

隐私计算在分布式认知工业互联网中的应用研究
描述
作者简介
刘乃嘉
中国信息通信研究院工业互联网与物联网研究所硕士研究生在读,主要从事区块链、新型工业互联网标识、隐私计算等方面的研究工作。
郭健
中国信息通信研究院工业互联网与物联网研究所区块链开发工程师,从事区块链底层链开发、分布式数字身份等方面的研发工作。
李海花
中国信息通信研究院工业互联网与物联网研究所副所长,正高级工程师,主要从事与信息通信相关的政府支撑、战略咨询、新技术跟踪研究、标准研制等工作。
论文引用格式:
刘乃嘉, 郭健, 李海花. 隐私计算在分布式认知工业互联网中的应用研究[J]. 信息通信技术与政策, 2023, 49(11): 25-32.
隐私计算在分布式认知工业互联网中的应用研究
刘乃嘉 郭健 李海花
(中国信息通信研究院工业互联网与物联网研究所,北京 100191)
摘要 :现有的工业互联网数据在互联互通过程中存在难以安全共享的问题,工业互联网发展模式急需创新。首先细化了分布式认知工业互联网的技术架构,其次探讨了工业互联网领域在数据共享与利用方面的困境,并提出了隐私计算在具体工业应用场景下的解决方案,最后根据实际需求给出了隐私计算在分布式认知工业互联网中的发展建议。
0 引言
工业互联网通过实现各个环节的信息共享和协同创新,可以加强供应链、生产链和销售链之间的协作与优化,进而提升产业链现代化水平,对于支撑制造强国和网络强国建设具有重要意义。2020年,我国出台了《工业和信息化部办公厅关于推动工业互联网加快发展的通知》
,指出了“加快发展工业互联网基础设施建设、健全工业互联网安全保障体系”的必要性。工业大数据作为工业互联网的核心,承载着从数据的采集、加工到集成,再到建模分析,最后向顶层服务进行决策支撑的能力。如何打破工业互联网中的“数据孤岛”问题,实现工业大数据的隐私保护和价值挖掘成为研究重点。目前,工业互联网发展已由起步期进入快速发展期。在此阶段,研究新一代信息技术(如物联网、5G通信、边缘计算、隐私计算等)与工业互联网的深度融合应用,有助于健全工业互联网安全保障体系,进一步提高工业互联网服务实体经济能力。因此,急需探索适用于工业互联网创新发展的新型技术模式。
1 工业互联网核心功能架构
工业互联网是一种将工业与信息网络高度融合的网络,其核心功能是基于数据驱动的物理系统与数字空间进行全面互联与深度协同,实现各设备厂商的信息集成和共享,以及在此过程中的智能分析与决策优化。如图1所示,现有工业互联网的核心功能架构可细分为边缘层、基础设施(Infrastructure as a Service,IaaS)层、平台(Platform as a Service,PaaS)层以及应用(Software as a Service,SaaS)层。