

基于3D点云的多任务模型在板端实现高效部署
描述
简介
对于自动驾驶应用来说,3D 场景感知至关重要。3D点云数据就是具有3D特征的数据。一方面,3D 点云可以直接用来获取障碍物的距离和大小,以及场景的语义信息。另一方面,3D 点云也可以与 2D 图像进行融合,以充分利用两者所提供的不同信息:图像的优势在于语义信息更加丰富,点云的优势在于距离和深度感知精确。随着深度学习架构的发展,出现了很多基于3D 点云感知模型,通过提取 3D 空间的点云特征,可以构建一种更精确、高维度、高分辨率的场景表示形式,助力下游预测与规控任务的发展。对于检测模型,相比图像感知模型,对于 3D 感知任务,基于3D 点云的感知模型通常拥有非常明显的精度优势。
同时,在自动驾驶系统中,可行驶区域分割是一项重要的任务。可行驶区域的提取是ADAS的关键技术,旨在使用传感器感知技术感知驾驶车辆周围的道路环境,识别并分割出当前驾驶场景下可行驶的区域,防止偏离车道或违规驾驶。
在部署过程中,相比图像模型,3D 点云的输入处理过程更复杂,量化难度高,导致难以部署。当前常见的对点云数据处理方式包括point-based、pillar-based、voxel-based等方式。考虑到部署的实时性需求,地平线选用了基于pillar-based的 Centerpoint,同时提出了基于3D点云的多任务模型,实现可行驶区域分割的感知功能。本文即对如何在地平线征程5芯片上高效部署基于3D点云的多任务模型进行介绍。
整体框架
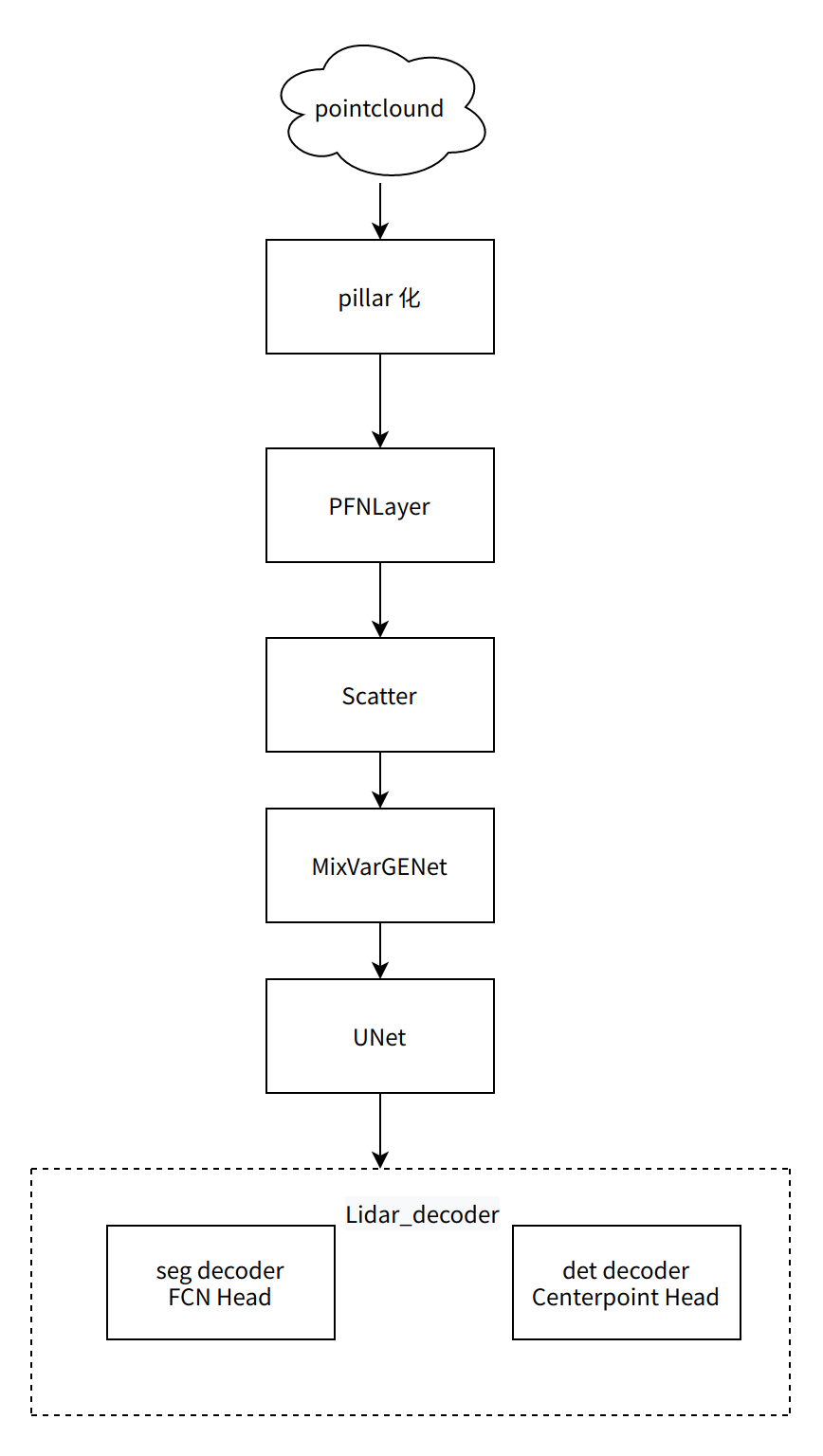
本文介绍的多任务模型输入为3D点云,通过感知模型可同时输出 3D 目标检测结果和 2D 可行驶区域的分割结果。多任务模型网络结构可分为以下三个部分:
• 点云前处理。该部分是对3D点云做基于pillar-based的处理,将点划分到pillars中,形成伪图像。包括以下三个部分:
a. Pillar 化:将输入的原始点云转换为 pillar 特征;
b. PFNLayer:提取 pillar 特征,特征通道数提升至 64;
c. Scatter:完成 pillar 特征到伪图像化的转换;
