

芯科技,解密ChatGPT畅聊之算力芯片
描述
在今日飞速发展的科技浪潮中,OpenAI的ChatGPT如一颗璀璨明星,引领着智能对话的新潮流。ChatGPT不仅是一款聊天机器人程序,它背后的驱动力是一个庞大而复杂的算力网络。这个网络依赖于先进的GPU服务器,尤其是英伟达的A100 GPU,提供了强大而精确的计算能力。ChatGPT的功能远超日常对话,它能够学习、理解并生成人类般的文本,是人工智能领域的一个重要突破。但其真正力量的源泉,是背后那些不断工作的算力芯片,它们让ChatGPT能够实时响应和进化,成为我们生活和工作中的得力助手。
本期是“芯科技”栏目第一期,文末有惊喜,千万别错过!
作为OpenAI研发的聊天机器人程序,支撑ChatGPT运转的可不是简单的一台机器,而是一个庞大的算力网络。这个算力网络可以抽象为三层:传输网络、计算网络和存储网络。如下图:
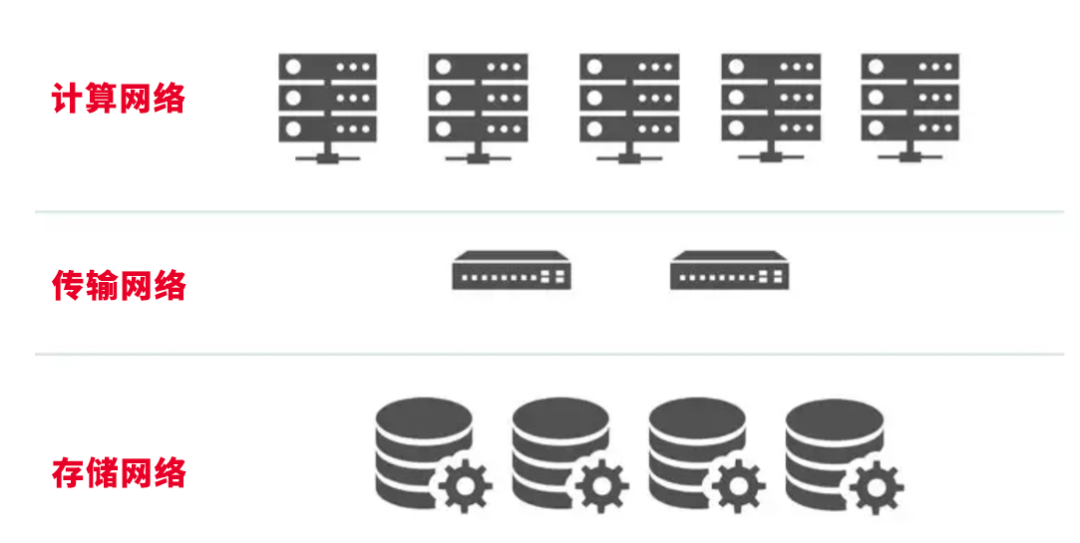
图:算力网络示意图
当前,大部分算力网络所采用的是GPU服务器,并广泛使用英伟达A100 GPU。A100 GPU属于算力芯片的一种,类型是GPGPU,此外还有专用的ASIC,比如NPU、VPU和TPU等,以及传统的CPU和FPGA等。我们通过下面这张图能够比较直观地看到GPGPU在性能、算法精度、通用性等方面的优势。
|
算力芯片对比 |
||||
|
指标 |
GPGPU |
CPU |
FPGA |
ASIC |
|
算力性能 |
高 |
极低 |
较高 |
高 |
|
芯片成本 |
高 |
中 |
较高 |
高 |
|
系统成本 |
