

NVIDIA ADAS-英伟达硬件芯片Orin解析
汽车电子
描述
上篇文章NVIDIA ADAS-英伟达DriveOS入门,介绍了英伟达的软件,本篇文章来说明下现在英伟达在智能驾驶上已商用最新的硬件芯片Orin。
目前Orin订单火爆,上汽的R和智己,理想L9、蔚来ET7、小鹏新一代P7,威马M7、比亚迪、沃尔沃XC90,还有自动驾驶卡车公司智加科技,Robotaxi等众多明星企业Cruise、Zoox、滴滴、小马智行、AutoX、软件公司Momonta等等,都搭载Orin平台进行开发,看阵容就不可小觑,可谓地表最强算力芯片。
1. 英伟达智驾SoC芯片发展史
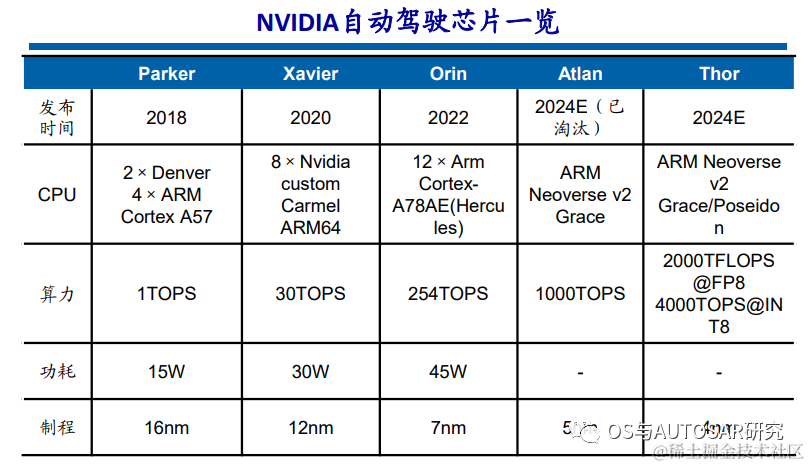
从2015年开始,英伟达开始进入车载SoC和车载计算平台领域,为自动驾驶提供基础计算能力。此后英伟达几乎每隔两年发布一款车规级SoC芯片,且不断拉升算力水平。2020年,Xavier芯片算力为30 TOPS,2022年发布的Orin算力为254 TOPS,2022秋季GTC大会上发布了新自动驾驶芯片Thor,算力为2000TFLOPS@FP8、4000TOPS@INT8,取代了之 前发布的算力达1000TOPS的Altan。
也就是说目前商用最新的芯片就是Orin。英伟达使用的车企阵容强大,如下图:

1.1 Xavier平台
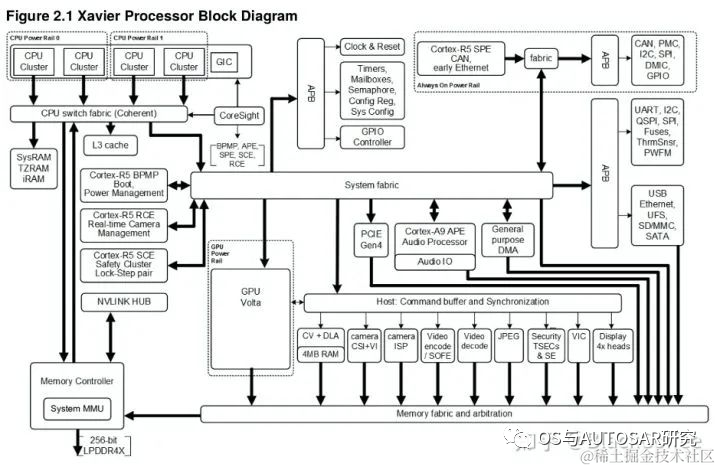
NVIDIA在2018年CES上推出了Xavier平台,作为Driver PX2 的进化版本。NVIDIA称Xavier 是“世界上最强大的SoC(片上系统)”,Xavier可处理来自车辆雷达、摄像头、激光雷达和超声波等传感器的自主驾驶感知数据,能效比市场上同类产品更高,体积更小。“NVIDIA Jetson AGX Xavier 为边缘设备的计算密度、能效和 AI 推理能力树立了新的标杆。”
2020年4月上市的小鹏汽车P7,成为首款搭载 NVIDIA DRIVE AGX Xavier 自动驾驶平台的量产车型,小鹏 P7 配备了13 个摄像头、5 个毫米波雷达、12 个超声波雷达,集成开放式的 NVIDIA DRIVE OS 操作系统。
Xavier SoC基于台积电12nm FinFET工艺,集成90亿颗晶体管,芯片面积350平方毫米,CPU采用NVIDIA自研8核ARM64架构(代号Carmel), 集成了Volta架构的GPU(512个CUDA核心),支持FP32/FP16/INT8,20W功耗下单精度浮点性能1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs。
Xavier是一颗高度异构的SoC处理器,集成多达八种不同的处理器核心或者硬件加速单元。使得它能同时、且实时地处理数十种算法,以用于传感器处理、测距、定位和绘图、视觉和感知以及路径规划等任务负载。
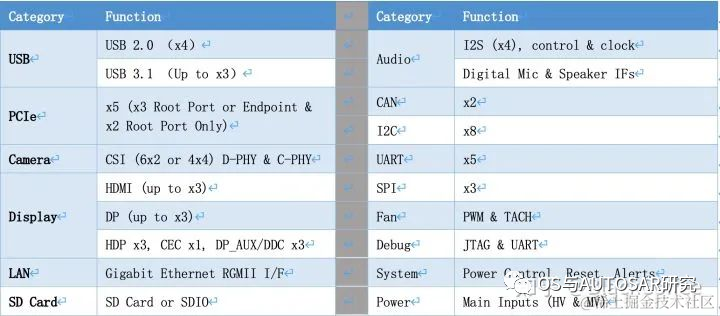
除了强大的计算资源外,Xavier SoC拥有丰富的IO接口资源:
Xavier的主处理器可以达到ASIL-B级别的功能安全等级需求。Ecotron公司基于NVIDIA Xavier SoC和Infineon TC297 MCU打造、面向L3/L4级别自动驾驶领域的高性能中央计算平台。按照设计方案考虑,Xavier智能处理器用于环境感知、图像融合、路径规划等,TC297 MCU用于满足ISO26262功能安全需求(ASIL-C/D级别)的控制应用场景(也即作为Safety Core) ,比如安全监控、冗余控制、网关通讯及整车控制。
