

智能驾驶芯片TOP20排名
描述
智能驾驶芯片排名并不简单只看AI算力,CPU、存储带宽、功耗和AI算力数值一样重要,这个下文会详细分析。CPU算力也很重要,智能驾驶系统软件异常复杂,会消耗大量的CPU运算资源,软件系统包含众多中间件诸如SOME/IP、自适应AUTOSAR、DDS、ROS等,基础软件包括订制的Linux BSP、OS抽象层、虚拟机,还有与底层硬件关联的内存管理、各种驱动、各种通讯协议等等。除此之外,应用层中的路径规划、高精度地图、行为决策等也大量消耗CPU资源,同时CPU也管理AI运算时的任务调度、存储搬运指令等,整体的任务调度、决策自然也是CPU的任务。CPU是绝对的核心,AI是CPU的附属功能,只是在做图像特征提取、分类、BEV变换、矢量地图映射或空间分布占有时才用到AI。
排名的权重依次是AI算力、存储带宽、CPU算力、GPU算力、制造工艺。存储带宽和AI算力同等权重,GPU也是锦上添花,大部分车载AI处理部分只能对应INT8位数据,而GPU可以对应FP32数据,有些时候可能有很大作用。实际AI算力数字完全是个黑箱,操作空间极大,参考意义不大。最能准确衡量算力的是MAC阵列数量,谷歌的TPU V1是65000个FP16 MAC,运行频率0.7GHz,那么算力就是65000*0.7G*2=91TOPS。特斯拉第一代FSD两个NPU,每个NPU是9216个INT8 MAC,运行频率是2GHz,算力就是2*2*2G*9216=73.7TOPS。制造工艺方面,自然还是越先进,功耗越低。
智能驾驶芯片TOP20
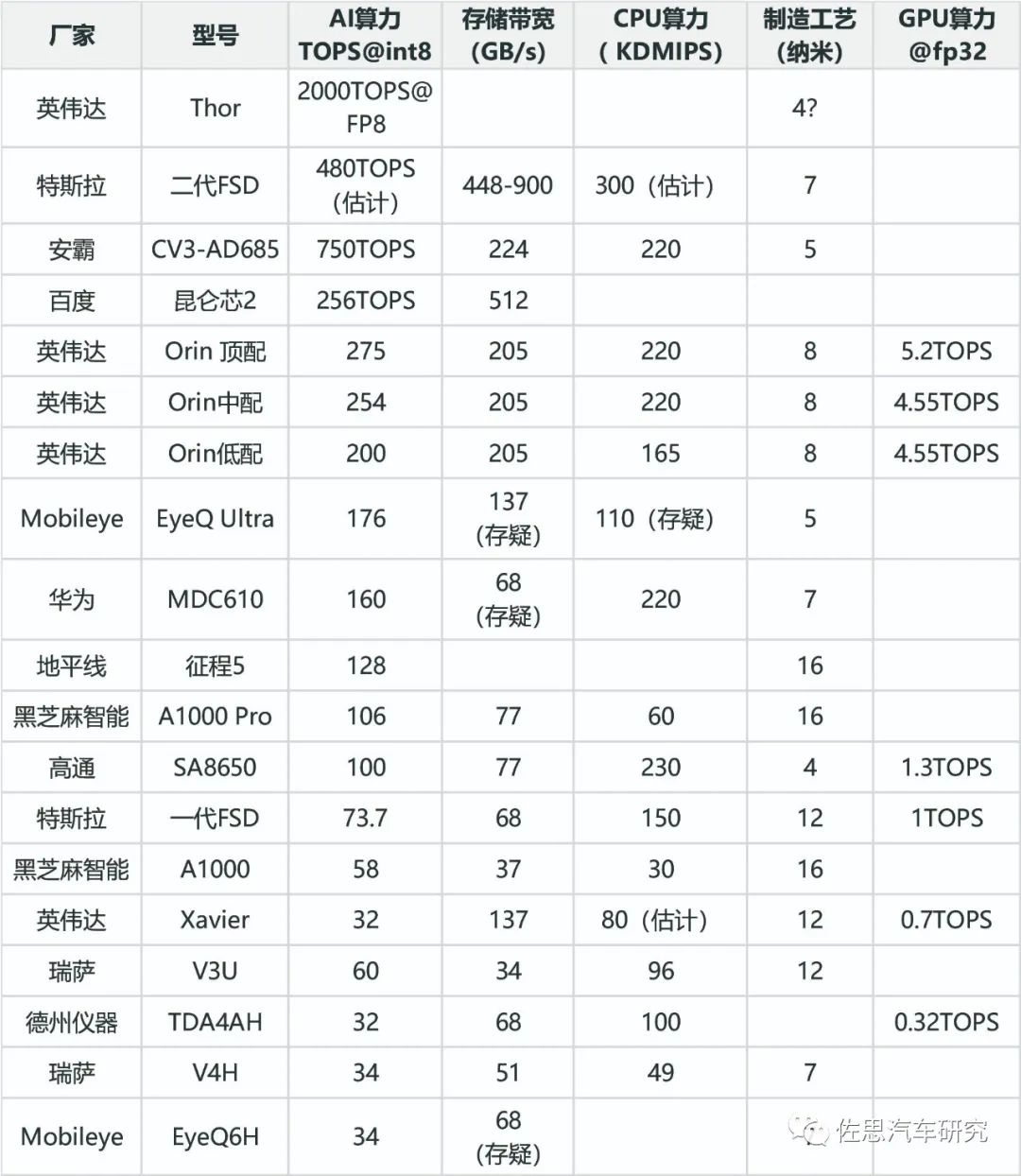
图片来源:公开资料整理
