

从Google多模态大模型看后续大模型应该具备哪些能力
描述
前段时间Google推出Gemini多模态大模型,展示了不凡的对话能力和多模态能力,其表现究竟如何呢?
本文对Gemini报告进行分析,总的来说Gemini模型在图像、音频、视频和文本理解方面表现出卓越的能力。其包括 Ultra、Pro 和 Nano 尺寸,能够适用于从复杂推理任务到设备内存受限用例的各种应用。
不像OpenAI接入多模态能力需要利用多个不同的模型,Google直接在预训练阶段直接接受多模态的输入是Gemini的特点之一,它能够直接处理多模态的数据,并且各项指标都还不错。另外可以看出具备图文理解等能力后,再结合大模型的对话能力,能够带来更惊艳的效果体验。
一、概述
1 Motivation
发布Google的能与GPT4竞争的大模型,同时兼具多模态能力,包括文字、图像、视频、音频识别与理解能力。
2 Methods
1 Gemini模型支持4种格式输入,2种格式输出
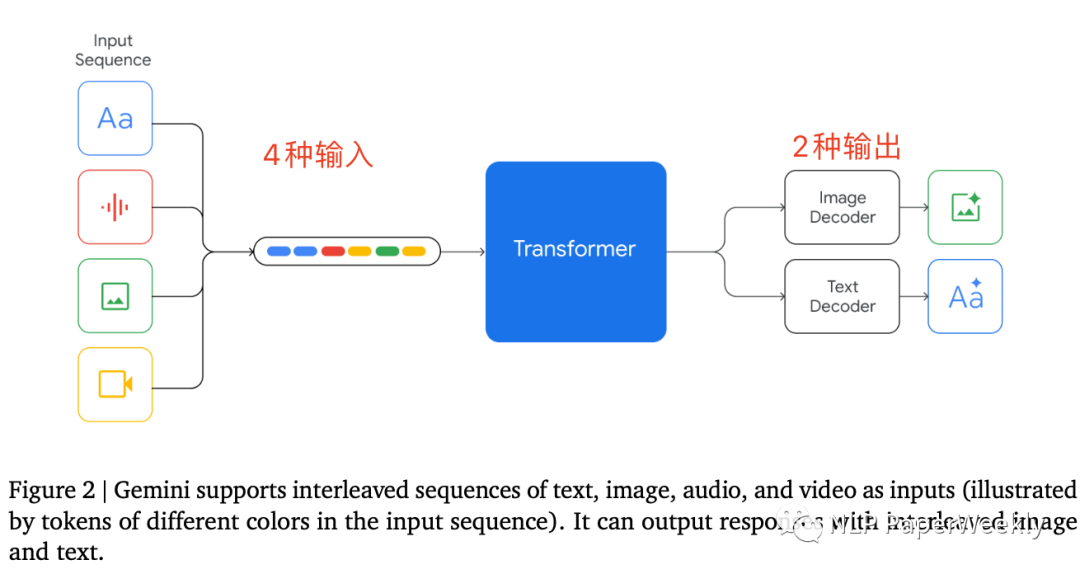