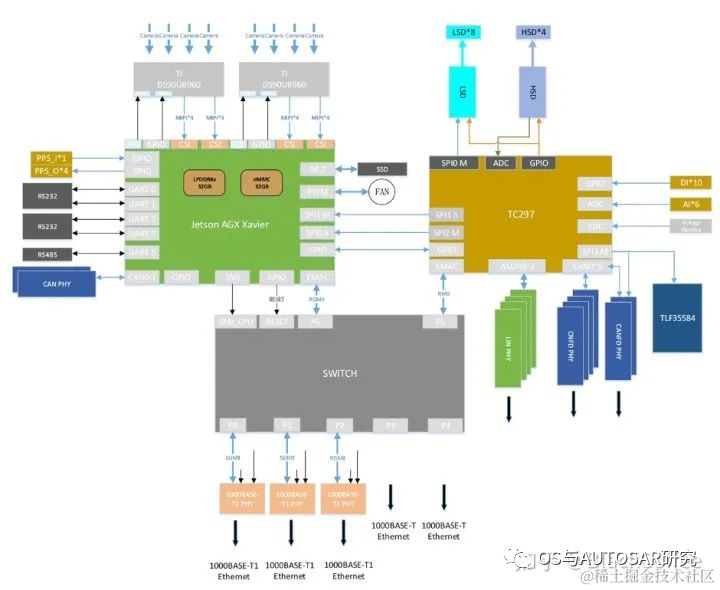
双Xavier+TC297 MCU的方案结构图:
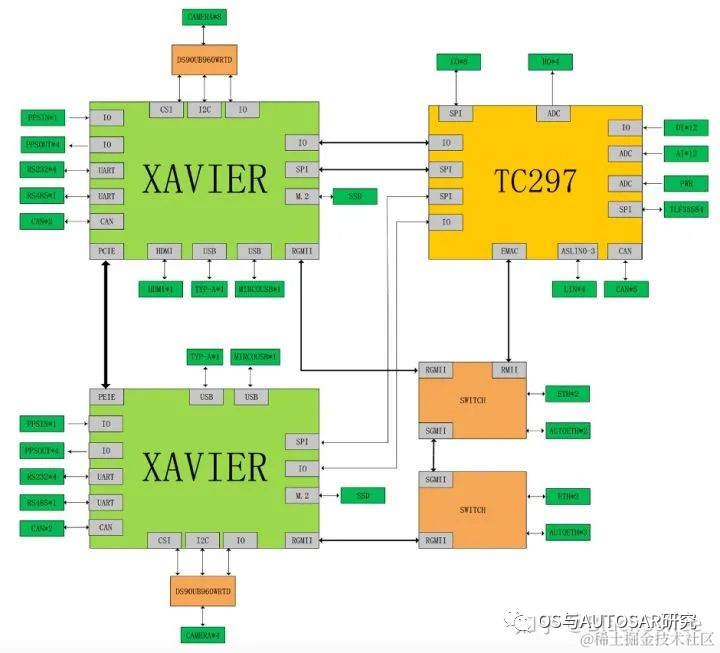
此用法虽然是旧平台的,但是其方案之后也是一直继承的,即TCXXX的车控芯片独立运行AUTOSAR,这里画出了两个域:智驾域(NVIDIA)+车控域(TC),座舱一般直接使用成熟便宜的手机安卓技术了。就看未来是否有中央式架构实现的可能了,目前还是三域架构。
1.2 Orin平台

2019年12月英伟达发布了新一代面向自动驾驶和机器人领域Orin芯片和计算平台。具有ARM Hercules CPU内核和英伟达下一代GPU架构。Orin SoC包含170亿晶体管,晶体管的数量几乎是Xavier SoC的两倍,具有12个ARM Hercules内核,将集成Nvidia下一代Ampere架构的GPU,提供200 TOPS@INT8性能,接近Xavier SoC的7倍,Orin SOC将在2021年提供样片,2022年正式面向车厂量产。
2020年5月GTC上,英伟达介绍了即将发布的新一代自动驾驶Drive AGX Orin平台,它可以搭载两个Orin SoC和两块NVIDIA Ampere GPU,可以实现从入门级ADAS解决方案到L5级自动驾驶出租车(Robotaxi)系统的全方位性能提升,平台最高可提供2000TOPS算力。未来L4/L5级别的自动驾驶系统将需要更复杂、更强大的自动驾驶软件框架和算法,借助强劲的计算性能,Orin计算平台将有助于并发运行多个自动驾驶应用和深度神经网络模型算法。
作为一颗专为自动驾驶而设计的车载智能计算平台,Orin可以达到ISO 26262 ASIL-D 等级的功能安全标准。
借助于先进的7nm制程工艺,Orin拥有非常出色的功耗水平。在拥有200TOPS的巨大算力时,TDP仅为50W。NVIDIA Orin处理器功能模块图
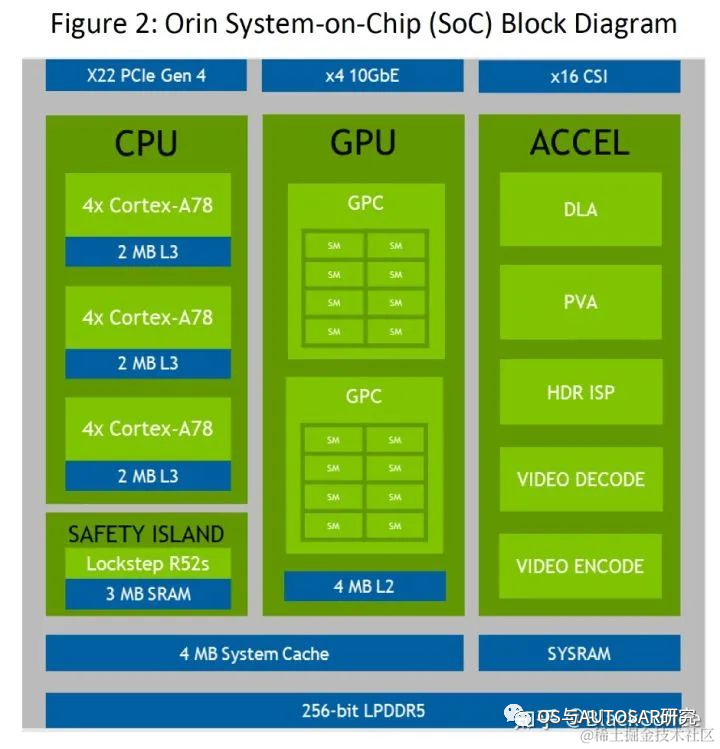
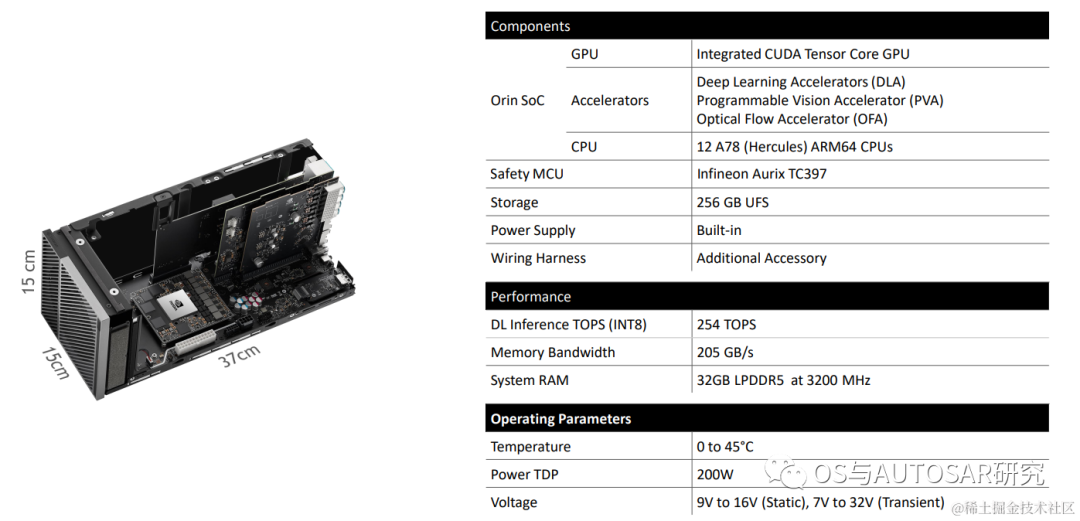
下表是Jetson AGX Orin的片上系统的性能参数:
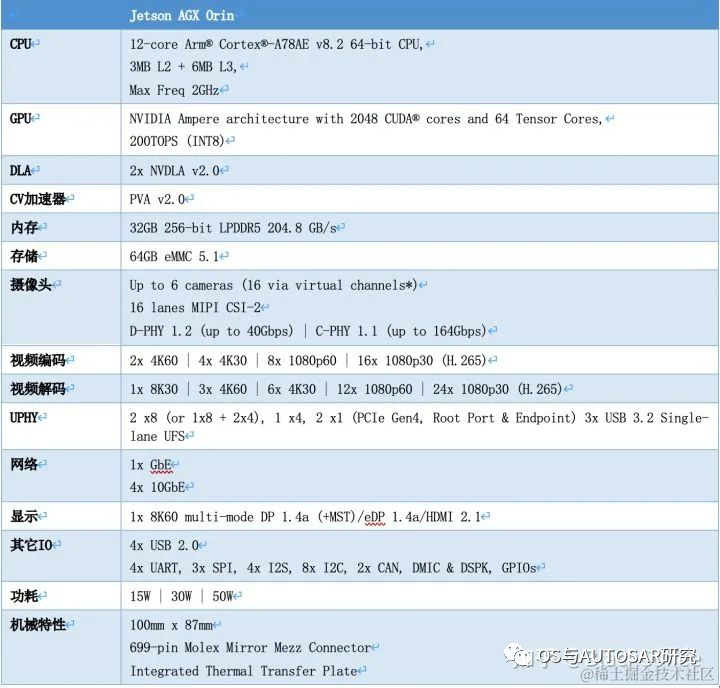
image.png
1.3 Thor平台
NVIDIA DRIVE Thor 是NVIDIA新一代集中式车载计算平台,可在单个安全、可靠的系统上运行高级驾驶员辅助应用和车载信息娱乐应用。DRIVE Thor 超级芯片借助我们新的 CPU 和 GPU 突破,可提供出色的 2000 万亿次浮点运算性能,同时降低总体系统成本,计划于2025年开始量产。
可以看到三域开始变两域了,智驾和座舱统一了,一统天下看来指日可待了,就需要利用安全技术解决最后一个车控MCU就可以了。
DRIVE Thor 还在深度神经网络准确性方面实现了令人难以置信的飞跃。Transformer 引擎是NVIDIA GPU Tensor Core的新组件。Transformer 网络将视频数据作为单个感知帧进行处理,使计算平台能够随着时间的推移处理更多数据。
该SoC能够进行多域计算,这意味着它可以划分自动驾驶和车载信息娱乐的任务。这种多计算域隔离可以让并发的时间关键进程不间断地运行。在一台计算机上,车辆可以同时运行Linux、QNX和Android。通常,这些类型的功能由分布在车辆各处的数十个电子控制单元控制。制造商现在可以利用 DRIVE Thor 隔离特定任务的能力来整合车辆功能,而不是依赖这些分布式ECU。

