

蔚来5纳米自动驾驶芯片神玑NX9031分析
汽车电子
描述
2023年12月23日,NIO DAY上,蔚来推出了新旗舰车型ET9,同时也介绍了蔚来自主研发的自动驾驶芯片神玑NX9031,并宣布2025年ET9将量产,搭载这款NX9031。
目前对于这款芯片,蔚来仅公布了如上图中的信息,不过这已经足够做深度分析了。关键点包括5纳米工艺,超过500亿晶体管,使用LPDDR5X存储,32核心CPU配置,且是大小核配置,高动态ISP,位宽26比特,像素处理能力6.5GPixel/s,支持ASIL-D级安全。
现在芯片行业是IP时代,只要舍得花钱,自动驾驶SoC需要的IP都可以买得到,蔚来能做出来5纳米芯片并不令人惊讶。能做5纳米芯片代工的只有台积电和三星,蔚来找三星代工的可能性更高,一来台积电代工价格至少是三星的两倍,二来三星的5纳米客户稀缺,车规级更是稀缺,台积电有大量高通5纳米车规芯片订单,产能可能还比较紧张,三星仅有安霸一家,产能肯定非常充裕。
智能驾驶芯片排名并不简单只看AI算力,存储带宽和AI算力数值一样重要,CPU算力也很重要,智能驾驶系统软件异常复杂,会消耗大量的CPU运算资源,软件系统包含众多中间件诸如SOME/IP、自适应AUTOSAR、DDS、ROS等,基础软件包括订制的Linux BSP、OS抽象层、虚拟机,还有与底层硬件关联的内存管理、各种驱动、各种通讯协议等等。除此之外,应用层中的路径规划、高精度地图、行为决策等也大量消耗CPU资源,同时CPU也管理AI运算时的任务调度、存储搬运指令等,整体的任务调度,决策自然也是CPU的任务。CPU是绝对的核心,AI是CPU的附属功能,只是在做图像特征提取、分类、BEV变换、矢量地图映射或空间分布占有时才用到AI。
