

AI算力数据中心的一些挑战
人工智能
描述
2023年11月,趋动科技联合创始人兼CTO陈飞博士,在数据中心标准大会上以《从小模型到大模型——AI时代下的数据中心建设》为题发表演讲,根据演讲内容整理下文,供数据中心行业内的广大读者参考。
01. 人工智能的发展和现状
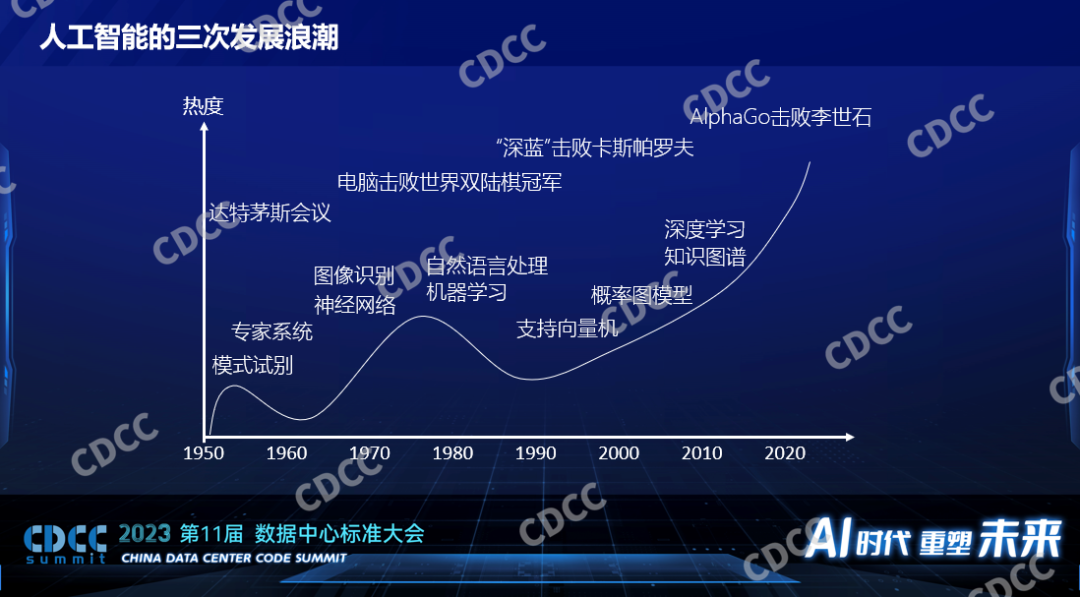
AI或者人工智能自1956年提出至今已有几十年的历史。过去的几十年里面,人工智能的热度经历了三次浪潮,第一次提出人工智能之后出现一些新的技术,也应用到了工业生产上,但是很快大家发现所谓的人工智能还不是那么智能,一波浪潮过去之后,大家对它的关注度也就降低了。随着一些新技术的出现,1979年电脑程序击败了当时的世界冠军,1997年IBM的深蓝击败了卡斯帕罗夫,这样标志性事件提升了人们对人工智能的期望,人工智能迎来了一波高峰。2006年Hinton提出了深度学习的概念,标志着第三次人工智能发展的浪潮。
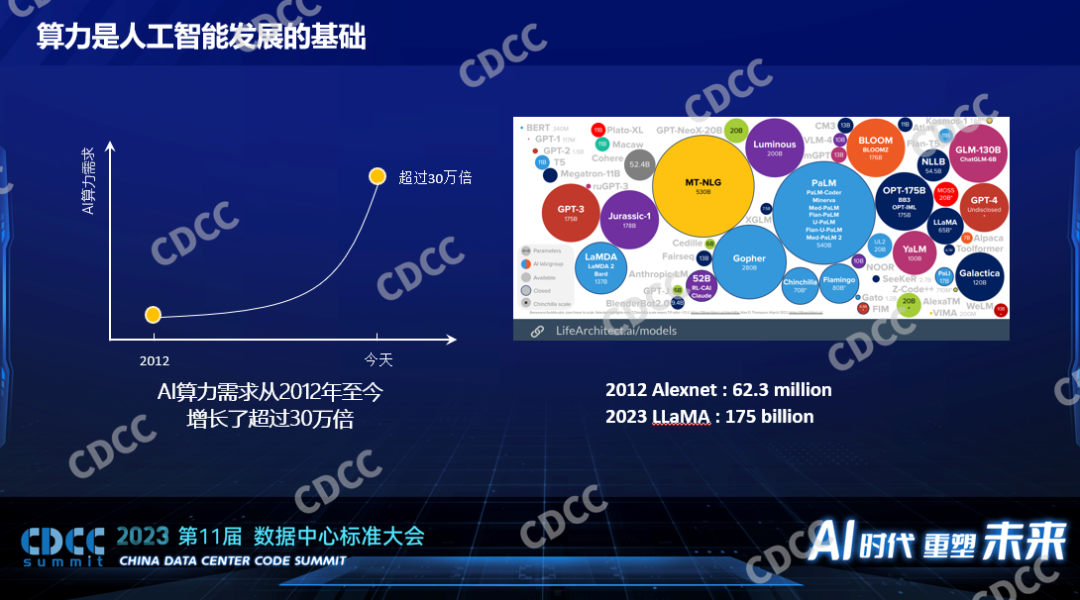
第三次人工智能浪潮开始后,有很多新的算法出现,同时有GPU这样的硬件支撑这类算法。据统计,2012年至今,我们对算力的需求涨了30万倍。这么多的算力需求都消耗在哪了?大量消耗在模型算法本身的快速发展。上图是国外的一个网站,他们自动统计了一些公开的模型的大小,图左上角很小的一个点是BERT,它在两三年前小模型时代还是比较重量级别的模型,到现在图里几乎已经看不到了。2012年标志性的深度学习模型Alexnet(百万参数)到2023年 LLaMa,是2800倍的模型的增长,模型的增长意味着算力的消耗增长。
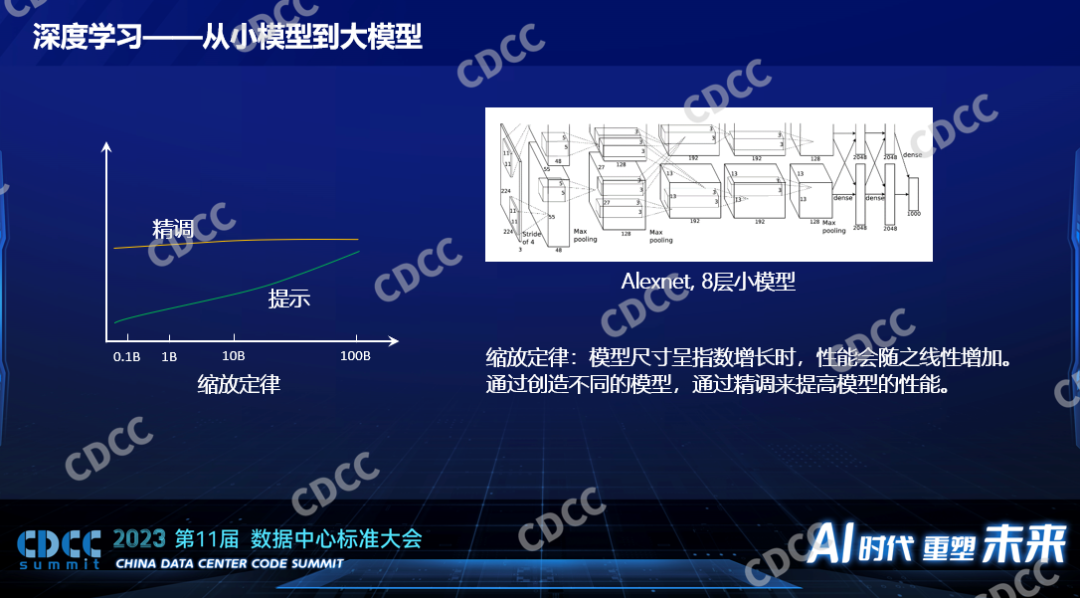