所有车辆显示器、传感器等都可以连接到这个单一SoC,从而简化了汽车制造商极其复杂的供应链。
参考:https://blogs.nvidia.com/blog/drive-thor/
2. Orin架构介绍
以 Orin-x 为例,其中的 CPU 包括基于 Arm Cortex-A78AE 的主CPU 复合体,它提供通用高速计算能力;以及基于 Arm Cortex-R52 的功能安全岛(FSI),它提供了隔离的片上计算资源, 减少了对外部 ASIL D 功能安全 CPU 处理的需求。
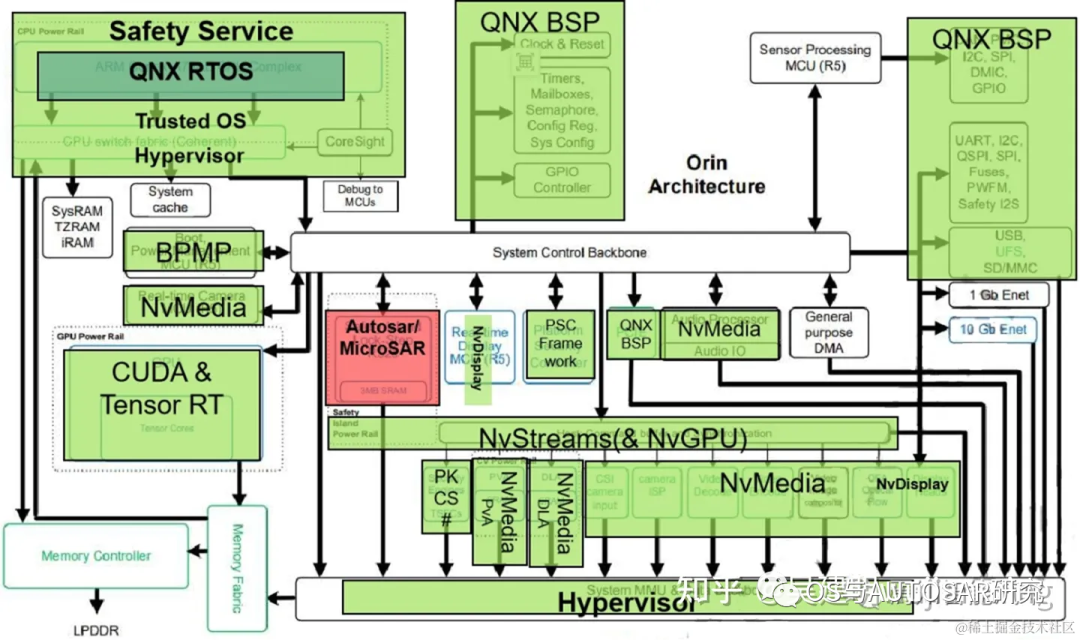
GPU 则是 NVIDIAAmpere GPU,为 CUDA 语言提供高级并行处理计算能力,并支持多种工具, 如 TensorRT,一种深度学习推理优化器和运行时,可提供低延迟和高吞吐量。Ampere 还提供最先进的图形功能,包括实时光线跟踪。域特定硬件加速器(DSA)是一组专用硬件引擎,旨在从计算引擎中卸载各种计算任务,并以高吞吐量和高能效执行这些任务。
整个芯片内部架构设计主要是按分块进行功能设计区分。包括操作系统底层软件QNX BSP(时钟Clock源&系统重启、CAN/SPI/I2C/GPIO/UART控制器、配置寄存器、系统配置)、实时运行系统QNX RTOS、Nv多媒体处理模块(传感器处理模块MCU(R5)、PVA、DLA、Audio Processor、MCU R5配置实时相机输入)、经典Autosar处理模块(用于Safety Island Lock-Step R52s)、安全服务Safety Service(ARM Cotex-A78AE CPU Complex、CPU Switch fabric Coherent、信息安全PSC)、神经网络处理模块(CUDA & TensorRT)。
下图显示了 SoC 的高级架构,分为三个主要处理复合体:CPU、GPU 和硬件加速器。
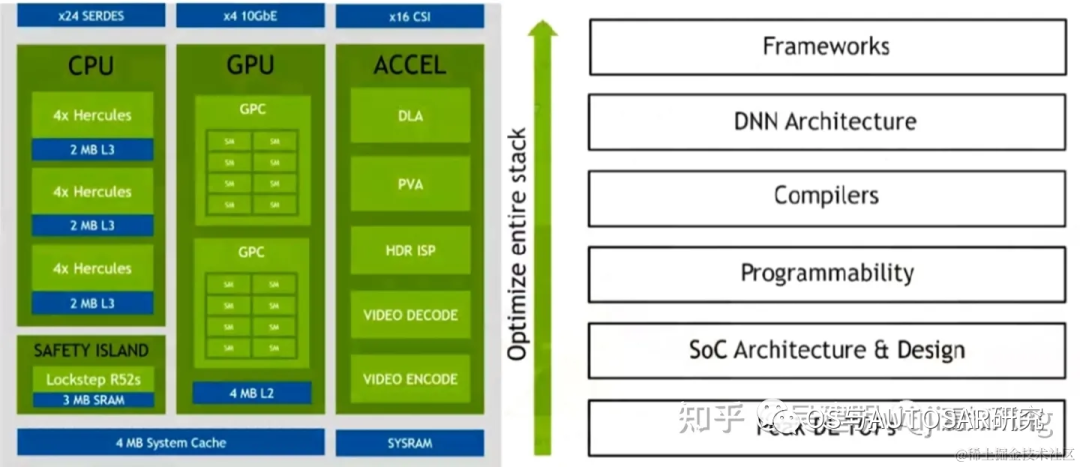
2.1 CPU相关
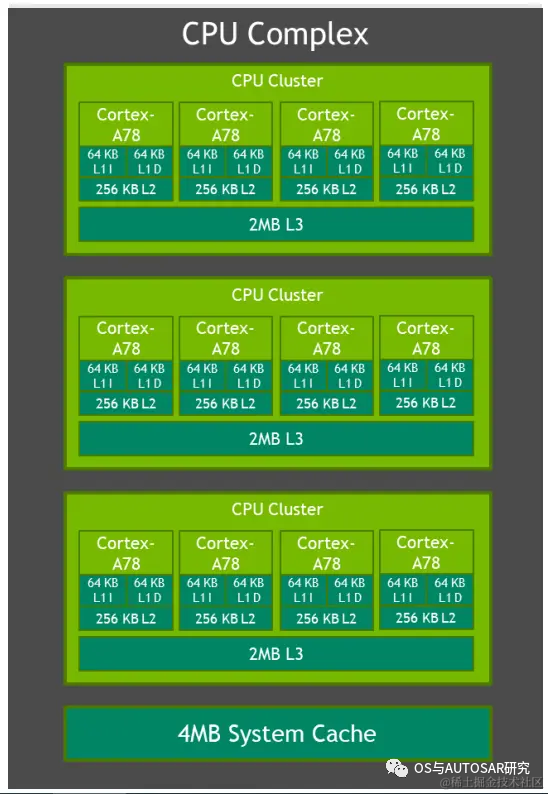
Orin系统架构中,CPU从之前自研的Carmel架构回到了到5纳米工艺的ARM Cortex-A78上。Orin-x中CPU包括 12个 Cortex-A78,可以提供通用的目标高速计算兼容性。同时,Arm Cortex R52 基于功能安全设计(FSI),可以提供独立的片上计算资源,这样就可以不用增加额外的 CPU(ASIL D)芯片用来提供功能安全等级。
CPU 族群所支持的特性包括 Debug 调试,电源管理,Arm CoreLink 中断控制器,错误检测与报告。CPU需要对芯片进行整体性能监控,每个核中的性能监控单元提供了六个计算单元,每个单元可以计算处理器中的任何事件。基于 PMUv3 架构上,在每个 Runtime 期间这些计算单元会收集不同的统计值并运行在处理器和存储系统上。
2.2 GPU

Orin采用了新一代的Ampere架构GPU,由2个GPC(Graphics Processing Clusters,图形处理簇)组成。每个GPC又包含4个TPC(Texture Processing Clusters, 纹理处理簇),每个TPC由2个SM(Streaming Multiprocesor,流处理器)组成,下图为Orin的GPU架构。每个SM有192KB的L1缓存和4MB的L2缓存,包含128个CUDA Core和4个Tensor Core。因此Orin总计2048个CUDA Core和64个Tensor Core,INT8稀疏算力为170 TOPS(Tensor Core提供),INT8稠密算力为54TOPS,FP32算力为5.3TFLOP(由Cuda Core提供)。
