

浅谈从FPGA到ASIC的人工智能芯片设计路
可编程逻辑
描述
黑芝麻智能芯片和架构副总裁何铁军、安谋科技智能物联及汽车业务线负责人赵永超、环宇智行联合创始人曹晶将在自动驾驶算力专场带来演讲,主题分别为《新一代智能汽车跨域计算芯片加速舱驾一体商业落地》、《高性能融合计算IP平台加速智能车芯发展》以及《高阶智驾时代需要怎样的算力平台?》。扫码报名~ 也许某团队正在为边缘计算设计一款嵌入式推理引擎,或者正在进行进一步的汽车视觉处理,也许在数据中心领域具备可以挑战英伟达和谷歌的洞察力!然而在广泛的性能需求、环境和应用中,人工智能加速器架构不仅在设计方面,而且在验证和实现方面都面临着独特的挑战。从一个体系架构到FPGA(在这个领域几乎是强制性的一步),再到生产ASIC,将是一段不平凡的历程。不过,对于有经验且有充分准备的设计团队来说,如果提前做好规划,这也未必就一定意味着是一次冒险!
01. 三个方向
如果像大多数研发团队一样,选择在FPGA中进行概念验证或验证平台,将从一开始就同时被拉往三个方向,具体如图1所示。架构师团队希望FPGA实现能够尽可能地接近他们的微体系架构,因为对他们来说,关键是要看设计如何有效地实现他们的算法。而软件团队将推动FPGA的性能设计优化,这意味着要对架构进行某种程度的折衷,以适应所选FPGA芯片的能力和局限性。此时,还必须考虑到来自市场营销方面的压力,如果他们计划想利用FPGA尽早进入市场的话。实际上还有一种风险,即概念验证本身会有自己的生命,就像弗兰肯斯坦生物(creature of Frankenstein)一样。
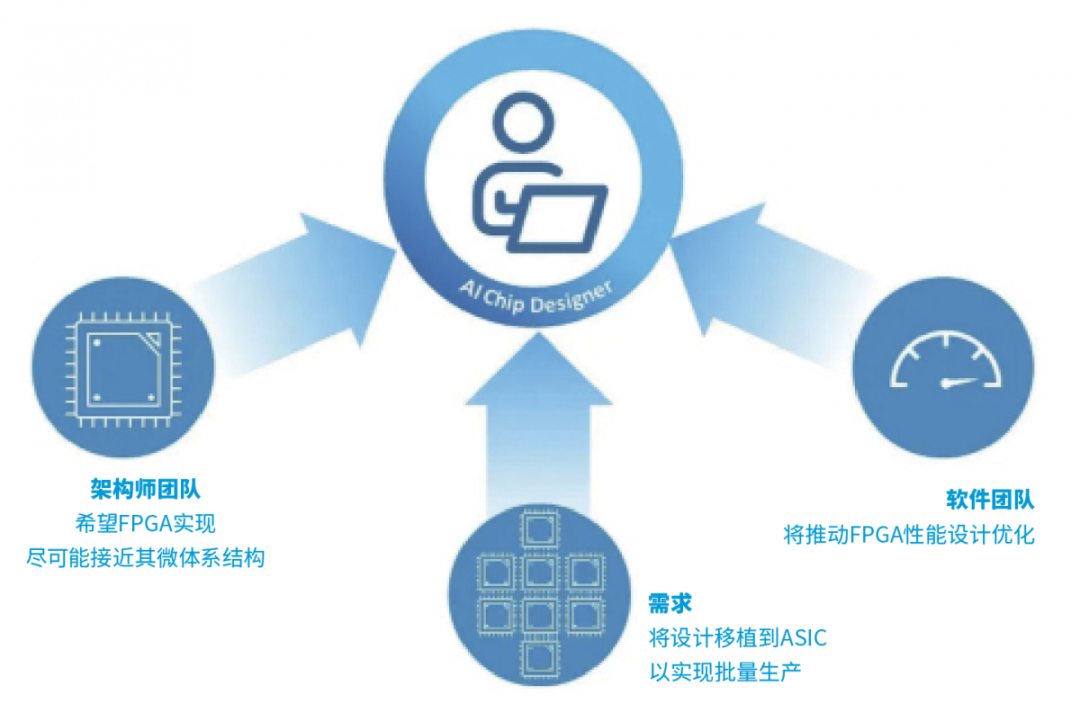
图1:如果选择在FPGA中进行概念验证或验证平台,将受到以下三个方向的拉力,分别来自:架构师团队、软件团队和制造需求。 如果设计的前两步分别是体系架构和FPGA设计,第三步则是需要将设计移植到ASIC以进行批量生产。这将为产品带来竞争力所需的性能、功率和面积。理想情况下,ASIC设计将准确反映原始理论架构,并结合对所选ASIC工艺和IP库的优化。不过,即便是通过转换经过验证的FPGA设计,但可以在多大程度上实现优异的ASIC设计,也仍是一个至关重要的问题。答案将归结于架构师团队、FPGA和ASIC团队合作的紧密程度。 能够支持这一说法的最好方式,也许就是充分研究各类人工智能加速器的架构特征,并在设计过程中予以遵循。
02. 并行处理
并行处理是最普遍的,也是AI加速器的基础。它可以通过许多阵列的小型专用处理内核(如特定算法的GPU)来实现,或者以数据流(即专用处理器的流水线)的方式来实现。不过,这两种体系架构都给FPGA的实现带来了诸多挑战。 设计团队在RTL中可以对处理单元及其互连进行编码,并将RTL移交给FPGA设计工具。不过,要获得一个具有足够器件资源利用率和性能的设计,通常几乎接近100%的布线、或至少在平面规划和布局方面需要进行人工干预。 需要注意的是,该规划将不关注加速器的原型架构,而是关注FPGA中资源的可用性和位置。例如,体系架构可能希望计算单元聚集在本地组中,然而,FPGA则可能需要将计算单元分散在芯片上,甚至将它们拆分成更小的块,以确保足够的路由和RAM资源。这可能需要改变互连体系架构,例如改变总线架构。