中 |
高 |
高 |
低 |
|
功耗 |
中 |
低 |
中 |
中 |
|
能效比 |
中 |
极低 |
高 |
高 |
|
通用性 |
强 |
强 |
强 |
无 |
|
算力精度 |
丰富 |
单一 |
单一 |
单一 |
|
算法适配 |
丰富 |
单一 |
单一 |
单一 |
|
数据并行能力 |
强 |
差 |
强 |
强 |
|
适用场景 |
云端训练和推理 |
任务调度类 |
云边端推理 |
云边端训练和推理 |
图:算力芯片分类
综合而言,GPGPU是一款算力性能高,算力类型丰富,算法框架适配完全,数据并行能力强的算力芯片,更加适合当前多模态AI模型的发展。
在算力网络中,GPGPU芯片要发挥性能光靠自己可不行,需要系统的配合。在这个系统内:CPU负责任务调度;GPU负责主要的算力输出,也就是计算任务;内存负责数据暂存,配合GPU进行计算。
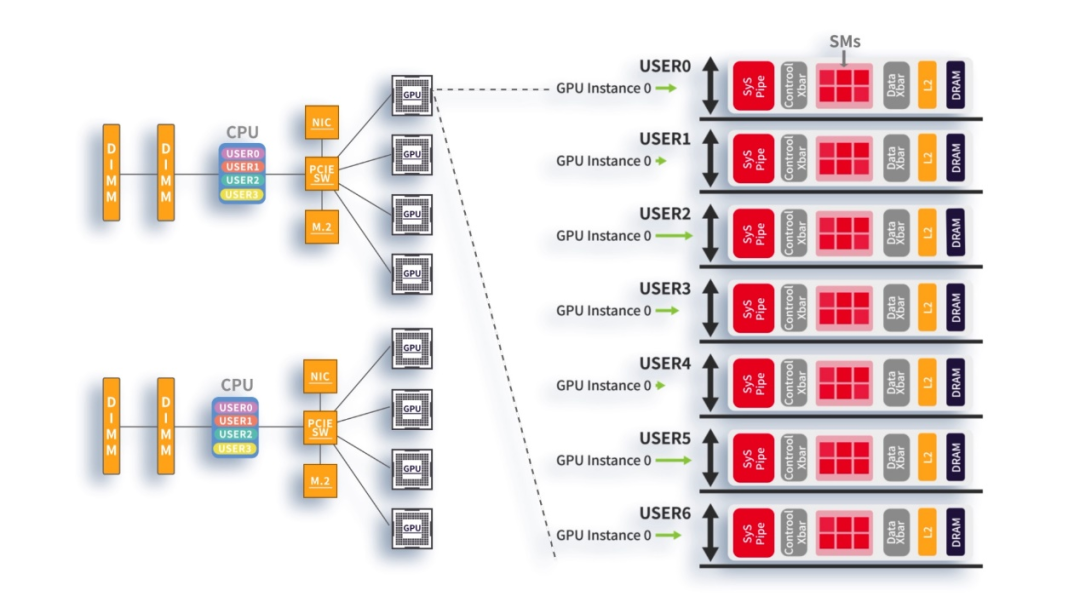
图:算力网络芯片分工示意图
为了提升计算效率,减少数据传输的延时,英伟达A100在芯片封装内搭载了HBM内存,其具有传输距离近,速度带宽高,堆叠容量大的优势。
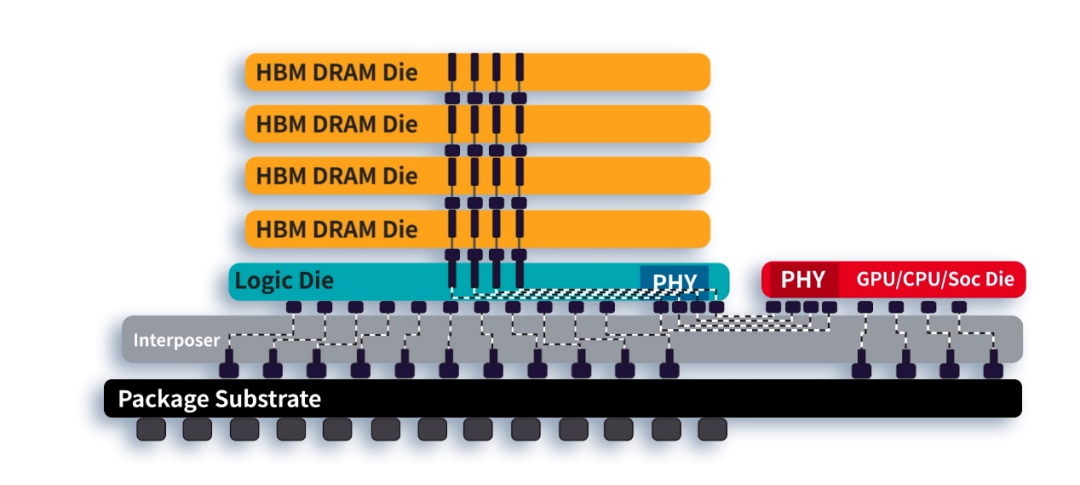
图:HBM内存,示意图
HBM这种芯片封装内搭载内存的方式,成本是比较高的,因此大部分AI服务器选择将计算芯片和内存分开,为了提升这种方式下内存的传输速度,内存标准也在不断演进,已经迭代到DDR5。
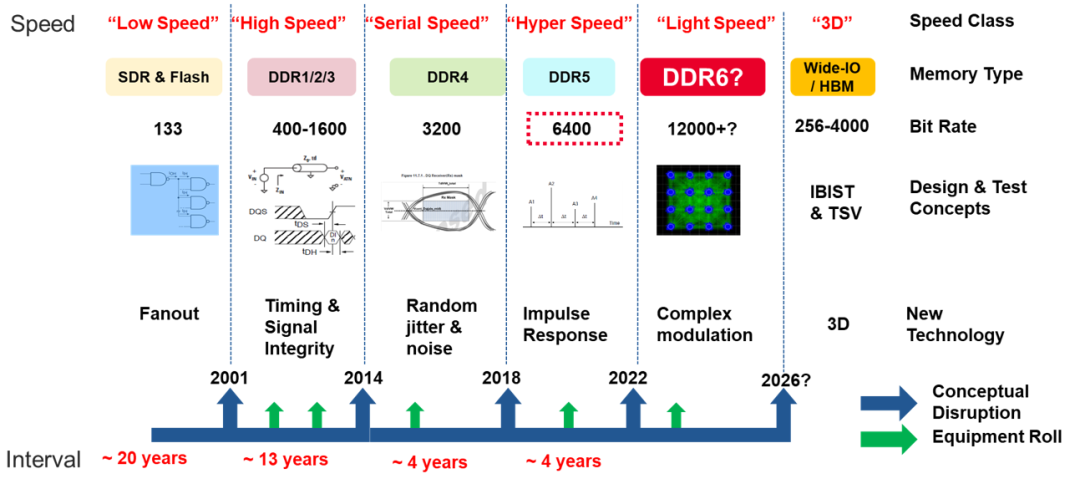
图:内存技术发展
