

深度解析HBM内存技术
描述
HBM作为基于3D堆栈工艺的高性能DRAM,打破内存带宽及功耗瓶颈。HBM(High Bandwidth Memory)即高带宽存储器,通过使用先进封装(如TSV硅通孔、微凸块)将多个DRAM芯片进行堆叠,并与GPU一同进行封装,形成大容量、高带宽的DDR组合阵列。
HBM通过与处理器相同的“Interposer”中间介质层与计算芯片实现紧凑连接,一方面既节省了芯片面积,另一方面又显著减少了数据传输时间;此外HBM采用TSV工艺进行3D堆叠,不仅显著提升了带宽,同时降低了功耗,实现了更高的集成度。
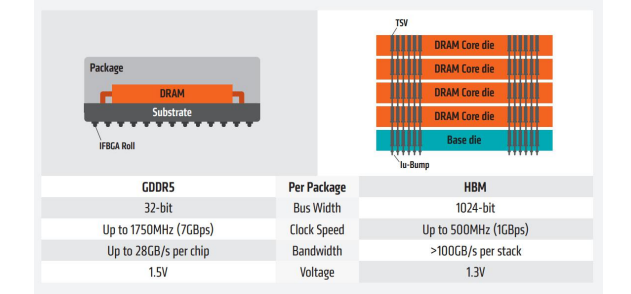
HBM性能远超GDDR,成为当前GPU存储单元理想解决方案。GPU显存一般采用GDDR或者HBM两种方案,但HBM性能远超GDDR。
根据AMD数据,从显存位宽来看,GDDR5为32-bit,HBM为其四倍,达到了1024-bit;从时钟频率来看,HBM为500MHz,远远小于GDDR5的1750MHz;从显存带宽来看,HBM的一个stack大于100GB/s,而GDDR5的一颗芯片才25GB/s,所以HBM的数据传输速率远远高于GDDR5。
从空间利用角度来看,HBM由于与GPU封装在一块,从而大幅度减少了显卡PCB的空间,而GDDR5芯片面积为HBM芯片三倍,这意味着HBM能够在更小的空间内,实现更大的容量。因此,HBM可以在实现高带宽和高容量的同时节约芯片面积和功耗,被视为GPU存储单元理想解决方案。
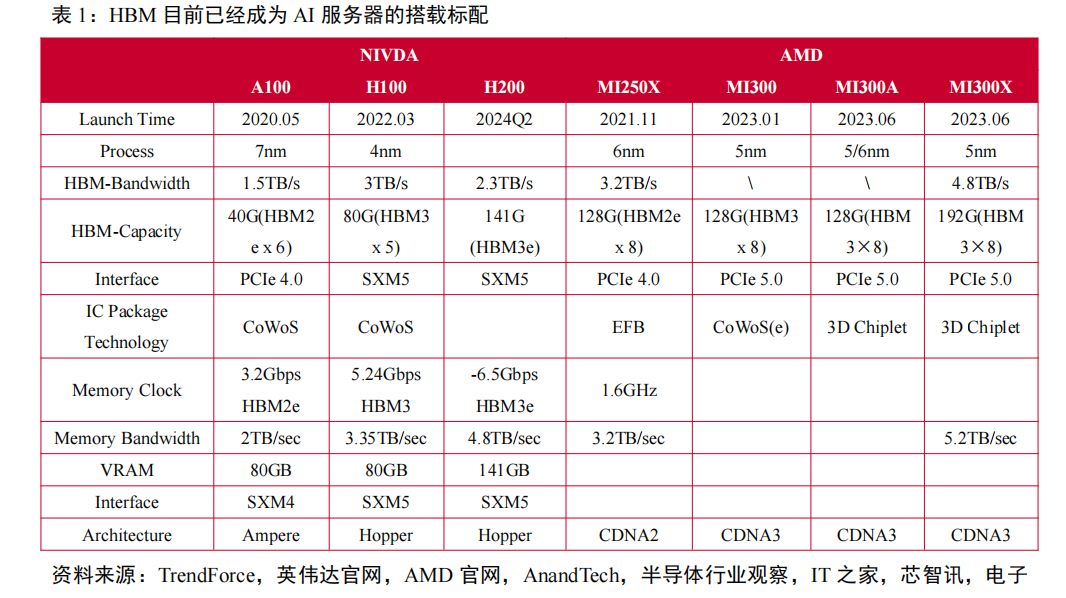