排名的权重依次是AI算力、存储带宽、CPU算力、GPU算力、制造工艺。存储带宽和AI算力同等权重,GPU也是锦上添花,大部分车载AI处理部分只能对应INT8位数据,而GPU可以对应FP32数据,有些时候可能有很大作用。实际AI算力数字完全是个黑箱,有些厂家写的是等效于多少算力,这里面操作空间极大,参考意义不大。最能准确衡量算力的是MAC阵列数量,谷歌的TPU V1是65000个FP16 MAC,运行频率0.7GHz,那么算力就是65000*0.7G*2=91TOPS。特斯拉第一代FSD两个NPU,每个NPU是9216个INT8 MAC,运行频率是2GHz,算力就是2*2*2G*9216=73.7TOPS。制造工艺方面,自然还是越先进,功耗越低。
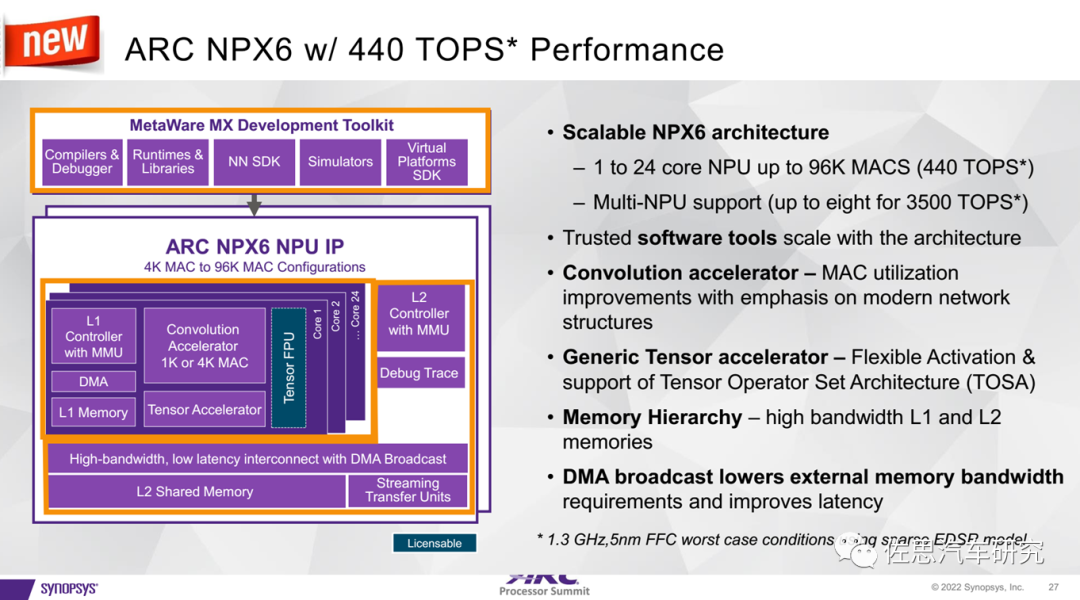
图片来源:Synopsys
上图是SYNOPSYS推出的一款IP,最高支持8个NPU,达到3500TOPS的算力,单个NPU有高达96000个MAC,运行频率1.3GHz,2*1.3G*96000=249.6TOPS的算力,这个显然是稠密值,如果是稀疏EDSR模式,那么算力会增加大约76%,即440TOPS。
蔚来NX9031未公布算力,有人认为NX9031是代替4片英伟达Orin的,算力自然是4*254=1008TOPS。这就大错特错了,4片英伟达Orin如果是用以太网交换机连接,那么算力顶多增加20%,4片也就是大约300TOPS。想要算力增加4倍付出的成本远超4片Orin。
通过英伟达DGX级联8个GPU的例子来看看如何级联芯片。
英伟达DGX系统的示意图
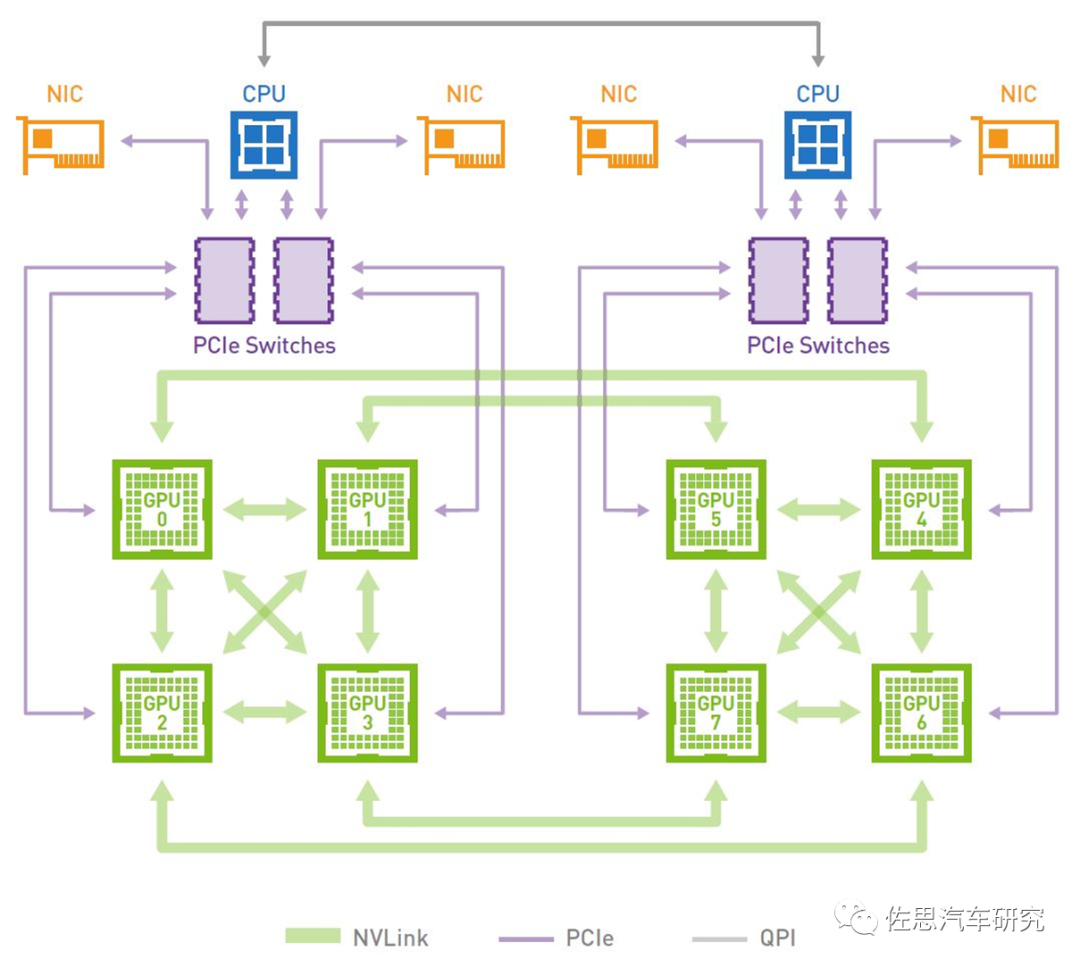
图片来源:NVIDIA
英伟达DGX系统有8个GPU也就是8张显卡级联,首先GPU是无法单独工作的,必须配合CPU才能工作。GPU之间是通过NVLink连接的,CPU与GPU之间是通过PCIe交换机连接的。

图片来源:NVIDIA