特点:同时支持text文本,image图像,video视频和audio音频输入,支持文本和图片的输出。可以直接处理音频文件,不需要将音频转为文字等。
猜测的训练方法:
多模态训练方法:Gemini是几种模态一起联合从头训练的,包括文本、图片、音频、视频等。这与目前通常的多模态做法不太一样,目前的多模态模型一般是使用现成的语言大模型或者经过预训练过的图片模型(比如CLIP的图片编码部分),然后利用多模态训练数据在此基础上加上新的网络层训练;如果是几个模态从头开始一起训练,那么按理说应该都遵循next token prediction的模式,就应该是LVM的那个路子,其它模态的数据打成token,然后图片、视频等平面数据先转换成比如16*16=256个token,然后搞成一维线性输入,让模型预测next token,这样就把不同模态在训练阶段统一起来。
解码结构:Decoder only的模型结构,针对结构和优化目标做了优化,优化目的是大规模训练的时候的训练和推理的稳定性,所以大结构应该是类似GPT的Decoder-only预测next token prediction的模式。目前支持32K上下文。
命令理解方面:和GPT一样,采用多模态instruct数据进行SFT+RM+RLHF三阶段,这里的RM部分在训练打分模型的时候,采用了加权的多目标优化,三个目标helpfulness factuality和 safety,猜测应该是对于某个prompt,模型生成的结果,按照三个指标各自给了一个排序结果。
模型大小:从硬件描述部分来看,意思是动用了前所未有的TPU集群,所以推测Gemini Ultra的模型规模应该相当大,猜测如果是MOE大概要对标到GPT 4到1.8T的模型容量,如果是Dense模型估计要大于200B参数。考虑到引入视频音频(当然是来自于Youtube了,难道会来自TikTok么)多模态数据,所以总数据量*模型参数,会是非常巨大的算力要求,技术报告说可以一周或者两周做一次训练。
训练细节:可能分成多个阶段,最后阶段提高了领域数据的混合配比,猜测应该指的是逻辑和数学类的训练数据增加了配比,目前貌似很多这么做的,对于提升模型逻辑能力有直接帮助。