边缘层连接工业互联网平台与底层物理资产,提供针对不同工业设备的工业数据接入能力和针对多源异构数据的协议解析与转换功能。IaaS层主要为工业互联网平台提供硬件支撑。PaaS层基于底层通用的资源管理、运维管理、流程管理、数据管理等模块,为工业建模提供高质量数据源,建立与工业数据模型库相关的微服务组件,并针对不同场景融合工业机理建模方法和数据科学建模方法,实现工业大数据价值深度挖掘。SaaS层部署工业创新应用,将创新软件引入工业互联网平台中,为用户提供各种工业应用解决方案。
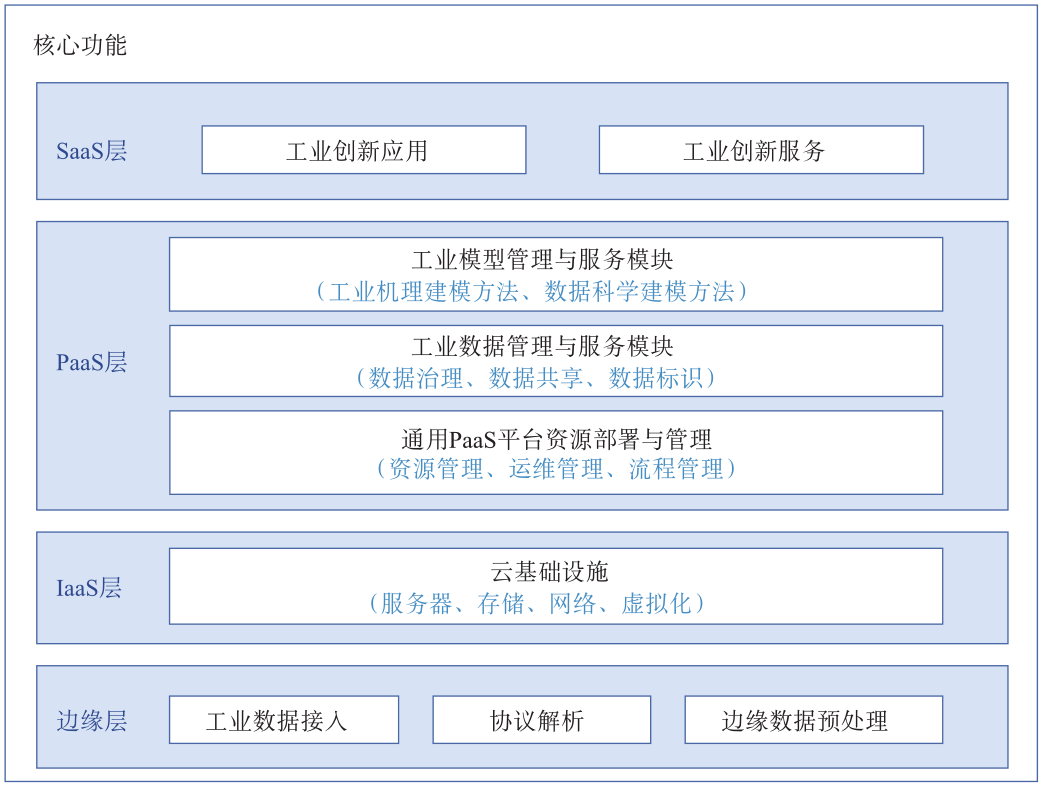
图1 工业互联网核心功能架构
2 分布式认知工业互联网技术架构
分布式认知工业互联网概念在2020年首次提出,通过将区块链技术、隐私计算技术、知识图谱技术深度集成到工业互联网平台架构,解决目前工业互联网尚未解决的问题。借助区块链技术的数据真实、透明、不可篡改等特性,实现更加安全可信的工业制造协同生态;融合应用知识图谱技术与机器学习技术,有助于深度挖掘工业大数据价值;隐私计算技术作为研究重点,可以在符合数据隐私保护和监管要求的前提下,保障工业数据的可信流转与高效利用。本文在工业互联网核心功能架构的基础上进一步细化了分布式认知工业互联网架构(如图2所示),主要分为边缘层、基础设施层、区块链层、数据协同层、认知智能层、平台层、激励层以及应用层。
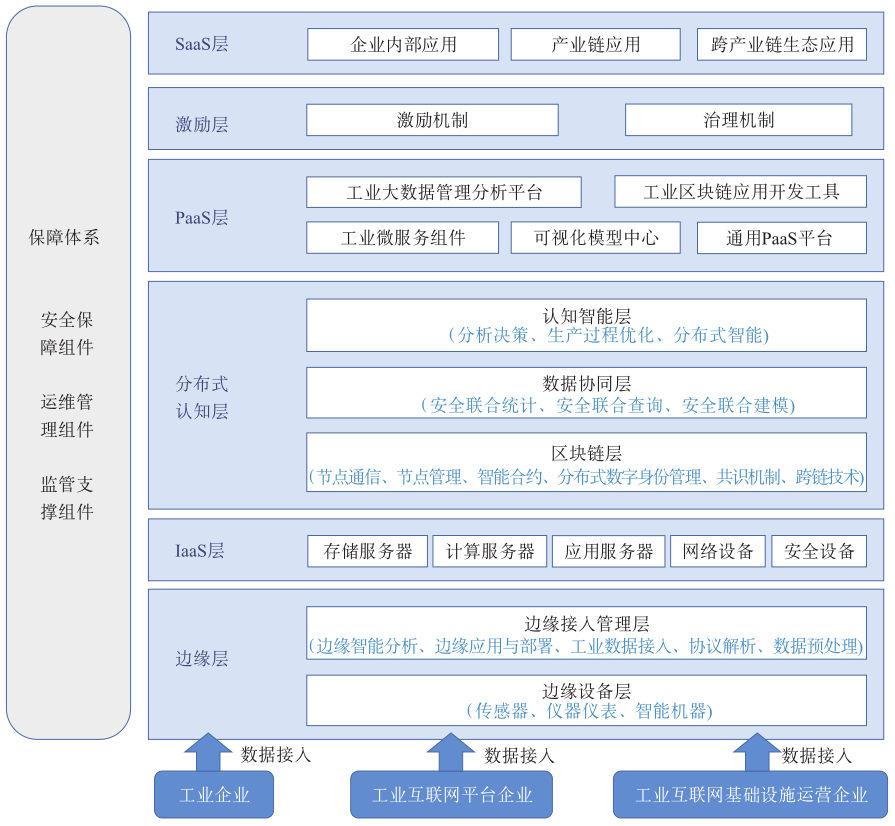
图2 分布式认知工业互联网技术架构
2.1 边缘层
边缘层包括边缘设备层和边缘接入管理层。边缘设备层由各种设备(如传感器、仪器仪表、智能机器等)组成,与相关工业企业、工业互联网平台企业、工业互联网基础设施运营企业等进行交互,完成数据接入过程,保障工业数据安全的存储、分析和计算,高效、精准的数据服务,向区块链提供可信数据。
边缘接入管理层包含边缘智能分析、边缘应用部署与管理、工业数据接入、协议解析、数据预处理等功能组件,通过工业数据可信接入实现与区块链层、PaaS层的信息安全交互。边缘智能分析对现场生产进行高效精准的优化决策,支持在边缘端实现分布式的工业智能数据分析和处理,满足边缘业务的实时性、可靠性以及多样化需求。边缘应用部署与管理组件支持应用管理协同,支持边缘节点部署运行环境以及相关应用。工业数据接入功能需具备各类异构工业设备的数据接入能力,以及企业资源计划系统、制造执行系统、仓库管理系统等系统的数据接入能力。协议解析和数据预处理中,需要进行数据合规性检查、数据质量检查以及多源异构数据的转换与适配,之后进行数据剔除、压缩、缓存等操作,将敏感工业数据上链存储。