不过,也会出现其他选项。例如,深度学习推理加速器的架构师团队经常利用精度较低的算法(比如说,8位而不是32位),来提高速度并节省能源。而出于性能和资源的原因,FPGA团队可能希望利用FPGA的32位乘法累加硬宏,而不是由逻辑单元构建的8位乘法器。这样的选择将会逐渐使FPGA设计脱离原来的架构,并给转换过程带来影响。 至此,是时候将实现移植转换到ASIC中去了。
在小型、简单的SoC中,FPGA到ASIC的转换,意味着一个近乎机械式的逐步转换过程。剔除任何专用的FPGA功能,如乘法累加块、高速串行接口、PCIe接口和DRAM控制器。然后再用功能等效的ASIC IP对它们进行置换,并对内部总线或接口进行任何必要的更改,以实现它们之间的高效互联。再然后就是需要重新进行逻辑综合,并插入新的时钟网络和自检架构、分配电源和进行验证。
对人工智能加速器来说,这仍然有效。在FPGA中工作的任何实体,都可以通过这种方式转换到ASIC。然而,对于设计团队为优化FPGA设计所做的设计更改呢?答案是,由于ASIC中的逻辑和路由资源基本上是无限的,并且有大量的第三方IP库,这些专为FPGA所进行的更改将是不必要的,而且可能会出现适得其反的效果。 进行转换的团队必须了解原始设计意图,以便根据具体情况来决定是利用FPGA设计还是恢复到原始架构。对于确定综合哪种代码以及选择如何最好地利用IP来说,这肯定是正确的。
03. RAM
再举一个存储器的例子,可能对充分理解会有所帮助。由于存储器的并行架构,在处理单元内部或单元之间,人工智能加速器通常会利用许多具有不同形状、大小、类型和速度的小型RAM实例。这种做法完全符合ASIC设计的优势,但它可能会对FPGA造成严重破坏。虽然可以将单个FPGA逻辑单元组转换为逻辑架构内的小RAM,但在FPGA设计中,设计团队通常会利用大的、硬连接的、可配置的RAM块。这就给FPGA团队留下了两个选择:要么修改原始架构,即不是利用许多较小的RAM块,而是利用大型共享RAM块;要么是在FPGA的大块RAM周围设计一个wrapper,来模拟一批较小的实例,希望不会耗尽RAM块附近的路由资源。
图2:从FPGA到ASIC则提供了更多的选择。具体决策取决于对设计意图理解的清晰程度。 当需要从FPGA转换到ASIC时,则有更多的选择,具体如图2所示。转换团队是否应该对FPGA设计进行直接转换(在ASIC设计中实现FPGA的RAM块功能,这对于经验丰富的转换者不会有任何困难)?抑或是团队还应该恢复到具有许多分散RAM实例的原始体系架构(更小的RAM将更快、更节能,并可能恢复原始体系架构的数据流,从而消除可能的内存瓶颈)?但究竟如何决策,还取决于团队对设计意图的理解程度。
04. 多合一