NVIDIA Ampere GPU 可以提供先进的并行处理计算架构。开发者可以使用 CUDA 语言进行开发(后续将对CUDA架构进行详细说明),并支持 NVIDIA 中各种不同的工具链(如开发 Tensor Core 和 RT Core 的应用程序接口)。一个深度学习接口优化器和实时运行系统可以传递低延迟和高效输出。Ampere GPU 同时可以提供如下一些的特性来实现对高分辨率、高复杂度的图像处理能力(如实时光流追踪)。
稀疏化::细粒度结构化稀疏性使吞吐量翻倍,减少对内存消耗。浮点处理能力:每个时钟周期内可实现 2 倍 CUDA 浮点性能。
缓存::流处理器架构可以增加 L1 高速缓存带宽和共享内存,减少缓存未命中延迟。提升异步计算能力,后 L2 缓存压缩。
2.3 加速器
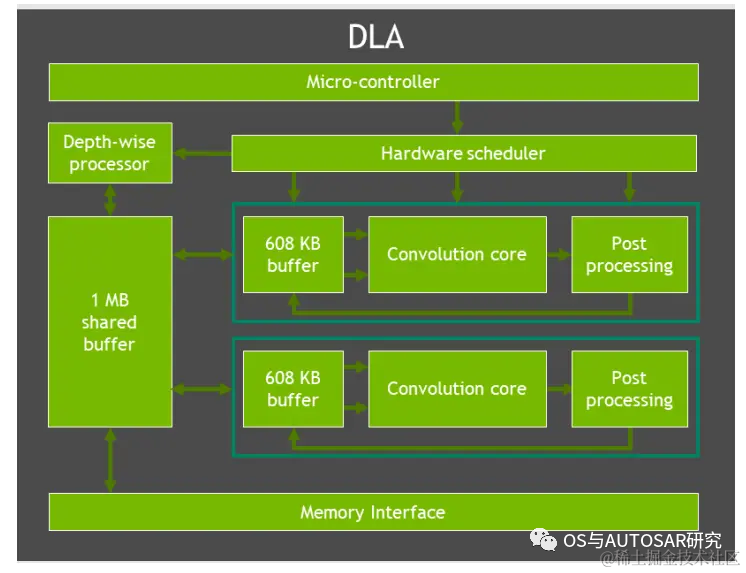
特定域硬件加速器(DSAs、DLA、PVA)是一组特殊目的硬件引擎,实现计算引擎多任务、高效、低功率等特性。计算机视觉和深度学习簇包括两个主要的引擎:可编程视觉加速器 PVA 和深度学习加速器 DLA(而在最新的中级算力 Orin n 芯片则取消了 DLA 处理器)。
PVA 是第二代 NVIDIA 视觉DSP架构,它是一种特殊应用指令矢量处理器,这种处理器是专门针对计算机视觉、ADAS、ADS、虚拟现实系统。PVA 有一些关键的要素可以很好的适配预测算法领域,且功耗和延迟性都很低。Orin-x需要通过内部的R核(Cortex-R5)子系统可以用于 PVA 控制和任务监控。一个 PVA 簇可以完成如下任务:双向量处理单元(VPU)带有向量核,指令缓存和 3 矢量数据存储单元。每个单元有 7 个可见的插槽,包含可标量和向量指令。此外,每个 VPU 还含有 384 KBytes的3端口存储容量。
DLA 是一个固定的函数引擎,可用于加速卷积神经网络中的推理操作。Orin-x 单独设置了 DLA 用于实现第二代 NVIDIA 的 DLA架构。DLA支持加速 CNN 层的卷积、去卷积、激活、池化、局部归一化、全连接层。最终支持优化结构化稀疏、深度卷积、一个专用的硬件调度器,以最大限度地提高效率。
2.4 第二代视觉加速器PVA和VIC
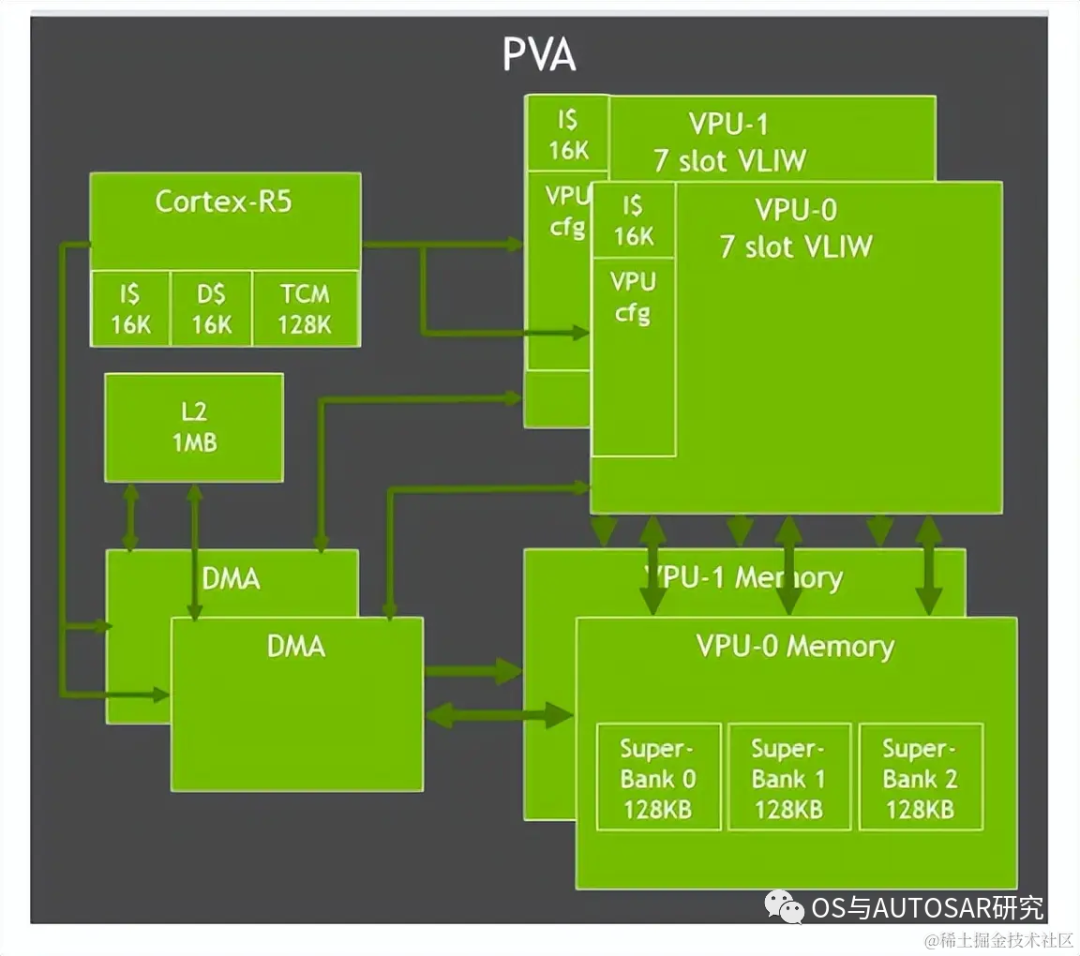
Orin中对PVA进行了升级,包括双7路VLIW(超长指令字)矢量处理单元、双DMA和Cortex-R5,支持计算机视觉中过滤、变形、图像金字塔、特征检测和FFT等功能。
Orin还包含一个Gen 4.2视频成像合成器 (Video Imaging Compositor,VIC) 2D 引擎,支持镜头畸变校正和增强、时间降噪、视频清晰度增强、像素处理(色彩空间转换、缩放、混合和合成)等图像处理功能。
为了调用Orin SoC上的多个硬件组件(PVA、VIC、CPU、GPU、 ENC等),英伟达开发了视觉编程接口 ( Vision Programming Interface,VPI) 。作为一个软件库,VPI附带了多种图像处理算法(如框过滤、卷积、图像重缩放和重映射)和计算机视觉算法(如哈里斯角检测、KLT 特征跟踪器、光流、背景减法等)。
2.5 内存和通讯
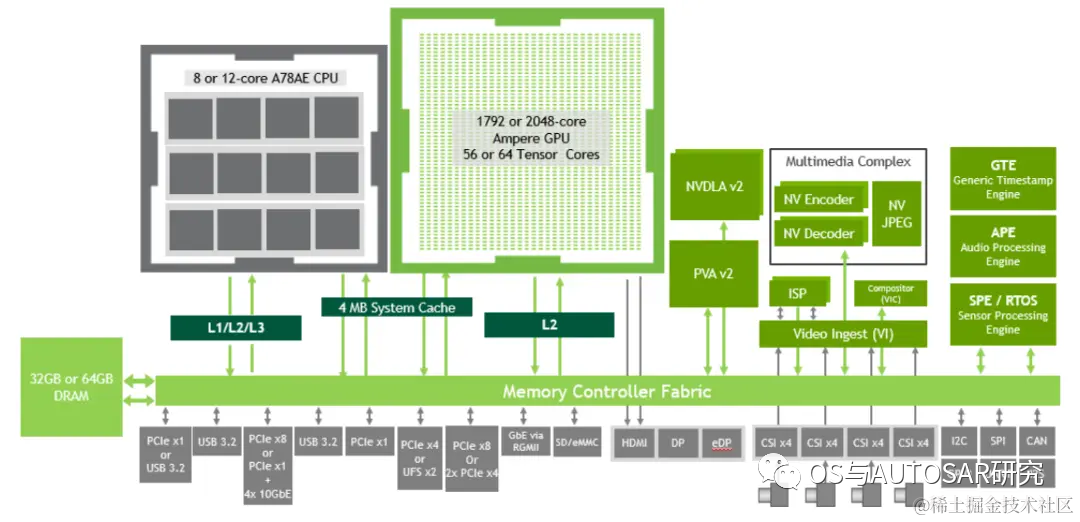
