态估计模型部署前期准备2024-01-01 1818
-
佳能6D2最新消息:佳能6D Mark II规格曝光 比现款6D大2017-05-31 8847
-
时隔五年终于等到你佳能EOS 6D Mark II!佳能6D2规格配置价格一览2017-06-29 13189
-
来聊一聊佳能EOS 6D Mark II的发布 佳能EOS 6D Mark II值得买吗?2017-07-13 6126
-
一种基于深度神经网络的迭代6D姿态匹配的新方法2018-09-28 4774
-
亚太6D卫星基本满足了卫星出厂条件2020-03-27 4824
-
3D姿态估计 时序卷积+半监督训练2020-12-08 1796
-
基于OnePose的无CAD模型的物体姿态估计2022-08-10 2552
-
一种基于去遮挡和移除的3D交互手姿态估计框架2022-09-14 1710
-
无需实例或类级别3D模型的对新颖物体的6D姿态追踪2023-01-12 2722
-
基于PoseDiffusion相机姿态估计方法2023-07-23 2841
-
AI深度相机-人体姿态估计应用2023-07-31 2238
-
基于MMPose的姿态估计配置案例2023-09-15 2247
-
基于飞控的姿态估计算法作用及原理2023-11-13 2577
-
一文读懂六自由度激光跟踪仪2023-12-12 1804
全部0条评论

快来发表一下你的评论吧 !