上图是一个Alexnet很小的内部结构图,Alexnet相对今天来说是一个非常小的模型,它为什么叫深度学习呢?它的模型是分层的,一层一层,最左边这层,给大家打一个比喻,它就是一幅图片,我们都知道它是二维的像素点,宽和高,像素点就是一些数值,最黑就是0,最亮就是255,这个是它的一层。一层进来了之后,它要和一个模型的参数进行数学运算,从一个二维的图象经过数学运算数学变换之后变成一个三维的立体,从数据的表达上是个三维的立体,一层一层的去运算,每一层的运算都不一样,有做卷积的,有求最大值的,有求最小值的,一层一层下来最后得出一个结果,这个结果就是给这个图片做一个分类,是猫还是狗,这就是一个模型。深度学习就是这个意思,一层归一层。Alexnet是8层的小模型,后面在小模型时代还有ResNet50,具有50层,ResNet 152,有152层,每一层的增加以及每一层规模的大小背后都意味着巨大的算力的消耗。
GPT模型结构有可能不一样,比喻成初期的小模型,那都是千层级别,所以深度学习的模型消耗着巨大的算力,大家为什么热衷于增大模型?,过去的时候学术界里有一个结论,他们认为有个缩放定律,这个缩放定律就是当这个模型的尺寸呈指数增长的时候性能呈线性增长,性能不是指运算的速度,在人工智能领域里面性能指的是模型的质量,比如识别图象的精确率,如果是大语言模型的话就是它生成的内容的质量,这个性能会随之线性增长,这个规律其实是挺悲观的规律,因为模型是指数性增长换来的才是性能的线性增长,意味着我们有可能对这个模型背后算力的需求要消耗非常非常大,之前估计大到整个太阳的能量都提供给一个模型都不足以产生具有人一样的智能的模型出来。
如果落地到一些具体小的应用,具体的场景里面还是有非常好的效果的,像人脸的识别,精确度非常高。
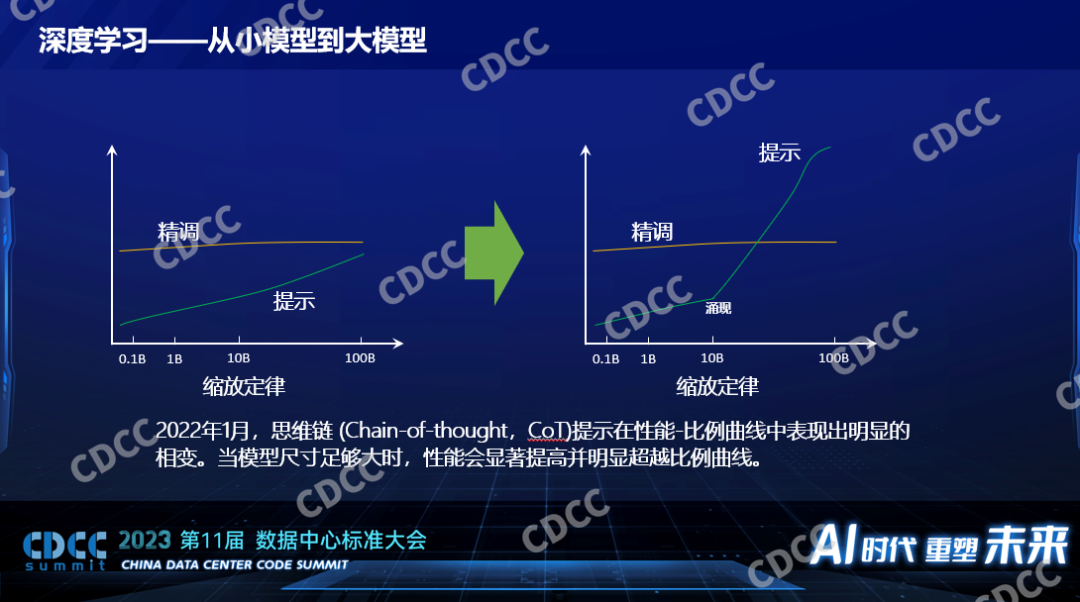
以前一般都通过精调来提高模型的性能,比如改变数据集,人工做更好的标注,提高更高质量的数据集,让模型的性能越来越好,对模型做变种,比如觉得ResNet 50不够,用ResNet 152,大模型和以前很不一样的是大模型都是要有提示词的,提示词在小模型时代已经出现了,但这个技术比起人工标注数据的方式效果并不好,小模型的时候离人工精调一个模型得到的性能差别非常远,所以在那个时候提示词并没有成为人工智能的主流,并且当时人们认为基于提示词这种比较简单的模型训练的方法要到模型非常大的时候才能媲美一个很小的模型,比如要在100B的参数的模型下面,它的性能和0.1B的小模型相媲美,那时候不成为主流。