image.png
上图显示了Orin各组件中,通过内存控制器结构(Fabric)和DRAM如何通讯和数据交互。
Orin最高支持64GB的256位LPDDR5和64GB的eMMC。DRAM支持3200MHz的最大时钟速度,每个引脚6400Gbps,支持204.8GB/s的内存带宽,是Xavier内存带宽 memory bandwidth 的1.4倍、存储storage的2倍。
3. 基于Orin的自动驾驶平台架构设计

常规的 SOC 系统架构通常是包含有常规的 SOC+MCU 双芯片甚至三芯片的方式进行设计的。SOC 由于计算性能上的优势,一般在前端感知、规划中的计算应用场景比 MCU 更好。
MCU 由于具备较高的功能安全等级,可以作为控制执行的校验输出。业界对于英伟达芯片是否可以单纯作为类似 TDA4 一样的超异构芯片而独立承担任务, 一直都是褒贬不一的。原则上,从无论 Xavier 还是 Orin 系列,英伟达系列芯片设计都兼具丰富的 AI 和 CPU 算力能力。考虑 L2+级别以上的自动驾驶系统开发而言,这种能力都是可以完全适配整个方案设计的。可能是对于安全要求较高的车控MCU不光是技术上先进就可以替代,主要还是装机量,需要用起来安全才可以。
3.1 安全考虑

可以看到基本R52核实现的安全岛达到了ASIL-D,其他基本还是只满足ISO 26262。所以需要一个SMCU作为辅助实现车控域。如英飞凌 Aurix TC系 列,瑞萨的 RH850 系列都可以充当 MCU 实现对 Orin 的 SMCU 接入。这样的 SMCU 实际是可以充当整个系统开发的电源控制和严重失效故障规避的。在英伟达卖的开发平台上就可以看到SMCU TC397的身影,如下图:
通过可信安全加载技术,ATF中BL1存入ROM,里面有BL2的安全校验,然后形成链式安全加载。包括 u-boot 在内的所有低级引导步骤都可以通过签名的二进制文件来确保安全。它们的密钥可以存储在 CPU 中的一次性可编程保险丝中。U-boot 本身可以配置为使用签名的FIT 映像,从而提供一个安全的引导链,一直到 Linux 内核。初始 ROM 引导加载程序和 TegraBoot 也都支持完全冗余的引导路径。
3.2 FSI介绍

上图显示了如何在英伟达系列芯片中加载 FSI 及底层相关模块驱动引导程序。英伟达系列芯片在功能安全设计上,Orin 系列通过制定目标实现 ASIL D 系统能力设计和ASIL B/D 随机错误管理能力设计。包括基于 SOC 芯片硬件的 ASIL 分解需求到各个核,确保核间设计一致性可以满足 ASIL D 需求,并应用标准的 ASIL D 开发流程到整个功能安全设计中,从底之上分别对安全流程、Drive AGX、操作系统 Drive OS、Drive Work、传感器、冗余架构设计、安全策略几个方面分别进行相应的安全设计。
英伟达系列芯片的功能安全岛(FSI)是一个包含 Cortex-R52 和 Cortex-R5F real 的处理器集群,并具有专用 I/O 控制器的时间处理器的核心。例如,Orin-X 中的 FSI 模块具有自己的电压轨、振荡器和PLL、SRAM,以确保与 SOC 内部的其他模块相互作用最小,并实现如上模块相互之间无干扰。
Cortex-R52 处理器,也称为安全CPU,具有 DCLS(双核锁步)模式下的 4 个内核(共 8 个物理内核),可运行经典 AUTOSAR 操作系统,实现错误处理、系统故障处理和其他客户工作负载,综合性能约为 10KDMIPs。
Cortex-R5F 处理器,也称为加密硬件安全模块(CHSM),用于通过 CAN 接口运行加密 和安全用例,如安全车载通信(SecOC)。