在高性能GPU需求推动下,HBM目前已经成为AI服务器的搭载标配。AI大模型的兴起催生了海量算力需求,而数据处理量和传输速率大幅提升使得AI服务器对芯片内存容量和传输带宽提出更高要求。
HBM具备高带宽、高容量、低延时和低功耗优势,目前已逐步成为AI服务器中GPU的搭载标配。英伟达推出的多款用于AI训练的芯片A100、H100和H200,都采用了HBM显存。
其中,A100和H100芯片搭载了40GB的HBM2e和80GB的HBM3显存,最新的H200芯片搭载了速率更快、容量更高的HBM3e。AMD的MI300系列也都采用了HBM3技术,MI300A的容量与前一代相同为128GB,而更高端的MI300X则将容量提升至192GB,增长了50%,相当于H100容量的2.4倍。
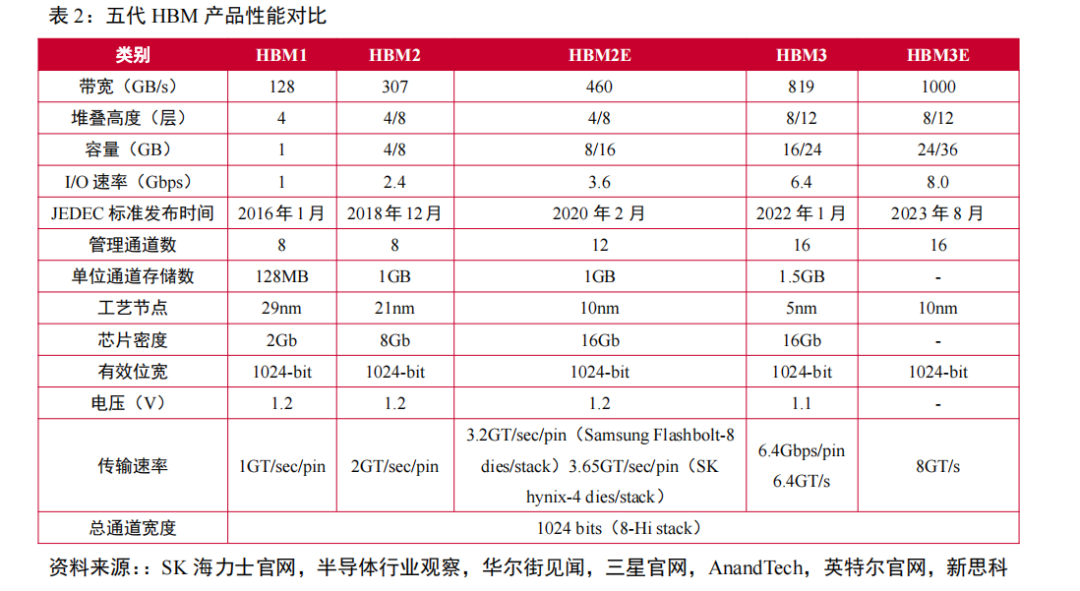
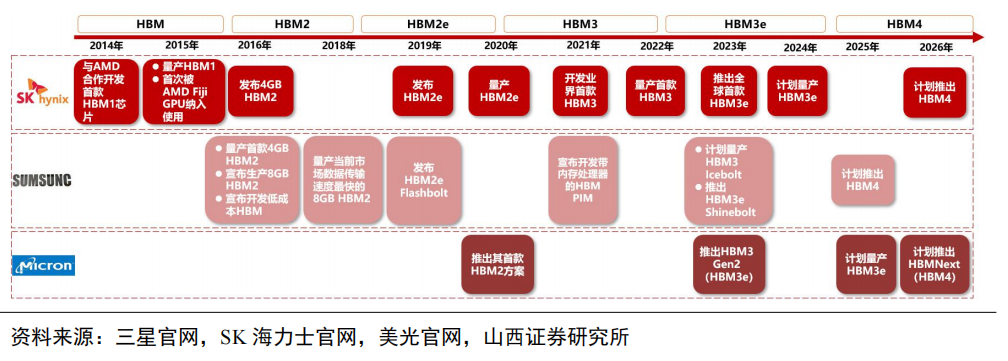
HBM市场竞争激烈,HBM产品向低能耗、高带宽、高容量加速迭代。从2016年第一代HBM1发布开始,HBM目前已经迭代到第五代产品——HBM3e,纵观五代HBM产品性能变化,可以发现HBM在带宽、I/O速率、容量、工艺节点等方面取得较大突破,其中带宽由初代的128GB/s迭代至HBM3e的1TB/s,I/O速率由1Gbps迭代至8Gbps,容量从1GB增至最高36GB,制造工艺则取得进一步突破,达到5nm级别。
最新一代HBM3e数据处理速度最高可达到1.15TB/s,HBM系列产品的更新迭代将在低能耗、高带宽、高容量上持续发力,以高性能牵引AI技术进一步革新。