• 特征提取和融合: 该层选用 MixVarGENet+UNET 结构,提取多层特征并加以融合,获得高层语义特征;
• 多任务输出头: 输出多类别的 3D 目标检测和二分类的可行驶区域分割结果。
部署优化
在部署优化之前,首先明确针对Centerpoint多任务模型的各部分的结构做性能和量化精度上分析,然后进一步给出优化方向和优化思路。
量化精度优化
在前面有提到,点云数据具有不均匀的特征,这种分布特点的数据使用PTQ量化方式很大可能会有量化精度问题,因此在 Centerpoint 多任务模型的量化过程中,我们使用 Calibration+QAT 的量化方式来保证点云模型的量化精度。需要提到的是地平线的calibration对于大部分模型就可以达到预期的量化精度,少量模型在较小的QAT训练代价下可以达到量化精度。由于 Centerpoint 多任务模型中所有算子的量化在征程5上是完全支持的,得到初版的量化精度是非常简单的。
QAT量化方式是根据数据的分布选取量化系数,将fp32的数据截断到int8范围,由于点云数据分布不均匀,其表现在部分数据(点云坐标)的数值范围较大,部分(点到中心的距离)数值范围较小,这种情况对量化是很不友好的,因此在量化训练中,会导致精度掉点;为了使数据分布处于均匀范围内,一般都会做归一化处理(归一化对浮点的精度也是有利的),因此,为了提升量化精度,我们增加了对点云特征的归一化处理。
Python
def _voxel_feature_encoder(self, features, norm_dims, norm_range,feature,num_points_in_voxel):
# normolize features
for idx, dim in enumerate(norm_dims):
start = norm_range[idx]
norm = norm_range[idx + len(norm_range) // 2] - norm_range[idx]
features[:, :, dim] = features[:, :, dim] - start
features[:, :, dim] = features[:, :, dim] / norm
...