整个FSI机制上总体包含有如下的一些安全指令和控制接口信息:
1、安全和 CHSM CPU 每个核心的紧密耦合内存、指令和数据缓存。
2、安全岛上总共有 5MB 的片上专用 RAM,以确保代码执行和数据存储可以保持在 FSI 内。
3、岛上有专门用于与外部组件通信的专用 I/O 接口。包含1个 UART,4 个 GPIO 口。
4、硬件安全机制,如 FSI 内所有 IP 的 DLS、CRC、ECC、奇偶校验、超时等。专用热、电压和频率监测器。
5、逻辑隔离,确保与 SoC 的其他部分有足够的错误恢复时间FFI。
3.3 TESC
Tegra是英伟达芯片中特有的信息安全芯片内核,Tegra Security Controller(TESC)是一种信息安全子系统,他有自己的可信任根ROM、IMEM、DMEM,Crypto 加速器(AES、SHA、RNG、PKA),关键链路和关键存储。TSEC 提供了一个片上TEE(可信任执行环境)可以运行NVIDIA-标记的为处理代码。TSEC是一种典型的安全视频回放解决方案,下载信息安全运行所需的HDCP1.x 和2.x连接授权和完整的线端连接检测。
1)线端HDMI 1.4上的HDCP 1.4和 线端HDMI 2.3上的HDCP 2.0 2.1; HDCP连接管理没有暴露受保护的内容,也无需运行在CPU上的软件钥匙。用于 HDCP 链路管理的两个软件可编程独立指令队列(最多可容纳 16 条指令);整个芯片能够独立于播放器在 HDCP 状态检查失败时禁用 HDMI 输出。
2)平台安全控制器; 他是一个高安全子系统,他可以保护和管理SOC中的资产(钥匙、保险丝、功能、特性),并提供可信任的服务,提升自由的抵御对 SOC 的攻击,并可以提高对子系统本身的软件和硬件攻击的保护水平。
3)钥匙管理和保护; PSC 将是唯一可以访问芯片中最关键秘钥的机制。该子系统代表了 Orin-x 中最高级别的保护,并且该子系统本身对各种软件和硬件攻击具有高度的弹性。
4)授信服务; 例如,在 SOC 安全启动期间,主要的 PSC 服务可以完成有效的安全身份验证、提供额外的密钥/ID/数据、密钥访问和管理、随机数生成和授信的时间报告。
5)信息安全监控。 PSC 将负责定期的安全管理任务,包括持续评估 SOC 的安全状态,主动监控已知或潜在的攻击模式(例如,电压故障或热攻击),降低硬件攻击风险,并在检测到有攻击的情况下采取有效的措施。PSC 将能够接受各种软件更新来作为解决方法,以提高现场系统的稳健性。
3.4 安全引擎(SE)
安全引擎SE中有两种情况针对软件使用是有用的。其一,TZ-SE只能被可信任区域软件所访问。其二,NS/TZ-SE可配置用来被可信任的软件区域或非安全软件所访问。安全引擎SE可以为各种加密算法提供硬件加速以及硬件支撑密钥保护。SE提供的加密算法可以被软件用来建立加密协议和安全特性。所有加密运算都是基于国际标准技术协会NIST批准的加密算法。
英伟达的安全引擎SE可支持包含如下的所有信息安全保障能力:
NIST合规的对称以及非对称加密和哈希算法、侧信道对策(AES/RSA/ECC)、独立并行信道、硬件钥匙访问控制(KAC)(基于规则,增强硬件访问控制的对称钥匙)、16xAES,4xRSA/ECC钥匙孔、硬件密钥隔离(仅针对AES钥匙孔)、读保护(仅针对AES钥匙孔)、硬件钥匙孔函数、密钥包装/解包功能(AES->AES钥匙孔)、钥匙从钥匙孔分离(KDF->AES钥匙孔)、随机钥匙生成(RNG->AES钥匙孔)。
4. GPU编程CUDA