目前第四代NVLink的带宽是900GB/s,那么以太网交换机带宽是多少?以目前量产最顶级以太网交换机88Q5192来说,下行端口带宽一般是1Gb/s,也就是0.125GB/s,与NVLink有天壤之别,即便不看上行或下行,目前主流的以太网交换最高也就1.25GB/s,通常这种带宽的端口不超过两个。
想要媲美NVLink,让4个Orin就是4倍算力,可以考虑博通的Qumran3D的路由交换芯片,它的上行带宽高达3200GB/s,也就是25.6Tb/s,价格惊人,超过1万美元。不过Orin芯片最高也只支持1.25GB/s的以太网,Qumran3D是无法使用的。
再来看存储,蔚来把LPDDR5X特别点出来,但没说芯片存储位宽,也就无法得知存储带宽了。
历代LPDDR的参数
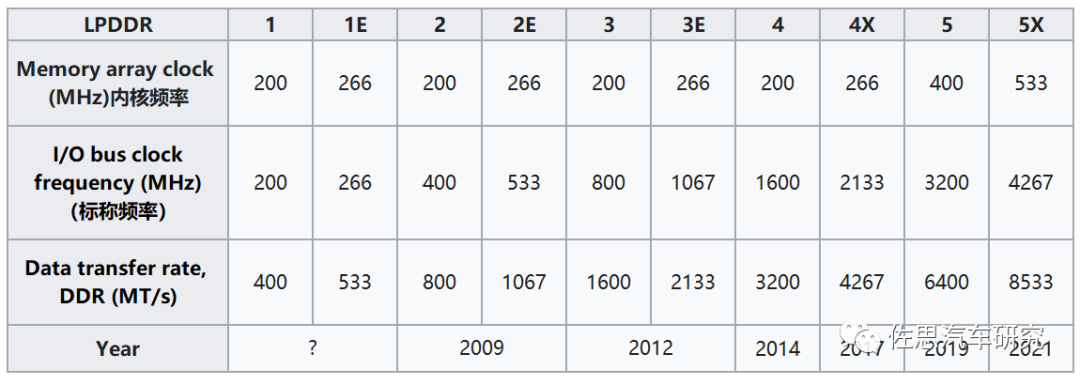
图片来源:公开资料整理
目前业内大多数是采用LPDDR5或LPDDR4,LPDDR5X毕竟是2021年才有标准的(实际2020年就有产品了),最高带宽8533MT/s,不过比LPDDR5X高的GDDR6已经有百度和特斯拉在用了,还有更高的HBM。
蔚来未给出位宽,估计位宽是128-256比特,存储带宽也就是136-273GB/s。那厂家为何不把位宽做高一点,很简单,会增加成本,芯片的成本就是die size,位宽越高,对应的内存控制器die size就增加越多,成本就增加越多。
苹果M3系列芯片
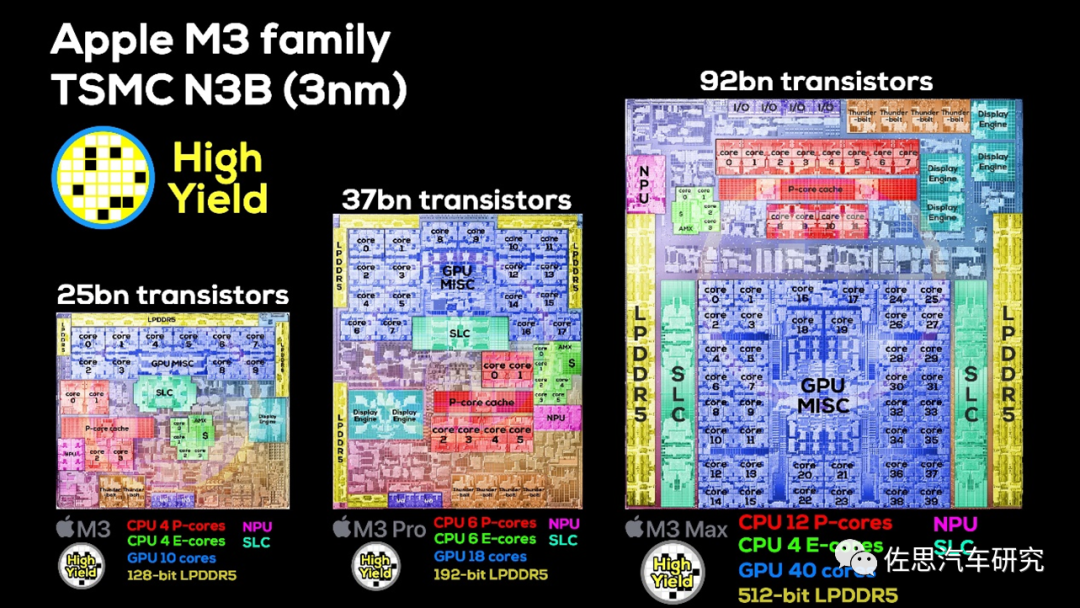
图片来源:Twitter
苹果M3的位宽仅128比特,M3 Pro是192比特,M3 Max是512比特,从上图不难看出M3 Max的内存控制器占的die size远比M3和M3 Pro大十几倍乃至几十倍以上,也就是存储位宽的增加会导致成本暴增,也是大多数厂家宁肯多放一些cache,也不愿意增加存储位宽的原因。
2023年初LPDDR进一步升级,出现了LPDDR5T,联发科的天玑9300第一个使用。