return features
在nuscenes数据集上的验证,经归一化处理后,量化精度损失在 1% 以内。
性能优化
点云前处理优化
前处理包括Voxelization操作和特征的扩维操作-VoxelAugment。我们将分析公版的实现在征程5上部署的困难点,然后基于困难点介绍优化方式以及地平线对点云前处理的部署优化。
|
Voxelization:体素化,是把三维空间中的点云数据转换到体素(voxel,即三维空间中的网格)。 Centerpoint中的 Pillars 可以看作是特殊( z 轴没有空间限制)的 voxel,为了与社区名称和代码实现名称相统一,我们下文统一称为 Voxelization、voxel。 |
Voxelization部署分析
假设用 (x, y, z, r, t) 表示点云数据中的一个点,其中(x, y, z) 坐标,r 为点云的反射强度,t为时间戳。
Centerpoint中的Pillar化(一种特殊的 Voxelization 操作,是把 z 轴看作一个整体,把三维空间离散化为 x-y 平面中均匀间隔的网格),在 Voxelization 过程中,需要依次、逐个对密集点云中的每个点进行判断,并将其划分入对应的 voxel 中,且每个 voxel 都需要存储点云中对应区域的信息。随着点云密度的增加,处理的体素数量也相应增多,导致需要更多的计算和内存资源,其计算复杂度可能导致较长的部署时间。
VoxelAugment部署分析
继voxelization 中把每个点云 point 划分到各个 pillar 中之后,公版 Centerpoint中对点云 point 做了特征增强,即前文提到的把基于 nuscenes 数据集的5 维点云 point 数据(x, y, z, r, t)根据点到中心的距离扩充到了 11 维(x, y, z, r, t, xc, yc, zc,xp, yp, zp,)。然而,这样的处理方式,无论是对量化精度还是部署性能方面,都存在一些不足:
• 量化精度方面:前文已提到,这里不再赘述;
• 部署性能方面: 在从 5 维扩充到 11 维时,对中心点距离的求解,增加了计算量和相应的耗时。而在我们的实验中发现,增加的后 6 维数据,实际对模型的浮点精度影响很小。
针对以上两个问题,下面介绍地平线的优化方法。
VoxelAugment优化
根据实验,原11维的方案会导致耗时增加,精度收益不大,因此在我们的改进方法中,点云 point 仅使用前5维(x, y, z, r, t),见板端c++代码:
Python
void QATCenterpointPreProcessMethod::GenFeatureDim5(float scale) {
for (int i = 0; i < voxel_num_; i++) {
int idx = i * config_->kmax_num_point_pillar * config_->kdim;
for (int j = 0; j < config_->kmax_num_point_pillar; ++j) {