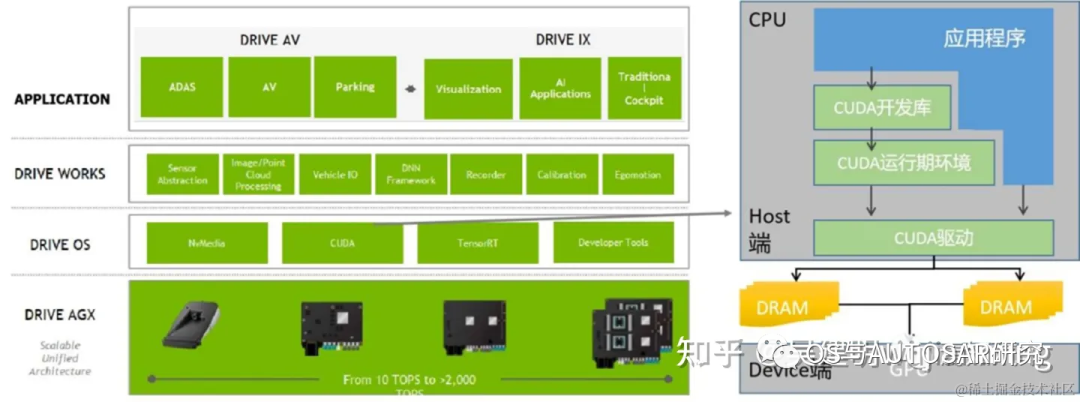
image.png
上图表示了 CUDA 架构示意图,表示了CPU,GPU,应用程序,CUDA 开发库,运行环境,驱动之间的关系
4.1 GPU软件架构
自动驾驶领域使用的 AI 算法多为并行结构。AI 领域中用于图像识别的深度学习、用于决策和推理的机器学习以及超级计算都需要大规模的并行计算,更适合采用 GPU 架构。由于神经网络的分层级数(通常隐藏层的数量越多,神经网络模拟的结果越精确)会很大程度的影响其在预测结果。擅长并行处理的 GPU 可以很好的对神经网络算法进行处理和优化。因为,神经网络中的每个计算都是独立于其他计算的,这意味着任何计算都不依赖于任何其他计算的结果,所有这些独立的计算都可以在 GPU 上并行进行。通常 GPU 上进行的单个卷积计算要比 CPU 慢,但是对于整个任务来说,CPU 几乎是串行处理方式,需要要逐个依次完成,因此,其速度要大大慢于 GPU。因此,卷积运算可以通过使用并行编程方法和GPU来加速。
英伟达通过 CPU+GPU+DPU 形成产品矩阵,全面发力数据中心市场。利用 GPU 在AI 领域的先天优势,英伟达借此切入数据中心市场。针对芯片内部带宽以及系统级互联等诸多问题,英伟达推出了 Bluefield DPU 和 Grace CPU,提升了整体硬件性能。
对于英伟达的GPU而言,一个 GPC 中有一个光栅引擎(ROP)和 4 个纹理处理集群(TPC),每个引擎可以访问所有的存储。
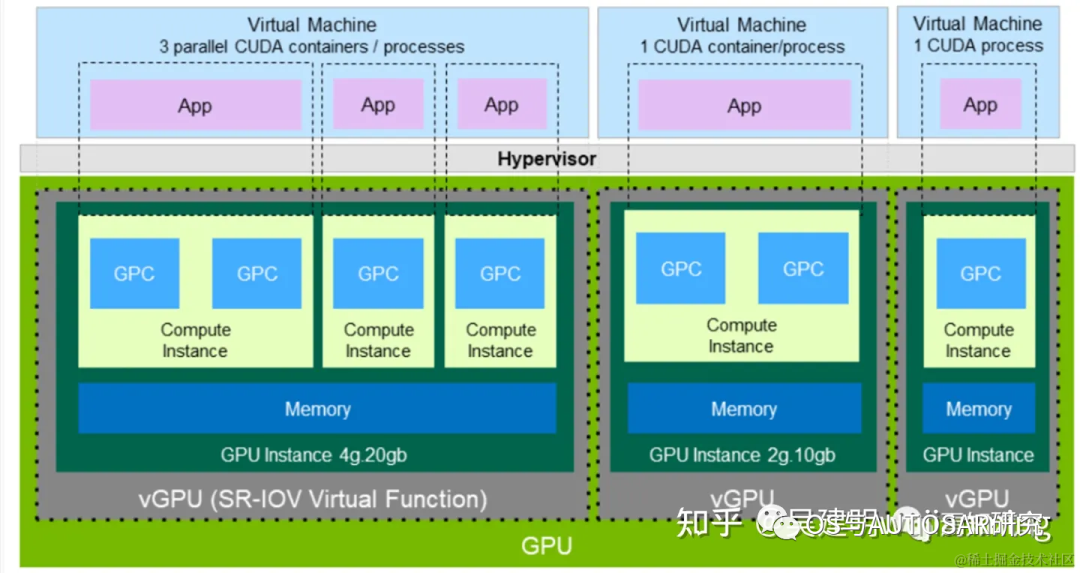
4.2 CUDA编程
CUDA(Compute Unified Device Architecture,统一计算架构) 作为连接 AI 的中心节点,CUDA+GPU 系统极大推动了 AI 领域的发展。搭载英伟达 GPU 硬件的工作站(Workstation)、服务器(Server)和云(Cloud)通过 CUDA软件系统以及开发的 CUDA-XAI 库,为自动驾驶系统 AI 计算所需要的机器学习、深度学习的训练(Train)和推理(Inference)提供了对应的软件工具链,来服务众多的框架、云服务等等,是整个英伟达系列芯片软件开发中必不可少的一环。
CUDA 是一个基于英伟达 GPU 平台上面定制的特殊计算体系/算法,一般只能在英伟达的 GPU 系统上使用。这里从开发者角度我们讲讲在英伟达 Orin 系列芯片中如何在 CUDA架构上进行不同软件级别开发。
从CUDA 体系结构的组成来说,它包含了三个部分:开发库、运行期环境和驱动。
“Developer Lib 开发库” 是基于 CUDA 技术所提供的应用开发库。例如高度优化的通用数学库,即cuBLAS、cuSolver 和 cuFFT。核心库,例如 Thrust 和 libcu++;通信库, 例如 NCCL 和 NVSHMEM,以及其他可以在其上构建应用程序的包和框架。
“Runtime 运行期环境” 提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。
“Driver 驱动部分” 是 CUDA使能GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA 提供运行期环境也是通过这一层来实现各种功能的。