如何计算存储带宽,芯片本身都有存储管理器,这通常是CPU的一部分,决定存储带宽的有两点,首先是CPU支持的存储类型,即存储的物理层和控制器,其次是CPU的存储带宽,LPDDR的存储带宽最高一般是256比特,GDDR可以到384比特,HBM可以到4096甚至8192比特,这些都关联成本,厂家在设计芯片时,会在成本和性能之间找一个平衡点,有些厂家偏重成本,那就64比特甚至32比特,有些偏重性能,如真正的AI芯片,无一例外都是HBM的,成本都在1500美元以上。
常见汽车内存性能与价格对比
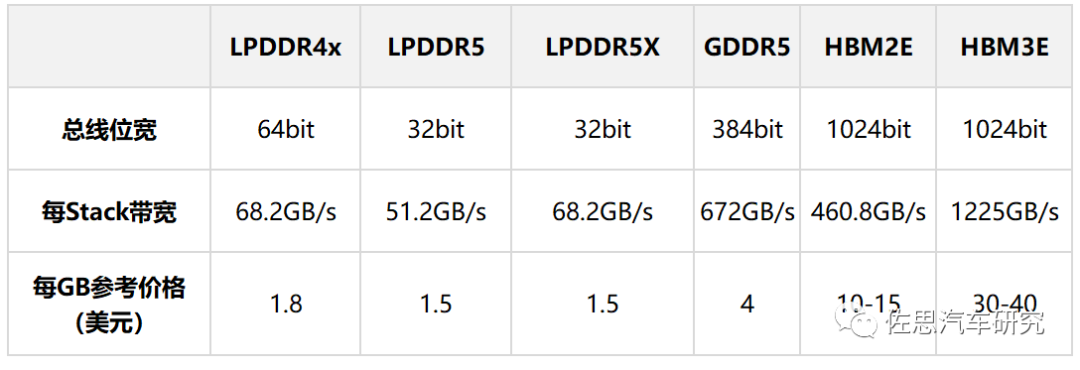
图片来源:公开资料整理
上表为常见汽车内存性能与价格对比,显然,一分价钱一分货。英伟达H100是HBM3的最大采购者,每GB的采购价格大约14美元。还有一点需要指出,目前没有车规级GDDR6存储芯片。
目前智能驾驶芯片除了百度和特斯拉,都采用了LPDDR。
历代LPDDR的参数
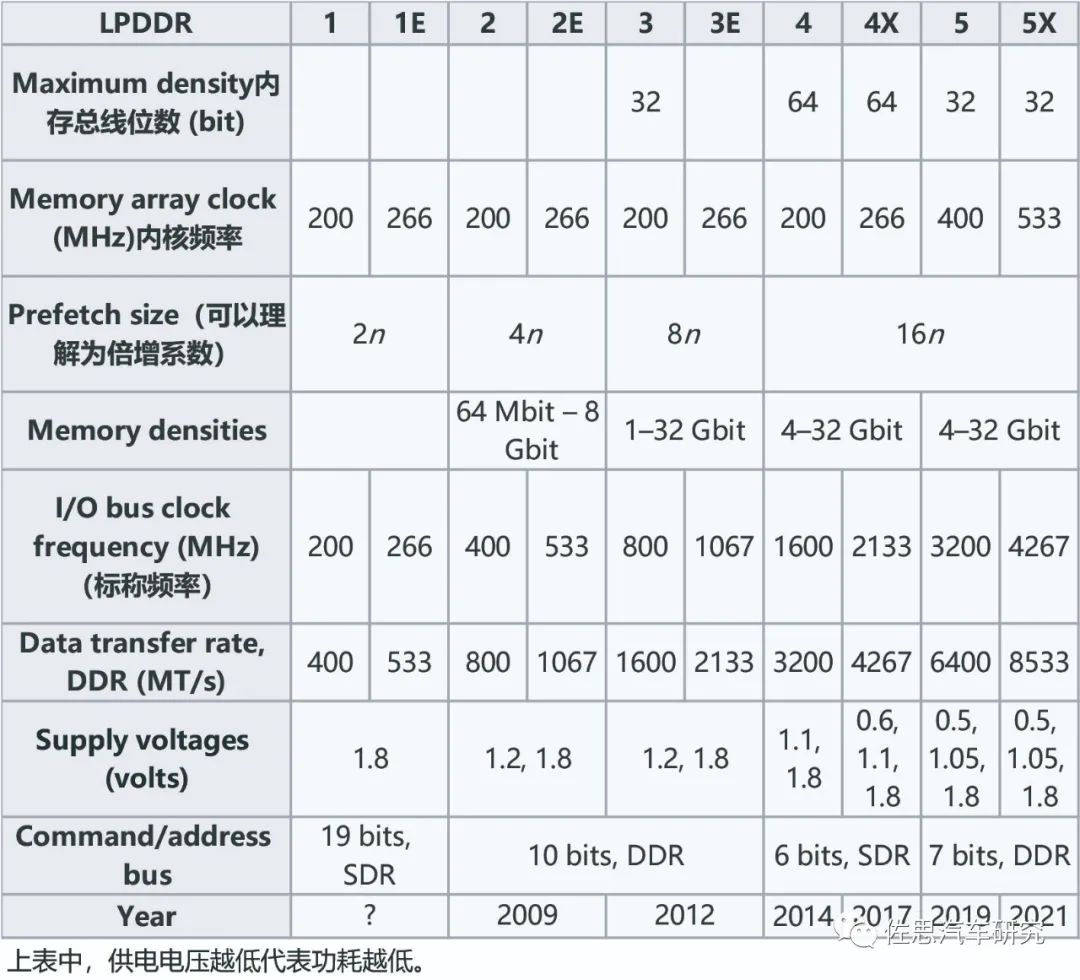
图片来源:公开资料整理
存储带宽等于CPU的存储位宽乘以存储器的Datatransfer rate, DDR (MT/s)再除以8换算为大写的GB,例如英伟达Orin其存储位宽是256比特,支持LPDDR5,传输速率为6400MT/s,那么存储带宽为256*6400M/8=204.8GB/s,再比如特斯拉一代FSD,存储位宽是128比特,支持LPDDR4,传输速率为3200MT/s,存储带宽就是128*3200M/8=51.2GB/s。
存储带宽如此重要的原因是Roof-line模型,Roof-lineModel 解决的,是“计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少”这个问题。