代码能力:AlphaCode2是在Gemini pro基础上,使用编程竞赛的数据fine-tune出来的,效果提升很明显,在编程竞赛上排名超过85%的人类选手,之前的AlphaCode1超过50%的人类选手;
2 Gemini模型有多个版本,最小有1.8B

特点:其中Nano首先从大模型蒸馏,然后4bit量化。Gemini Nano包含两个版本:1.8B面向低端手机,3.25B面向高端手机。
3 Conclusion
1 文本理解:Ultra性能超过了GPT4
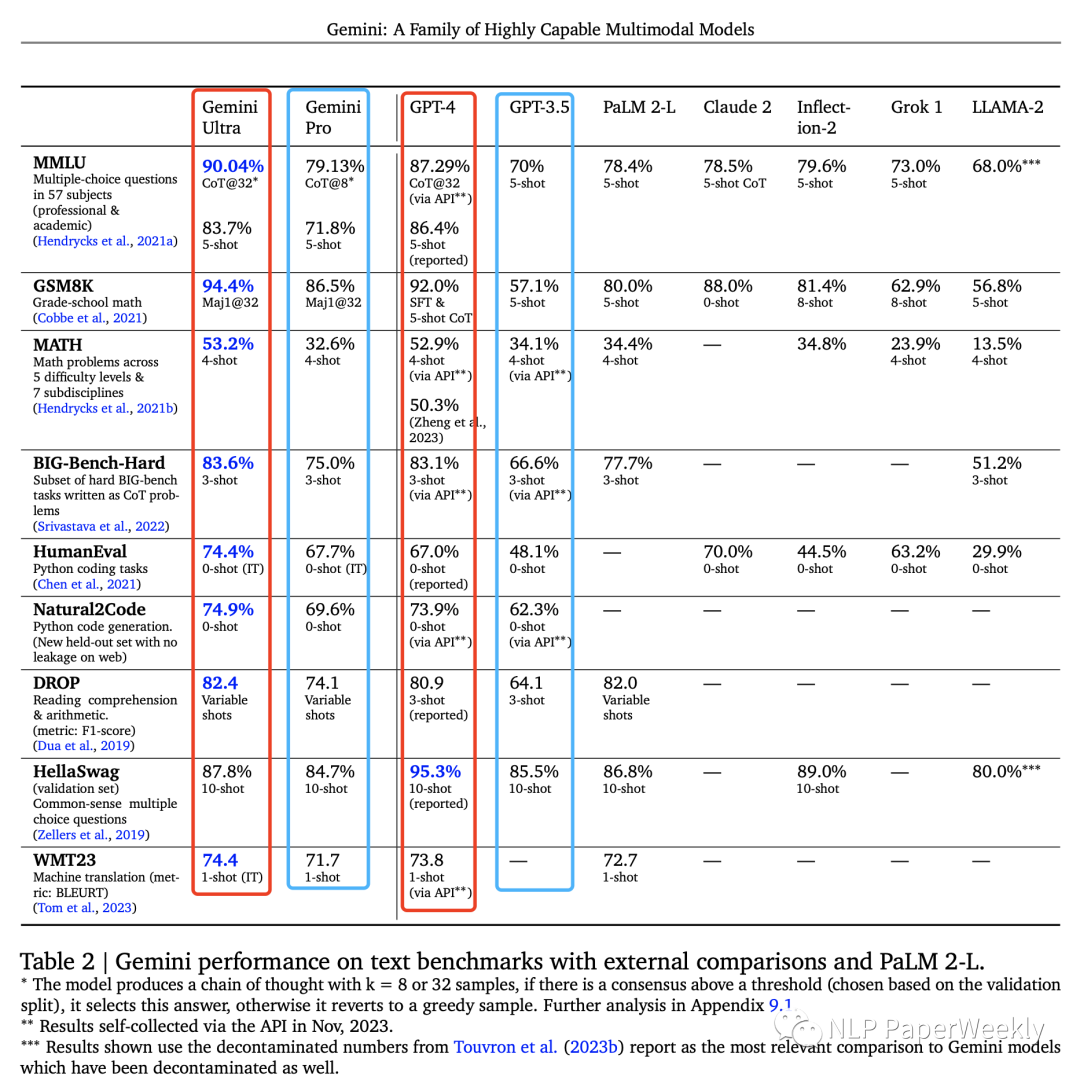
Ultra比gpt4效果好,pro比gpt3.5效果好,MMNLU第一次超过人类专家水平。
Gemini Ultra 在六个不同数据集上都是最佳。Gemini Pro是Gemini系列中的第二大模型,效率更高的同时也颇具竞争力。
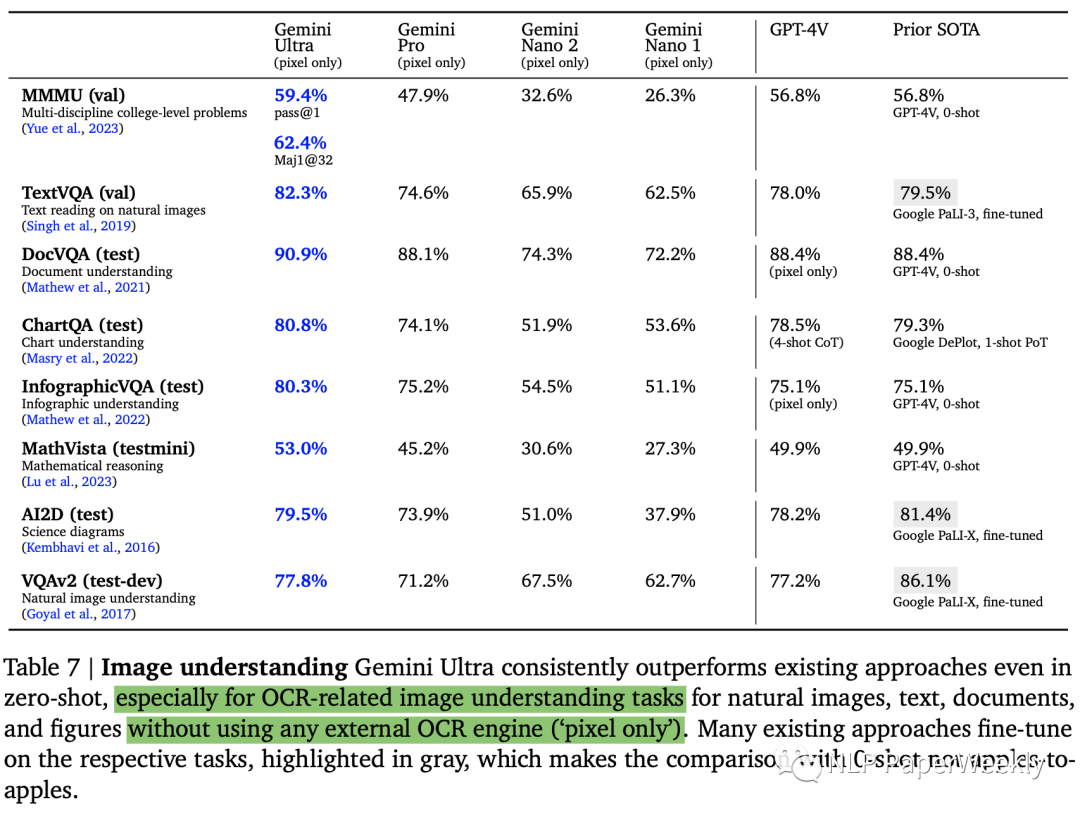
2 图像理解:zero-shot效果超过很多微调后的模型
3 视频理解:超过之前的few-shot SoTA模型