为什么突然大模型出现了?2022年一篇来自谷歌的文章向技术领域公开了思维链的技术,简单的说以前人工智能训练一个模型是给一个数据并且人工告诉它关于这个数据的结果。但是在思维链的训练模型下面,它会像人教学生一样一步一步的推到这个结果是怎么得到的,这种思维链的产生出现了让科学家们意料不到的现象,这个现象叫涌现,意思就是当模型大到一定程度之后使用思维链的训练方式会引起相变或者突变,它不再是我们以前预期的平缓的上升,而是突然有一个飞跃的发展。这种思维链用在小模型的时候是不生效的,但是用在模型参数大概10Billion的时候会生效,并且得到的性能比以前精调的方式有了本质的差异。所以我们说什么是小模型和什么是大模型,一个特征就是是否会在模型变得足够大的时候有涌现的现象出现,如果没有的话,它的模型参数再大,我们还是认为它是小模型,虽然说它对算力的消耗也是巨大的。正因为有了涌现的现象出现,大家对人工智能的期望再次被拔高了,现在大家都在讨论大模型。
02. 企业人工智能的开发和生产
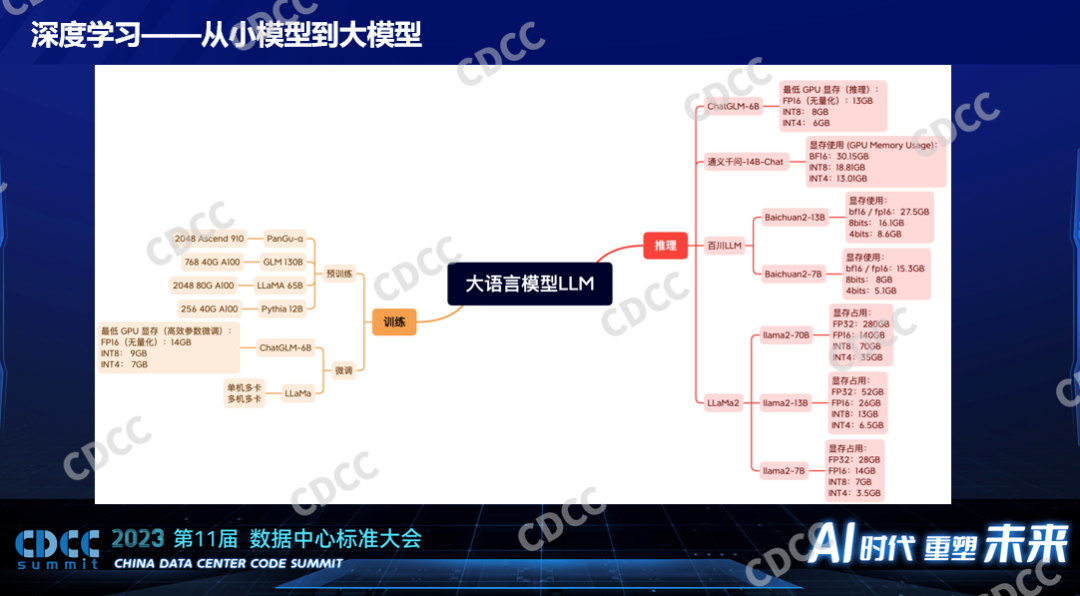
小模型和大模型在硬件方面的一些需求上的差异:小模型在V100的时候甚至更小,比V100等同算力的硬件下面已经工作的非常好,比如早些年小模型的训练各个厂家打榜用1024个V100多快的时间训练,在时间的生产里面一般都在一个节点8个V100下面训练几天就可以训练出来,这是个小模型。当时以比较好的硬件单个节点做训练是完全可接受的,也是实践中比较常用的。如果在线推理的话,一个卡都用不满,连一个只有V100几分之一性能的T4都绰绰有余,这是小模型的时候。