if (config_->pillar_point_num[i] >
config_->kmax_num_point_pillar_vec[j]) {
int index = idx + j * config_->kdim;
voxel_data_[index + 0] =
(voxel_data_[index + 0] - config_->kback_border) /
config_->kx_range / scale;
voxel_data_[index + 1] =
(voxel_data_[index + 1] - config_->kright_border) /
config_->ky_range / scale;
voxel_data_[index + 2] =
(voxel_data_[index + 2] - config_->kbottom_border) /
config_->kz_range / scale;
voxel_data_[index + 3] = (voxel_data_[index + 3] - config_->kr_lower) /
config_->kr_range / scale;
if (voxel_data_[index + 4] != 0) {
voxel_data_[index + 4] = voxel_data_[index + 4] / scale;
}
}
}
}
}
在优化后,该部分耗时减少了 4ms,精度上影响较小。
除了以上的优化外,考虑硬件对齐特性,对特征的layout也做了优化,以便模型可以高效率运行。征程5计算运算的时候有最小的对齐单位,若不满足规则时会对Tensor自动进行padding,造成无效的算力浪费。例如conv的对齐大规则为2H16W8C/2H32W4C。基于硬件特征,采用H W维度转换的方式,将大数据放到W维度以减少算力的浪费,因此在生成pillars特征对其做归一化后使用permute将1x5x40000x20转换为1x5x20x40000。
Python features = features.unsqueeze(0).permute(0, 3, 2, 1).contiguous()
Voxelization优化
对于点云的voxelization耗时问题,地平线提供了ARM和DSP部署方式。可以在OE包的AIBenchmerk中查看其具体实现。
DSP具有强大的并行计算能力,能够同时处理多个数据,且具有快速读写内存的特点,利用 DSP 可以有效加速 Voxelization 过程,提高实时性能。例如,在 nuscenes数据集(点云数据量为30万),经 DSP 优化后,前处理耗时由77ms 降低至20ms,性能提升3.8倍。具体数据可见实验结果章节。
优化后,点云处理部分流程图如下所示:
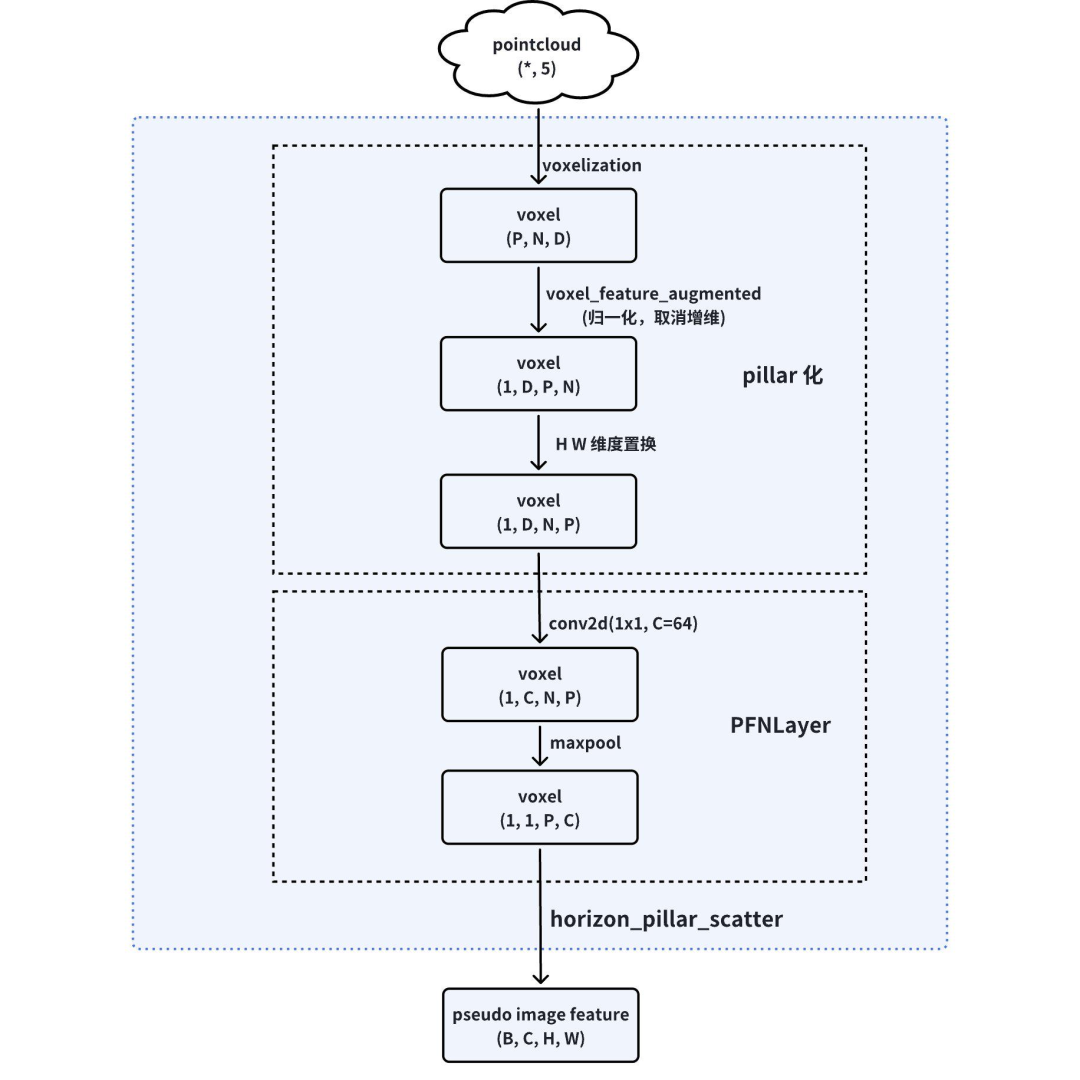
特征提取与融合PFNLayer
Centerpoint 的PFNLayer作用是将每个包含D维特征的点(由前文可知,公版Centerpoint中 D=11,地平线参考模型中D=5)用一个Linear+BatchNorm1d+ ReLU+max 的组合来进行特征提取,生成(C,P,N) 的张量。