HBM产品迭代助力AI芯片性能升级。当地时间2023年11月13日,英伟达发布了首款搭载最先进存储技术HBM3e的GPU芯片H200。H200作为首款搭载最先进存储技术HBM3e的GPU,拥有141GB显存容量和4.8TB/s显存带宽,与H100的80GB和3.35TB/s相比,显存容量增加76%,显存带宽增加43%。
尽管GPU核心未升级,但H200凭借更大容量、更高带宽的显存,依旧在人工智能大模型计算方面实现显著提升。根据英伟达官方数据,在单卡性能方面,H200相比H100,在Llama2的130亿参数训练中速度提升40%,在GPT-3的1750亿参数训练中提升60%,在Llama2的700亿参数训练中提升90%;在降低能耗、减少成本方面,H200的TCO(总拥有成本)达到了新水平,最高可降低一半的能耗。
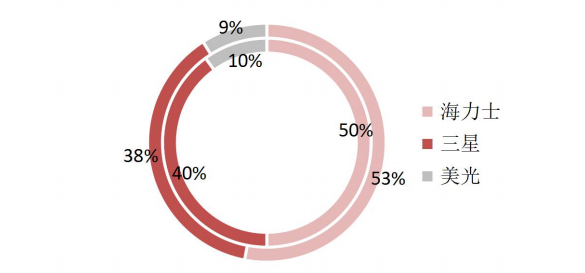
HBM市场目前被三大原厂占据,其中海力士份额领先,占据HBM市场主导地位。据TrendForce数据,三大原厂海力士、三星、美光2022年HBM市占率分别为50%、40%、10%。2023年年初至今,生成式AI市场呈爆发式增长,大模型参数量、预训练数据量攀升,驱动AI服务器对高带宽、高容量的HBM需求迅速增加。
作为最先开发出HBM芯片的海力士,在AIGC行业迅速发展背景下得以抢占先机,率先实现HBM3量产,抢占市场份额。2023年下半年英伟达高性能GPUH100与AMD MI300将搭载海力士生产的HBM3,海力士市占率将进一步提升,预计2023年海力士、三星、美光市占率分别为53%、38%、9%。

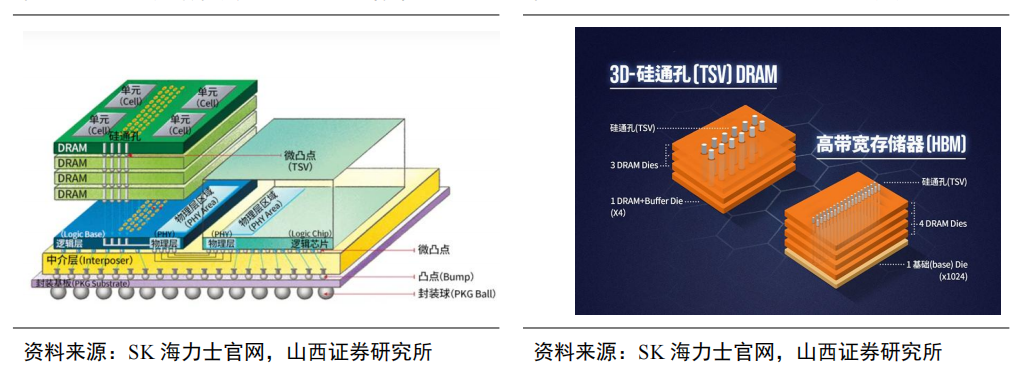
TSV技术通过垂直堆叠多个DRAM,能显著提升存储容量、带宽并降低功耗。TSV(硅通孔)技术通过在芯片与芯片之间、晶圆和晶圆之间制作垂直导通,并通过铜、钨、多晶硅等导电物质的填充,实现硅通孔的垂直电气互联。