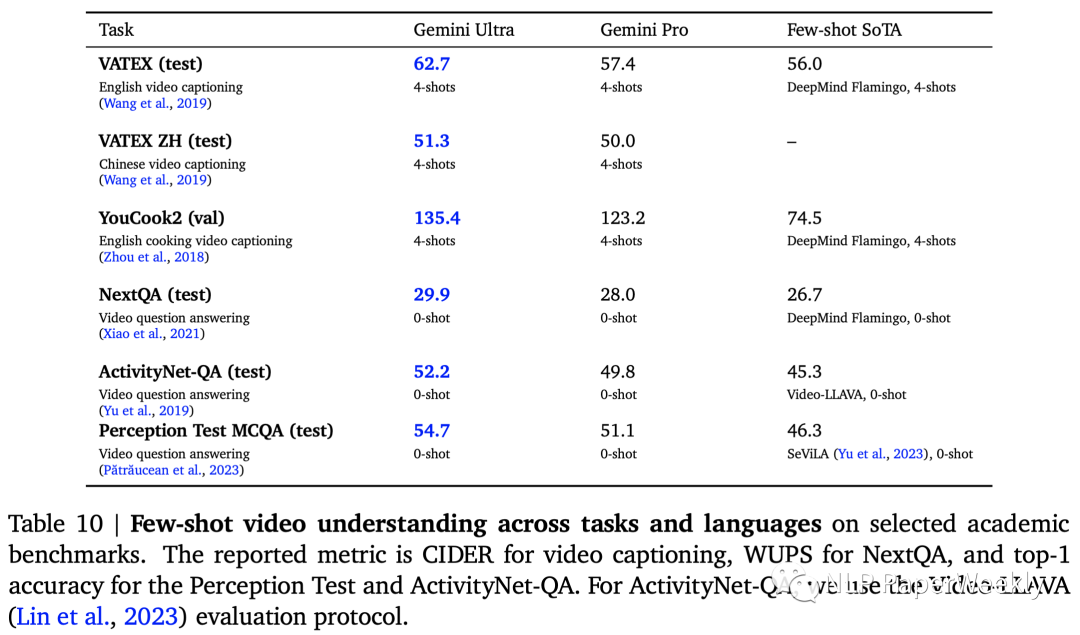
也是取得了SoTA,特别是英语视频字幕数据集(VATEXT、YouCook2)上提升比较大,其他感觉提升没那么大。相关评估指标如下:视频字幕 -> CIDER,NextQA -> WUPS,Perception Test -> top-1 accuracy,ActivityNet-QA -> ActivityNet-QA。
4 不同版Genmini模型的性能
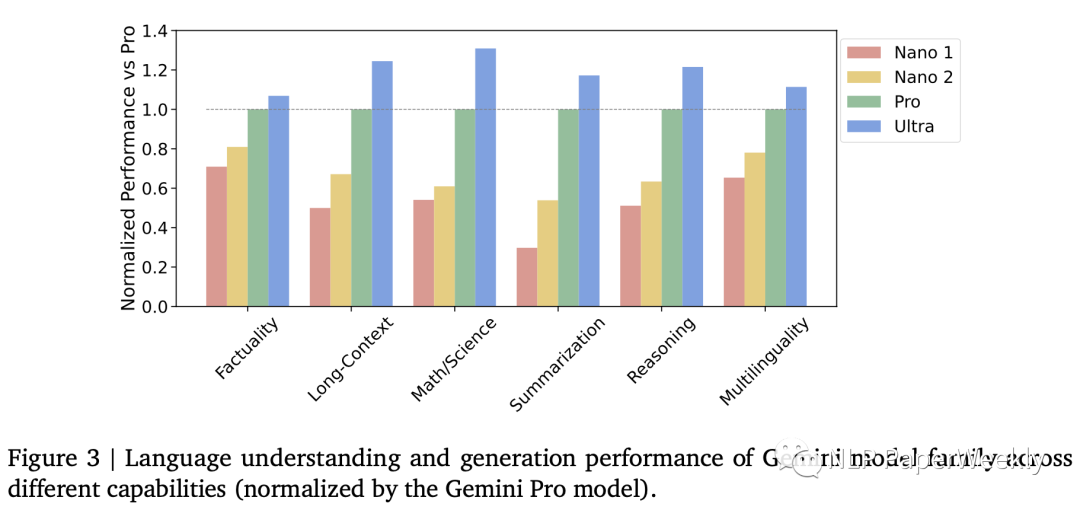
“事实性” :涵盖开放/闭卷检索和问题回答任务;
“长文本” :涵盖长篇摘要、检索和问题回答任务;
“数学/科学” :包括数学问题解决、定理证明和科学考试等任务;
“推理” :需要算术、科学和常识推理的任务;
“多语言” :用于多语言翻译、摘要和推理的任务。
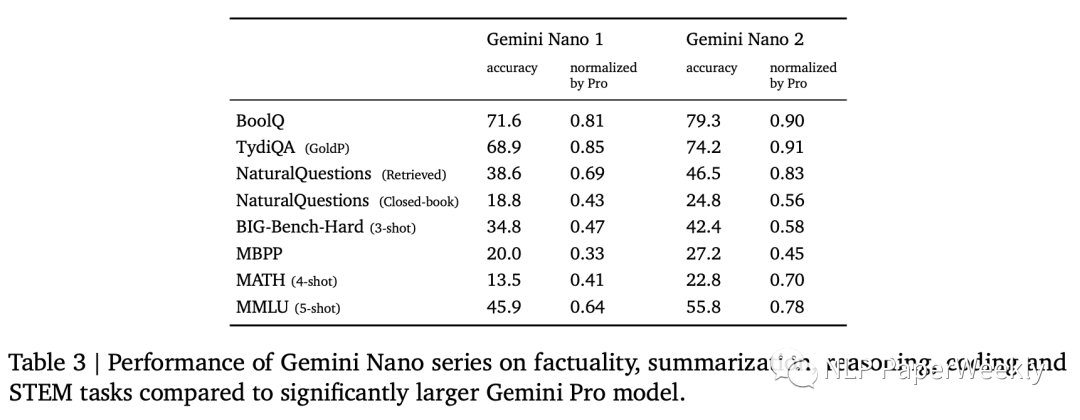
Nano2模型很多超过了Pro版本的50%,部分达到90的水平,效果还不错。
5 多语种翻译:性能超过GPT4