而地平线征程5最早针对的是以CNN为基础的图像处理,在编译器内部4d-Tensor是最高效的支持方式。如果不是4d-Tensor的话,编译器内部会主动转成4d(某些维度为1)来做,会多了很多无效的计算。我们可以使用常规的4维算子替换原来任意维度的设置,避免不必要的冗余计算。常见的替换方式如下,中间配合任意维度的reshape,permute来完成等价替换。因此,我们将公版中的 Linear + BatchNorm1d + ReLU + max 分别做了如下替换:
| N dims | 4dims |
| nn.Linear | nn.Conv2d |
| nn.BacthNorm1d | nn.BacthNorm2d |
| torch.max | nn.MaxPool2d |
伪图像化
PillarScatter 是实现伪图像转换的最后一个步骤,该部分将(1, 1, P, C) 的特征映射获得形如(C, H, W) 的伪图像。为了便于量化训练和上板推理优化,我们在 horizon_plugin_pytorch 和编译器中均实现了point_pillars_scatter 算子。该算子由编译器内部完成,用户不需要感知。
horizon_plugin_pytorch 中 point_pillars_scatter 算子的调用方式为:
Python from horizon_plugin_pytorch.nn.functional import point_pillars_scatter pseudo_image_feature = point_pillars_scatter(voxel_features, coords, out_shape)
backbone+neck
关于特征提取与融合部分,由于点云处理部分生成的伪图像特征输出通道数较大,原 Centerpoint 模型中的 SECOND 结构部署速度不够快,本文选用 MixVarGENet+UNET 结构,作为模型的 backbone 与 neck。
MixVarGENet 为地平线基于征程5硬件特性自研的backbone结构,特点是性能表现优异,可以达到双核5845FPS。该结构的基本单元为MixVarGEBlock。如下为MixVarGEBlock的结构图:
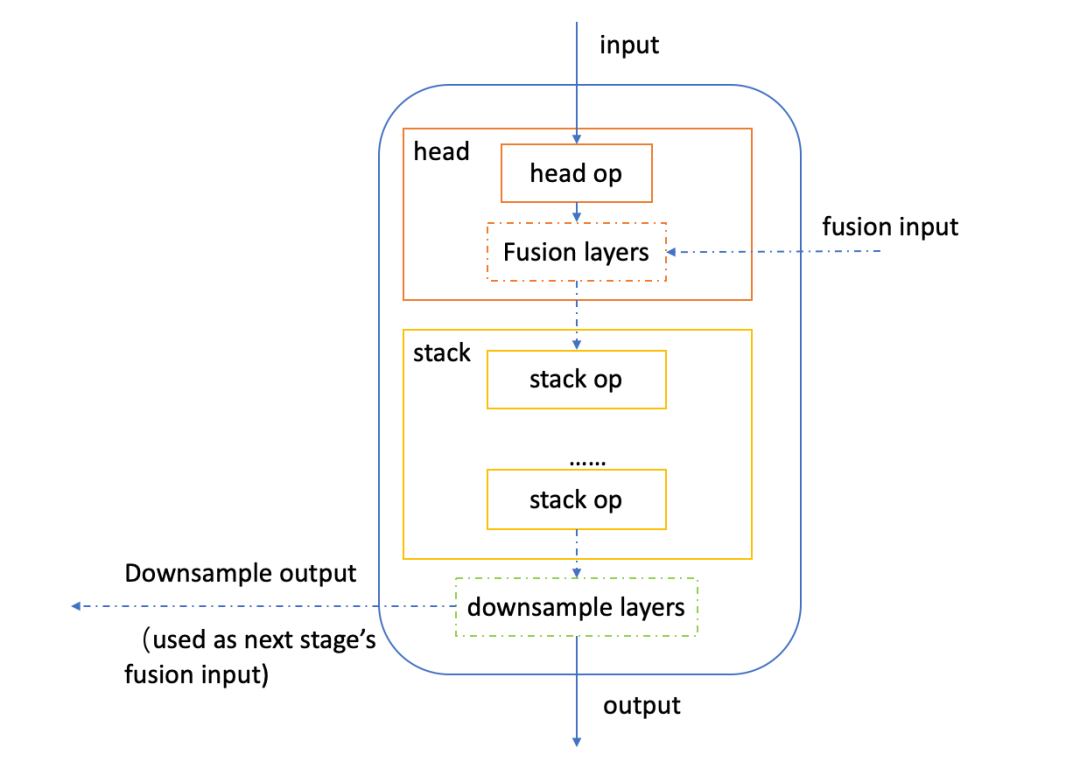
MixVarGENet高度秉承了“软硬结合”的设计理念,针对征程5的算力特性做了一些定制化设计,其设计思路可以总结为:
1. 小channel时使用normal conv,发挥征程5算力优势;
2. 大channel时引入group conv,缓解带宽压力;
3. Block内部扩大channel,提升网络算法性能;
4. 缩短feature复用时间间隔,减少SRAM到DDR访存。
充分考虑征程5的带宽和硬件属性,小neck+大backbone的组合比较经济,且可以提高BPU的利用率,能达到平衡精度与速度的最佳组合!