大模型对硬件的要求就变得高得多了,现在大模型还是发展的阶段,大模型和大模型之间的大小差异也非常大,也有百倍的差异,有10个Billion的也有上百个Billion,对硬件的需求差异比较大。我们和比较多的公司或产业有过合作,我们看到的更多的是百这个量级,H100或H800或者A100、A00,100还是200还是512,这是比较常见的。如果是ChatGPT的模型的话,根据爆料应该是万这个级别,这是做训练。做推理,现在单个节点一般来说都是够的,不管什么模型,更常见的单个卡也已经够了,毕竟现在的硬件性能也已经比之前有一个飞跃的发展。
大模型是不是意味着一定是几百个卡才能完成的任务呢?不是,大模型里面训练也分为预训练和微调,预训练用卡比较多,比如GLM130B的模型要2000多个A100,训练一个月到几个月之间,不同的模型不一样,这个预训练模型是消耗算力比较大的。但是对于微调来说,对于资源的消耗小很多,比如基于一个开源的LLaMa模型进行一些微调,一个配置比较高的单节点是可以完成的,时间长一点而已,如果是更小的模型,单卡都是可以完成微调的。现在大家也会发现他们会通过一些技术减少模型的大小,通过量化的手段通过剪枝的手段,不断的把大模型裁小。对推理来说,大部分情况下一个卡是足够的,我们收集到了模型使用的资源情况,比如刚才说的LLaMa2,如果是7B的模型的话,它对显存的占用也就是28个G,以现在的中高端的GPU来说就算是一个不大的消耗了,单卡都能完成,半个卡都已经足够了。百川13B的或7B的都是单卡就可以完成了,它对显存的占用并没有那么高,能把显存缩下来用了很多技术。
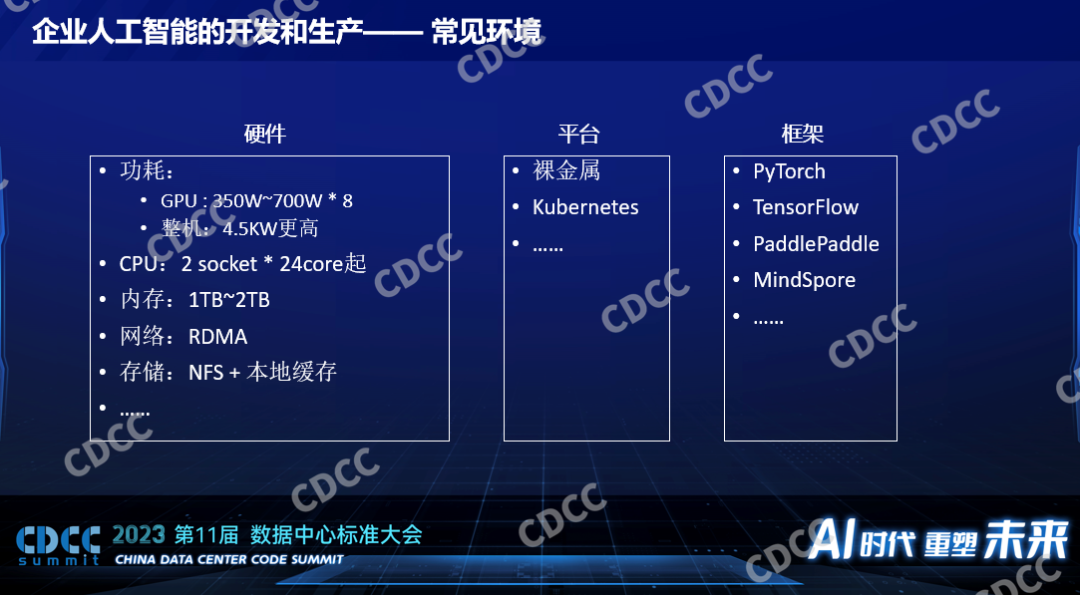
一个企业要开展人工智能的开发需要什么样的条件,它要考虑哪个方面的事情,这是影响数据中心建设的一个重要因素。所以这里面讲到的数据中心的建设,包括一些企业部署他内部使用的私有的环境,也有一些会把数据中心贡献给到第三方贡献到外部去使用的情况。