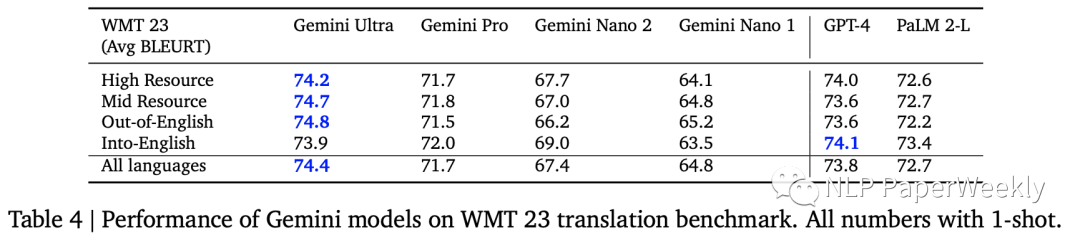
翻译能力也是比GPT-4好,WMT23指标中4个有3个超过GPT4的表现。
6 图像理解数据集:MMMU数据集表现
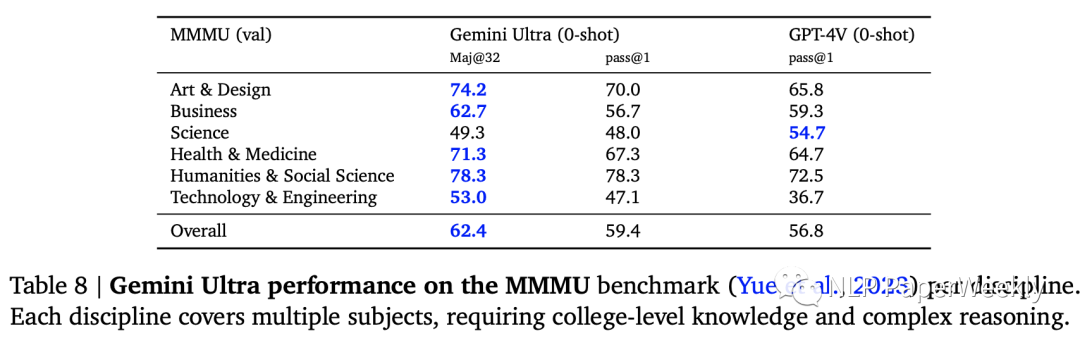
MMMU(Yue et al., 2023):是最近发布的评估基准,由6个学科的图像问题组成,每个学科内有多个主题,需要大学水平的知识来解决这些问题。
Gemini Ultra将最先进的结果提高了 5 个百分点以上,6个学科中有5个学科中超越了之前的最佳成绩,展示了其多模态推理能力。
二、详细内容
1 多模态推理能力:识别手写答案,对物理问题进行解答

特点:识别书写结果,这个和OpenAI之前演示的根据草图写前端代码是一样的,不过识别的准确率是存疑的。
2 多模态推理能力:重新组织子图顺序
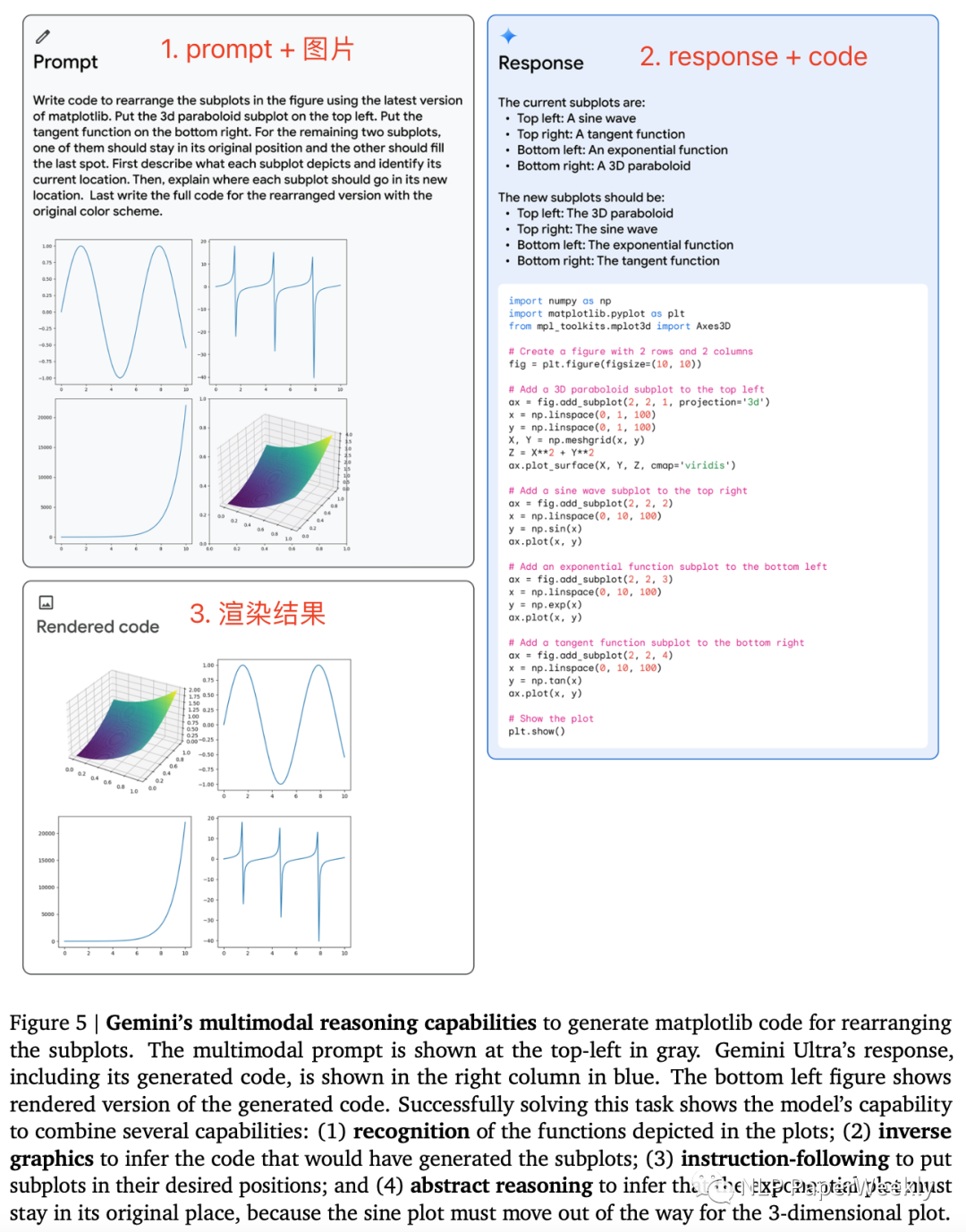
Gemini的多模态推理能力可生成用于重新排列子图的matplotlib代码。
