

如何使用NVIDIA DeepStream和Edge Impulse快速推进计算机视觉部署
描述
基于 AI 的计算机视觉(CV)应用日益增多,这对于从视频流中提取实时洞察至关重要。这项革命性的技术使作业人员能够在没有大量操作干预的情况下获得有价值的信息,从而为创新和解决问题带来了新的可能性。
NVIDIA DeepStream SDK 专门用于那些使用机器学习(ML)从视频流中提取深入洞察的智能视频分析(IVA)用例。在 NVIDIA 硬件上运行时,它使用 GPU 加速 ML,同时使用加速硬件实现预处理性能的最大化。
本文将探讨用于模型开发的 Edge Impulse 与用于部署的 NVIDIA DeepStream SDK 相结合的潜力,以便快速创建端到端应用。
计算机视觉应用
在如今的环境中,快速构建复杂、可扩展的 CV 应用的能力至关重要。典型的 CV 应用涵盖了各种用例,包括车辆识别、流量测量、检测系统、生产线质量控制、通过监控加强安全和安保、智能结账系统和过程测量等。
将机器智能进行集成来分析业务流程中的多媒体流可以带来巨大的价值。凭借无与伦比的准确性和可靠性,机器智能可以帮助精简运维,从而提高效率。
预建的 AI 模型有时并不是合适的解决方案,并且往往需要针对其未考虑到的特定问题来进行微调。
构建基于 AI 的 CV 应用通常需要三种技能:MLOps、CV 应用开发和部署(DevOps)。如果没有这些专业技能,项目的投资回报率和交付时间都可能面临风险。
过去,复杂的 CV 应用需要高度专业化的开发人员,因此需要耗费较长的学习周期和昂贵的资源。
Edge Impulse 与 NVIDIA DeepStream SDK 的组合提供了一个用户友好的互补解决方案堆栈,可帮助开发人员快速创建 IVA 解决方案。您可以针对特定用例轻松自定义应用,将 NVIDIA 硬件直接集成到您的解决方案中。
DeepStream 可免费使用,Edge Impulse 则提供了一个免费层,适合许多 ML 模型构建用例。
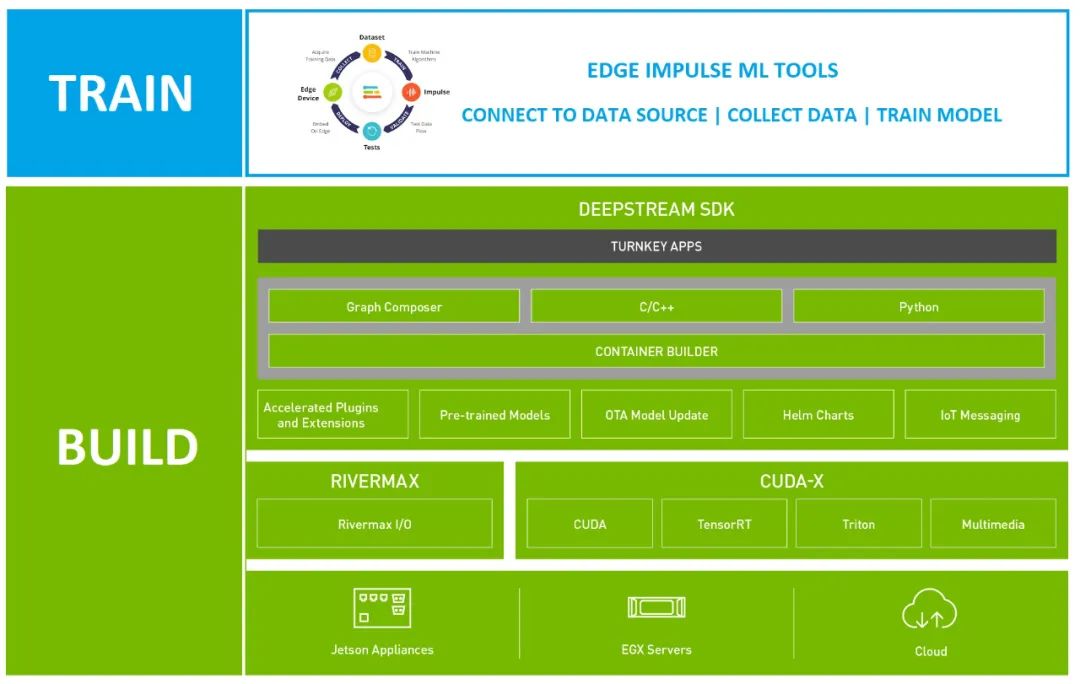
图 1. Edge Impulse 和 NVIDIA DeepStream SDK 解决方案堆栈
使用 NVIDIA DeepStream
构建 CV 应用
Deepstream SDK 是 NVIDIA Metropolis 的一个组件,旨在支持大规模的视频分析。您可以快速、轻松地创建可直接部署在 NVIDIA 硬件设备上的生产就绪 CV 管线。
DeepStream 应用的构建方法如下:
从命令行进行构建
使用 Graph Composer 以可视化的方式进行构建
使用 DeepStream 参考应用和配置文件进行构建,无需代码
使用 C++ 或 Python 代码进行进一步自定义