接下来看ISP(Image Signal Processor),早期有不少独立的外置ISP芯片,近期大多集成在SoC内,因为随着AI应用的大量出现和像素的飞速增加,外置ISP芯片延迟会比较明显。典型的ISP通常会对摄像头输出的RAW数据先做黑电平矫正(BLC)、坏点矫正(DPC)、数字增益(Dgain)、镜头阴影矫正(LSC)等必要处理。然后通过去马赛克(DM)插值恢复出全彩色图像,在RGB域完成色彩矩阵矫正(CMC)、伽马矫正(GMA)。最后转到YUV域,进行锐度(SHP)、对比度(CON)、颜色饱和度(SAT)等调整后输出。在整个ISP pipeline中间会插入若干降噪(NR)模块。
ISP流程
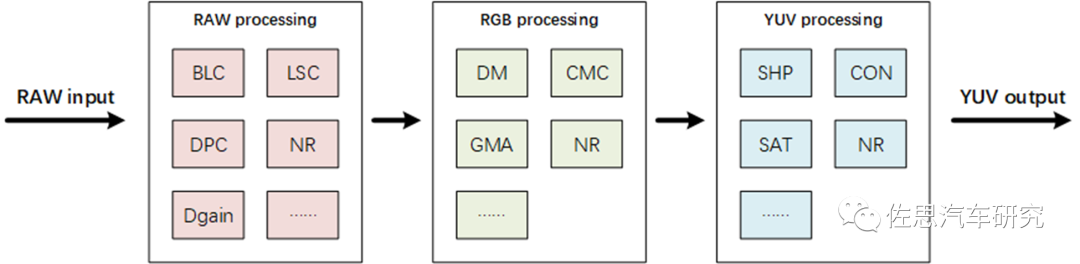
图片来源:网络
Orin内部也是有ISP的,处理像素的速度是1.85Gpixel/s,蔚来的NX9031达到了6.5Gpixel/s,是Orin的3倍还多。不过这不算什么,手机领域的ISP更高。
联发科天玑9000的ISP
上图是联发科天玑9000的ISP,高达9Gpixel/s,高通的一般会低一点。pixel/s越高意味着对应的摄像头像素可以越高,基本上1.3Gpixel/s就可对应1亿像素摄像头,但图像会有压缩,完全不压缩的话,3.2Gpixel/s可以对应1亿像素。蔚来可以对应2亿像素。
至于ISP的位宽,很少人提及,天玑9000的位宽是18比特,蔚来是26比特,高出不少,不过大部分图像传感器的位宽也只有10或12比特。位宽主要是ADC的动态范围决定,以索尼IMX490为例,当ADC是10比特时,帧率40fps,12比特时,帧率30fps。ISP的位宽越高意味着帧率可以越高。