对于所有数据中心建设来说都是用户的需求驱动的,这是比较常见的一个企业要开展人工智能方面的开发和生产他们需要的一些事情,当然首先要有硬件,其次在管理这个平台上面因为他要做训练,他要做推理,而且推理的任务不是一个而是多个,他一定会有一个平台。现在80%以上的客户都是基于Kubernetes管的,和超算不一样,超算用Slurm,人工智能用Kubernetes是比较通用的,这是一个平台能够让任务分发到我们的硬件上面去运行,在上面不同的模型不同的算法要基于一些框架,这些框架在开源界有PyTorch、TensorFlow等,随着国产化的需求以及国内科技的进步,百度主导的PaddlePaddle,它是开源的,华为的MindSpore比PaddlePaddle晚一点。这是不管是开源、学术还是企业用的比较多的框架。
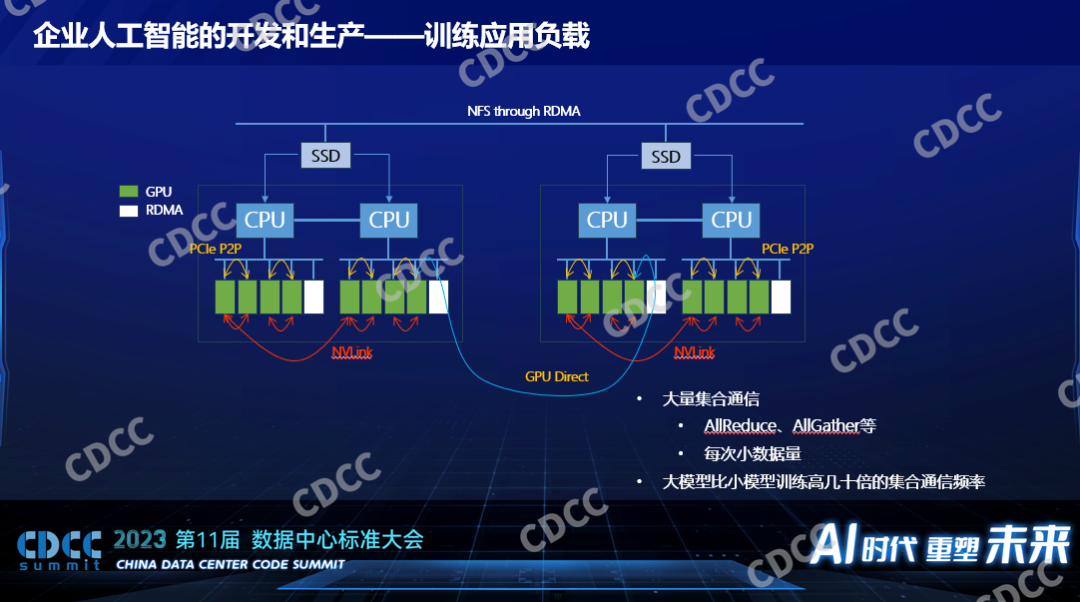
在数据中心建设里面仍然要考虑的是人工智能背后的负载究竟是什么。对于训练来说,一个分布式训练,一般说来都是多卡,如果是大模型还是多节点也就是分布式,我们知道数据中心建设,网络是一个非常关键的因素,我们考虑算法或者模型在训练过程中对网络的冲击是怎么样的,它分好几层,卡和卡之间的交换如果是英伟达有NVLink,点对点的传输,如果对于没有NVLink的来说,也有基于PCIE Swich的协议,可以完成卡到卡的通讯,对CPU的负载比较低,只在节点内完成,只要在硬件配置或者服务器的采购定制上面做好就行。如果是服务器和服务器之间的训练来说,RDMA几乎是必备的,没了它性能会慢到不可接受,所以每个节点上都会有配IDMA。而现在以英伟达为例的这种卡都支持GPU Direct,GPU和GPU之间的通讯不过CPU,它通过底层的硬件技术和驱动的配置,数据可以从一个GPU卡直接通过PCIE Swich到RDMA卡到另一个节点的RDMA卡直接灌到GPU上去,完成数据的交换。训练的时候要有数据,AI的数据以读为多,写的少,一个典型得用法就是通过网络的存储方案配合本地的高速缓存,当然本地的高速缓存需要平台需要框架支持使用,一般来说会用高速的SSD作为缓存。