内存的发展趋势是速度更快、尺寸更小、功耗更低。为了保障内存的高性能和稳定性,在测试环节,需要进行各种功能、性能和可靠性等方面测试,其中需要用到高速误码仪,示波器,协议分析仪,一致性分析软件等软硬件组合,如下图:
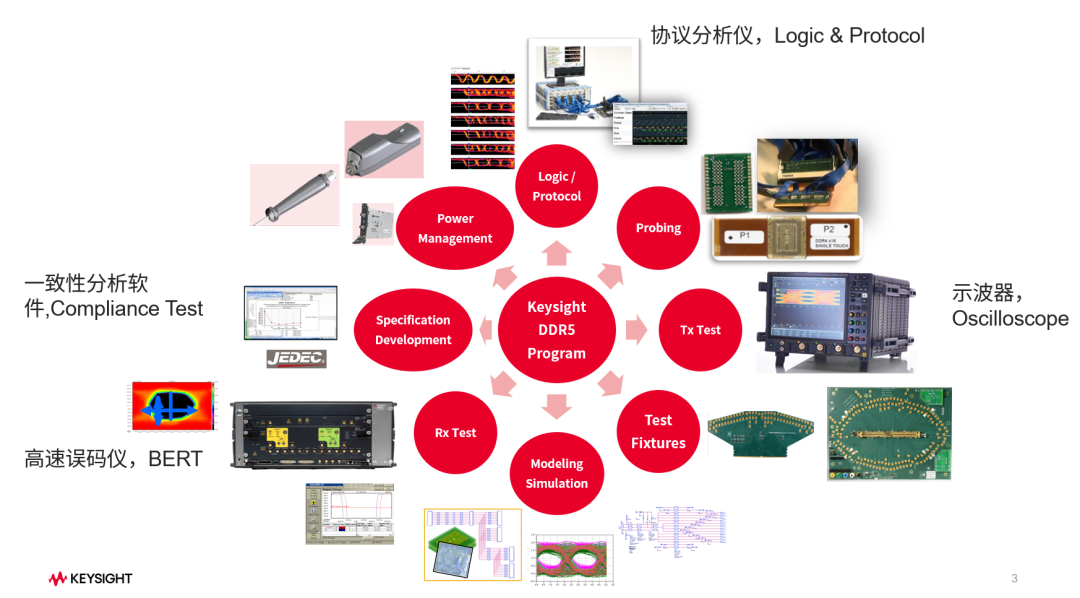
图:是德科技DDR5测试拓扑图
是德科技,对算力芯片,总线技术PCIe/CXL,存储技术DDR/LPDDR等都有完整的解决方案,更多有关算力芯片测试,请参考文章下载链接:
点击注册
作为是德科技 “芯科技” 系列第一期,我们特意为大家准备了精美的礼品抽奖,也欢迎大家留言,把你想学习的知识,你和是德科技的故事,一起告诉小编!
- 相关推荐
- 热点推荐
- 是德科技
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
昆仑芯AI芯片以AI算力服务实体经济 筑底算力经济新基建2022-10-19 4040
-
用国产通用GPU打造中国版ChatGPT的算力底座2023-03-01 3152
-
如何测算ChatGPT算力需求?2023-03-02 3227
-
ChatGPT背后的算力芯片2023-05-21 5121
-
【核芯观察】ChatGPT背后的算力芯片(二)2023-05-28 4632
-
【核芯观察】ChatGPT背后的算力芯片(三)2023-06-04 4215
-
云端算力芯片为什么是科技石油?2023-07-12 2097
-
ChatGPT算力芯片如何做算力输出2024-01-11 1347
全部0条评论

快来发表一下你的评论吧 !