2.2 IaaS层
基于分布式认知的基础设施包括存储服务器、计算服务器、应用服务器、网络设备和安全设备等。其中工业数据的存储可以通过区块链技术分布在边缘侧,工业数据的多方协同可以通过密文计算来实现,复杂的领域及行业知识可以以图谱的形式展现。
2.3 区块链层
区块链层将区块链技术集成到工业互联网平台架构。区块链技术源于Satoshi Nakamoto 在2008年提出的比特币系统,该技术可以利用分布式节点来进行数据的存储及传输,已被应用在金融、物流、物联网等多个领域。其中节点通信主要依赖点对点(Peer to Peer,P2P)网络,这是一种分布式节点网络,节点之间相互建立通信链接,区块链的P2P架构在面对恶意网络攻击时具有更高的安全性和可靠性;节点管理是区块链节点形成P2P网络所进行的合作,共同完成节点间的数据交互,用于支撑分布式网络的运转;智能合约是以信息化方式自动执行合约条款的协议,能够在无第三方参与的情况下完成可信交易,交易结果可溯源且不可篡改。分布式身份管理支持身份真实性认证,使用安全加密算法和协议生成用户唯一标识,通过用户唯一标识可以查询成员身份信息,不同节点查询的用户信息保持一致,基于区块链的数字身份将可识别的用户身份标识和用户身份验证的公钥信息锚定在区块链上,不再依赖于中心化身份提供商,身份由用户自己控制。共识机制是分布式的区块链节点就当前时间窗口内的实物达成状态一致性的方法,是解决区块链网络中各个节点在分布式系统运行期间的互信问题的关键 ,目前广泛应用的共识机制有工作量证明机制、权益证明机制以及拜占庭容错算法。跨链技术兼容多种异构区块链及跨链机制,保障良好的可扩展性,包括可信执行环境验证机制、公证人机制、侧链机制等。
2.4 数据协同层
数据协同层将隐私计算技术集成到工业互联网平台架构,满足企业对工业数据可用不可见、可用不可存、可控可计量的需求,其中包括同态加密、安全多方计算、联邦学习、机密计算、差分隐私等多种关键技术,逐渐被划分为基于密码学算法、人工智能技术、可信硬件的三大技术方向。安全多方计算以及差分隐私等技术依赖于严格的密码学理论,其中安全多方计算主要有混淆电路、同态加密、秘密分享3种形式,主要面向的是在多个参与方的环境下,每个参与方都拥有自己的私密信息,同时又希望利用其他信息来共同完成计算一个函数的过程。其中差分隐私是针对统计数据库的隐私泄露问题提出的一种隐私保护技术,通过加噪声的方式避免原始信息外露,可以去除个体特征,保障数据提供方敏感及隐私数据的安全,在工业互联网领域中数据敏感性较高的复杂场景有较高的应用价值。