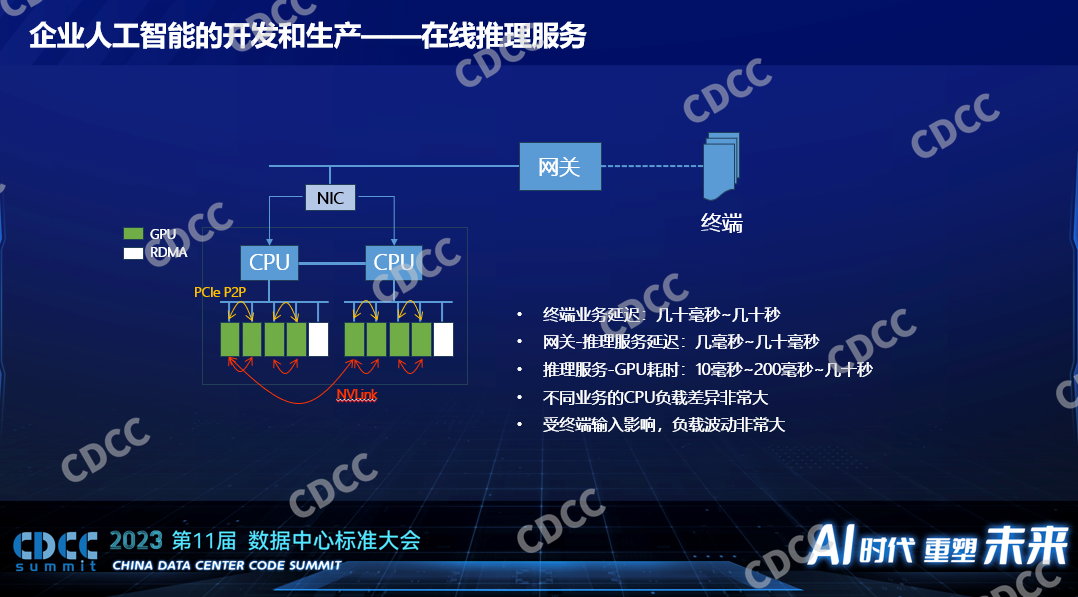
在线推理对于硬件的需求就少多了,大家会特别关心一个推理的性能吗,不一定,一个在线的推理服务对端到端的性能有很多方面的影响,终端是手机到达数据中心或者到达企业的网关本身就有几十毫秒的延迟,里面为什么写了几十秒呢,指的是得到一个业务的返回,以GPT为例,发一幅图片给它,它把结果给我,人可以接受的延迟最长可以长到几十秒,如果是刷人脸的话,人可以接受的延迟大概是500毫秒到1秒。落到GPU运算或者AI运算,这个延迟在整个通路里面占小头,尤其在以前小模型里面它占小头,在以前小模型的时候我们听到的业务需求是几百个毫秒到1秒它都可以接受,这个时候用来做推理的延迟一般才10个毫秒到小于100个毫秒,这个时候我们的算力低一点在小模型时代并不会影响端到端的服务质量,如果我们要做数据中心建设的话我们一定要考虑上面的推理服务究竟是什么类型的。
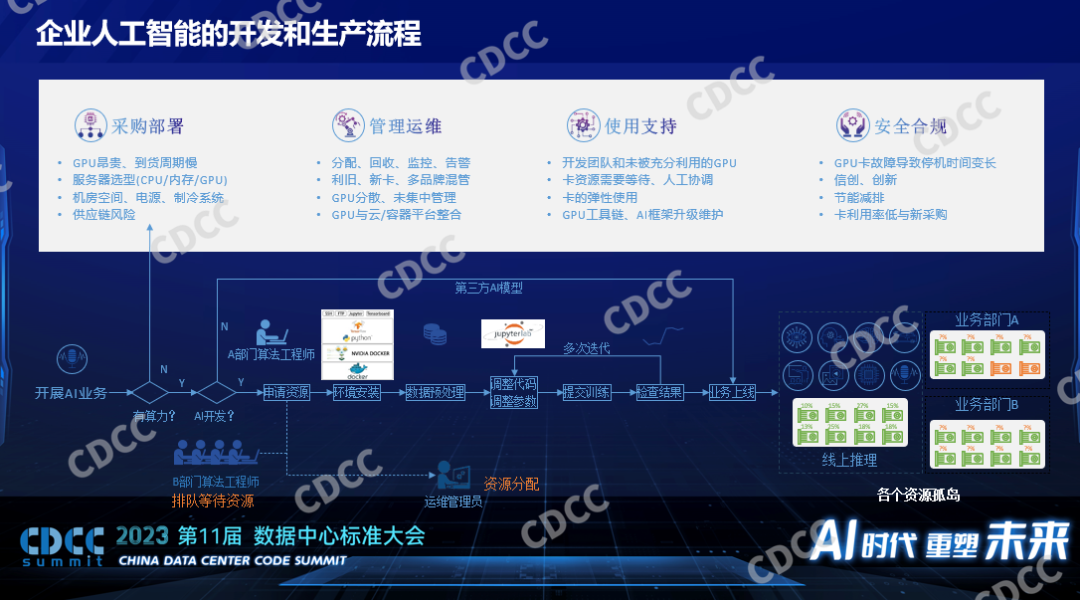
一个企业开展人工智能生产流程有很多环节,如果我们要做开发而不是采购第三方的模型的话,我们涉及到的采购就会比较多,我们要去采购部署,要有相关的运维,运维只能解决硬件故障的问题,刚才说的平台层、框架层,还要由更上一层的团队去支持。对数据中心来说我们要满足很多合规的要求,我们要知道GPU卡的故障率非常高,如果是消费级的卡甚至还有起火的案例,在整个过程中我们要考虑的是各个部门对于GPU集群使用的需求是什么,它要求有的部门做训练,有的是推理的,他们是否要求独占不同的资源,这也都是我们要考虑到的。
03. 面向人工智能的数据中心建设
根据我们对行业的观察,我们发现有一些数据中心在使用GPU时候的挑战:
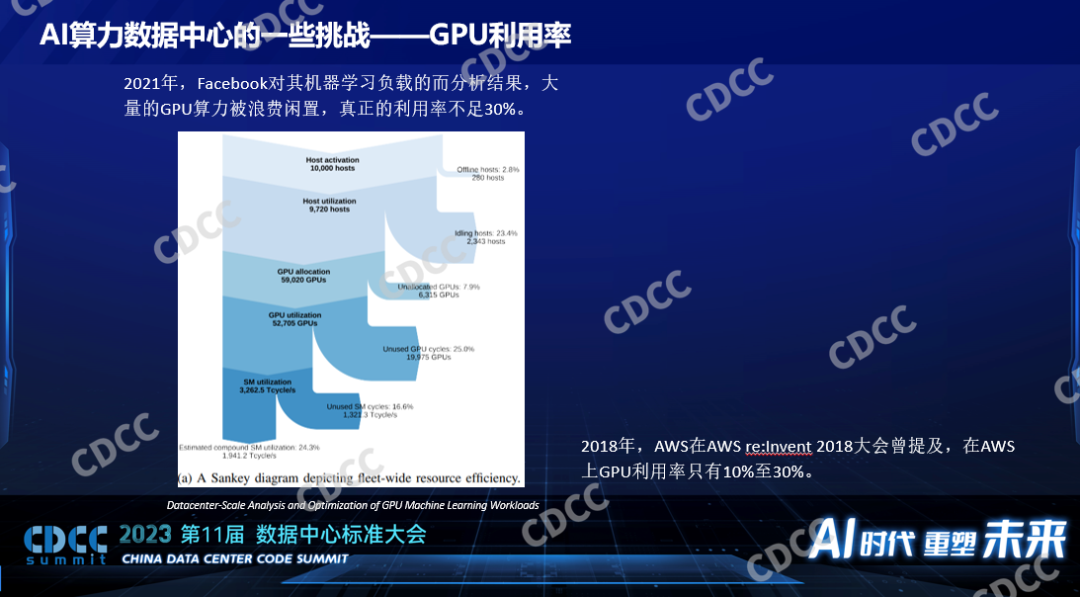
一是利用率。由于各种环节它都有损耗,导致最后GPU的实际利用率只有20%-30%,这是Facebook公开的一个数据,他们对GPU平均的实际的利用率只有10%-30%,每个环节都有可能引起它的损耗。