作为实现3D先进封装的关键技术之一,对比wire bond叠层封装,TSV可以提供更高的互连密度和更短的数据传输路径,因此具有更高的性能和传输速度。随着摩尔定律放缓,芯片特征尺寸接近物理极限,半导体器件的微型化也越来越依赖于集成TSV的先进封装。目前DRAM行业中,3D-TSVDRAM和HBM已经成功生产TSV,克服了容量和带宽的限制。
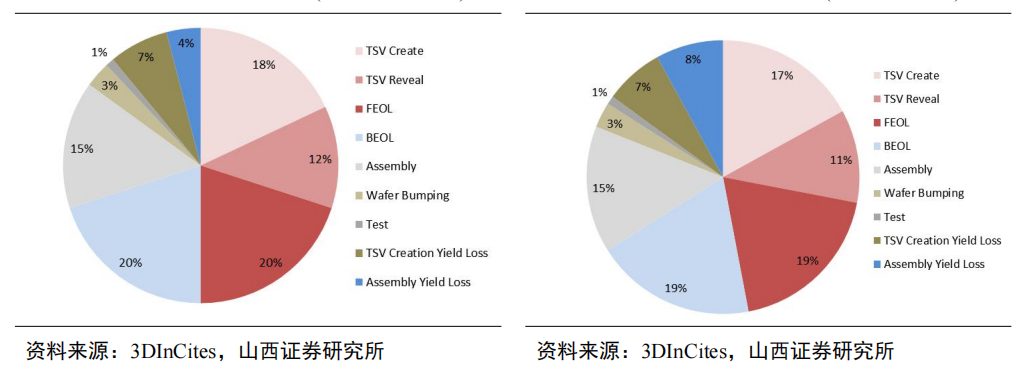
TSV为HBM核心工艺,在HBM3D封装成本中占比约30%。根据SAMSUNG,3D TSV工艺较传统POP封装形式节省了35%的封装尺寸,降低了50%的功耗,并且对比带来了8倍的带宽提升。对4层存储芯片和一层逻辑裸芯进行3D堆叠的成本进行分析,TSV形成和显露的成本合计占比,对应99.5%和99%两种键合良率的情形分别为30%和28%,超过了前/后道工艺的成本占比,是HBM3D封装中成本占比最高的部分。
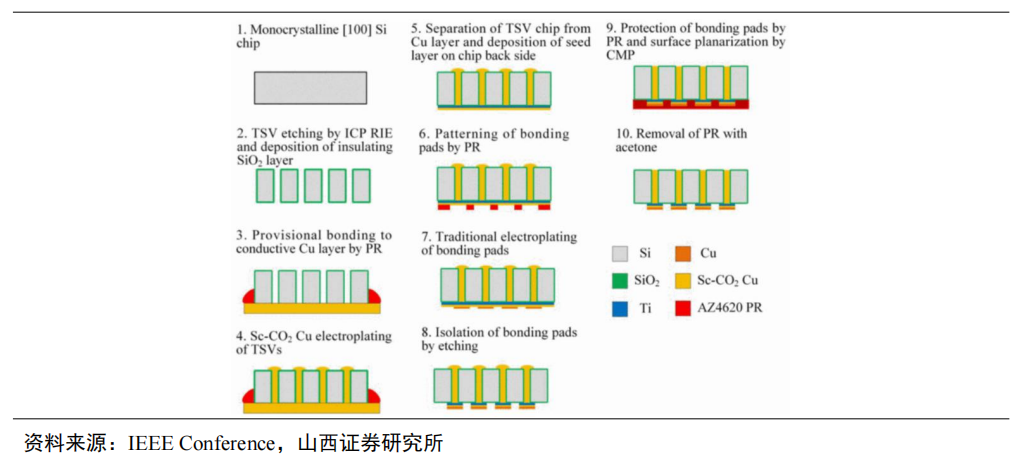
TSV技术主要涉及深孔刻蚀、沉积、减薄抛光等关键工艺。TSV首先利用深反应离子刻蚀(DRIE)法制作通孔;然后使用化学气相沉积(PECVD)的方法沉积制作介电层、使用物理气相沉积(PVD)的方法沉积制作阻挡层和种子层;再选择电镀铜(Cu)进行填孔;最后使用化学和机械抛光(CMP)法去除多余的铜。另外,由于芯片堆叠集成的需要,在完成铜填充后,还需要晶圆减薄和键合。