联邦学习依赖于人工智能技术,根据原始数据的分布规律主要分为横向联邦学习、纵向联邦学习及迁移联邦学习,可以做到各个参与方的自有数据不出本地,而后通过加密机制下的参数交换方式,在保障数据隐私的情况下,建立一个虚拟的最优共有模型。可信执行环境、机密计算等技术依赖于可信硬件,硬件隔离可以保护设备处理器及内存等组件不受用户安装应用程序的影响,保证在该环境下所加载的数据和执行的程序的机密性、完整性。
上述3种方向的隐私计算技术侧重点不同但仍可以组合使用,在实际应用时的主要计算场景包括安全联合统计、安全联合查询和安全联合建模等。安全联合统计包括基础计算、联合排序等,安全联合查询通过隐私求交、隐匿查询等方式完成数据查询任务,安全联合建模联合多方数据建立深度学习模型。
2.5 认知智能层
认知层将知识图谱技术集成到工业互联网平台架构。知识图谱本质上是一种揭示实体之间关系的语义网络
,其重要性在于推进了异构数据的结构化过程,让数据建立链接关系,为各种算法的介入提供支撑。其在分布式认知工业互联网架构内的发挥作用有3点,一是将知识图谱的理解、分析、决策能力赋能到产品全生命周期过程中,从而实现自适应、自优化的产品设计、资源调度、决策管理、流程优化和智能制造;二是以行业和企业内部的数据为主要来源,快速对企业整体运行情况和外部机遇进行分析,辅助战略布局;三是面向行业/地域的数据集成分析,可有效评估产业健康情况、优化产业格局。
2.6 PaaS层
PaaS层集成了工业大数据管理分析平台、工业区块链应用开发工具、可视化模型中心及工业微服务等通用平台能力,同时也可以横向对接外部成熟的通用工业互联网平台,以被集成或相互调用的方式来互为补充。
2.7 激励层
激励层的激励及治理机制是分布式认知工业互联网架构中的重点,只有在有效的激励及治理模式下,再依托区块链中的智能合约技术快速开发应用、服务或者小程序,助力行业内适配性相对较低的工业智能应用程序逐步下沉并实现场景化应用。多方参与者实现信息共享是构建工业互联网互联互通的前提,激励层的治理机制主要依托于区块链层的存证和多方验证的能力,保证价值链从生产过程到交付、服务、检修,形成完整的闭环数据监控;激励层的激励机制依托于区块链中的价值交换,通过设计适度的经济激励机制激励区块链中大规模节点参与共识过程。在分布式认知工业互联网中,通过优化针对信息共享的激励,实现产业链供应链上的利益协同。
2.8 SaaS层
SaaS层将多种底层技术在不同的场景中以单一或者组合方式使用出来,形成不同的工业应用。从参与者范围来看,可以区分为企业内部应用、产业链应用、跨产业链生态应用。企业内部应用指分布式认知工业互联网平台的参与者属于同一个实体企业;产业链应用指参与者属于相同行业供应链上下游之间的关系型企业;跨产业链生态应用指参与者不但包括行业供应链上下游的实体,还包括为产业链提供各种服务的生态机构,如物流、法务、公证、银行、保险、政府、公共基础服务机构等。