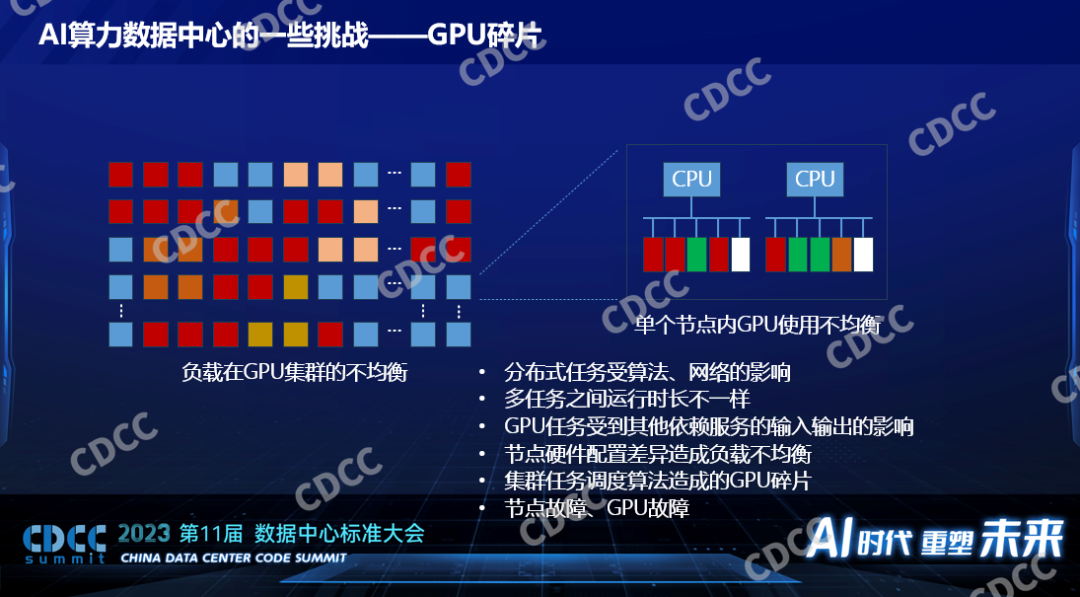
二、GPU碎片。这是引起损耗的一个重要因素,即使是百卡甚至千卡的分布式的大模型的训练,也由于算法本身的特征,它并不是每个节点的每个卡都被100%使用的。我们观察到的是大概有50%在大模型的训练里面而且是一个不大的规模,百这个级别只有50%的GPU在100%被使用,还有50%经常会空闲,当然它不是静态的,它是变化的过程。如果规模更大,比如GPT以万为级别的训练,根据他们公开的数据也只有30%的GPU利用率,以及每个节点也会出现有的卡被用满,有的卡没有被用上,这是GPU碎片。

三、功耗碳排放。不同模型的碳排放的指标是非常高的,像训练一个BLOOM模型,30吨的二氧化碳的排放,一个GPT3 552吨的碳排放。
训练和推理的需求非常不一样,小模型和大模型对硬件的需求也是非常有差异,管理异构的硬件配置对于数据中心的运维来说是非常大的挑战。要解决这些问题,业内曾经给过一个很通用的方案,像存储,我们之前用磁盘也遇到过类似的问题,磁盘的碎片怎么解决的呢?把磁盘变成一个分布式的存储,这样的话应用在使用存储的时候从来不用关心我使用的磁盘是本地磁盘还是别的节点的磁盘,只要我整个机群里面的磁盘还有冗余,我的应用就可以使用,GPU之所以有这些缺点,因为它现在还不具备这个特征,对于我们公司来说使用的软件就是让GPU一个一个独立的GPU卡就像当初一个一个独立的磁盘一样,能够把它聚合起来,在数据中心里面通过网络,对于应用来说它呈现的是一个最基本的算力,已经被还原成算力了,而不是一个一个的卡,这个时候只要我这个数据中心还有一张卡空闲,我的业务不管在数据中心的哪个节点,我都仍然可以使用这个卡的算力进行人工智能的计算,它可以解决负载不均衡、碎片等等的产生。
通过这个方案解决企业在AI开发和生产过程中各个阶段的痛点问题,像预训练、最后的上线,我们都提供了不同的支撑,比如双资源池可以让训练的性能更快,最后的显存和算力的超分支持热迁移,支持它最后业务的上线和生产。