如果您不是开发人员,可以使用前三种方法中的任何一种,不到一小时就能搭建好管线,并与训练好的 ML 模型一起运行。如果您需要更多自定义功能,可以使用现有模板来构建一个自定义编码的解决方案。
部署 CV 应用
在创建管线后,您可以直接将其部署到 NVIDIA 硬件设备上,如边缘设备(如 NVIDIA Jetson Nano)、高性能计算(HPC)和云部署,以及混合部署等。
您可以将应用部署在 NVIDIA 边缘硬件上在本地运行,并直接连接视频源,以减少延迟。如果您需要处理复杂的管线或容纳超出 NVIDIA 边缘设备能力的多个视频源,可以将相同的管线部署到您首选的 IaaS 供应商的 NVIDIA 云实例上。
您也可以采用混合部署的方法,将管线部署到 NVIDIA 边缘设备上,然后使用 NVIDIA Triton 推理服务器远程执行推理。
Triton 能够远程执行模型,接收来自客户端的输入帧并返回结果。Triton 可使用 NVIDIA GPU,也可在 x86 上执行推理,并支持并发和动态批处理。Triton 还支持大多数常用的框架,包括 TensorFlow 和 PyTorch。
DeepStream 通过名为 Gst-nvinferserver 的 Gst-nvinfer 推理插件支持 Triton。通过使用该插件,您可以在 DeepStream 应用中使用 Triton 实例。
IVA 应用的好坏取决于构建时所使用的 ML 模型。虽然有许多预构建模型可以使用,但用例往往需要自定义模型和 MLOps 工作流。因此需要有一个易于使用的 MLOps 平台来实现快速部署,尤其在与 DeepStream 快速应用开发相结合时。
用于机器学习的 Edge Impulse
Edge Impulse 提供了一套功能强大的 ML 模型构建工具,这些模型可以直接部署到 NVIDIA 目标上并导入进 DeepStream 应用中。通过无缝集成 NVIDIA 硬件加速和 DeepStream SDK,Edge Impulse 能够帮助您快速扩展项目。
Edge Impulse 在整个过程中为各级开发人员提供指导。经验丰富的 ML 专业人员将享受到从不同来源导入数据的便捷性和端到端模型构建流程。您还可以将自定义模型与自定义学习块功能集成在一起,为 MLOps 减轻繁重的工作。
如果您是机器学习新手,Edge Impulse 流程会在您使用该环境时指导构建基本模型。可以在 DeepStream 中使用的基本模型类型包括 YOLO 对象检测和分类。
您还可以改造专为 tinyML 目标构建的模型,使其适用于边缘用例和功能更强大的 NVIDIA 硬件。许多边缘 AI 用例涉及复杂的应用,需要更强大的计算资源。NVIDIA 硬件可以帮助解决与受限设备的局限性相关的挑战。
您可以使用 Edge Impulse 从头开始创建自己的模型,Edge Impulse 还集成了 NVIDIA TAO 工具套件,可以使用 Computer Vision Model Zoo 中的一百多个预训练模型。Edge Impulse 是 TAO 的补充,可用于将这些模型调整为自定义应用,这对企业用户来说是一个很好的出发点。