最后来看CPU,CPU被蔚来重点标明,高达615kDMIPS的算力的确是无敌的。Orin的CPU算力是228kDMIPS,Orin是用了12个ARM Cortex-A78AE核心,ARM目前为汽车行业设计的大核心只有Cortex-A78AE,蔚来极有可能也是用Cortex-A78AE,Orin的L2缓存是3MB,L3缓存是6MB,运行频率是2.0-2.2GHz之间,也就是每个核心贡献19kDMIPS的算力。蔚来是5纳米工艺,运行频率和缓存都可以更高一点,估计最高可以达到每核心24kDMIPS的算力,估计大核心是20个,小核心还是常见的Cortex-A55,有12个。合起来算力就是615kDMIPS。
至于ASIL-D级功能安全,添加一个MCU核心岛即可,一般是2到4个Cortex-R52做锁步,高通SA8255、SA8755就是这种设计。 蔚来第一次做芯片就达到全球第三的水平,难能可贵。
审核编辑:黄飞
-
蔚来芯片子公司安徽神玑完成首轮超22亿元融资2026-02-28 718
-
蔚来智驾芯片神玑NX9031启动技术授权2025-11-20 7270
-
今日看点丨蔚来自研全球首颗车规5nm芯片!;沃尔沃中国区启动裁员计划2025-07-08 2314
-
蔚来拆分智驾芯片业务,新公司浮出水面2025-06-23 7060
-
蔚来神玑5nm智驾芯片流片成功2024-07-31 1472
-
蔚来:全球首颗5纳米智驾芯片神玑NX9031”流片成功北京中科同志科技股份有限公司 2024-07-29
-
蔚来宣布全球首颗车规级5纳米高性能智驾芯片流片成功2024-07-27 4000
-
蔚来5nm智驾芯片流片,车企智驾之战一触即发2024-07-23 4335
-
蔚来发布业界首款5nm自研芯片——神玑NX90312023-12-25 3562
-
自动驾驶AI芯片现状分析2020-12-04 2785
-
自动驾驶:小鹏在展翅,蔚来有未来2020-11-16 2747
-
蔚来正在规划自主研发自动驾驶计算芯片2020-10-21 1482
-
威马、小鹏、蔚来三足鼎立 激战自动驾驶市场2019-12-09 1522
全部0条评论

快来发表一下你的评论吧 !