实际场景中,根据区块链、隐私计算等技术的应用特性,可以构造多种企业内部的工业应用。设备身份认证、设备访问控制、数据存证等应用较为常见,同时这些应用也可以组合在产业链应用和跨产业链应用中。在产业链应用方面,研发与产销协同、质量追溯、产品生命周期管理等是较为常见的场景;在跨产业链生态应用方面,引入多种类型的企业服务机构(如金融企业、政府、法务等),利用数据在多个参与方之间安全共享的特点,可以打造供应链金融、融资租赁、政府监管等多种应用。
3 隐私计算在分布式认知工业互联网中的应用
3.1 工业产品自动化质检与可信协作
在离散型工业制造供应链上,通常由多个零件生产商为下游企业供应同一规格零件,零件的批量较大,一般采用人工抽样检测的方式来进行工件质检。这也造成了两个问题,一是随机抽样方式不覆盖所有工件;二是检测完全依赖检验员的业务经验和工作态度,质检效果波动大、效率低。生产商一方面需要基于其他生产商的全量样本数据进行模型训练,但另一方面不希望将零件数据本身的信息透露给其他生产商。因此,亟需建立一种原始数据不出本地、基于跨企业数据共享的分析挖掘方式。
在分布式认知工业互联网中,采用基于安全多方计算的数据流通架构,利用服务平台功能将流水线每个环节采集到的问题工件图片,通过安全多方计算进行共享。计算节点使用共享数据集进行机器学习联合训练,生成并使用问题工件预测模型,给企业进行全量自动化质检。平台主要实现多方安全计算、区块链存证、数据传输以及供需对接功能,从而实现数据可用不可见、可控可计量、模块化与易开发,在保障数据安全的前提下,提高了计算的性能与数据的价值。参与实施的供应商各自提供带有划痕和缺陷的工件图片,通过数据共享进行联合模型训练(如图3所示),可以大幅提升模型准确率。
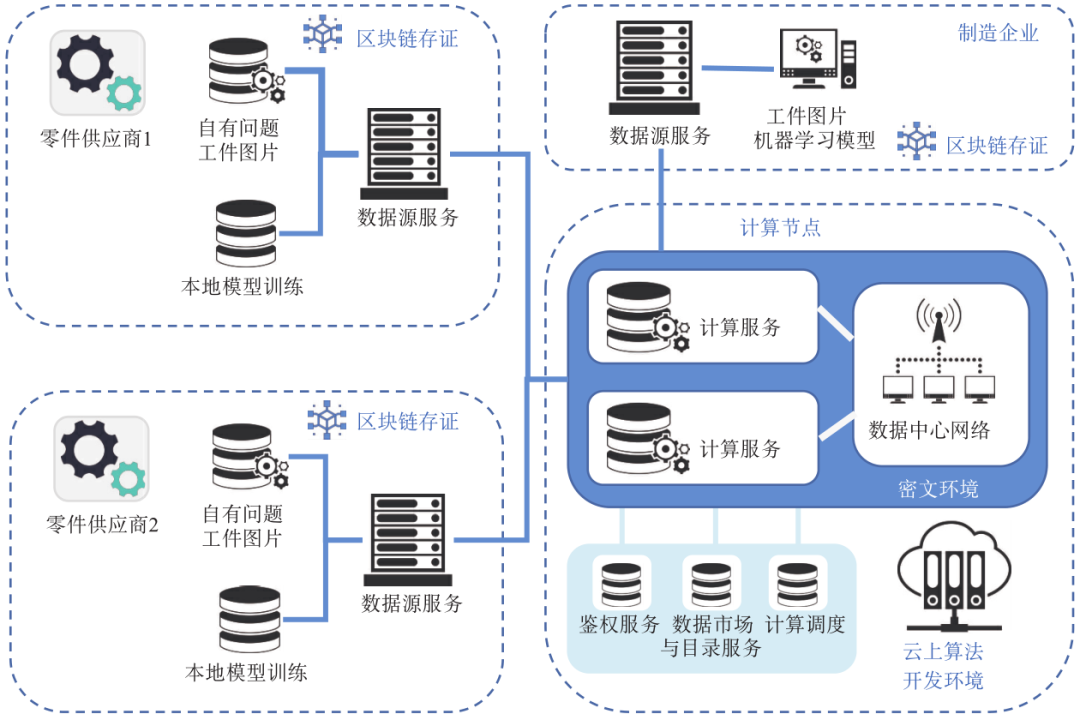
图3 自动化质检与可信协作模型
3.2 工业互联网网络安全防护
大部分传统工业企业依靠物理方式实现厂内数据、网络与外界的隔离,工业互联网的出现打破了其物理隔离屏障,但同时也使互联网中存在的一些安全威胁蔓延到了工业网络,需要加快工业互联网网络安全防护体系的升级与变革。在分布式认知工业互联网中,通过隐私计算技术可以实现设备、数据、网络等要素的安全访问和操作控制。