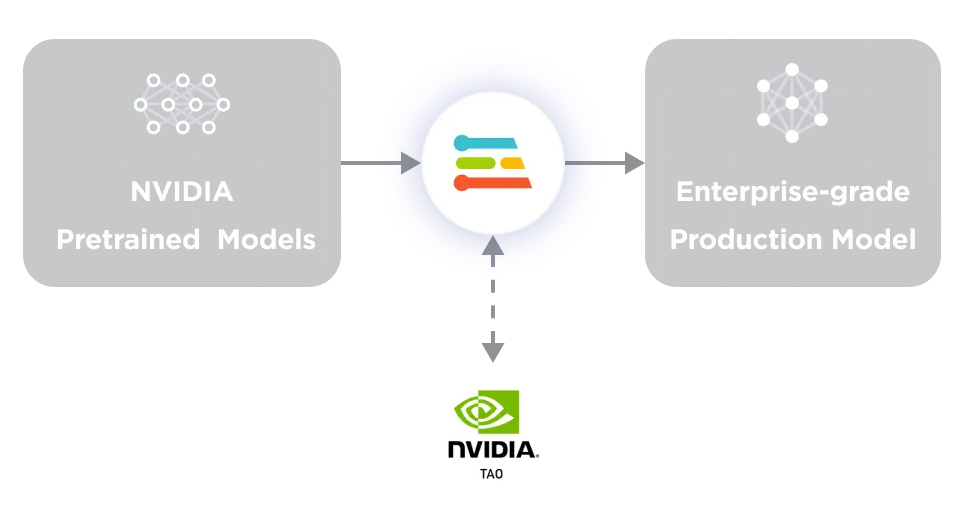
图 2. NVIDIA TAO 与
Edge Impulse Enterprise 相结合
使用 Edge Impulse 构建
适用于 DeepStream 的模型
在构建完模型后,将该模型部署到 DeepStream 中。从 Edge Impulse 导出模型文件并将其导入到 DeepStream 项目中。然后按照配置步骤操作,确保您的 Edge Impulse 模型能与 DeepStream 配合使用。该流程一般包括四个步骤(图 3)。

图 3. 将模型文件从 Edge Impulse
部署到 NVIDIA DeepStream 的四个步骤
第 1 步:
在 Edge Impulse 中构建模型
首先在 Edge Impulse Studio 中构建 YOLO 或图像分类模型。DeepStream 推理 Gst-nvinfer 插件要求输入层的张量为 NCHW 格式。请务必选择 Jetson Nano 作为目标,并使用 FP32 权重。
第 2 步:
从 Edge Impulse 导出模型
Edge Impulse 可以从 Edge Impulse Studio 的仪表盘页面中导出模型。YOLOv5 可以导出为带有 NCHW 输入层的 ONNX,以便与 DeepStream 一起使用。
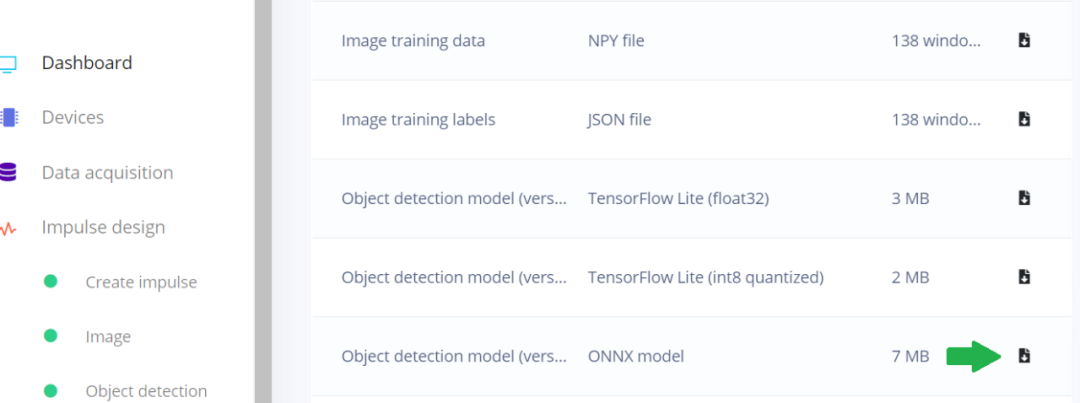
图 4. Edge Impulse Studio 仪表盘
显示如何导出为 ONNX 模型
DeepStream 中的 IVA 管线通常由一个主要推理(PGIE)步骤组成,该步骤使用边界框坐标执行对象检测。相关的对象类别会传递给二级推理步骤(SGIE),后者会对每个对象进行分类。每个步骤都以 Gst-nvinfer 插件实例的形式实现。
第 3 步:
将模型转换成与 DeepStream
兼容的 ONNX 格式
在将 YOLO 与 DeepStream 结合使用时,需要使用一个自定义输出层解析器来从输出层中提取边界框和对象类别,然后将其传递给下一个插件。有关自定义 YOLO 输出解析器的详细信息,请参见如何使用自定义 YOLO 模型:
https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_custom_YOLO.html
Edge Impulse 使用的 YOLOv5 是一种更新、性能更强大的模型,其输出张量格式与 YOLOv3 略有不同。YOLOv3 有三个输出层,分别负责检测不同尺度的物体,而 YOLOv5 只有一个输出层,使用锚框来处理各种尺寸的物体。