模型计算量指的是输入单个样本(对于CNN而言就是一张图像),模型进行一次完整的前向传播所发生的浮点运算个数,也即模型的时间复杂度,单位是FLOPS。访存量:指的是输入单个样本,模型完成一次前向传播过程中所发生的内存交换总量,也即模型的空间复杂度。在理想情况下(即不考虑片上缓存),模型的访存量就是模型各层权重参数的内存占用(Kernel Mem)与每层所输出的特征图的内存占用(Output Mem)之和。计算量除以访存量就可以得到模型的计算强度I (Intensity),它表示此模型在计算过程中,每Byte内存交换到底用于进行多少次浮点运算。单位是FLOP/Byte。模型在计算平台上所能达到的每秒浮点运算次数(理论值)。单位是 FLOP/s,即P。
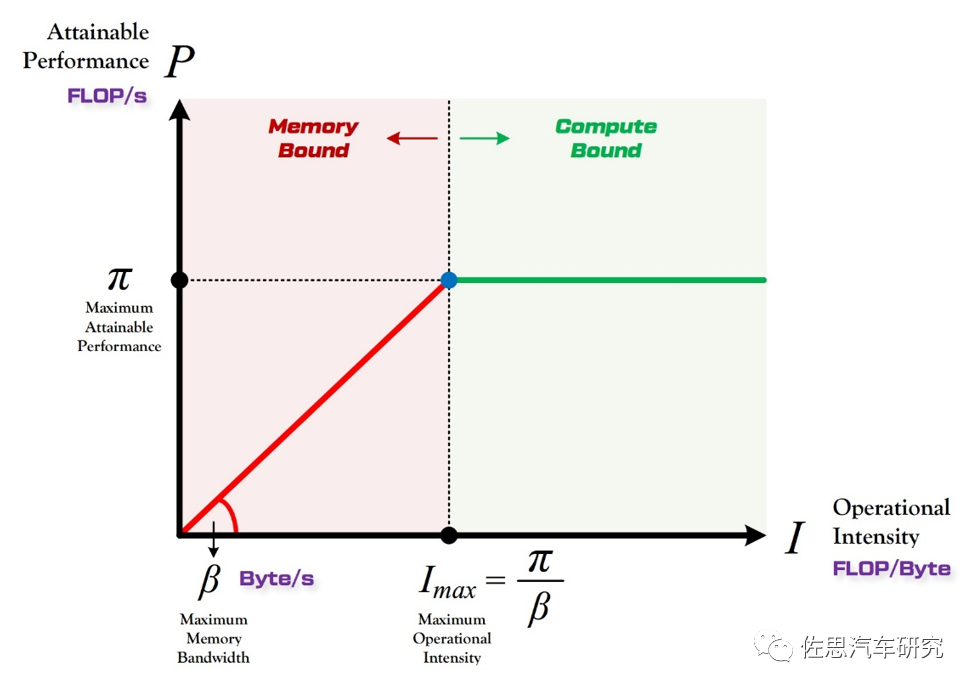
算力决定“屋顶”的高度(绿色线段),带宽决定“房檐”的斜率(红色线段)
模型计算的理论性能自然不可能超过其硬件的最大理论性能,如果有一个异常消耗算力的模型,其需要的算力超过了计算平台的理论性能,那么计算平台的利用率是100%,也就是红色线段部分,这时的风险就是处理图像的帧率或者说FPS会达不到目标帧率,对智能驾驶来说,主流帧率是30FPS,低速智能驾驶可以再降低一点,高速需要再升高一点。由于需要的算力太高,计算平台满负荷运转也无法适应,帧率会下降,此时高速行驶的话就会有风险,一般来说,厂家不会推荐算力需求远超理论性能上限的模型。
在低于100%利用率的绿色线段部分,模型理论性能 P 的大小完全由计算平台的带宽上限(房檐的斜率)以及模型自身的计算强度 I (Intensity)所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽即房檐越陡,或者说模型的计算强度 I 越大,模型的理论性能 P 可呈线性增长。斜率越低,意味着即使计算强度快速增加,计算平台算力的增加还是很缓慢,计算平台的利用率很低,比如计算平台的理论算力是100TOPS,斜率很低,很高计算强度的模型利用率也可能不到50%,换句话说,存储带宽决定了计算平台的性能利用率,因此存储带宽重要性丝毫不亚于算力,甚至高于算力。这也是为何特斯拉二代FSD排名第二的主要原因,GDDR6的带宽相对LPDDR有压倒性优势。