HBM多层堆叠结构提升工序步骤,带动封装设备需求持续提升。(1)前道环节:HBM需要通过TSV进行垂直方向连接,增加了TSV刻蚀设备需求,同时HBM中TSV、微凸点、硅中介层等工艺大量增加了前道工序,给前道检、量测设备带来增量;(2)后道环节:HBM堆叠结构增多,要求晶圆厚度不断降低,这意味着对减薄、键合等设备的需求提升;HBM多层堆叠结构依靠超薄晶圆和铜铜混合键合工艺增加了对临时键合/解键合等设备的需求;(3)各层DRAM Die的保护材料也非常关键,对注塑或压塑设备提出了较高要求。
审核编辑:汤梓红
-
Cadence推出HBM4 12.8Gbps IP内存系统解决方案2025-05-26 1899
-
HBM新技术,横空出世:引领内存芯片创新的新篇章2025-03-22 6105
-
美光新加坡HBM内存封装工厂破土动工2025-01-09 1504
-
HBM与GDDR内存技术全解析2024-11-15 7412
-
SK海力士加速HBM4E内存研发,预计2026年面市2024-05-14 1274
-
SK海力士将采用台积电7nm制程生产HBM4内存基片2024-04-23 1711
-
什么是HBM3E内存?Rambus HBM3E/3内存控制器内核2024-03-20 5430
-
英伟达斥资预购HBM3内存,为H200及超级芯片储备产能2024-01-02 1731
-
一文解析HBM技术原理及优势2023-11-09 21596
-
C语言深度解析2023-09-28 880
-
HBM内存:韩国人的游戏2023-06-30 2182
-
AUTOSAR架构深度解析 精选资料分享2021-07-28 2024
-
全面解构FuzionSC如何高速组装HBM内存2020-09-04 3034
全部0条评论

快来发表一下你的评论吧 !