还有一个问题,那就是多片FPGA问题。许多加速器设计对于单个FPGA来说太大,必须分布在多颗芯片上。于是,这些芯片之间的通信方式将对转换过程带来影响。 例如,如果FPGA通过高速并行总线(例如存储器总线)进行连接,则设计团队可以将FPGA的所有内容移植到ASIC中,再通过安排相同的并行总线进行连接,比如利用类似PCIe的接口来实现多片FPGA之间的连接。在这种情况下,设计团队将不得不移除PCI接口,并根据块之间数据流的性质,用直接并行连接或可能的片上网络来替换它们。回溯最初的体系架构,看看是否为了适应芯片间接口的插入(例如,通过插入大缓冲存储器或创建消息传递协议)而被更改,然后对这些更改进行排除,这一点也至关重要。
05. 密切合作
一旦功能设计被转换(translated),工作就可以进入时钟架构。这里再次指出,ASIC不受FPGA所施加的许多约束的影响。转换团队可以研究原始架构的操作理论,并充分利用其为本地时钟域、门控和频移提供的所有机会,因为所有这些在ASIC中都很容易获得。
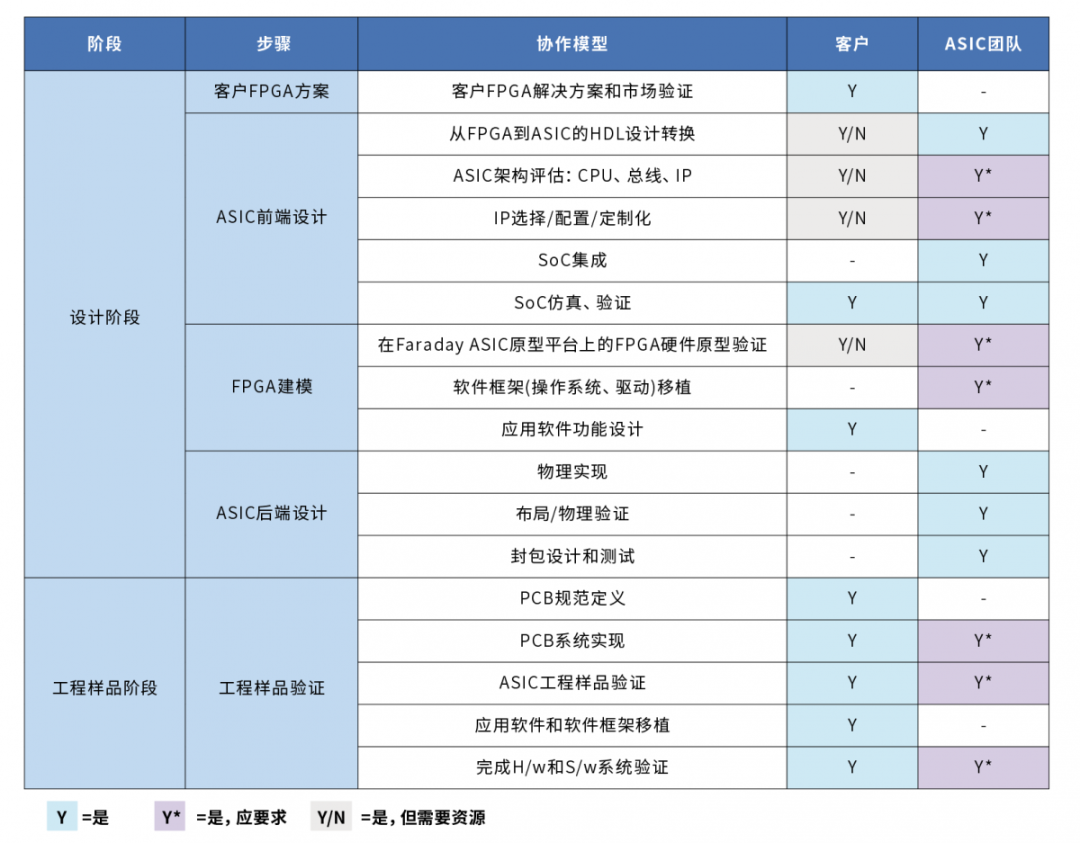
图3:该表列出了FPGA到ASIC转换过程中的每个步骤,并明确了实施责任。 同样,经验丰富的转换团队可以利用加速器的并行架构来实现并行内置自检,利用他们对设计意图的清晰理解和对测试提供商能力的充分了解。实际上,这种优化不仅已经超越了ASIC设计本身,而是进一步深入到了供应链。如果各方对图3所示的步骤内容和责任充分理解并实施得好,将会大幅度降低测试成本,从而显著节省总单位成本。 至此已经看到,将人工智能加速器设计从中间FPGA转换为ASIC,几乎也是一个机械式的过程。但由于人工智能与加速器高度并行的性质,对于转换团队来说,如果能够充分理解原始设计意图和架构的微妙之处、能够识别FPGA特定优化、具有人工智能半导体设计经验、能够在客户和ASIC团队专家之间自由分配任务,就可以取得更好的结果。 不过,任何时候都要牢记,最终实现具有卓越功率、性能和面积的ASIC,才是设计的初衷。
审核编辑:黄飞
-
浅谈人工智能(2)2026-02-22 575
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2420
-
arm/asic/dsp/fpga/mcu/soc的特点是什么?2021-11-11 2021
-
2018人工智能股票龙头2021-07-28 2142
-
人工智能芯片是人工智能发展的2021-07-27 6759
-
路径规划用到的人工智能技术2021-07-20 2443
-
什么是基于云计算的人工智能服务?2019-09-11 6007
-
智能控制、人工智能、智能算法的发展前景怎么样2019-05-10 5621
-
人工智能技术及算法设计指南2019-02-12 5215
-
解读人工智能的未来2018-11-14 4993
-
人工智能就业前景2018-03-29 8466
-
人工智能实现的流派 FPGA vs. ASIC看好谁?2016-12-23 3250
-
FPGA与ASIC大PK,谁将引领移动端人工智能潮流?2016-12-15 3330
-
人工智能是什么?2015-09-16 6490
全部0条评论

快来发表一下你的评论吧 !