特斯拉第二代FSD

图片来源:网络
特斯拉第二代FSD采用了三星的7纳米工艺,之所以用三星代工,主要可能还是价格和地理因素,三星代工的价格远低于台积电,只有台积电价格的一半左右,台积电的亚利桑那厂效率低下,从2020年开工建设,预计到2025年才能投产,而三星的德克萨斯奥斯汀二代工厂仅用两年就完工投产,而特斯拉总部离奥斯汀也很近。第一代FSD使用三星的14纳米工艺,WikiChip的数据显示,三星7nm LPP HD高密度cell方案的晶体管密度在95.08 MTr/mm²,而HP高性能方案的晶体管密度则在77.01 MTr/mm²;三星14纳米UHP方案的晶体管密度则在26.22MTr/mm²,HP方案晶体管密度则在32.94 MTr/mm²,基本上三星7纳米是14纳米密度的3倍以上,意味着特斯拉至少可以塞进3倍多的MAC阵列,AI性能可以提升三倍,一代FSD的AI性能是73.7TOPS@INT8,3倍就是221.1,再像英伟达那样搞个稀疏模型加速,算力数字可以再增长一倍,加上二代FSD芯片面积明显比一代要大,且NPU增加到3个,因此估计算力在500TOPS上下。特斯拉二代FSD也大幅度加强了CPU,使用三星Exynos 20核心配置,这也说明CPU在智能驾驶中很重要。
安霸的CV3熟悉的人可能不多,其存储带宽支持最高的LPDDR5X,且是最高的256比特,采用三星的5纳米工艺制造,目前得到了德国大陆汽车公司的支持。
安霸CV3-AD内部框架图
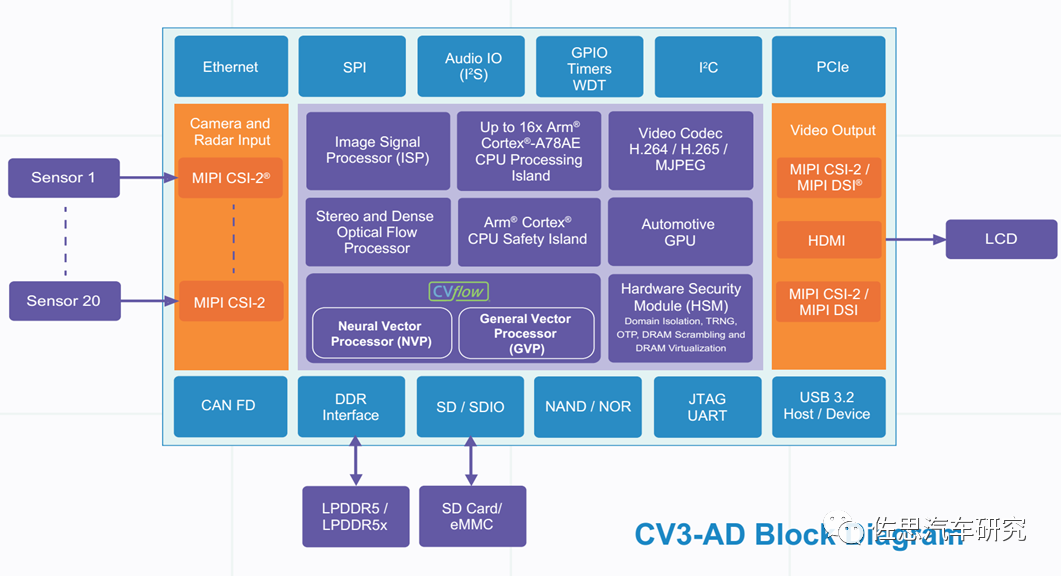
图片来源:Ambarella