Prompt:识别当前子图的结果,重新组织子图的顺序并解释。
解决此任务需要模型具备以下能力:
(1) 识别图中描绘的函数;
(2) 逆向图形来推断生成子图的代码;
(3) 按照指令将子图放置在所需的位置;
(4) 抽象推理,推断指数图必须留在原来的位置,因为正弦图必须为 3 维图移动。
3 图像生成能力:多模态理解+图像生成
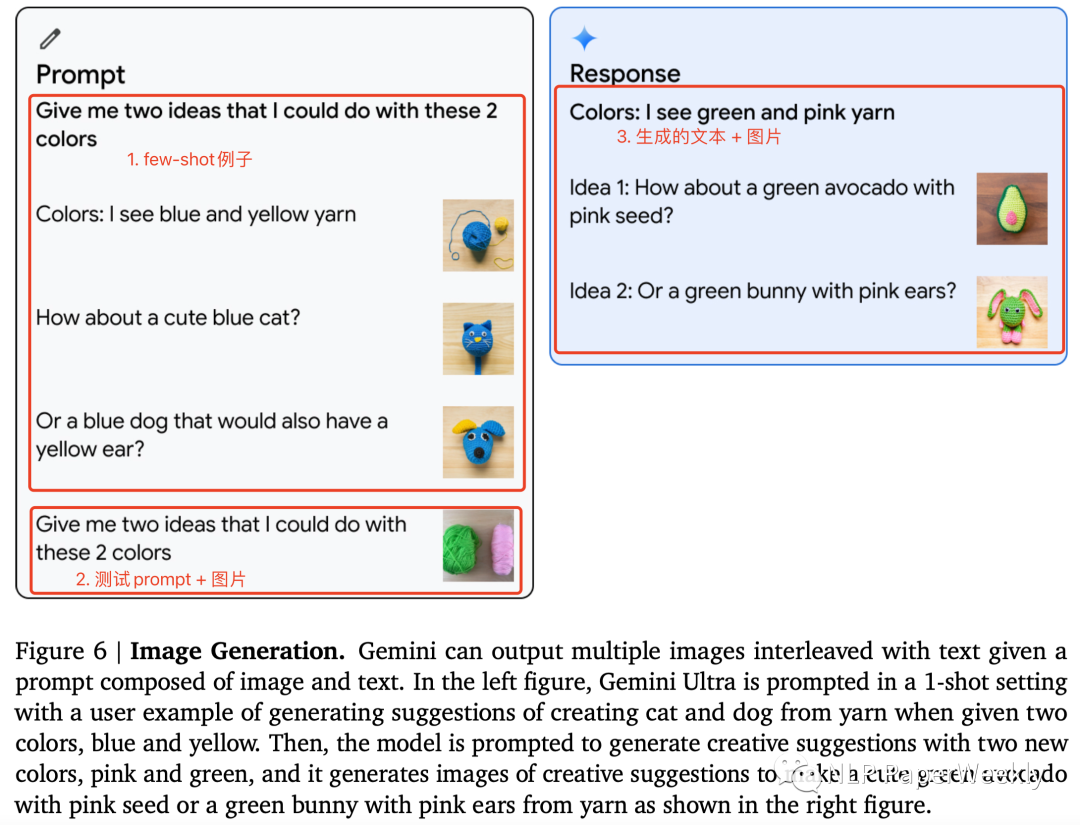
要具备上面的功能需要以下能力:
(1)识别图像中的颜色。这个难度不大。
(2)生成文字+图片结果。这个难度好像也没有那么大,可能有two-stage的实现方法或者end-to-end的实现方法。不太确定google用的哪种方法。
4 语音理解能力:具备语音识别和语音翻译能力
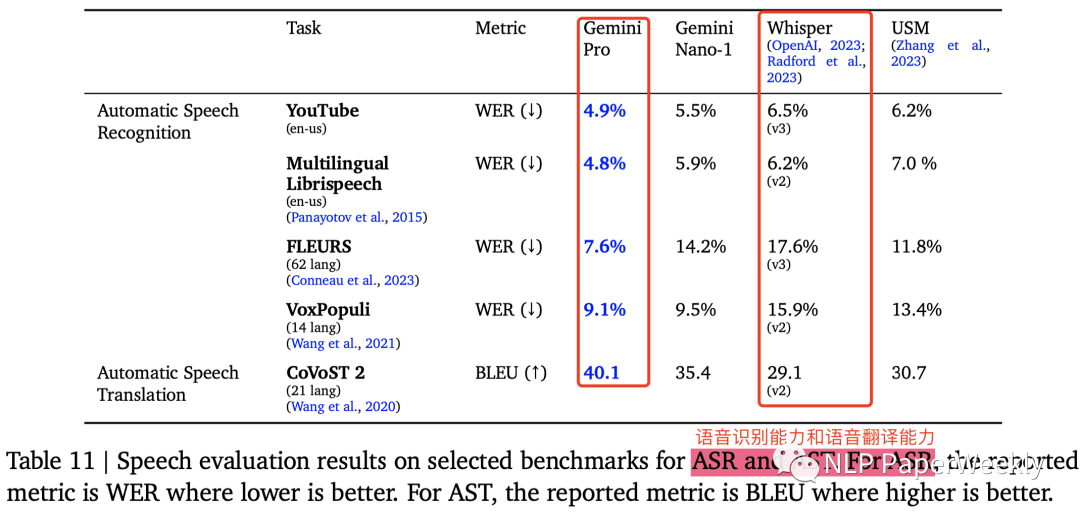
对比的是OpenAI的Whisper,看着Gemini就是把多个SoTA模型包装起来了。
5 多模态理解:支持图片+音频输入

这个gptv+加个语音转文字的模型可以做,这里的特点可能是直接用一个模型就可以解决?