工业环境设备、网关设备、云基础设施等设备之间的身份识别与认证是实现工业互联网网络安全防护的基础,分布式认知工业互联网中采用零信任、主动式网络安全防护理念,任何网络访问都需要基于身份认证,需要对访问主体的风险和信任度进行持续评估,动态授予访问权限。通过消息认证、数字签名等基础密码学辅助隐私计算技术,可以防止身份隐私数据外泄,实现相关设备之间的可信认证。结合区块链技术中的共识机制、智能合约以及隐私计算技术数据可用不可见的特点,设计工业数据的管理规则、存储规则以及交易规则,根据工业数据敏感度采用分等级(一般数据不加密、重要数据部分加密、敏感数据完全加密等)的加密存储措施,为数据安全提供可行、高效、低成本的防护方案。此外,通过部署诱骗系统,吸引攻击者并记录攻击行为,通过隐私计算中的联邦学习模型分析新型攻击的特点。在此基础上,建立联动机制使防火墙、入侵检测系统、反病毒系统、日志处理系统等安全技术和产品协同工作、联动运转,跟踪回溯攻击源,学习新的入侵规则并反哺安全防护体系。
3.3 工业隐私数据全生命周期保护
工业隐私数据全生命周期分为工业数据采集、工业数据存储、工业数据流转、工业数据利用与工业数据追溯五个阶段。在数据采集阶段,采用搭载可信芯片的物联网设备为终端对真实数据进行实时采集,利用同态加密、数据脱敏、差分隐私等隐私计算技术保障数据安全并将密文上链存储。在数据存储阶段,利用区块链的分布式存储技术形成不可篡改的数据记录,有效防止单点攻击,避免攻击者获取完整的隐私数据,保障数据存储安全。在数据流转阶段,工业数据提供方为工业数据、工业加密数据、计算因子以及部分运算结果的提供方。工业数据使用方为工业数据或运算结果的需求方,需求参数的提供方。随着数据提供方和使用方数量增多,以及双方对数据的使用形式和深度提出的不同需求,在分布式认知工业互联网架构的基础上,结合隐私计算技术,可以打造更为安全的工业数据流转模式,多家企业可以使用多方安全计算,共享工业数据样本,共同训练神经网络模型(如图4所示)。除了安全多方计算,数据沙盒和联邦学习也是常见的数据流转方式。隐私计算技术使得工业数据的共享与流通在连接性、可信度以及应用深度上均有提高。在数据利用阶段,根据工业数据使用方的不同计算需求搭建联邦学习或可信计算平台,各参与方共建工业数据虚拟模型,数据本身无需移动即可实现多方数据的高效利用及训练,在保障数据隐私的前提下不断挖掘其价值。在数据追溯阶段,结合区块链及隐私计算技术,对交易、设备、产品等信息实现可信、难以篡改的溯源查询。
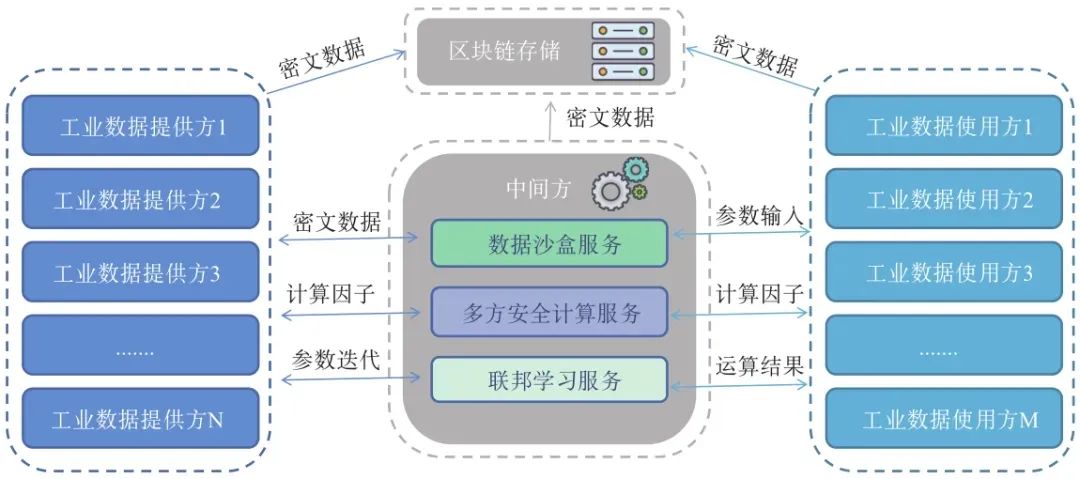
图4 工业隐私数据安全流转模型
4 隐私计算面临的挑战与展望