安霸CV3-AD最高包括了16核心的Coretex-A78AE,CPU算力也是极高。也通过了ASIL-B级认证。AI算力方面是等效于500TOPS。英伟达的位宽是256比特,特斯拉和Mobileye大多是128比特,征程6未公布存储信息。
百度的昆仑芯2很少人知晓,实际这不能算百度的,它是百度芯片部分独立后的产物,公司全称是昆仑芯(北京)科技有限公司,前身为百度智能芯片及架构部,于2021年4月完成独立融资,首轮估值约130亿元。2022年11月29日,在百度Apollo Day技术开放日上,第二代昆仑芯在百度无人驾驶车辆RoboTaxi的驾驶系统上已经做了完整的适配,在高阶自动驾驶系统中运行正常。2011年,昆仑芯科技正式独立,开始从事AI计算相关的工作,早期使用FPGA芯片来对AI进行计算加速。2011-2015年之间,昆仑芯科技部署了超过5000片FPGA芯片用在百度数据中心,到了2017年累计部署超过12000片的FPGA芯片。并在2018年决定自研AI芯片,正式启动昆仑芯系列产品的研发和设计。2020年,第一代昆仑芯开始大规模地部署,2022年,第二代昆仑芯在数据中心、工业领域、自动驾驶等领域大规模地部署和落地。第一代昆仑芯是14纳米的人工智能芯片, 这款芯片采用了先进的HBM内存、2.5D的封装,芯片刚量产就在百度数据中心里面部署了超过2万片。一年后第二代昆仑芯量产,采用了更先进的7纳米工艺、XPU第二代的架构,也是业界第一颗采用GDDR6高速显存技术的AI芯片。昆仑芯科技正在研发更先进的第三代AI芯片,针对高阶自动驾驶系统,未来会考虑推出定制的车规高性能的SoC(系统级芯片)。
英伟达对存储系统一向比较重视,全线都是最高的256比特。高通SA8650与座舱领域的SA8255非常近似,CPU和GPU基本完全相同,AI算力做了特别加强,存储位宽是比较少见的96比特,SA8650是取代上一代SA8540P的,主要是增加了针对功能安全的部分,增加了4个Cortex-R52内核。Mobileye对成本异常重视,也从不公布其存储带宽和支持存储类型,只能猜测。Xavier虽是早期产品,但存储位宽是最高的256比特,所以排名很靠前。