DeepStream 基于专门用于多媒体用例的 GStreamer。NVIDIA 在 GStreamer 管线中添加了支持深度学习的功能,包括额外的 ML 相关元数据,这些元数据通过 Gst-Buffer 在管线中传递,并通过 Gst-Buffer 封装在 NvDsBatchMeta 结构中。
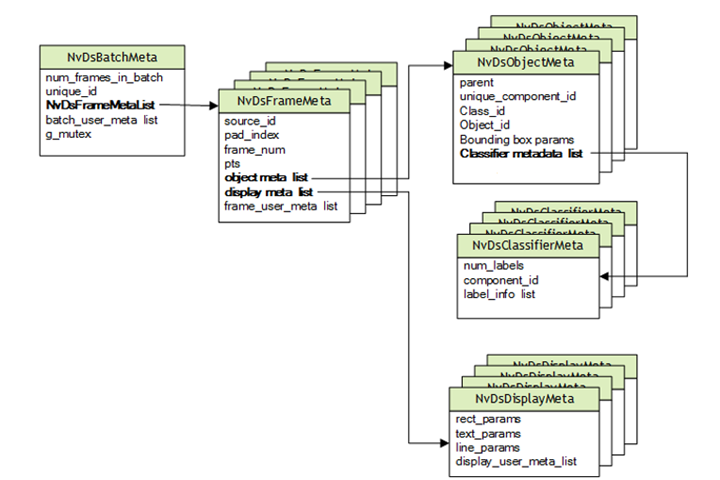
图 5. DeepStream 元数据层次
YOLO 的输出张量不同于 DeepStream 所需的边界框数据,这些边界框数据保存在 NvDsObjectMeta 中。为了将 YOLO 与 DeepStream 结合使用,就需要一个自定义输出解析器来转换 YOLO 输出,以满足 NvDsObjectMeta 在运行时的要求。NVIDIA 提供了一个通过 YOLOv3 运行的示例插件。
Edge Impulse 使用 YOLOv5。YOLOv3 和 YOLOv5 在输出层之间的差异使得 YOLOv3 插件不适合与 YOLOv5 一起使用(图 6)。
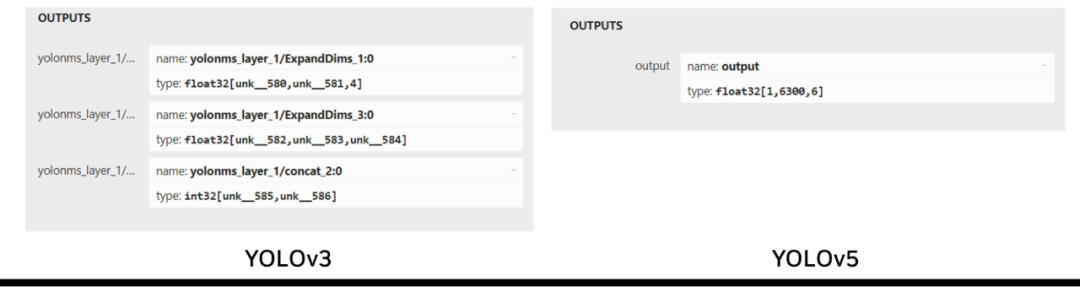
图 6. YOLOv3 和 YOLOv5 输出张量结构的比较
要使用在 Edge Impulse 中训练的 YOLOv5 模型,必须创建一个自定义的 YOLOv5 输出解析器来处理单个输出张量。可以使用的一种实现方式是与 Edge Impulse ONNX 格式导出模型一起工作的第三方输出解析器。
对于图像分类模型,需要将 Edge Impulse 以 NHWC 格式提供的默认 TFLite Float32 及其输入层转换为 NCHW 格式。
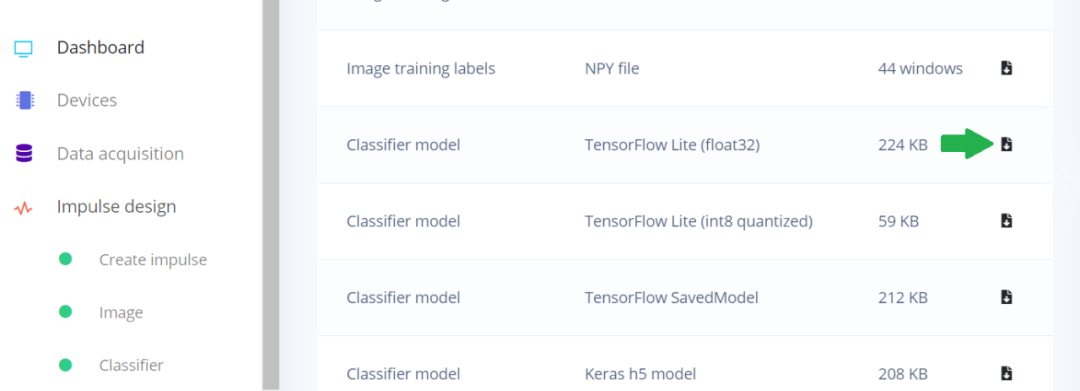
图 7. Edge Impulse Studio 仪表盘
显示 TFLight Float32 的位置
使用以下 tf2onnx 命令即可轻松实现:
python -m tf2onnx.convert --inputs-as-nchw serving_default_x:0 --opset 13 --tflite MODELFILE --output OUTPUT.ONNX
MODELFILE 是输入文件,OUTPUT.ONNX 是输出文件,Edge Impulse 生成的输入层名称被指定为 serving_default_x:0。因此,该输入层经过转换后符合 DeepStream 的要求。

图 8. Edge Impulse 默认输入层形状
与 DeepStream Gst-nvinfer 插件比较
第 4 步:
创建推理插件配置文件
DeepStream 要求为 Gst-nvinfer 插件的每个实例创建纯文本配置文件,以指定运行时要求,其中包括 ONNX 模型文件或生成的 TRT 引擎文件,以及包含标签名称的文本文件。图 9 显示了使用 Edge Impulse YOLOv5 和分类模型所需的最小参数集。