三、多模态能力展示
1 几何推理能力:求平行四边形的高

2 视觉多模态推理能力:根据图片确定地点

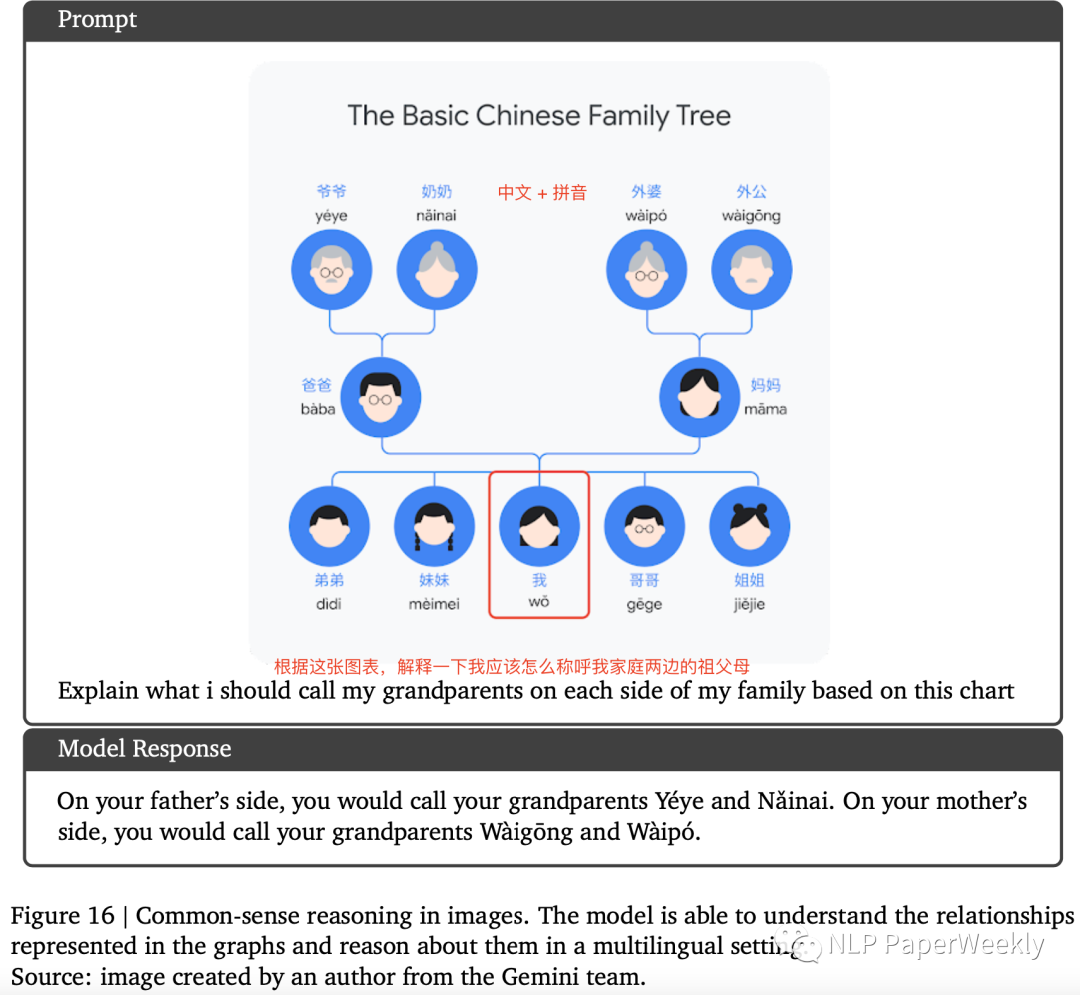
3 多语言常识推理:识别中文关系图
4 视频理解能力:分析视频中的人如何提升足球技术

四、总结
直接支持多模态的能力是Gemini的特点,Google从预训练阶段就统一了多模态大模型的训练,该策略也可能是后续大模型的发展趋势,但是其具体实现方法、带来的增益、以及cost还未知。OpenAI多模态的能力是引入(支持语音)其他模型或者通过插件(支持图像)来实现。
Gemini的多模态能力比GPT4-V要强,科学推理能力可能稍微弱于GPT4。
图文理解+视频理解等多模态能力与最新的大模型强强组合确实能带来惊艳的效果,但是其稳定性,是否真实能落地还有待进一步观察。例如结合图像信息求平行四边行的高,在教育领域相对于纯文本可能会更有价值,但是OCR等技术还面临鲁棒性偏差的问题,Google的模型段时间应该还是没办法解决这些问题。
审核编辑:刘清
-
人工智能多模态与视觉大模型开发实战 - 2026必会2026-07-13 139
-
视频课程下载—【完结】多模态与视觉大模型开发实战 - 2026必会2026-07-12 69
-
【完结】多模态与视觉大模型开发实战 - 2026必会2026-07-11 36
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 230
-
亚马逊云科技上线Amazon Nova多模态嵌入模型2025-10-29 547
-
商汤日日新SenseNova融合模态大模型 国内首家获得最高评级的大模型2025-06-11 1740
-
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo2024-04-24 2299
-
李未可科技正式推出WAKE-AI多模态AI大模型2024-04-18 1260
-
探究编辑多模态大语言模型的可行性2023-11-09 1228
-
北大&华为提出:多模态基础大模型的高效微调2023-11-08 2689
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1773
-
VisCPM:迈向多语言多模态大模型时代2023-07-10 1645
全部0条评论

快来发表一下你的评论吧 !