审核编辑:刘清
-
“上传资料——做分享达人”活动第一周中奖名单及TOP20名单2012-07-30 7657
-
嵌入式技术频道2012年上半年最受工程师喜爱热文Top202012-08-15 2856
-
华大北斗高精度芯片助力上汽名爵MG7智能驾驶2023-08-30 1158
-
2011年芯片厂商TOP20排名 英特尔位居榜首2011-12-05 1522
-
2014年EDA/IC设计频道最受关注热文TOP202015-01-04 2892
-
2014年触控感测频道最受关注热文TOP202015-01-09 1670
-
国内企业管理SaaS软件TOP20排名2018-01-30 66843
-
兆芯入选中国半导体行业专利百强榜单IC设计企业TOP202021-02-04 6406
-
知行科技入选2022中国自动驾驶最具商业潜力科技企业TOP20榜单2022-12-08 3931
-
芯进电子入榜“2023未来之星·川商最具价值投资企业TOP20”2023-10-14 1293
-
亿铸科技登榜2023硬科技新锐之星TOP202023-12-25 1697
-
服务机器人企业YOGO ROBOT荣登《2023中国智能制造创新技术应用TOP20》2024-01-17 1683
-
普强荣获2024智能客服企业TOP202024-11-21 1165
-
云知声荣登2024数字技术创新企业TOP20榜单2025-01-23 1227
-
格陆博科技荣获2025低速无人驾驶行业TOP20核心供应链奖2025-12-24 2647
全部0条评论

快来发表一下你的评论吧 !