图 9. 使用 Edge Impulse 所创建的模型
的 Gst-nvinfer 插件配置参数
请注意,虽然为了便于说明,注释与参数并列显示,但所有配置参数都应另起一行。
process-mode 参数可用于指定插件是一级还是二级。请注意,在指定 ONNX 文件后,DeepStream 会使用 trtexec 生成 NVIDIA TensorRT 在 NVIDIA GPU 上执行的 TensorRT 引擎。
创建该引擎后,使用 model-engine-file 参数指定该引擎。可以注释掉 model-file 参数,以防止在每次运行时都重新创建引擎,从而节省启动时间。
根据 model-color-mode(模型是 RGB 还是灰度)的不同,该参数必须分别设置为 0 或 2。这将与 Edge Impulse Studio 中设置的颜色深度相对应。
上例展示了如何将该模型用作主推理插件。通过设置 process-mode 属性,也可以将该模型用作第二阶段分类器:
process-mode=2 #SGIE
图 9 中的示例还显示了两阶段管线所需的最小配置文件,其中 YOLO 模型会首先检测对象,然后在第二阶段分类器中对它们单独分类。对于 YOLO 模型,可以编辑默认的 YOLO 标签文件,并根据 YOLO 标准格式,将标签替换为自定义模型的标签,每个标签另起一行。
在分类模型中,标签用分号分隔。在运行期间,将根据这些文件对模型进行相应的索引,并显示您指定的文本。
DeepStream 可通过引用管线中嵌入这些设置的配置文件来使用。
审核编辑:刘清
-
计算机视觉的主要研究方向2024-06-06 3314
-
Edge Impulse发布新工具,助 NVIDIA 模型大规模部署2024-03-25 1786
-
什么是计算机视觉?计算机视觉的三种方法2023-11-16 6966
-
使用Edge Impulse和Nvidia Jetson的面罩检测器2023-06-26 1390
-
NVIDIA 携手微软打造大规模云端 AI 计算机2022-11-17 1420
-
计算机视觉的基础概念和现实应用2022-11-08 2802
-
NVIDIA DeepStream SDK是什么 有哪些特性2022-06-30 3458
-
深度学习与传统计算机视觉简介2021-12-23 2254
-
计算机视觉入门指南2020-11-27 3973
-
计算机视觉的发展历史_计算机视觉的应用方向2020-07-30 9293
-
计算机视觉与机器视觉区别2018-12-08 14274
-
机器视觉与计算机视觉的关系简述2014-05-13 3281
-
计算机视觉讲义2010-03-19 1019
-
基于OpenCV的计算机视觉技术实现2009-11-23 2021
全部0条评论

快来发表一下你的评论吧 !