在 CUDA 架构下,一个程序分为两个部份:host端和 device端。Host端是指在 CPU 上执行的部份,而 device端则是在显示芯片(GPU)上执行的部份。Device 端的程序又称为 "kernel"。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。这里需要注意的是,由于 CPU 存取显存时只能透过 PCI Express 接口,因此速度较慢 (PCI Express x16 的理论带宽是双向各 4GB/s),因此不能经常进行,以免降低效率。
基于以上分析可知,针对大量并行化问题,采用 CUDA 来进行问题处理,可以有效隐藏内存的延迟性 latency,且可以有效利用显示芯片上的大量执行单元,同时处理上千个线程 thread 。因此,如果不能处理大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
对于这一应用瓶颈来说,英伟达也在数据存取上做出了较大的努力提升。一方面,优化的CUDA 改进了 DRAM 的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少 DRAM 的数据传送,更少的依赖 DRAM 的内存带宽。
此外,CUDA 还可以在程序开始时将数据复制进 GPU 显存,然后在 GPU 内进行计算,直到获得需要的数据,再将其复制到系统内存中。为了让研发人员方便使用 GPU 的算力,英伟达不断优化 CUDA 的开发库及驱动系统。操作系统的多任务机制可以同时管理 CUDA 访问 GPU 和图形程序的运行库,其计算特性支持利用 CUDA 直观地编写 GPU 核心程序。
后记:
对于软件开发人员学习SoC架构也是非常有用的,在制定软件方案的时候需要参考硬件上有那些通路,性能是否可以满足,有那些硬件可以利用来支撑功能实现。在驱动开发的时候,需要罗列那些硬件模块的需求需要开发,驱动对上层提供的服务要达到什么程度形成封装API接口。
本篇文章为了更加全面准确的介绍Orin,除了参考官网的资料外,参考了大量他人的文章,见参考资料章节,对于芯片更细节的东西需要注册英伟达官网账号,甚至购买后有芯片的data sheet和FAE支持,这里不涉及。芯片研发和使用需要大量人力物力,这里虽只是冰山一角都这么多,也写的比较流水账,大家多多担待。
审核编辑:黄飞
-
NVIDIA Jetson_AGX_Orin模组刷机教程2026-05-13 505
-
Orin芯片的技术特点2024-10-27 3835
-
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片2024-05-13 6806
-
英伟达的主要产品有哪些2024-03-01 17401
-
英伟达Orin 的系统结构解析2024-01-29 6475
-
英伟达:四家中国车企选其自动驾驶芯片平台2024-01-09 2129
-
携手英伟达,RoboSense速腾聚创正式入驻NVIDIA Omniverse生态系统2023-05-22 1360
-
工业富联采用基于英伟达的超级芯片NVIDIA Grace CPU2022-05-26 5515
-
英伟达DPU的过“芯”之处2022-03-29 6002
-
英伟达最新推出的自动驾驶芯片Atlan详解2021-04-19 13273
-
蔚来 ET7 电动汽车搭载四颗英伟达 Orin 芯片2021-02-20 6262
-
理想汽车将在2022年使用NVIDIA Orin系统级芯片2020-09-26 5155
-
英伟达发布新一代的自动驾驶芯片Orin2019-12-18 7240
-
【NVIDIA社招】英伟达上海热招ASIC验证工程师2016-09-26 3426
全部0条评论

快来发表一下你的评论吧 !