04. 思考和展望
最后有几个思考,可以帮助我们提高GPU在数据中心中的利用率,尤其是对于一些私有化部署来说:
1、统一资源管理
越大的AI算力资源池效率越高
2、开发、训练、推理混合部署
通过不同大小的任务调度提高利用率
通过不同延迟敏感性的任务调度提高利用率
通过不同优先级的任务调度提高利用率
3、通过提高运维的手段,GPU出现故障的时候能够快速把它隔离出去,能够把业务迁移走,减少对业务的冲击。
审核编辑:黄飞
-
成都汇阳投资关于AI 算力持续爆发,数据中心高景气有望贯穿全年2026-05-21 392
-
电力重构:AI算力狂潮下,数据中心UPS系统的极限挑战与范式转移2025-12-31 777
-
华为星河AI高算效数据中心网络亮相ODCC 20252025-09-16 2920
-
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级2025-08-13 730
-
简单认识安森美AI数据中心电源解决方案2025-07-05 3956
-
DeepSeek推动AI算力需求:800G光模块的关键作用2025-03-25 1199
-
施耐德电气如何助力数据中心行业平衡能耗与算力2025-03-24 1108
-
AI算力需求激增,数据中心如何应对能源挑战2025-02-22 1542
-
算智算中心的算力如何衡量?2025-01-16 6743
-
智算中心会取代通用算力中心吗?2025-01-06 1451
-
一图看懂星河AI数据中心网络,全面释放AI时代算力2024-03-22 1740
-
华为全联接大会2023|瞄准多元算力网络挑战,华为发布L4数据中心自动驾驶网络方案2023-09-27 1694
-
专家对话 算力激荡,维谛技术模块化数据中心如何满足AI高算力需求2023-09-01 1278
-
数据中心冷却的一些技巧和诀窍2019-11-28 3629
全部0条评论

快来发表一下你的评论吧 !