多任务输出头
Centerpoint多任务模型的输出头分为两部分,对于 3D 目标检测,选用 Centerpoint 模型的预测头,2D 可行驶区域的分割结果则选用了 FCN 结构做为输出头。
多任务模型的分割头为 FCNHead,其中部分卷积模块替换为深度可分离卷积,有利于部署性能的进一步提升。同理,多任务模型的检测头 CenterpointHead 也将部分卷积模块替换为深度可分离卷积。替换后,模型部署性能得到了进一步的提升,同时浮点精度不受影响。
由于公版 Centerpoint 模型的二阶段在 nuscenes 数据集上并无精度提升,因此这里只选用了一阶段的输出头。
实验结果
1. Centerpoint 多任务模型在征程5性能数据
| 数据集 | Nuscenes |
| 点云量 | 30W(5dim)(注1) |
| 点云范围 | [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0] |
| Voxel size | [0.2, 0.2, 8] |
| 最大点数 | 20 |
| 最大pillars数 | 40000 |
| FPS | 106.14 |
| 前处理时长(arm/arm+dsp) | 77ms/20ms |
| latency | 23.79ms |
| 量化精度 |
浮点:NDS: 0.5809, mAP: 0.4727, miou:91.29 定点:NDS: 0.5762, mAP: 0.4653, miou:91.22 |
| 检测类别 | 10类(注2) |
| 分割类别 | 二分类(注2) |
注
1:维度为(x,y,z,r,t),即:3维坐标、强度和时间
2:检测任务:["car","truck","construction_vehicle","bus","trailer","barrier","motorcycle","bicycle","pedestrian","traffic_cone"]
分割任务:["others", "driveable_surface"]
2. 基于3D点云的多任务模型高效部署通用建议
• 对输入数据做归一化,更有利于量化。
• 如在部署中使用PTQ无法解决量化精度问题,考虑使用QAT做量化部署。
• 对于点云数据,pillars_num较大,将大数据放到W维度提升计算效率。
• 建议选择小neck+大backbone的组合,减小带宽压力,达到性能提升。
• 使用地平线提供的点云前处理,若前处理存在性能瓶颈,尝试DSP方案。
总结
本文通过对基于3D点云的多任务模型在地平线征程5上量化部署的优化,使得模型以低于1%的量化精度损失,得到 latency 为 23.79ms 的部署性能。在点云处理方面,通过针对性的优化方法,灵活支持了不同点云输入并大幅提高点云处理的速度;在特征提取方面,选用了征程5高效结构 MixVarGENet+UNET;在输出设置上,采用多任务输出设计,能够同时得到 3D 目标检测结果和可行驶区域的分割结果。
审核编辑:刘清
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2675
-
老生常谈---一种裸奔多任务模型2011-12-08 3481
-
你没看错,浩辰3D软件中CAD图纸与3D模型高效转化这么好用!2020-05-13 2558
-
PYNQ框架下如何快速完成3D数据重建2021-01-07 1930
-
裸奔环境下的多任务模型2022-01-21 606
-
基于页的8051多任务模型2010-09-25 1233
-
3D点云技术介绍及其与VR体验的关系2017-09-15 1570
-
点云问题的介绍及3D点云技术在VR中的应用2017-09-27 1526
-
3D 点云的无监督胶囊网络 多任务上实现SOTA2021-01-02 2967
-
何为3D点云语义分割2022-07-21 10446
-
workflow的任务模型2023-02-21 1914
-
如何试用MediaPipe实现人脸3D点云数据提取2023-02-23 2588
-
3D点云数据集在3D数字化技术中的应用2023-05-06 2466
-
基于深度学习的3D点云实例分割方法2023-11-13 3878
-
C#通过Halcon实现3D点云重绘2025-01-05 452
全部0条评论

快来发表一下你的评论吧 !