隐私计算发展至今分化出了多种技术路线,多种隐私计算框架并存且短期内无法得到统一,在性能、安全性等方面都各有侧重。例如,基于密码学算法的隐私计算技术依赖于严格的密码理论,计算性能受到密码学算法的制约;融合联合建模的隐私计算技术存在各参与方计算性能不一致的问题,同时对网络连接状态及网络带宽有较强的依赖,计算效率受到网络状态的制约;基于可信硬件的隐私计算技术需要较高的硬件投入,隐私保护能力受到硬件厂商可信度的制约。因此在实际使用过程中,需要针对不同的工业互联网应用场景具体设计,综合考虑性能、安全性、可扩展性、成本等多方面因素来选用合适的隐私计算技术类别,也要考虑所选技术类别与其他技术(如区块链、知识图谱、边缘计算等)的融合运用难度,尽量选择具有更高可信度和安全性的机构作为主要参与方,并提前考虑其他参与方进行恶意攻击造成的影响和应对措施。
5 结束语
隐私计算技术的优点使其近年来受到了各个领域的持续关注,在工业互联网领域也成为了工业数据难以安全共享问题的重点解决方案。本文在工业互联网核心功能的基础上,重点阐述了分布式认知工业互联网功能架构,聚焦区块链、隐私计算等技术,结合工业互联网领域的业务特点,提出了包括工业产品自动化质检与可信协作、工业互联网网络安全防护、工业隐私数据全生命周期保护在内的三大应用场景,并分析了隐私计算尚存的挑战与展望。隐私计算在满足国家法律法规及相关政策的前提下可以实现多方数据价值的最大化,在各种工业互联网细分应用场景中将会发挥更加重要的作用。
本文刊于 《信息通信技术与政策》 2023年 第11期
审核编辑:汤梓红
-
分布式IO工业自动化数据采集与分析的核心2023-12-28 1578
-
工业互联网中的标识解析技术2023-09-19 1147
-
EtherCAT分布式IO助力工业互联网的发展趋势2023-04-14 2556
-
工业边缘计算在工业物联网的四大应用场景2020-11-20 6070
-
IIOT分布式计算发布,可使基于数据中心的云计算更靠近物联网设备2020-10-22 2624
-
飞凌嵌入式LS1028A系列核心板正式开售!让5G和边缘计算为工业互联网赋能!2020-09-22 2094
-
邀约 | 2019中国工业互联网应用场景特色展2019-08-22 3665
-
分布式工业物联网云平台是怎样的2019-06-25 2159
-
几款国产开源分布式任务调度系统2019-05-06 6355
-
继移动互联网之后,区块链技术或将成为下一个风口2018-11-22 3124
-
互联网与工业物联网之间的区别与联系2017-06-14 5773
-
工业互联网2016-01-25 3815
-
【MiCOKit申请】互联网智能刷卡考勤系统2015-08-20 3532
-
大规模分布式互联网应用的测量2011-05-30 959
全部0条评论

快来发表一下你的评论吧 !
